

Redis的哈希表相对而言比较复杂,与其展示过多的源码,还不如解释其中的想法。
模型
Redis 的哈希表与 C++ 的不同(可以见我的博客),它内部是有多个链表的,每个链表都以 NULL 结尾。
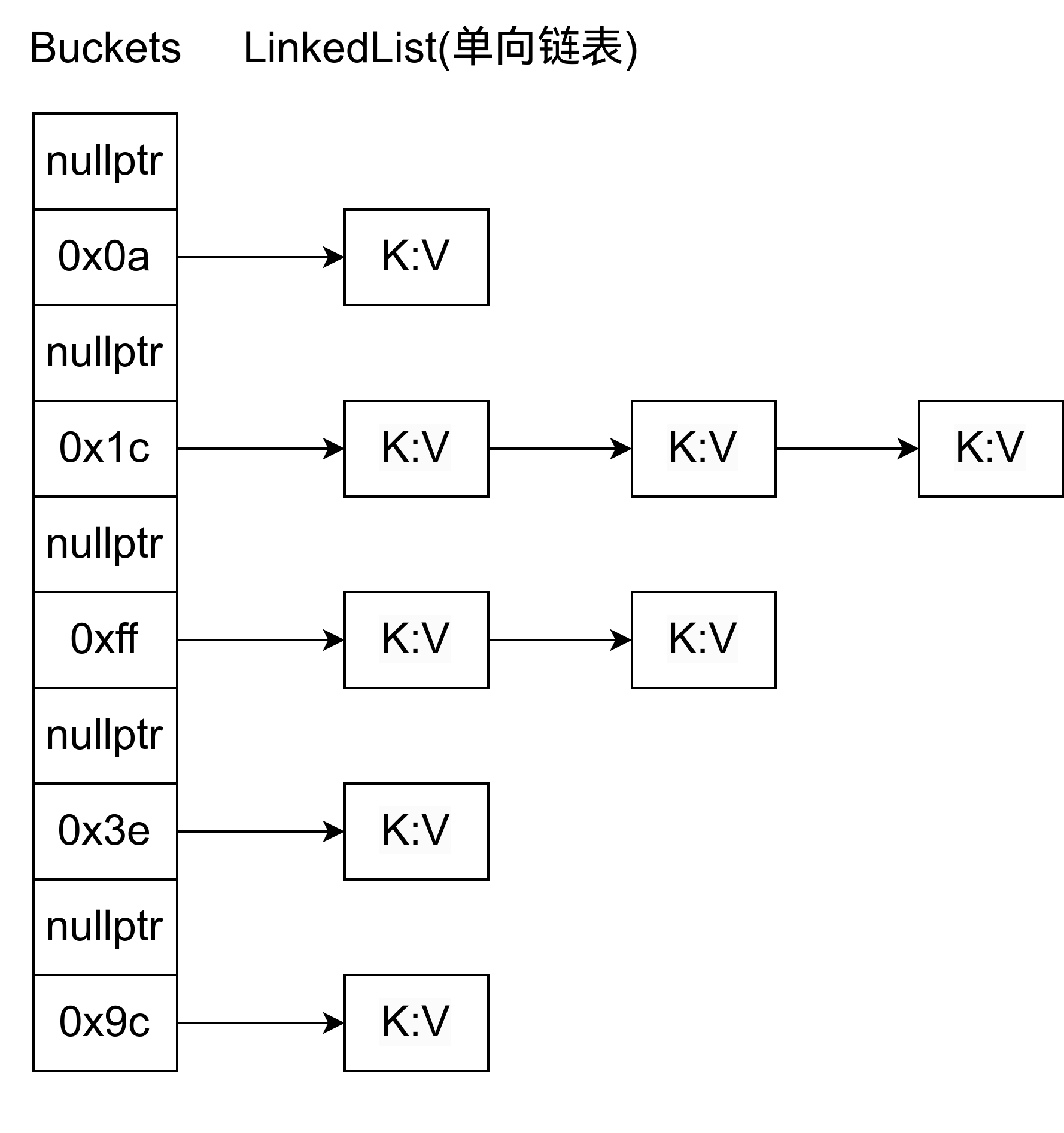
哈希表的定义是:
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
unsigned pauserehash : 15; /* If >0 rehashing is paused */
unsigned useStoredKeyApi : 1; /* See comment of storedHashFunction above */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
int16_t pauseAutoResize; /* If >0 automatic resizing is disallowed (<0 indicates coding error) */
void *metadata[];
};
其中 type 指针用于实现泛型,ht_table[2]、ht_used[2]、rehashidx用于实现渐进式 Rehash,pauserehash 在遍历的时候会用上。
特点1: 通用的泛型哈希表
dictType 包括了 hashFunction、keyCompare、key/value Copy(dup)、key/value Deconstructor、keys_are_odd(用于优化存储)、no_value(也是用于优化存储)。除此之外还有 userdata,报告 rehash 进度的两个回调函数等。
keyCompare、hashFunction是最关键的,其他的根据需要给定即可。
特点2: 渐进式 Rehash
据说许多哈希表都有渐进式 rehash,比如 go、absl::flat_hash_map。渐进式 Rehash,是逐步迁移哈希表中的条目,主要优点是在哈希表扩展期间避免了长时间的阻塞。
Rehash 在 _dictResize 中触发。rehash 一旦触发,那么新插入的键值对都只会插入到新桶中。
redis 用 rehashidx 和两个 ht_table 来实现渐进式 rehash。
ht_table[0](以下简称 ht0)在 rehash 中是旧表,ht1 则是新表。rehashidx 标记的是 ht0 的 [0, rehashidx] 已经被迁移到 ht1 了。如果 rehashidx == -1,则表示当前没有进行 rehash。
ht0, ht1 的大小都是由 ht_size_exp 表示的。ht0 的大小是 2^ht_size_exp[0],ht1 也是如此。
每次在添加元素、删除元素、查找元素的时候都会推进一次 rehash。以下代码保证了每次操作的都是 ht1。
if (dictIsRehashing(d)) {
if ((long)idx >= d->rehashidx && d->ht_table[0][idx]) {
// 如果在 ht0 中找到了对应的键,则把当前键所在的桶的所有键值对都 rehash 到 ht1
_dictBucketRehash(d, idx);
} else {
// 如果找不到,就只推进一次 rehash,这里的 RehashStep 在
// pause rehash 的时候是无效的,但是上面的 dictBucketRehash 是会进行 Rehash 的。
// static void _dictRehashStep(dict *d) {
// if (d->pauserehash == 0) dictRehash(d,1);
// }
_dictRehashStep(d);
}
}
特点3: 内存存储优化
整数、浮点数、无符号整数存储优化
Redis 的哈希表额外提供了几个函数
void dictSetKey(dict *d, dictEntry* de, void *key);
void dictSetVal(dict *d, dictEntry *de, void *val);
void dictSetSignedIntegerVal(dictEntry *de, int64_t val);
void dictSetUnsignedIntegerVal(dictEntry *de, uint64_t val);
void dictSetDoubleVal(dictEntry *de, double val);
int64_t dictIncrSignedIntegerVal(dictEntry *de, int64_t val);
uint64_t dictIncrUnsignedIntegerVal(dictEntry *de, uint64_t val);
double dictIncrDoubleVal(dictEntry *de, double val);
他们分别操作的是 dictEntry 的 union 中的不同类型。
struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* Next entry in the same hash bucket. */
};
这样存储整数时就不需要一个额外的指针了。
set 类型优化
dictEntry 同时具有键值对,而值对于一个集合而言是没有必要的。所以 Redis 还有一个结构体,名为 dictEntryNoValue
typedef struct {
void *key;
dictEntry *next;
} dictEntryNoValue;
同时还是利用 malloc 获得的指针没有低 3 位的特性,使用了 0x2
#define ENTRY_PTR_MASK 7 /* 111 */
#define ENTRY_PTR_NORMAL 0 /* 000 */
#define ENTRY_PTR_NO_VALUE 2 /* 010 */
sds 类型存储优化
Redis 会对 sds 集合类型进行内存压缩。Redis 会直接把 sds 指针当做 dictEntry 指针存储到桶里面,而不是专门 alloc 一个新的 dictEntry。它依赖于既定事实:
- sds 类型是一个指针,这些指针都是奇数。如一个 sds 表示为 0x00ffff01。
首先,malloc 返回值都是一个可以被 8 整除的地址。这表明了这些地址的低 3 位都是 0。其次 sds 的 header 长度都是奇数。最后 sds 指向的都是 buf 域。
struct __attribute__ ((__packed__)) sdshdr5 {
// 低三位是类型,高5位表示字符串长度。这里5表示的是字符串最长长度是2^5。
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
-
集合类型不需要 value 域
-
DICT_RESIZE_ENABLE 模式下,哈希表中大多数桶中只有一个键
if ((dict_can_resize == DICT_RESIZE_ENABLE &&
d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0])) ||
(dict_can_resize != DICT_RESIZE_FORBID &&
d->ht_used[0] >= dict_force_resize_ratio * DICTHT_SIZE(d->ht_size_exp[0])))
{
if (dictTypeResizeAllowed(d, d->ht_used[0] + 1))
dictExpand(d, d->ht_used[0] + 1);
return DICT_OK;
}
return DICT_ERR;
到此,满足以下条件则可以优化存储
- 该哈希表是集合
- 存储的指针是奇数
- 目标桶是空桶
所以满足这些条件后,存储 sds 时,不需要新建一个 dictEntry,而是直接存储指针即可。
而假如一个桶不是空桶了,就无法直接用这种存储优化方法,所以就需要 dictEntry 形成一个链表。至于为什么没有指针为偶数的优化,我们可以在源码中找到 TODO,说是能够做这种优化。
* TODO: Add a flag 'keys_are_even' and if set, we can use
* this optimization for these dicts too. We can set the LSB
* bit when stored as a dict entry and clear it again when
* we need the key back. */
但是暂时不做这种优化的原因大概是没必要吧。
相关的 issue 可以见:https://github.com/redis/redis/pull/11595
特点4: 不同级别的 iterator
Redis 的 dictIterator 有两种,一种 safe iterator, 一种是 unsafe iterator。如果是 safe iterator, 那么 iter.safe 设置为 1。如果是 unsafe, 那么 iter.safe = 0, 并且生成 fingerprint, 在释放 iterator 结构体的时候检查 fingerprint。
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
unsigned long long fingerprint;
} dictIterator;
fingerprint 是对当前哈希表信息的一个特征值,作用就是如果你在用 Unsafe iterator 的过程中修改了哈希表,那么在释放这个 iterator 的时候,会再生成特征值,和 iterator 中的 fingerprint 比对。这样的目的是为了避免误用 iterator。
在用 safe iterator 的时候,会递增 dict 的 pauserehash 字段,这个时候 Rehash 被暂停了。而释放则会递减。safe iterator 在遍历的时候是允许修改哈希表的,所以 iterator 会额外记录一个 nextEntry。这样做解决的问题是:如果用户删除了 iter.entry,那么这个时候通过 entry 访问 next 会造成 segment fault。
补充: 新旧表并存的时候如何查找元素的
由于正在 Rehash 时新旧表会同时存在,所以这个时候如何查表时个问题。更大的问题是 Redis 中的写法略微难懂。
void *dictFindPositionForInsert(dict *d, const void *key, dictEntry **existing) {
unsigned long idx, table;
dictEntry *he;
uint64_t hash = dictHashKey(d, key, d->useStoredKeyApi);
if (existing) *existing = NULL;
idx = hash & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
if (dictIsRehashing(d)) {
if ((long)idx >= d->rehashidx && d->ht_table[0][idx]) {
/* If we have a valid hash entry at `idx` in ht0, we perform
* rehash on the bucket at `idx` (being more CPU cache friendly) */
_dictBucketRehash(d, idx);
} else {
/* If the hash entry is not in ht0, we rehash the buckets based
* on the rehashidx (not CPU cache friendly). */
_dictRehashStep(d);
}
}
/* Expand the hash table if needed */
_dictExpandIfNeeded(d);
keyCmpFunc cmpFunc = dictGetKeyCmpFunc(d);
for (table = 0; table <= 1; table++) {
if (table == 0 && (long)idx < d->rehashidx) continue;
idx = hash & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
/* Search if this slot does not already contain the given key */
he = d->ht_table[table][idx];
while(he) {
void *he_key = dictGetKey(he);
if (key == he_key || cmpFunc(d, key, he_key)) {
if (existing) *existing = he;
return NULL;
}
he = dictGetNext(he);
}
if (!dictIsRehashing(d)) break;
}
/* If we are in the process of rehashing the hash table, the bucket is
* always returned in the context of the second (new) hash table. */
dictEntry **bucket = &d->ht_table[dictIsRehashing(d) ? 1 : 0][idx];
return bucket;
}
FindPositionForInsert 是插入键值对的时候调用的函数,hash 计算的结果会用在新旧表上。新旧表的大小不同,但是都是 2 的次方。所以只要对 hash 取低几位即可。
正在 Rehash
在进入到 for 循环之前,前面的 if 语句已经保证旧表中的目标桶所有键值对都已经移动到新表,所以目标键值对要么找不到,要么一定会在新表中。如果 idx < d->rehashidx,毫无疑问必须找新表。如果 idx >= d->rehashidx,此时 he == NULL, !dictIsRehashing(d) == false,那么 table 会递增为 1,此时就在查找新表了。
没有 Rehash
没有 Rehash,那么 d->rehashidx == -1,必然执行 while 循环,!dictIsRehashing(d) == true,不会找新表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号