

quicklist 实际上混合了两种类型。一种是 listpack,用于存放一些小元素,另一种是普通的双向链表节点,用于存放大元素。这两种类型都可能会被压缩为 LFZ 格式。由于一些原因,某些地方得看了源代码才能够明白这些结构体成员的意思。
quicklist 结构体
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmarks are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all listpacks */
unsigned long len; /* number of quicklistNodes */
signed int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
-
head, tail,就是传统链表中的头、尾节点指针。
-
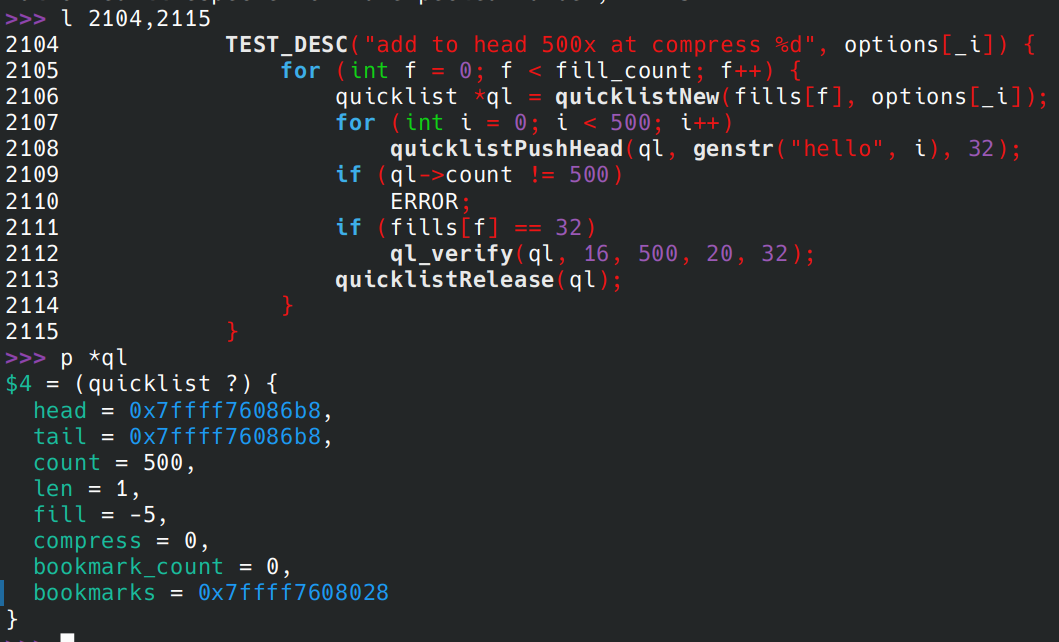
count,说白了就是你插入到 quicklist 的元素总数量,此处我怀疑注释写错了,就算单看 Push 的实现都会有这种感觉。注释中写的是 listpack 中元素的数量。而实际:
a. 插入 500 个小元素,可见 count 确实是 500,len 确实是 1
b. 插入 500 个大元素,可见 count 确实是 500,len 确实是 500
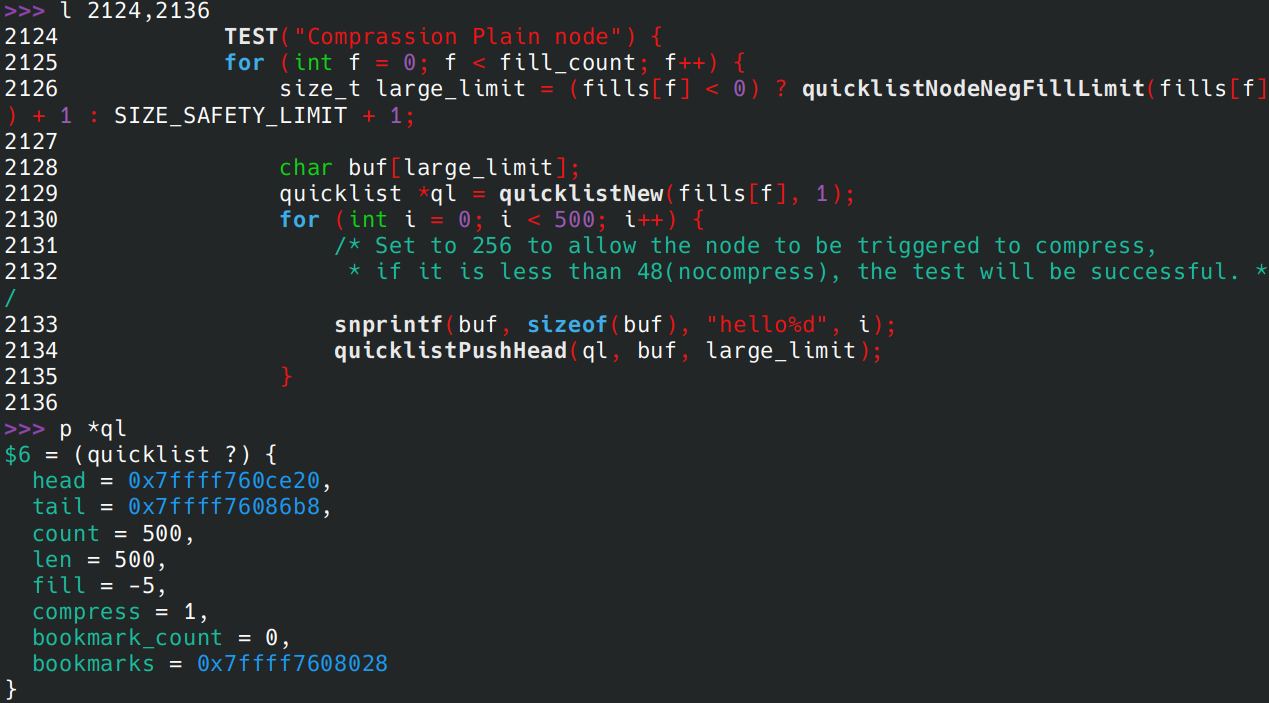
-
len, 该 quicklist 中的 quicklistNode 的数量,这个值不一定会和 count 相同,因为一个 listpack 中保存的元素往往不止一个——小元素会直接保存在 listpack 中,而不是一个元素单独一个节点。
-
fill, 用于判断元素是大元素还是小元素。如果 fill >= 0,那么如果插入的元素的大小大于
SIZE_SAFETY_LIMIT == 8192,那么会视作大元素。如果 fill < 0,那么 redis 会根据 fill 选择一个界限。这些界限保存在数组static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};中,取界限的方式是optimization_level[-fill - 1],如果 -fill - 1 导致数组越界,就直接取最后一个 65536。还有一个界限是 debug 用的:packed_threshold。
static int isLargeElement(size_t sz, int fill) {
if (unlikely(packed_threshold != 0)) return sz >= packed_threshold;
if (fill >= 0)
return !sizeMeetsSafetyLimit(sz);
else
return sz > quicklistNodeNegFillLimit(fill);
}
-
compress,如果它大于 0,表示 quicklist 头和尾开始的节点,需要有多少没有被压缩的。也就是说,如果这个 quicklist 足够长,且 compress > 0,那么 quicklist 中间部分没有被压缩。
-
bookmark,目前只在 scanLaterList 中看到调用,用途暂且不明确
下面是 quicklistNode。
/* quicklistNode is a 32 byte struct describing a listpack for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max lp bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, PLAIN=1 (a single item as char array), PACKED=2 (listpack with multiple items).
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* dont_compress: 1 bit, boolean, used for preventing compression of entry.
* extra: 9 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *entry;
size_t sz; /* entry size in bytes */
unsigned int count : 16; /* count of items in listpack */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* PLAIN==1 or PACKED==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int dont_compress : 1; /* prevent compression of entry that will be used later */
unsigned int extra : 9; /* more bits to steal for future usage */
} quicklistNode;
-
prev,next,与传统链表无异
-
entry、container,如果该 Node 保存的是一个 listpack 指针,那么 container 设置为 PACKED = 2;如果保存的是元素本身,那么 container 设置为 PLAIN
-
encoding,表示该节点保存的元素是否已经被压缩为 LZF 格式。
-
recompress,在使用 quicklist 的时候,可能中途会临时解压缩一个节点,这个 recompress 就是为了把该节点压缩回去而设置的。比如 quicklist 足够长了,遍历到中间的节点,这些节点需要临时解压缩,遍历完该节点后再压缩回去。
-
dont_compress,这是为了避免某些时候该节点被压缩了。设置它的原因是,作者复用某些函数的时候,这些函数会自动压缩节点。
quicklistNode *split_node = NULL, *new_node;
node->dont_compress = 1; /* Prevent compression in __quicklistInsertNode() */
/* If the entry is not at the tail, split the node at the entry's offset. */
if (entry->offset != node->count - 1 && entry->offset != -1)
split_node = _quicklistSplitNode(node, entry->offset, 1);
/* Create a new node and insert it after the original node.
* If the original node was split, insert the split node after the new node. */
new_node = __quicklistCreateNode(isLargeElement(sz, quicklist->fill) ?
QUICKLIST_NODE_CONTAINER_PLAIN : QUICKLIST_NODE_CONTAINER_PACKED, data, sz);
__quicklistInsertNode(quicklist, node, new_node, 1);
- attempt_compress,debug 用的。
各种插入操作
个人认为插入操作真的很复杂。
三个比较复杂的 Push
int quicklistPushHead(quicklist *quicklist, void *value, const size_t sz);
int quicklistPushTail(quicklist *quicklist, void *value, const size_t sz);
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where);
Push 实际上是对 PushHead 和 PushTail 的 Wrapper,所以它的 where 只有两个取值:QUICKLIST_HEAD 和 QUICKLIST_TAIL,PushHead 又和 PushTail 相似。以 PushHead 为例子,做的事情无非是:
- 如果新元素是大元素,插入新节点,递增 count。
- 如果新元素是小元素,如果 head 可以继续插入值,插入到 head 中,否则创建新 listpack 再插入,递增 count。这里说 head 可以继续插入值,意思是 head 必须是 listpack 格式,且 listpack 可以插入值。另一种 plain 格式是不行的。
两个简单的 Node Append
void quicklistAppendListpack(quicklist *quicklist, unsigned char *zl);
void quicklistAppendPlainNode(quicklist *quicklist, unsigned char *data, size_t sz);
节点操作,和链表没什么大差别。
两个复杂的 Insert
void quicklistInsertAfter(quicklistIter *iter, quicklistEntry *entry,
void *value, const size_t sz);
void quicklistInsertBefore(quicklistIter *iter, quicklistEntry *entry,
void *value, const size_t sz);
它们都调用了 _quicklistInsert(iter, entry, value, sz, where)
为什么说 Insert 复杂?根本原因是:quicklist 中任意节点,可能是 plain 格式的,也可能是 listpack 格式的,而 listpack 格式包含多个元素,插入可能是插入到 listpack 中间的某个位置。如果是大元素,可能需要分割 listpack。
所以就分为很多种情况:
- 新元素是大元素
a. iter 指向的位置是 plain,此时与传统链表无异
b. iter 指向的位置是 listpack,此时要考虑是否分割 listpack,即如果是 listpack 头、尾的插入,就不需要分割。 - 新元素是小元素
a. iter 指向 plain,此时要考虑它前后是否是 listpack,能否插入,不能的话需要创建新节点
b. iter 指向的 listpack 没有满,此时插入到该 listpack 即可
c. iter 指向的 listpack 满了,此时需要考虑 listpack 前后是否是 listpack,它们能否继续插入值,插入位置是不是 listpack 头、尾(因为这关乎是否要分割 listpack,分割的话还要考虑是否和周围的 listpack 合并)。
所以说非常复杂……
值得一提的是,代码中为了避免用户误用 iter,在 Insert 结束后重置了 iter,这是个值得参考的技巧。
比较复杂的 Replace
Replace 的声明如下:
void quicklistReplaceEntry(quicklistIter *iter, quicklistEntry *entry,
void *data, size_t sz);
int quicklistReplaceAtIndex(quicklist *quicklist, long index, void *data,
const size_t sz);
ReplaceAtIndex 实际上是对 ReplaceEntry 的 wrapper。
ReplaceEntry 要考虑的情况有:
- replace 的新元素是大元素
a. iter 指向的是 plain,做传统链表操作
b. iter 指向的是 listpack,此时要考虑是否分割 listpack - replace 的新元素是小元素
a. iter 指向的是 plain,此时要考虑前后是否是 listpack,它们可以 replace 吗
b. iter 指向的是 listpack,此时要考虑它是否可以 replace,如果不可以还需要考虑借用前后的 listpack,否则还是要新建一个节点。
listpack 能否 replace?咋一看它总是成功的,但作者不这么认为。以下是注释:
} else { /* The node is full or data is a large element */
感觉这里的 full 意思没有表达完整。listpack 是否满,有两个条件:
- listpack 是否用完了 4GB
- listpack 中是否有 2^16 个元素
大元素和小元素的界限可能达到65536(2^16),而 listpack 还需要额外记录一些元数据,所以这种考虑是正确的。
一样,结束的时候还 reset 了 iter。
迭代遍历
迭代遍历的迭代器结构体如下:
typedef struct quicklistIter {
quicklist *quicklist;
quicklistNode *current;
unsigned char *zi; /* points to the current element */
long offset; /* offset in current listpack */
int direction;
} quicklistIter;
这个迭代器似乎记录了多余的元素:zi 和 offset 的作用有点重复,zi 可以指向 Plain,也可以指向 listpack 中的某个元素。个人认为只要有 zi 就够了,listpack 可以根据指针获取到下一个或者上一个元素。但是不过一个迭代器而已,多占一点空间也无所谓,因为它是临时的。
迭代的时候会把元素的值设置到 quicklistEntry。
值得提的有两点:
- 利用迭代器的操作,“上一个元素”和“下一个元素”的含义是相对的。它不是链表中或数组中表示的上一个或者下一个,而是与迭代方向相关。
如果是正向遍历,它的下一个节点的意思就是 node->next,如果是反向,则是 node->prev。因此我们可以看到这样的用法:
if (iter->direction == AL_START_HEAD) {
nextFn = lpNext;
offset_update = 1;
} else if (iter->direction == AL_START_TAIL) {
nextFn = lpPrev;
offset_update = -1;
}
iter->zi = nextFn(iter->current->entry, iter->zi);
iter->offset += offset_update;
- 利用递归进行代码复用
在代码中我们可以找到这一行:
int quicklistNext(quicklistIter *iter, quicklistEntry *entry) {
...
if (iter->zi) {
} else {
...
return quicklistNext(iter, entry);
...
}
这里就是一个递归,但是只会递归一次。仅当当前节点是 listpack 且遍历完毕后才会触发。
如果我来写,我可能更加偏向于用自动机的方式。
删除操作
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry);
int quicklistDelRange(quicklist *quicklist, const long start, const long stop);
REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,
unsigned char **p) {
int gone = 0;
if (unlikely(QL_NODE_IS_PLAIN(node))) {
__quicklistDelNode(quicklist, node);
return 1;
}
node->entry = lpDelete(node->entry, *p, p);
node->count--;
if (node->count == 0) {
gone = 1;
__quicklistDelNode(quicklist, node);
} else {
quicklistNodeUpdateSz(node);
}
quicklist->count--;
/* If we deleted the node, the original node is no longer valid */
return gone ? 1 : 0;
}
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
/* after delete, the zi is now invalid for any future usage. */
iter->zi = NULL;
/* If current node is deleted, we must update iterator node and offset. */
if (deleted_node) {
if (iter->direction == AL_START_HEAD) {
iter->current = next;
iter->offset = 0;
} else if (iter->direction == AL_START_TAIL) {
iter->current = prev;
iter->offset = -1;
}
}
/* else if (!deleted_node), no changes needed.
* we already reset iter->zi above, and the existing iter->offset
* doesn't move again because:
* - [1, 2, 3] => delete offset 1 => [1, 3]: next element still offset 1
* - [1, 2, 3] => delete offset 0 => [2, 3]: next element still offset 0
* if we deleted the last element at offset N and now
* length of this listpack is N-1, the next call into
* quicklistNext() will jump to the next node. */
}
删除操作中被注释起来的 else if 有点妙。如果删除的是 listpack 中间的某个元素,此时不需要调整 offset,zi 也不需要。
删除操作进行后依然可以继续用那个传入的迭代器。
好像有点多余的 Rotate
Rotate 不是说把整个链表全部都给翻转过来,它只把尾节点移动到头罢了。注释也是这么写的。所以似乎是为了把它当成环形链表用而预备的一个函数(我确实没找到哪里调用了它)。
/* Rotate quicklist by moving the tail element to the head. */
void quicklistRotate(quicklist *quicklist) {
...
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号