
Skiplist 学校是不教的,《算法导论》上也没有,所以有一个印象深刻的图来解释似乎更合适。
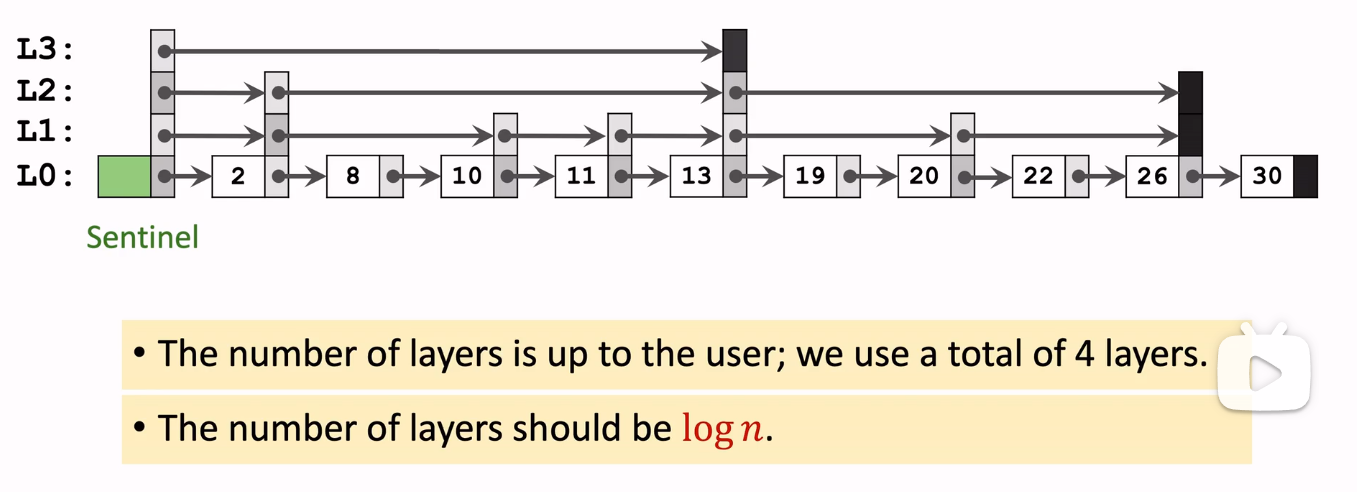
有一个视频大致介绍了跳表(虽然实现上和redis的跳表不一样,但是至少是比较像的)
https://www.bilibili.com/video/av930970170/
Redis 的跳表一共涉及到以下的结构体。因为它只支持 sds 类型字符串,以及 double 类型的 score,所以它不是泛型的。
zskiplistNode 中,backward 可以简单理解为链表中的 prev 指针,而 level 表示的就是上图的每个节点的每个 L0, L1, L2... 故而 forward 简单理解为每一层的 next 指针,而 span 表示的就是它到下一个节点的距离(如上图节点 2 的 L1 的 span 就是 2)。如果 forward == NULL,那就是其后面还有几个节点(如上图节点 13 L3 的 span 就是 5)。如果一个 skiplist 只有 level[0],那么该跳表就相当于普通链表了。
zskiplist 中,length 就是跳表一共有多少节点,level 就是当前跳表最高有几层。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
Redis 为什么选择了跳表而不是某种平衡树?以下是作者 antirez 所说。简单总结就是(结合源代码的意译),首先 skiplist 不是很占内存,而且占多少内存你可以手动调整 zslRandomLevel(void),其次对链表范围查找,跳表至少会和其他平衡树表现一样好,已排序集合而言常常要做很多范围查找,最后它实现简单,debug 容易。
https://news.ycombinator.com/item?id=1171423
跳表创建
跳表创建会生成一个有 32 层的头节点(ZSKIPLIST_MAXLEVEL 是 32,不论怎么样也不会超过 32 层),但是 32 层中暂时只有 level[0] 是有效的。默认 32 层是为了避免对头节点 realloc。
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
跳表插入值
插入值的代码略长,个人觉得与其解释其代码,还不如形象具体地解释其中的局部变量的作用。
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // update 记录所有需要更新的节点
unsigned long rank[ZSKIPLIST_MAXLEVEL]; // rank 到达需要更新的节点,有多少节点
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward && // 不是最后一个
(x->level[i].forward->score < score || // 找比 score/element 大的
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel(); // level 不可能小于等于 0
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
update 是一个指针数组,记录的是插入值后需要更新的所有节点。rank[i] 则是到达 update[i] 所需要经过的节点数量,可以简单理解为 rank[i] 是 update[i] 节点的下标。这种解释是不形象具体的,所以下面是更加好一点的解释。
为了简化绘图,每一个节点都会按照右边的方式绘制,左边是它原来的样子。
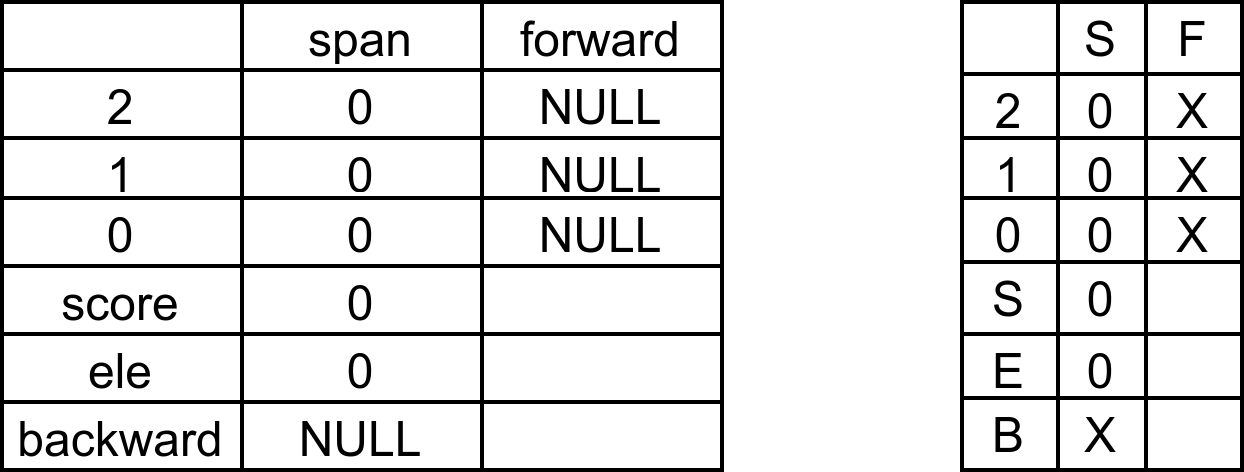
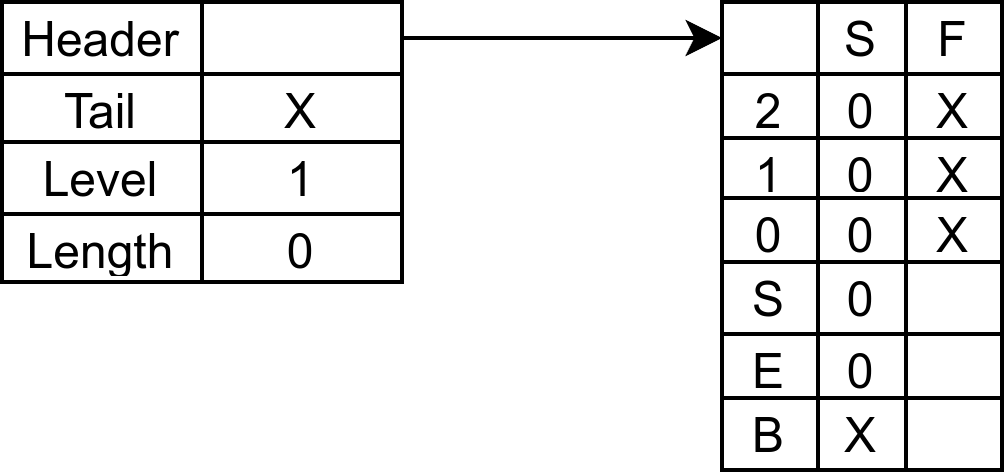
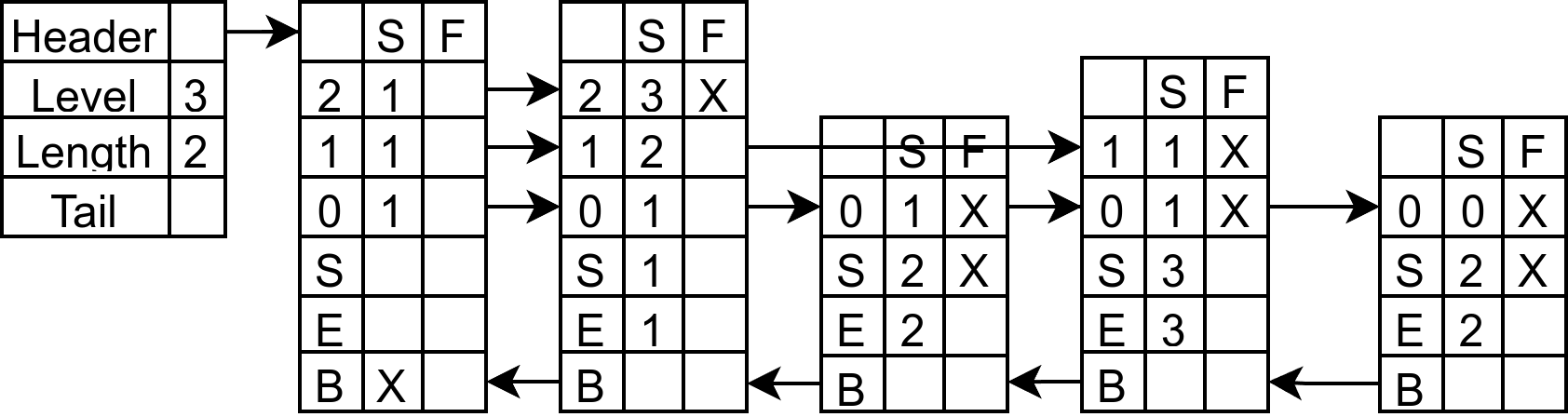
下图是初始化后(zslCreate)的结果:
对下面的 skiplist 插入 score = 4, ele = 4, 高度为 1:
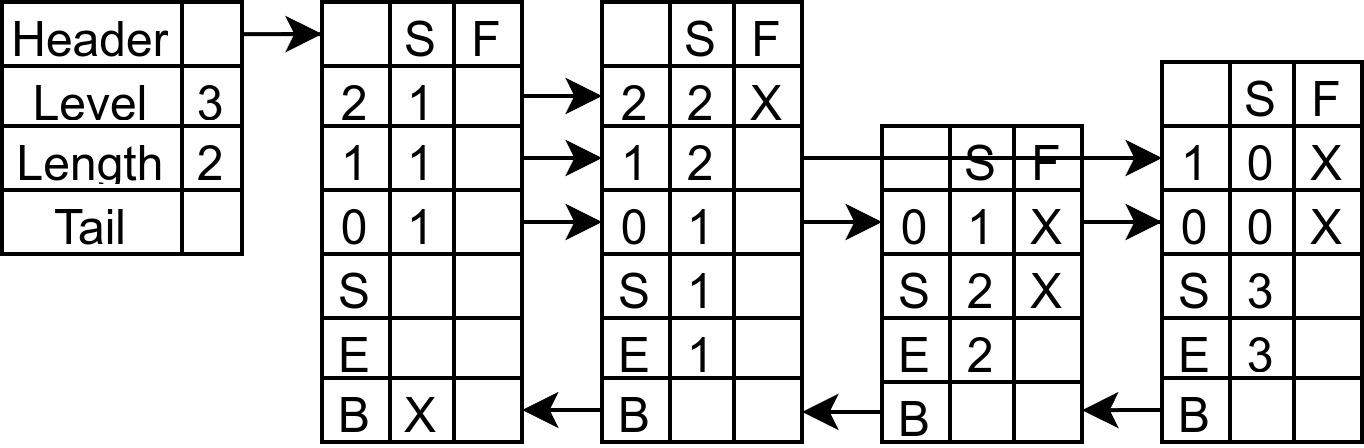
毫无疑问,新插入的节点必然是在 3 之后的,你站在 3 之后观察,会发现第 0 层能够看到的第一个节点是 3,第 0 层被 3 挡住的有三个节点,所以 update[0] 是节点 3,rank[0] 是 3。
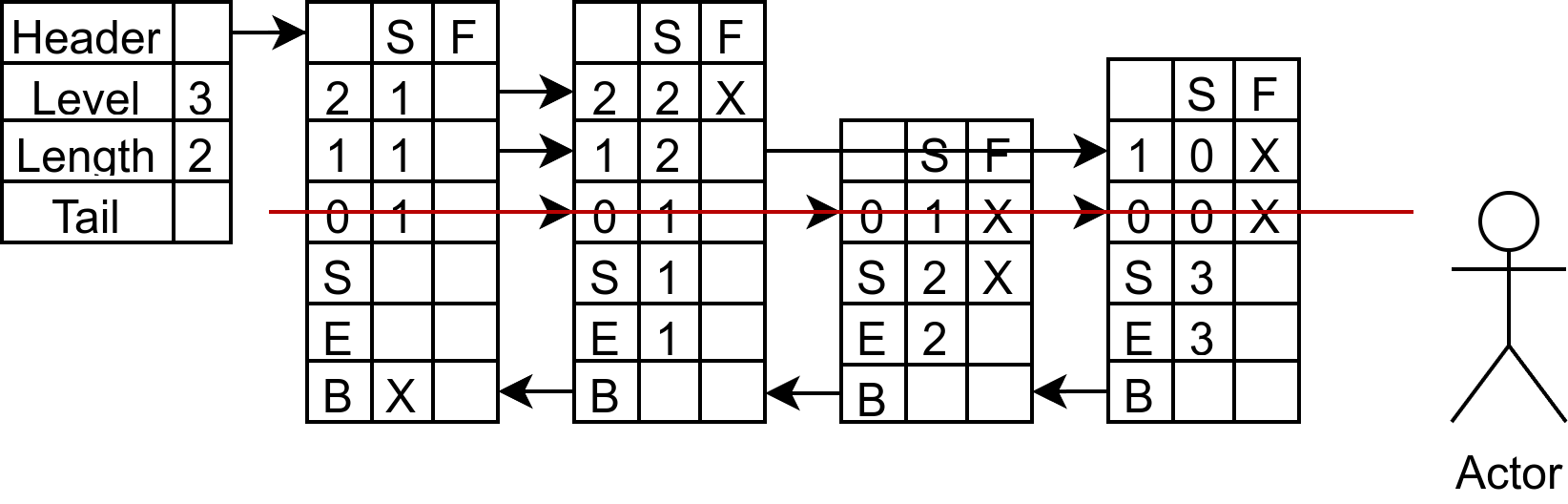
同样的,第一层能够看到的是节点 3,被挡住的有 3 个节点。所以 update[1] 是节点 3,rank[1] 是 3。
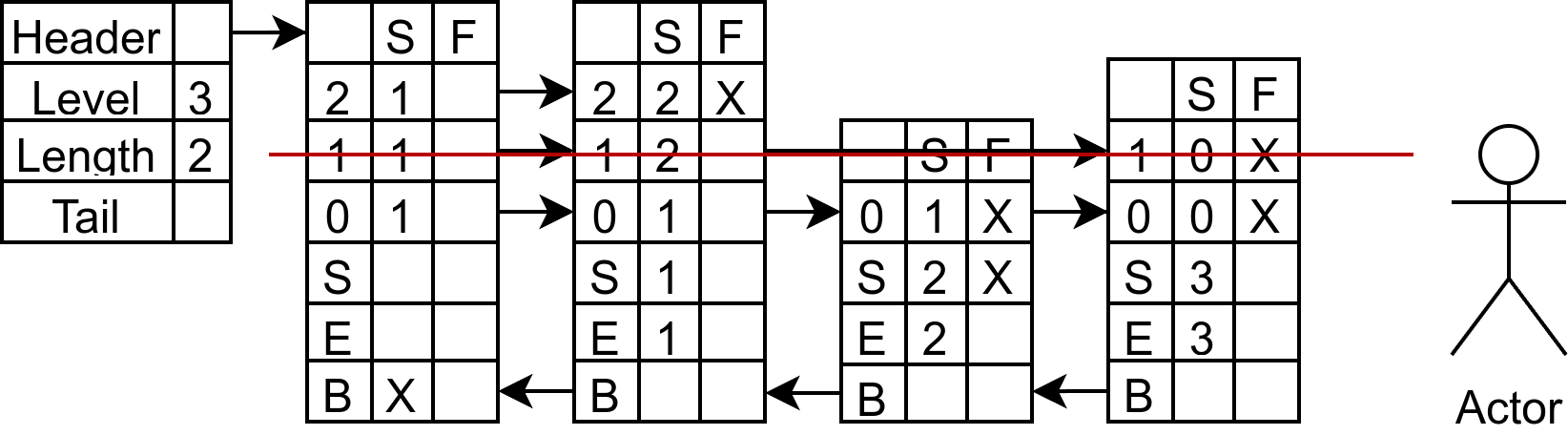
同样的,第二层能够看到的是节点 1,被挡住的有 1 个节点。所以 update[2] 是节点 1,rank[2] 是 1。
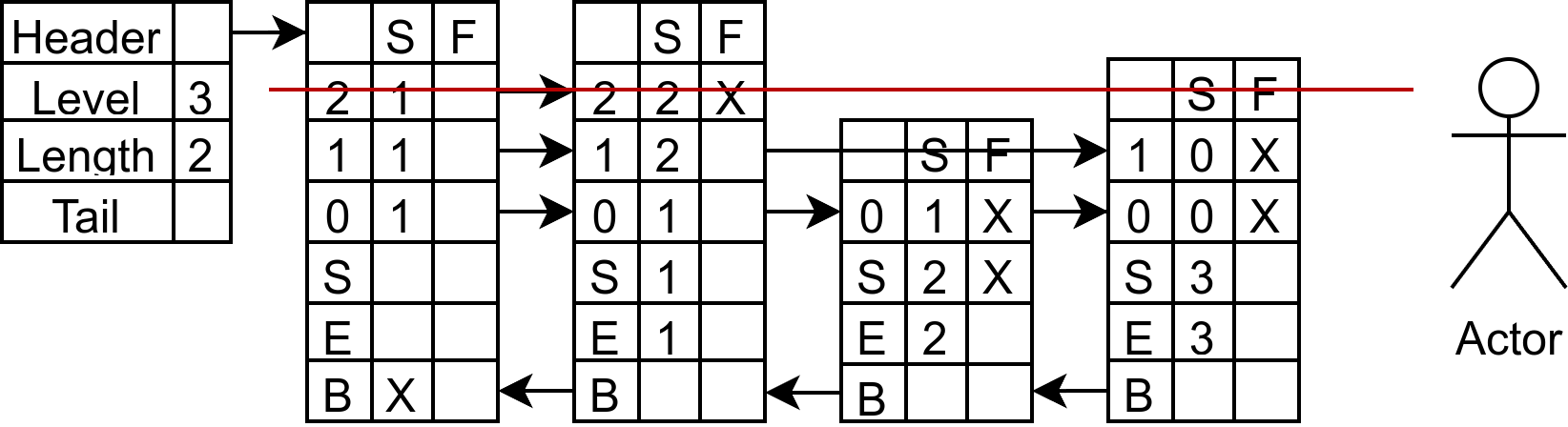
现在放置创建的节点 (4, 4),利用记录的 rank,更新各个 update 的 span 和 forward。rank[0] 的另一个意思是update[i]前方一共有几个节点,相当于记录一个链表中某个节点前方有多少个节点。所以 rank[i] - rank[0] 这种做法相当于对前缀和求某个区间的和。而 + 1 的原因纯粹就是因为是新插入节点所以需要 + 1。所以节点 1 L2 更新 span 为 3,3 的 L1、L0 更新为 1。其他的不过是常见链表的操作罢了。
跳表节点删除
删除依然需要用上刚刚说的 update。因为是移除,各层只要减一即可(这是 zslDeleteNode 做的事情)。所以依然是边找节点边构造 update,然后删除。
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
Range 操作
range 操作就是 zrange 一系列指令。
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]
在没有指定 byscore 和 bylex 的时候,就是按照下标查找的(byrank)。据官方文档说,bylex 需要确保所有的 score 都是相同的,但实际似乎只要保证 score 和 ele 同步递增就行了——因为其实现就是这样的。
如果是按顺序返回,它们都首先执行找到第一个符合条件的节点,然后由调用它们的函数,遍历节点,把结果写入 handler。逆序类似。如:
if (reverse) {
ln = zslNthInRange(zsl,range,-offset-1);
} else {
ln = zslNthInRange(zsl,range,offset);
}
while (ln && limit--) {
/* Abort when the node is no longer in range. */
if (reverse) {
if (!zslValueGteMin(ln->score,range)) break;
} else {
if (!zslValueLteMax(ln->score,range)) break;
}
rangelen++;
handler->emitResultFromCBuffer(handler, ln->ele, sdslen(ln->ele), ln->score);
/* Move to next node */
if (reverse) {
ln = ln->backward;
} else {
ln = ln->level[0].forward;
}
}
byrank
byrank 就是前文插入操作计算 rank 的步骤。唯一不同就是它不需要比较 score 和 ele。
zskiplistNode *zslGetElementByRankFromNode(zskiplistNode *start_node, int start_level, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = start_node;
for (i = start_level; i >= 0; i--) {
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
if (traversed == rank) {
return x;
}
}
return NULL;
}
至于 reverse,不过是 len - 需要找到的 rank 罢了
void genericZrangebyrankCommand(zrange_result_handler *handler,
robj *zobj, long start, long end, int withscores, int reverse) {
...
ln = zslGetElementByRank(zsl,llen-start);
...
ln = zslGetElementByRank(zsl,start+1);
...
byscore
byscore 依然类似于前面的查找。找到第一个大于 start 的节点,然后遍历到 stop。处理 offset 比较简单,故而省略。
zskiplistNode *zslNthInRange(zskiplist *zsl, zrangespec *range, long n) {
... // 找最高层第一个大于 start 的。之所以单独遍历最高层,是为了处理 offset。
while (x->level[i].forward && !zslValueGteMin(x->level[i].forward->score, range)) {
edge_rank += x->level[i].span;
x = x->level[i].forward;
}
/* Remember the last node which has zsl->level-1 levels and its rank. */
last_highest_level_node = x;
last_highest_level_rank = edge_rank;
if (n >= 0) {
// 找范围指定的第一个
for (i = zsl->level - 2; i >= 0; i--) {
/* Go forward while *OUT* of range. */
while (x->level[i].forward && !zslValueGteMin(x->level[i].forward->score, range)) {
/* Count the rank of the last element smaller than the range. */
edge_rank += x->level[i].span;
x = x->level[i].forward;
}
}
... // 处理 offset
} else {
// 找范围指定的最后一个
for (i = zsl->level - 1; i >= 0; i--) {
/* Go forward while *IN* range. */
while (x->level[i].forward && zslValueLteMax(x->level[i].forward->score, range)) {
/* Count the rank of the last element in range. */
edge_rank += x->level[i].span;
x = x->level[i].forward;
}
}
... // 处理 offset
}
bylex
bylex,就是按照字典序排序。前文说官方文档要求 score 必须与 ele 一同递增。简单解释就是查找的方式依然是匹配第一个可以匹配的,然后以此为基点继续找第一个未匹配的。所以就无法处理多个 score 的情况。但是 score 和 ele 同步递增的情况是可以的。因为 ele 随着 score 排序而变得有顺序。
zskiplistNode *zslNthInLexRange(zskiplist *zsl, zlexrangespec *range, long n) {
... // 几乎和 byscore 一样
while (x->level[i].forward && !zslLexValueGteMin(x->level[i].forward->ele, range)) {
edge_rank += x->level[i].span;
x = x->level[i].forward;
}
/* Remember the last node which has zsl->level-1 levels and its rank. */
last_highest_level_node = x;
last_highest_level_rank = edge_rank;
...
if (n >= 0) {
for (i = zsl->level - 2; i >= 0; i--) {
/* Go forward while *OUT* of range. */
while (x->level[i].forward && !zslLexValueGteMin(x->level[i].forward->ele, range)) {
/* Count the rank of the last element smaller than the range. */
edge_rank += x->level[i].span;
x = x->level[i].forward;
}
}
... // 处理 offset
} else {
for (i = zsl->level - 1; i >= 0; i--) {
/* Go forward while *IN* range. */
while (x->level[i].forward && zslLexValueLteMax(x->level[i].forward->ele, range)) {
/* Count the rank of the last element in range. */
edge_rank += x->level[i].span;
x = x->level[i].forward;
}
}
... // 处理 offset
}
range delete
三种 range delete 几乎是一样的。
unsigned long zslDeleteRangeByScore(zskiplist *zsl, zrangespec *range, dict *dict) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long traversed = 0, removed = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward && (traversed + x->level[i].span) < start) {
traversed += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
traversed++;
x = x->level[0].forward;
while (x && traversed <= end) {
zskiplistNode *next = x->level[0].forward;
zslDeleteNode(zsl,x,update);
dictDelete(dict,x->ele);
zslFreeNode(x);
removed++;
traversed++;
x = next;
}
return removed;
跳表节点更新
更新操作没什么特别的,先找到要更新的节点,删除它,再插入新值。
zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore) {
... // 几乎与插入一样的查找,记录 update。
/* Jump to our element: note that this function assumes that the
* element with the matching score exists. */
x = x->level[0].forward;
serverAssert(x && curscore == x->score && sdscmp(x->ele,ele) == 0);
/* If the node, after the score update, would be still exactly
* at the same position, we can just update the score without
* actually removing and re-inserting the element in the skiplist. */
if ((x->backward == NULL || x->backward->score < newscore) &&
(x->level[0].forward == NULL || x->level[0].forward->score > newscore))
{
x->score = newscore;
return x;
}
/* No way to reuse the old node: we need to remove and insert a new
* one at a different place. */
zslDeleteNode(zsl, x, update);
zskiplistNode *newnode = zslInsert(zsl,newscore,x->ele);
/* We reused the old node x->ele SDS string, free the node now
* since zslInsert created a new one. */
x->ele = NULL;
zslFreeNode(x);
return newnode;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号