
由于 bitmap、zset、list、set、map、stream 用的底层数据结构已经在之前介绍了,而这些数据结构又不如 quicklist 复杂,所以将会在此一口气全部介绍完。
确定一个命令调用了什么函数
这个问题,举个例子说明。假如你在 redis-cli 中输入 setbit mykey 100 1,那么 redis 实际上调用的函数是什么。本来我是想在代码中找的,后面用 grep 一查才发现,代码中根本没有,它实际是在一个 commands.def 文件中定义的。以下是 commands.c。里面有一个 MAKE_CMD,这就是定义一个命令的宏函数。
#include "commands.h"
#include "server.h"
#define MAKE_CMD(name,summary,complexity,since,doc_flags,replaced,deprecated,group,group_enum,history,num_history,tips,num_tips,function,arity,flags,acl,key_specs,key_specs_num,get_keys,numargs) name,summary,complexity,since,doc_flags,replaced,deprecated,group_enum,history,num_history,tips,num_tips,function,arity,flags,acl,key_specs,key_specs_num,get_keys,numargs
#define MAKE_ARG(name,type,key_spec_index,token,summary,since,flags,numsubargs,deprecated_since) name,type,key_spec_index,token,summary,since,flags,deprecated_since,numsubargs
#define COMMAND_STRUCT redisCommand
#define COMMAND_ARG redisCommandArg
#ifdef LOG_REQ_RES
#include "commands_with_reply_schema.def"
#else
#include "commands.def"
#endif
打开 commands.def,我们就可以发现它是由 utils/generate-command-code.py 生成的。后面又发现了 utils/generate-commands-json.py、src/commands/*.json。比如 src/commands/setbit.json
{
"SETBIT": {
"summary": "Sets or clears the bit at offset of the string value. Creates the key if it doesn't exist.",
"complexity": "O(1)",
"group": "bitmap",
"since": "2.2.0",
"arity": 4,
"function": "setbitCommand",
"command_flags": [
"WRITE",
"DENYOOM"
],
"acl_categories": [
"BITMAP"
],
...
里面的 function 字段就是执行 setbit 所调用的函数了。
Overview
Redis 中数据结构的关系
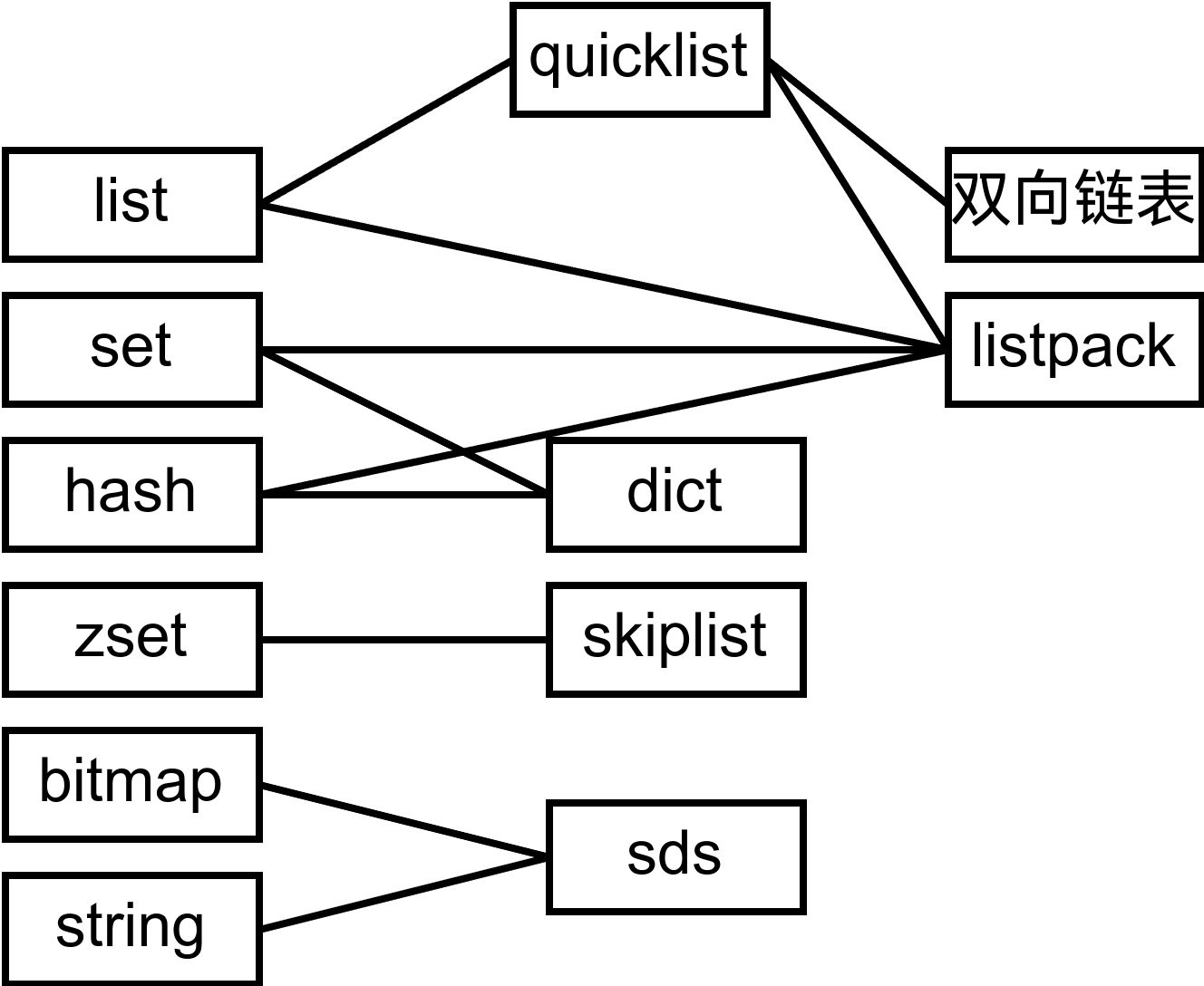
bitmap
bitmap,用一连串二进制的 0 和 1 来表示一个数据。内部实现是 redis 的 sds。剩下的内容基本上和你想的大差不差了,值得提的就是:
- setbit key offset 0/1:如果操作的 key 不存在,会创建一个大小为 offset / 8 + 1 的 sds。如果已经存在但是 sds 不够长,会自动扩容。以下是 setbitCommand 调用的 lookupStringFromBitCommand。
robj *lookupStringForBitCommand(client *c, uint64_t maxbit, int *dirty) {
size_t byte = maxbit >> 3;
robj *o = lookupKeyWrite(c->db,c->argv[1]);
if (checkType(c,o,OBJ_STRING)) return NULL;
if (dirty) *dirty = 0;
if (o == NULL) {
o = createObject(OBJ_STRING,sdsnewlen(NULL, byte+1));
dbAdd(c->db,c->argv[1],o);
if (dirty) *dirty = 1;
} else {
o = dbUnshareStringValue(c->db,c->argv[1],o);
size_t oldlen = sdslen(o->ptr);
o->ptr = sdsgrowzero(o->ptr,byte+1);
if (dirty && oldlen != sdslen(o->ptr)) *dirty = 1;
}
return o;
}
-
getbit 等读操作则不会自动扩容
-
bitpos 寻找第一个设置为 0 或 1 的方法是,先处理 start 和 end(因为可能是负数),还需要根据当前 sds 长度处理 start 和 end,最后才去找。找的时候会先处理左边界的字节,中间部分会和 0 或者 ULONG_MAX 比较,再处理右边界
zset
zset 混合了 listpack、哈希表和 skiplist,但不是同时用这两个数据结构体。数据量小的时候会用 listpack,否则是 skiplist + 哈希表。
listpack 会调用 zzlFind 确认该元素是否已经存在。zzlFind 调用 lpFind,skip 这个参数设置为 1 —— 这说明此时的 listpack 的用法是一个当作 score,另一个当作 element。然后根据参数选择操作的方式。有以下几种:
#define ZADD_IN_NONE 0
#define ZADD_IN_INCR (1<<0) /* Increment the score instead of setting it. */
#define ZADD_IN_NX (1<<1) /* Don't touch elements not already existing. */
#define ZADD_IN_XX (1<<2) /* Only touch elements already existing. */
#define ZADD_IN_GT (1<<3) /* Only update existing when new scores are higher. */
#define ZADD_IN_LT (1<<4) /* Only update existing when new scores are lower. */
它们和 ZADD 的用法是对应的,CH 则是 Element changed 的意思。
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]
listpack 转换为 skiplist 的条件是:
if (zzlLength(zobj->ptr)+1 > server.zset_max_listpack_entries ||
sdslen(ele) > server.zset_max_listpack_value ||
!lpSafeToAdd(zobj->ptr, sdslen(ele)))
{
zsetConvertAndExpand(zobj, OBJ_ENCODING_SKIPLIST, zsetLength(zobj) + 1);
}
所以是比对 zset_max_listpack_entries、zset_max_listpack_value,以及新值能否正常插入到 listpack 中。
也可能转换回 listpack,只在 GEO 和 zunion 中看到这函数调用。
void zsetConvertToListpackIfNeeded(robj *zobj, size_t maxelelen, size_t totelelen) {
if (zobj->encoding == OBJ_ENCODING_LISTPACK) return;
zset *zset = zobj->ptr;
if (zset->zsl->length <= server.zset_max_listpack_entries &&
maxelelen <= server.zset_max_listpack_value &&
lpSafeToAdd(NULL, totelelen))
{
zsetConvert(zobj,OBJ_ENCODING_LISTPACK);
}
}
除此之外值得提的:
- ZCARD 不会处理重复的 score,所以就是直接返回 listpack 和 skiplist 中包含的元素总数量。ZCARD 会调用 zsetLength。(zset 是不可能有重复元素的,但是可能有重复的 score)。
unsigned long zsetLength(const robj *zobj) {
unsigned long length = 0;
if (zobj->encoding == OBJ_ENCODING_LISTPACK) {
length = zzlLength(zobj->ptr);
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
length = ((const zset*)zobj->ptr)->zsl->length;
} else {
serverPanic("Unknown sorted set encoding");
}
return length;
}
- ZDIFF 会进行算法选择
ZDIFF numkeys key1 [key2 ...] [WITHSCORES]
ZDIFF 将 key1 中有,在 key2, key3... 中没有的元素取出来。
两个算法的流程分别是:
算法1:
对 set 进行从元素多到元素少排序,然后类似于下面的伪代码:
for each key in key1 对应的 set:
existed = false
for each set in key2, key3, key4... 对应的 set:
if key in set:
existed = true
if not existed:
add to result
所以时间复杂度确实是O(key1对应的set的大小*一共有多少个要处理的set)源码注释中给的O(N*M+K*log(K))是对它更加精确的描述
算法2:
复制 key1 对应的 set/zset,挨个遍历其他所有 set/zset 中的所有元素,边遍历,边在复制的 set/zset 中删除。所以时间复杂度就是O(sum(所有 set/zset 中的元素数量)),源码注释中给的O(L+(N-K)log(N))也一样是一个更加精确的描述。
下面的函数用于选择用哪个算法。简单说就是比较O(N*M)和O(L)哪个大,哪个小。
static int zsetChooseDiffAlgorithm(zsetopsrc *src, long setnum) {
int j;
long long algo_one_work = 0;
long long algo_two_work = 0;
for (j = 0; j < setnum; j++) {
/* If any other set is equal to the first set, there is nothing to be
* done, since we would remove all elements anyway. */
if (j > 0 && src[0].subject == src[j].subject) {
return 0;
}
algo_one_work += zuiLength(&src[0]);
algo_two_work += zuiLength(&src[j]);
}
/* Algorithm 1 has better constant times and performs less operations
* if there are elements in common. Give it some advantage. */
algo_one_work /= 2;
return (algo_one_work <= algo_two_work) ? 1 : 2;
}
- 可以混合 zset 和 set 使用
不仅仅可以直接用 redis-cli 试,还可以在源代码中找到对应的迭代器,可以轻松地看出来确实包含了多种迭代器。
下图展示了从 zset 取出所有不在 set 中的元素。
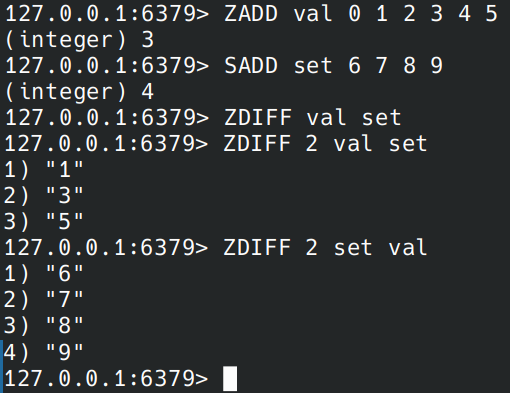
typedef struct {
robj *subject;
int type; /* Set, sorted set */
int encoding;
double weight;
union {
/* Set iterators. */
union _iterset {
struct {
intset *is;
int ii;
} is;
struct {
dict *dict;
dictIterator *di;
dictEntry *de;
} ht;
struct {
unsigned char *lp;
unsigned char *p;
} lp;
} set;
/* Sorted set iterators. */
union _iterzset {
struct {
unsigned char *zl;
unsigned char *eptr, *sptr;
} zl;
struct {
zset *zs;
zskiplistNode *node;
} sl;
} zset;
} iter;
} zsetopsrc;
- 混合使用 set、zset,并使用 withscores
set 是没有 score 的,但是却可以获得下面的结果。
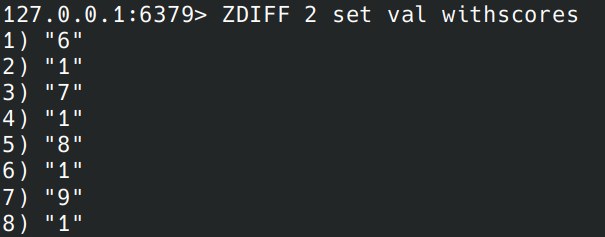
一看代码才知道,原来默认为 1.0(个人认为用一个 123456789 可能更加合适,这么奇怪的数字可以提醒开发者哪里出问题了,这种技巧也在 listpack 中出现过)
int zuiNext(zsetopsrc *op, zsetopval *val) {
...
if (op->type == OBJ_SET) {
iterset *it = &op->iter.set;
if (op->encoding == OBJ_ENCODING_INTSET) {
int64_t ell;
if (!intsetGet(it->is.is,it->is.ii,&ell))
return 0;
val->ell = ell;
val->score = 1.0;
/* Move to next element. */
it->is.ii++;
} else if (op->encoding == OBJ_ENCODING_HT) {
if (it->ht.de == NULL)
return 0;
val->ele = dictGetKey(it->ht.de);
val->score = 1.0;
/* Move to next element. */
it->ht.de = dictNext(it->ht.di);
} else if (op->encoding == OBJ_ENCODING_LISTPACK) {
if (it->lp.p == NULL)
return 0;
val->estr = lpGetValue(it->lp.p, &val->elen, &val->ell);
val->score = 1.0;
/* Move to next element. */
it->lp.p = lpNext(it->lp.lp, it->lp.p);
} else {
serverPanic("Unknown set encoding");
}
...
- 集合合并(union)、求交集(inter)
由于可能要操作都个 zset,所以每次都要考虑取哪个 score。
ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]]
[AGGREGATE <SUM | MIN | MAX>] [WITHSCORES]
ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]]
[AGGREGATE <SUM | MIN | MAX>] [WITHSCORES]
这也是代码中我们看到zunionInterAggregate(&score,value,aggregate);的原因。
- 所有的集合操作都需要检查是否在对同一个集合合并、求交集等
之所以这样,是因为所有的实现都会用迭代器,对同一个集合只能用一个 unsafe iter。
list
list 混合了 listpack、quicklist,但不是同时用这两个数据结构体。数据量小的时候会用 listpack,否则是 quicklist。
数据量大小的界限与 list_max_listpack_size相关,如果是整数那就是元素数量,负数就是分级判断元素大小(另一个转换函数是listTypeTryConvertListpack,与之类似):
static void listTypeTryConvertQuicklist(robj *o, int shrinking, beforeConvertCB fn, void *data) {
...
/* Check the length or size of the quicklist is below the limit. */
quicklistNodeLimit(server.list_max_listpack_size, &sz_limit, &count_limit);
if (shrinking) {
sz_limit /= 2;
count_limit /= 2;
}
if (ql->head->sz > sz_limit || ql->count > count_limit) return;
/* Invoke callback before conversion. */
if (fn) fn(data);
/* Extract the listpack from the unique quicklist node,
* then reset it and release the quicklist. */
o->ptr = ql->head->entry;
ql->head->entry = NULL;
quicklistRelease(ql);
o->encoding = OBJ_ENCODING_LISTPACK;
}
void quicklistNodeLimit(int fill, size_t *size, unsigned int *count) {
*size = SIZE_MAX;
*count = UINT_MAX;
if (fill >= 0) {
/* Ensure that one node have at least one entry */
*count = (fill == 0) ? 1 : fill;
} else {
*size = quicklistNodeNegFillLimit(fill);
}
}
static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};
static size_t quicklistNodeNegFillLimit(int fill) {
assert(fill < 0);
size_t offset = (-fill) - 1;
// 就是计算 optimization_level 数组有多少个元素。
size_t max_level = sizeof(optimization_level) / sizeof(*optimization_level);
if (offset >= max_level) offset = max_level - 1;
return optimization_level[offset];
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号