
浅谈链分治
 该文不被密码保护
该文不被密码保护
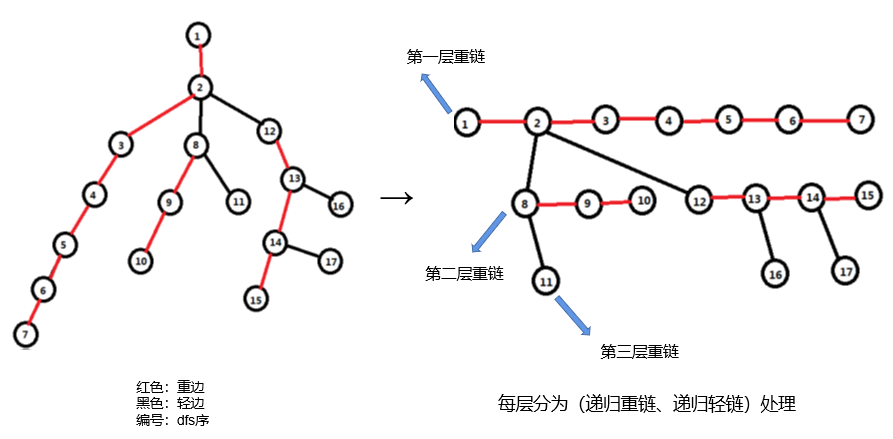
链分治
关于树的分治
众所周知大家会的有:淀粉质、边分治 (这两种分治相信大家都已经掌握了)
所以今天来讲一种新的树分治(说是新的其实大家都会)
前置知识:树链剖分、数据结构 (仅此而已)
链分治
点分治、边分治都是按点分、边分,最终分成一个点、一条边处理
同理,链分治也是按链分,最终分成一个点处理(一个点也是链)
通常情况下,链分治都是按树链剖分后按重链分治
形象地表达链分治
静态链分治

正如谈笑所言,静态链分治就是 dsu on tree
我们来温习一下 dsu on tree 的整个过程
- 递归轻子树,消除影响
- 递归重子树,不消除影响,将信息合并到根上
- 再递归轻子树,将信息合并到根上
- 判断是否上传信息
看似是 \(O(n^2)\) 的
但根据重剖性质,每个点到根的路径上最多经过 \(logn\) 条轻边
所以一个点在 1. 中遍历 \(O(logn)\) 次,2. 中遍历 1 次,3. 中遍历 \(O(logn)\) 次,每次遍历 \(O(1)\)
总时间复杂度为 \(O(nlogn)\)
从哪里可以看出 dsu on tree 的分治思想?
一棵树可以看作由一棵重子树和若干棵轻子树构成
操作 1. 就相当于处理所有轻子树,操作 2. 同理,操作 3. 相当于合并
这便是分而治之
例题
给你一棵 \(n\) 个节点的树,求每个节点的"结实程度"
一个节点的结实程度定义为以该节点为根的子树里所有节点的编号从小到大排列后,相邻编号的平方和。
假设一个节点的子树中所有节点编号排序后构成的序列为 \(a_1,a_2,...a_k\) ,那么答案为
\(n \le 1e5\)
sol
先考虑一个暴力的想法
用一个 set 维护子树内编号,然后做 dsu on tree,删除时清空,统计时遍历
时间复杂度为 \(O(n^2log^2n)\)
然后考虑优化
发现瓶颈在于每次统计时的遍历,我们其实可以在插入时统计答案
考虑每插入一个编号 \(i\) 带来的贡献
-
如果 \(i\) 是 set 中的最值,那么可以直接统计贡献
-
否则减去 \(i\) 在 set 中前驱后继产生的贡献,再加上 \(i\) 与前驱,\(i\) 与后继带来的贡献
这样时间复杂度为 \(O(nlog^2n)\)
另外,dsu on tree 不仅可以做 dsu on tree的题,还可以乱搞过一些静态树套树的题
并且 \(O(nlogn)\) 吊打树上莫队 \(O(n\sqrt n)\),所以有必要掌握
推荐题目:
CF570D Tree Requests(询问子树内特定深度的点)
CF600E Lomsat gelral(询问子树内颜色为众数的点)
CF741D Arpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths(求子树内边权重排能构成回文串的最长路径,注意答案初值赋为负)
CF就喜欢考dsu on tree(
动态链分治
淀粉质和边分治都难以处理动态树的问题(不要说点分树这些)
但由于链分治剖出来是一条条的链,我们可以用数据结构维护
所以链分治本身就可以资瓷修改

正如谈笑所言,链分治的本质其实就是树链剖分
主要是利用重剖和数据结构维护带修改的树上路径或子树问题(所以大家都会)
重链剖分
先复习一下重剖 (不会有人不会吧)
就是选子树大小最大的儿子做重儿子(多个取其一) ,对应的边为重边,重边连成的链为重链
性质:
-
树上每个节点都属于且仅属于一条重链
-
所有的重链将整棵树完全剖分
-
重链内的 dfn 序是连续的
-
树上的每条路径都可以被拆分成不超过 \(logn\) 条重链,也就意味着每个节点到根的路径上经过不超过 \(logn\) 条轻边(因为每经过一条轻边,子树大小至少除以2)
用途:维护路径、子树信息,求LCA
例题
给你一颗 \(n\) 个点,初始点权为 0 的有根树,要求支持
Increase x y w 将路径 x 到 y 所有点点权加上 w
Sum x y 询问路径 x 到 y 的点权和
Major x y 询问从路径 x 到 y 最大点权
Minor x y 询问最小点权
Invert x y 将路径上的点权翻转(保证 x 和 y 是祖先后辈关系)
\(n≤5e4,|w|≤1e3\)
(LCT可做)
sol
前面四个操作都很模板,直接套个线段树就行了,主要是第五个翻转不好搞
路径翻转可对应为 dfn 区间翻转,想一下之前是不是做过什么区间翻转的题
就是文艺平衡树
其他操作也都可以用平衡树维护
由于一条路径上最多 \(logn\) 条轻边,所以最多翻转 \(logn\) 个区间
所以把这直接 \(logn\) 个区间所构成的 \(logn\) 棵平衡树从原树中抠出来,合并成一棵新树,再在根打标记,然后把新树拆成原来 \(logn\) 棵树,又合并回去就行了
细节:由于操作路径一定是条直链,所以只需要从更深的点不断跳重链,收集区间,然后倒序合并;统计 Max 和 Min 时把初始值设为 -INF 和 +INF,INF一定要为 long long 级,不然答案就会随平衡树的rand值改变而改变 (别问我怎么知道的)
总时间复杂度 \(O(nlog^2 n)\)
(代码有亿点点好写,也就近300行的样子)
SP2666 QTREE4 - Query on a tree IV
给一棵带边权的树,每个点开始时为白色,维护两种操作:
-
改变一个点的颜色(白变黑,黑变白)
-
询问最远的两个白点之间的距离
\(n≤1e5,q≤2e5,|w|≤1e3\)
(这是一道LCT的题)
sol
先树剖,并对每条重链开一棵线段树
对于线段树上的一个节点 \(p\),其对应区间为 \([L,R]\)(重链上的一条路径)
记 \(lmx_p\) 表示从 \(L\) 出发,在 \([L,R]\) 间的某个节点拐出重链能到达的最远白点,\(rmx_p\) 同理,\(mx_p\) 表示 LCA 在¥\([L,R]\) 间的每对白点间距离的最大值
考虑线段树合并
记当前线段树上节点为 \(p\),区间为 \([L,R]\) ,左右儿子分别为 \(ls\) 对应\([L,mid]\),\(rs\) 对应 \([mid+1,R]\)
\(lmx_p=max\{lmx_{ls},dis(L,mid+1)+lmx_{rs}\}\)
\(rmx_p=max\{rmx_{rs},dis(mid,R)+rmx_{ls}\}\)
\(mx_p=max\{mx_{ls},mx_{rs},rmx_{ls}+dis(mid,mid+1)+lmx_{rs}\}\)
接下来考虑边界(线段树叶子节点)
记当前线段树上节点为 \(p\),对应 \([L,L]\)
记 \(d_i, d’_i\) 表示以 \(i\) 为根的轻子树内,根到白点的最远距离和次远距离,不存在即为 \(-\infty\)
当 \(L\) 为白点时:
\(lmx_p=rmx_p=max\{0,d_L\}\)
\(mx_p=max\{0,d_L,d_L+d'_L\}\)
当 \(L\) 为黑点时:
\(lmx_p=rmx_p=d_L\)
\(mx_p=d_L+d'_L\)
\(d\) 和 \(d’\) 如何维护?
记当前节点为 \(u\) ,它的一个轻儿子为 \(v\)
由于 \(u\) 在重链上,\(v\) 是 \(u\) 的轻儿子,所以 \(v\) 一定是另一条重链的开端
所以 \(v\) 的 dfn 就是 \(v\) 所在的这条重链所对应区间的左端点
所以从 \(v\) 出发到其子树内最远白点的距离就是这条重链的线段树的根的 \(lmx\)
记这个根为 \(p\)
若 \(u\) 为白点:\(d_u=max\{w(u,v)+lmx_p,0\}\)
若 \(u\) 为黑点:\(d_u=max\{w(u,v)+lmx_p\}\)
具体可以每个节点开一个 multiset,把轻儿子的 \(lmx+w\)丢进去,如果是白点再丢个 \(0\) ,那么 \(d\) 就是堆顶
对于修改,只需不断向上跳重链,同时删除原来贡献,加入新的贡献
由于一次修改最多更新 \(logn\) 次,所以时间复杂度为 \(O(nlog^2 n)\)
这样写属实有点搞心态
还有个比较简便的做法
可以添加虚点将树变为二叉树,如图
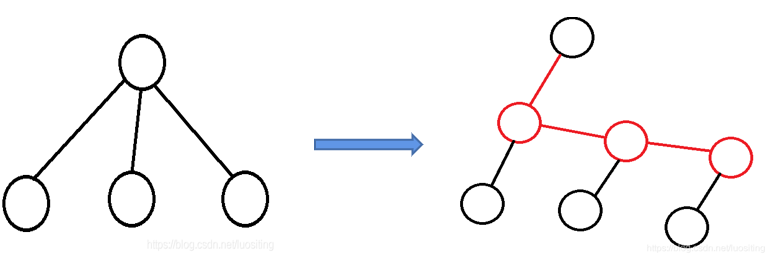
红点为虚点,红边边权为 \(0\)
这样每个点只有一个重儿子,一个轻儿子,那么 \(d\) 就唯一确定,\(d'\) 必为 \(-\infty\) ,不需要开 multiset 了
更多的题目
P1505 [国家集训队]旅游(LCT可做)(模板)
P2486 [SDOI2011]染色(LCT可做)(树上路径染色和询问路径染色段数)
P3313 [SDOI2014]旅行(LCT可做)(节点有标识和权值,修改标识/权值,询问路径上某含标识点的权值最大值/权值和)
长链剖分
再复习一下长剖(准确来说这一块应该属于静态链分治)
就是选子树深度最大的儿子做重儿子(多个取其一),对应的边为重边,重边连成的链为重链
性质:
-
树上每个节点都属于且仅属于一条重链(照搬)
-
所有的重链将整棵树完全剖分(照搬)
-
重链内的dfn序是连续的(照搬)
-
任意节点 \(u\) 的第 \(k\) 级祖先 \(v\) 所在重链的长度一定大于 \(k\)
Proof:
若过 \(u,v\) 在一条重链上显然;
反之,如果 \(v\) 所在链的长度小于 \(k\) ,那么 \(v\rightarrow u\) 这条链显然更长,那么 \(u,v\) 应在一条重链上,矛盾
- 每个节点到根的路径上经过不超过 \(\sqrt n\) 条重链(因为每经过一条轻边,子树大小至少除以 2 )
Proof:
根据性质 4,越往上跳,链越长,最坏情况跳的链长为 \(1,2,…,\sqrt n\)(根据性质1,链长之和为 \(n\) )
应用:
- 求树上 \(k\) 级祖先
这个问题可以倍增 \(O(nlogn)-O(logn)\) 或者重剖 \(O(n)-O(logn)\) 解决
但利用长剖可以做到 \(O(nlogn)-O(1)\) 解决
先长链剖分,同时树上倍增求出 \(2^k\) 级祖先 \(O(nlogn)\)
对于每个长链链顶 \(u\) ,记链长为 \(len\) ,记录 \(u\) 向上 \(len\) 个祖先和向下 \(len\) 个重儿子 \(O(n)\)
对于每次询问 \(x\) 的 \(k\) 级祖先,先跳到 \(x\) 的 \(2^{\lfloor logk\rfloor}\) 级祖先 \(y\)( \(y\) 在 \(x\) 的 \(k\) 级祖先下面或者 \(y\) 就是 \(x\) 的 \(k\) 级祖先)
根据性质 4,\(y\) 所在链长度大于 \(2^{\lfloor logk\rfloor}\) ,又因为 \(y\) 距离 \(x\) 的 \(k\) 级祖先距离小于 \(2^{\lfloor logk\rfloor}\)
所以可以先跳到 \(y\) 的链顶,若剩下级数为正,就向上查,否则向下查 \(O(1)\)
- 优化与深度相关的DP
思路很像dsu on tree,将轻儿子的信息向重儿子合并,使得每个节点 \(O(n)\) 的转移可以优化到均摊 \(O(1)\) ,同时搭配指针使用,空间直接由 \(O(n^2)\) 变为 \(O(2n)\)(取导)
可以先从优化一个简单的DP方程入手
设 \(f_(u,i)\) 表示在以 \(u\) 为根的子树中,与 \(u\) 距离为 \(i\) 的点的个数
这个树形DP显然时间空间都为 \(O(n^2 )\)
而一般的树的点数都时 \(1e5\) 级别的,所以这个DP直接TM双飞
考虑如果树退化成链的情况
那么方程显然可以写成
这下时间还是 \(O(n^2)\),但空间可以用滚动数组优化变为 \(O(2n)\)
那么如果我们把树剖成链,每个链单独分配大小为链长的空间,空间问题便得到解决
int *f[2][N];
inline void dfs(int u, int fa)
{
if (top[u] == u)//链顶处分配空间
{
f[0][u] = new int [mxdep[u] - dep[u] + 5];
f[1][u] = new int [mxdep[u] - dep[u] + 5];
}
//...
}
但这种滚动数组的写法比较少见,因为 new int 出来的数组初始值并不为 \(0\),需要循环赋值(不能 memset ),所以 Lougu 上更常见的是用指针分配
相当于先把 \(O(2n)\) 的数组开好,到了链顶,从数组中划一片给你这条链DP用
int tmp[N << 1]//先把全部数组开完
int *f[N], *now = &tmp[0];//now 是划分用的指针
inline void dfs(int u, int fa)
{
if (top[u] == u) //链顶分配空间
{
f[u] = now;//领空间
//f[u]占据了tmp的[now, (mxdep[u] - dep[u]) << 1] 这一部分的空间
now += ((mxdep[u] - dep[u]) << 1);//跳到下一个位置
}
//...
}
这样做还有一个好处,再次观察这个方程
从 \(f_{k-1}\) 到 \(f_k\) 实际上就把 \(f_{k-1}\) 向右移了 \(1\) 位
用指针表示为 \(f_k=f_{k-1}-1\)
所以在将空间传到重儿子时,我们只需让 \(f_{son[u]}=f_u+1\),这个操作是 \(O(1)\) 的
这样一直移,到链尾时移动的距离就变为了链长,但DP还要用的空间大小为 \(O(\text{链长})\),所以此时这条链实际已经占用 \(O(2 \cdot \text{链长})\) 的空间了,这就是为什么不用滚动数组也要开两倍空间的原因
此时,我们发现重链上的转移时间复杂度变为 \(O(\text{链长})\),而在以每个点为根,轻链向重链合并时时间为 \(O(\sum\text{轻链长})\) ,这就是为什么选长剖而不是重剖的原因
总时间复杂度为 \(O(n)\) 级别
例题
给定一棵树,在树上选 \(3\) 个点,要求两两距离相等,求方案数。
\(n≤5e3\)
加强版:\(n≤1e5\)(BZOJ4543)
sol
考虑三点距离相等的两种情况:对于当前点 \(u\)
- 三点都在u的子树内(那么 \(u\) 一定是LCA)
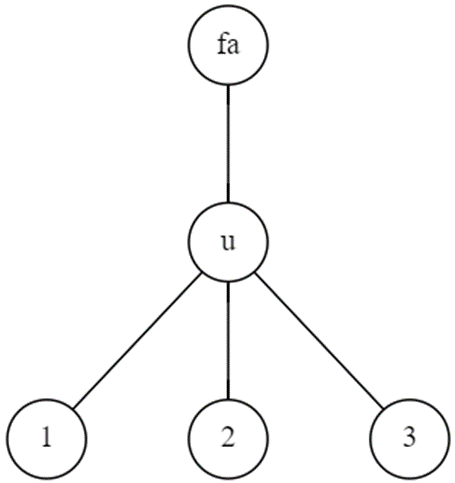
- 两点在子树内,一点在子树外,且LCA在子树内
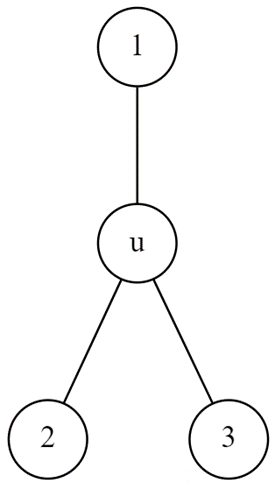
由于保证了第二种情况LCA在子树内,所以不需要讨论一点在子树内的情况
为了维护第一种情况,设 \(f_{u,i}\) 表示节点 \(u\) 子树内与 \(u\) 距离为 \(i\) 的点的数量
为了维护第二种情况,设 \(g_{u,i}\) 表示节点 \(u\) 的子树内两个点 \(x,y\) 到 LCA 的距离为 \(d\),LCA 到 \(u\) 的距离为 \(d-i\)
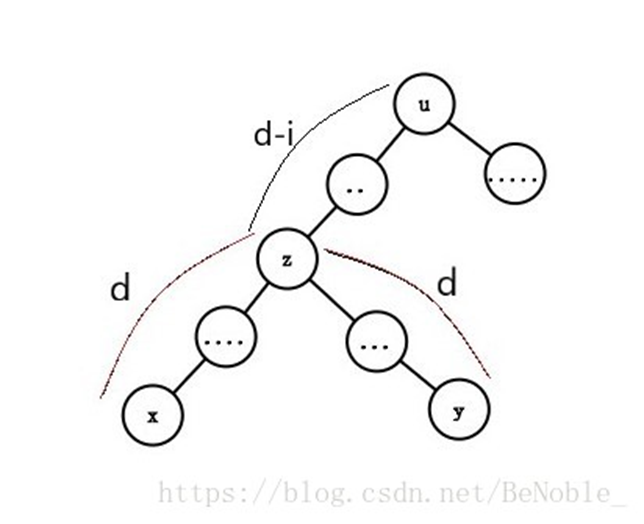
这么定义的目的是为了使 LCA 在 \(u\) 的子树内,以防算重
可以理解为:第三点为 \(u\) 向 LCA 所在子树以外的区域走 \(i\) 步(具体到哪个不用知道),选取第一二点的方案数
现在考虑转移(\(u\) 是当前点,\(v1,v2\) 是 \(u\) 的儿子)
\(f_{u,i} \leftarrow f_{v,i-1}\)
这个显然
\(g_{u,i} \leftarrow g_{v,i+1}\) (LCA在 \(u\) 的子树内)
第三点在子树外距 \(u\) 为 \(i\) 可以由距 \(v\) 为 \(i+1\) 转移而来
\(g_{u,i} \leftarrow f_{v1,i-1} \cdot f_{v2,i-1}\) (\(u\) 就是LCA)
因为 \(u\) 是 LCA,所以 LCA 到 \(u\) 的距离为 \(d-i=0 \Rightarrow d=i\),那么由来自两棵子树且与 \(u\) (LCA)距离为 \(i\) 的点贡献
注意到这个转移是 \(n^2\) 的,加上枚举节点就是 \(n^3\) 了,需要优化
可以使用前缀和的思想,先 \(g_{u,i} \leftarrow f_{u,i}\cdot f_{v,i-1}\),再 \(f_{u,i}\leftarrow f_{v,i-1}\),枚举一个儿子就贡献一次 \(g\)
这种思想在树背包中也经常用到
考虑统计答案
\(ans \leftarrow f_{v1,i-1} \cdot g_{v2,i+1}\)
选两棵子树,一棵出两个点和 LCA,另一棵出第三点
同样是丑陋的 \(n^2\) 转移,同样利用前缀和思想
\(\Leftrightarrow ans \leftarrow f_{u,i}\cdot g_{v,i+1},ans\leftarrow g_{u,i}\cdot f_{v,i-1}\)( LCA 在当前这棵子树内还是在前面的子树内)
总时间复杂度 \(O(n^2)\),空间复杂度 \(O(2n^2)\)
但很遗憾,内存限制只有 62.5MB,过不了
利用刚才讲的指针优化,空间降为 \(O(4n)\) ,可以通过
再用长剖将时间降为 \(O(n)\),通过加强版
总而言之,长剖能够优化的树形DP一般具有以下特征:
状态一般为 dp[树上一个点][与该点的距离](状态与 深度 or 链长 or 路径长… 有关),儿子向父亲转移时一般\(O(n)\),利用长剖优化成均摊 \(O(1)\),空间一条链共用,用指针优化后由 \(O(n^2)\) 降至 \(O(2n)\)
是一种时间空间双优的优化
更多的题目
CF1009F Dominant Indices(询问最小距离,使得点数最多)(虽然是dsu on tree的板子题,但练练长剖优化DP还是可以的)(实测dsu on tree带个 log 还更快,大雾)
