

 整个哈希表都只有一个链表算不算STL的哈希表的亮点?
整个哈希表都只有一个链表算不算STL的哈希表的亮点?
底层 C++ 哈希表实现原理
有时候英文资料反而会更加高效
这大概是,全中文网站唯一一篇正确解释了 C++ STL 哈希表底层实现的文章。
如果你的编译器中对哈希表的实现不一样,请告知我。我这是 GCC 13.2.1。9.3.0 我也验证过了,它也是这么实现的。
Overview
很多博客中写的 STL 中的链表是这个样子的:
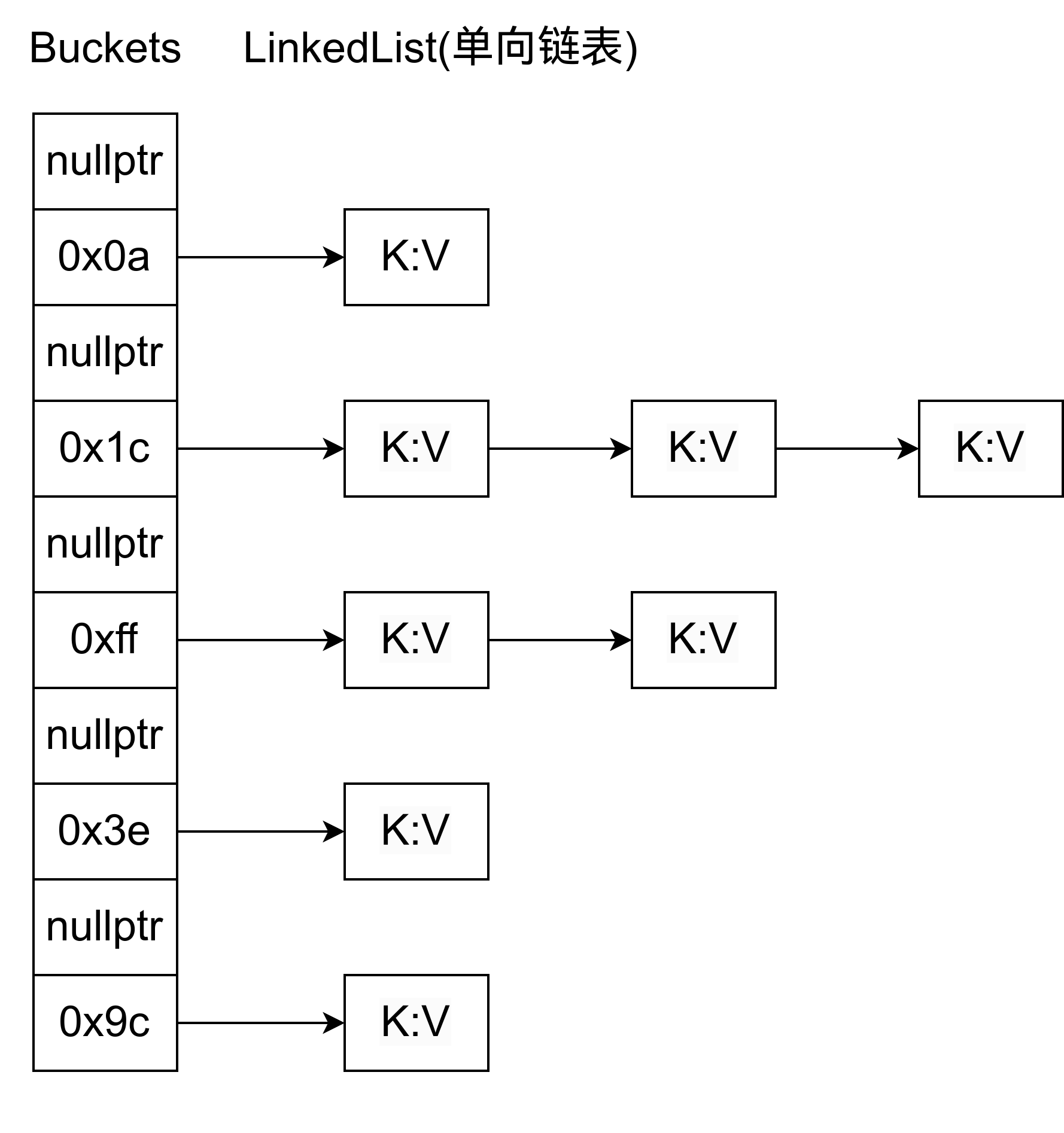
但是实际上是这样子的:
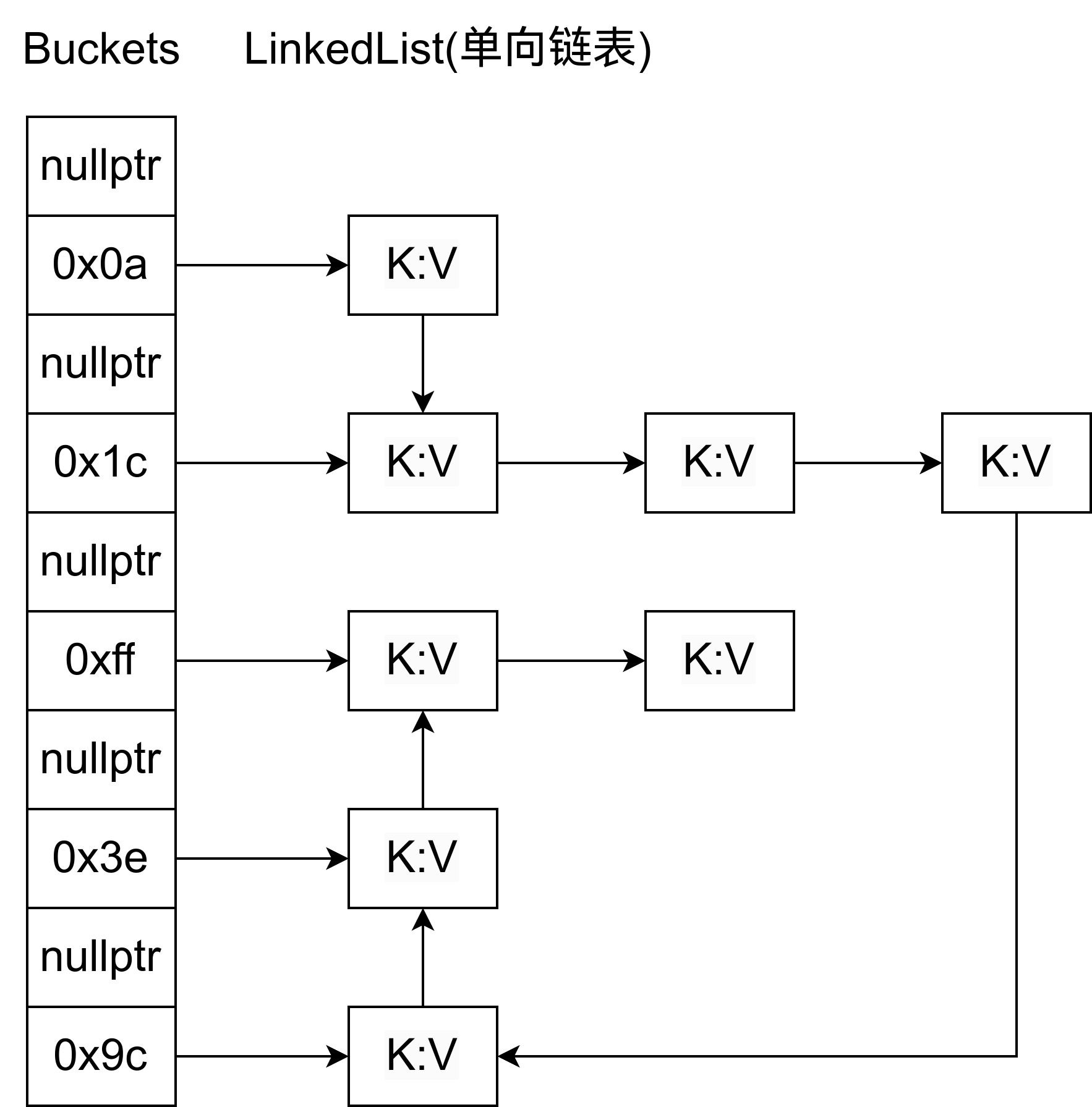
也就是说,实际上,整个哈希表都只有一个链表。
然后它没有redis、golang的渐进式rehash。
确实只有一个链表
写一段简短的代码
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> set;
set.insert(1);
set.insert(2);
set.insert(3);
set.insert(4);
set.insert(5);
for (auto i = set.begin(); i != set.end(); i++) {
std::cout << *i;
}
return 0;
}
编译它,记得加上 -g 参数。然后修改你的 ~/.gdbinit,注释掉:
这一些是为了在调试中跳过所有标准库中的函数而写的配置。如果没有那就不用管。
#skip -gfile /usr/include/*
#skip -rfunction ^std::*
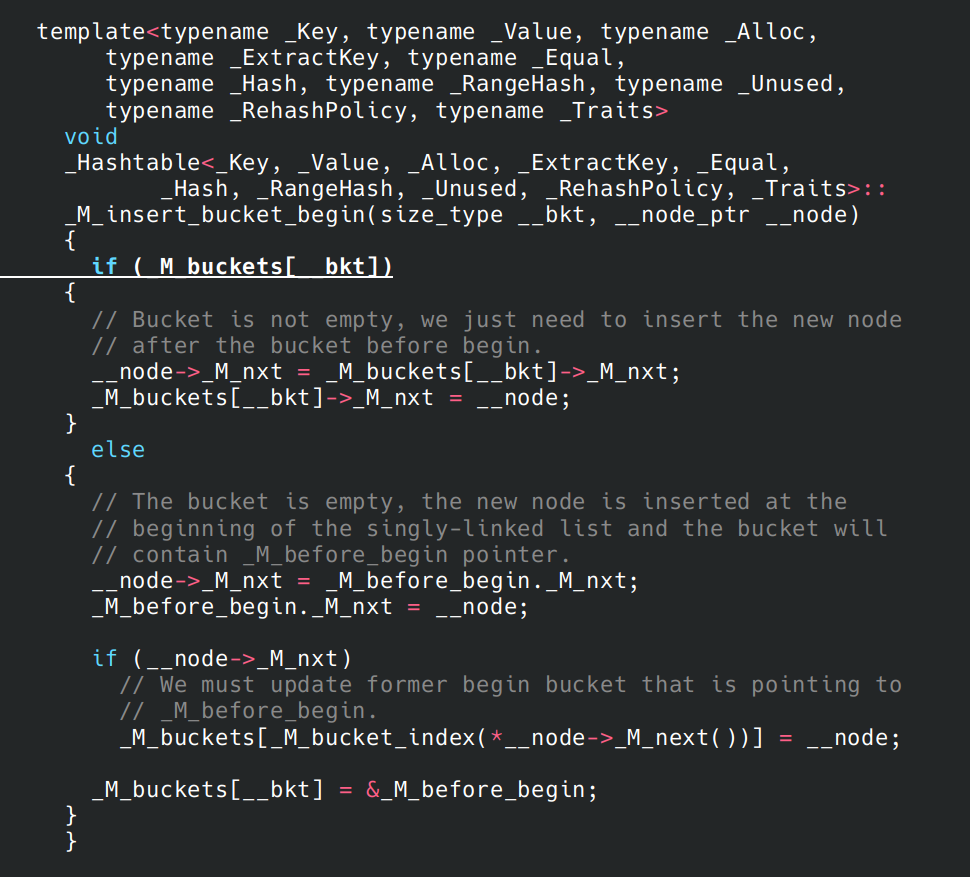
开始调试,执行到插入 5 的时候,step 进入 insert 函数,然后不停 step,直到_Hashtable::_M_insert_bucket_begin。这里给出当前的调用栈。我稍微化简了一点(因为太难看了)
#0 std::_Hashtable::_M_insert_bucket_begin
#1 std::_Hashtable::_M_insert_unique_node
#2 std::_Hashtable::_M_insert_unique
#3 std::_Hashtable::_M_insert_unique_aux
#4 std::_Hashtable::_M_insert
#5 std::__detail::_Insert::insert
#6 std::unordered_set::insert
#7 main
以及你应该看到的源代码。
执行到__node->_M_nxt = _M_before_begin._M_nxt;,输出 __node
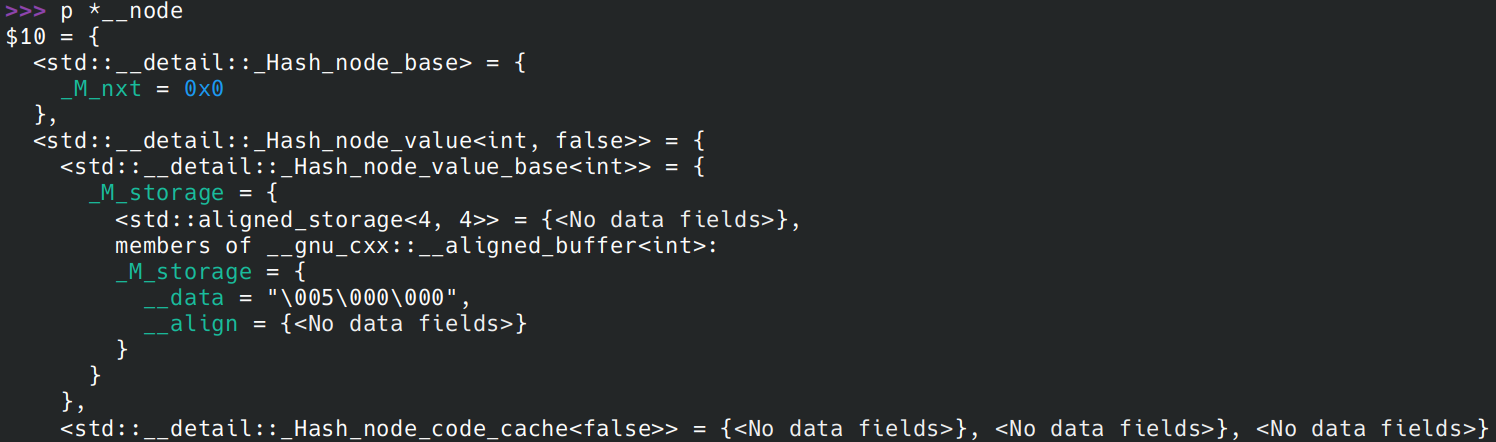
这就是新插入到链表的节点。到此我们输出整个链表,注意里面每一个 __data:
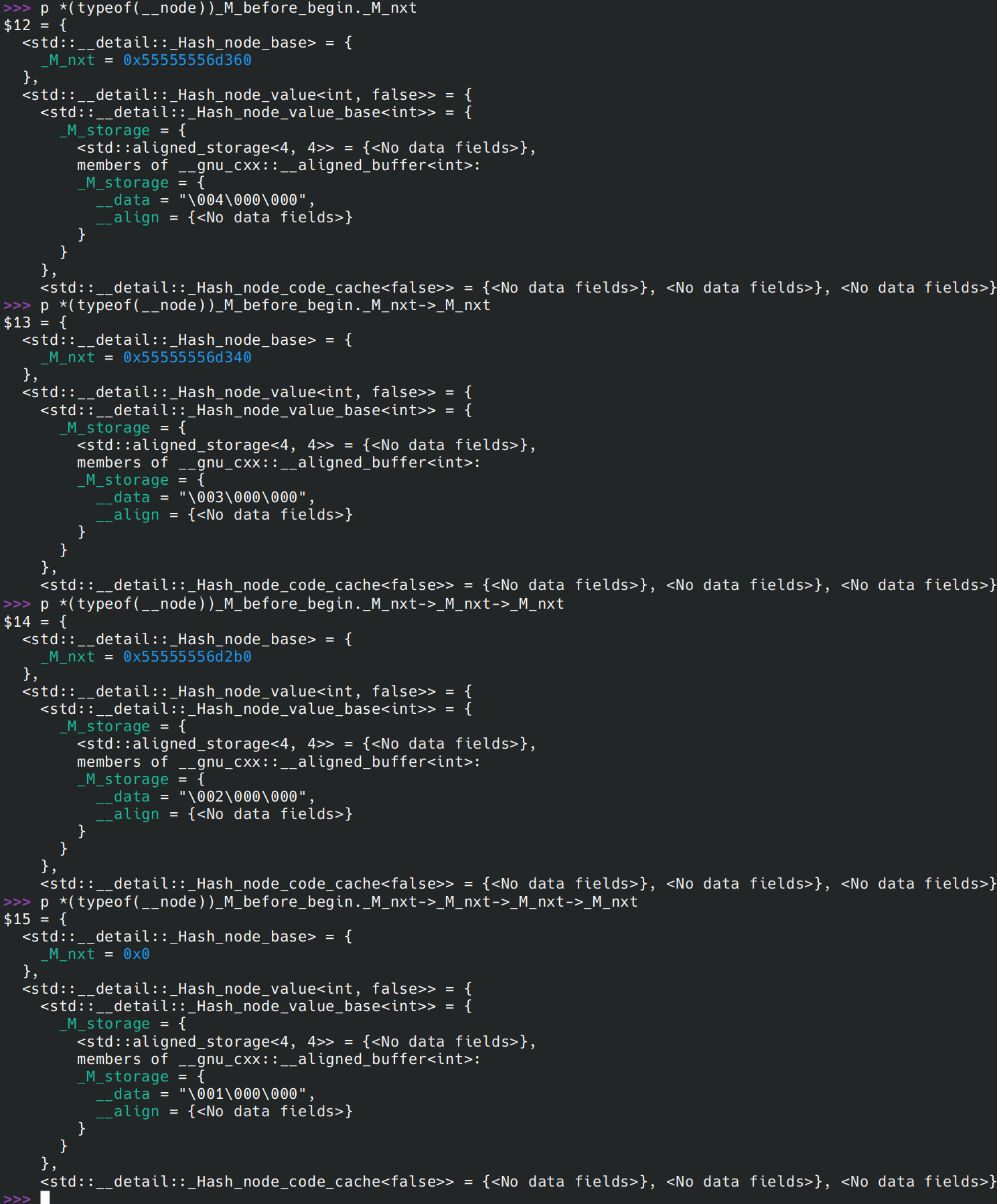
这里*(typeof(__node))_M_before_begin._M_nxt->_M_nxt->_M_nxt->_M_nxt中 typeof 的原因是 gcc 输出值的时候有一个 bug,有时候它无法确定一个指针指向的对象的正确的类型。
目前我还没有找到直接通过解地址的方式正确输出类型的方式。如果 typeof 不可用,这里你可以用 p *(std::__detail::_Hash_node<int, false>*)_M_before_begin
回到源代码。这里 if 里是处理哈希冲突,而 else 是为了处理当前桶为空的情况。if 里处理冲突的方式与传统拉链法没什么很大的区别,但是 else 都是对这整条链表做头插法。所以如果你遍历你的哈希表,且没有发生哈希冲突,那么你会发现你输出的顺序和你插入的顺序,刚好相反。
所以在遍历哈希表的时候,他做的是链表遍历。
补充一下,此处没有出现严重的哈系冲突。下图是输出的 _M_buckets 信息
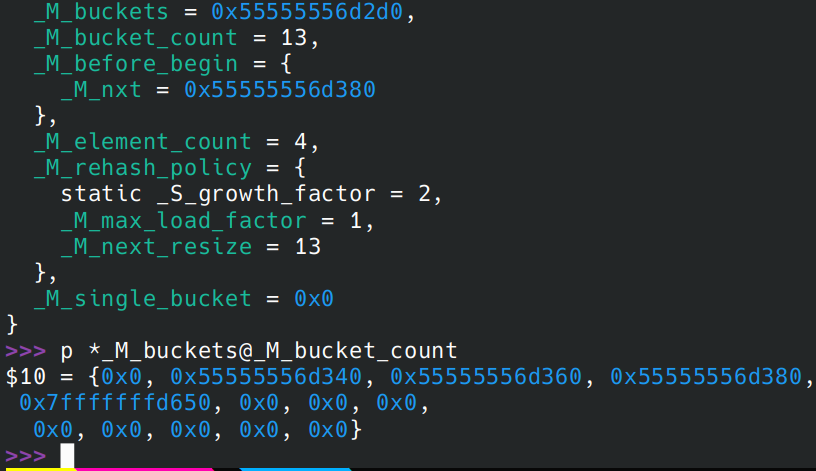
设计目的
以下都是个人猜想。
- 在哈希表比较空的时候,遍历哈希表会很快,因为其时间复杂度不是 O(桶大小 + 链表节点总数),而是 O(链表节点总数)
- 在空间使用上,没有什么代价,除了多了一个
_M_before_begin指针以外。
但是还有一定的代价,代价在于查找的时候的时间代价。
在查找 map[1] 的时候,需要遍历它指向的节点,但是什么时候结束遍历?到某个节点的哈希值,不等于 hash(1) 的时候,才可以确定该值是真的不存在。所以相比传统拉链法而言,它需要算更多次哈希值。
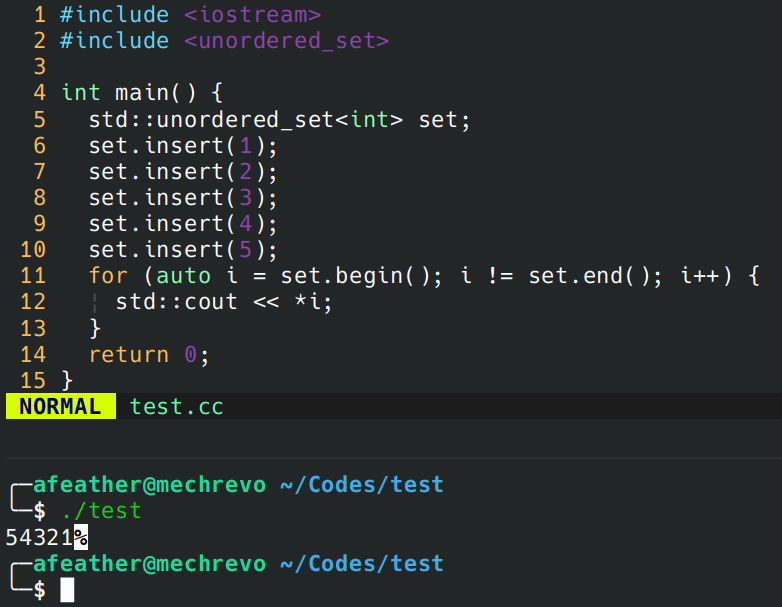
简单地看看是不是这样的。现在改用 unordered_multiset:
set.insert(1);
set.insert(2);
set.insert(15); // 这里我找到了15会和2产生哈希冲突
set.find(2);
执行到 find 里调用的这个函数
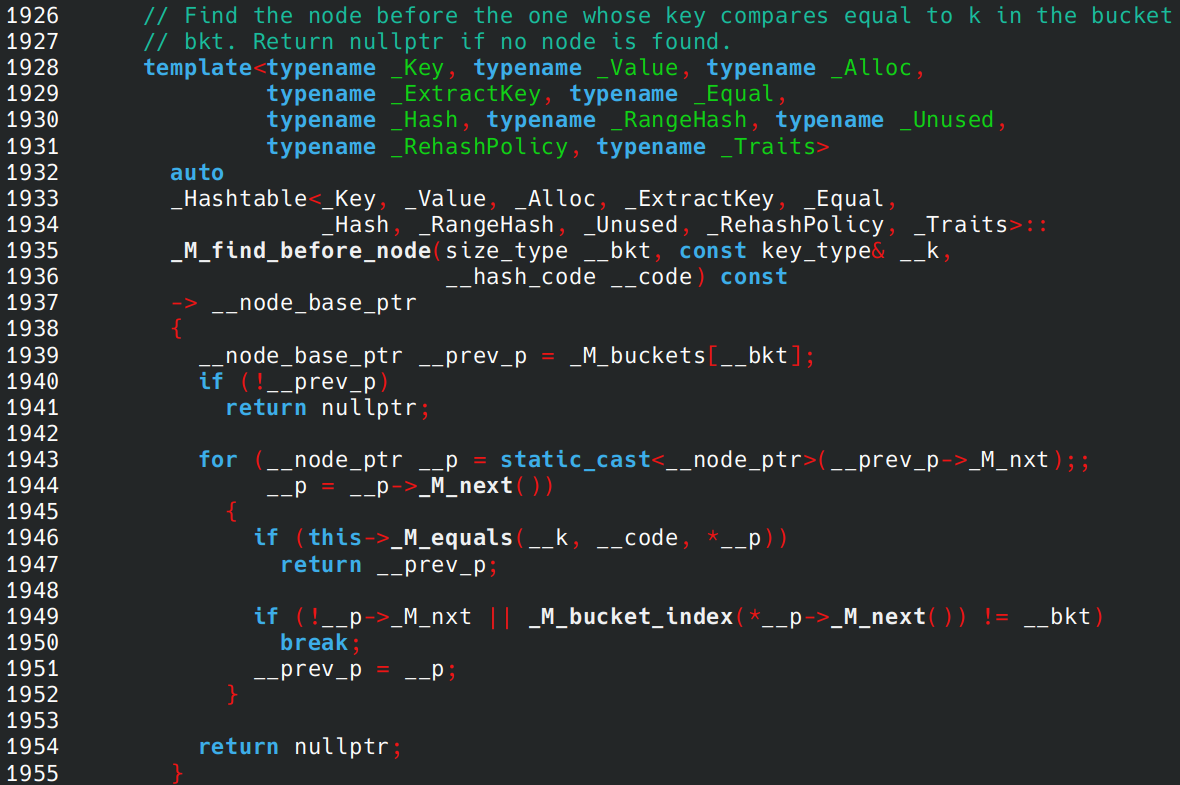
对 _M_bucket_index step,可以看到它最终还是调用了 _M_hash_code,所以除非到最后一个节点,并且遍历过程中没有找到值,它就会算 hash,而传统拉链法是不需要的。(不过我好像有一次看见了类似于 _M_hash_cache 这样的东西,说不定使用这个字段有一定的条件。)
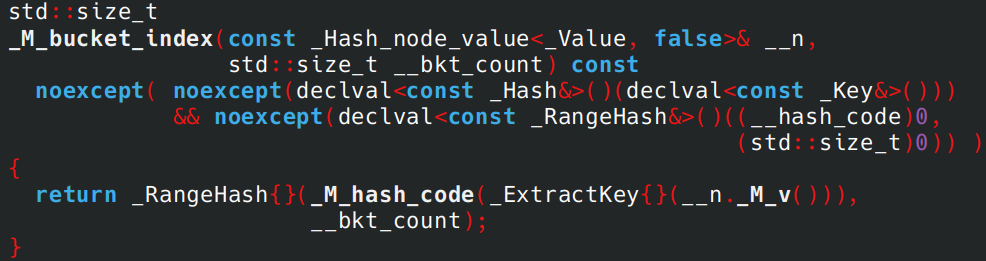
到此的调用栈:
#0 std::__detail::_Hash_code_base::_M_bucket_index
#1 std::_Hashtable::_M_bucket_index
#2 std::_Hashtable::_M_find_before_node
#3 std::_Hashtable::_M_find_node
#4 std::_Hashtable::find
#5 std::unordered_multiset::find
#6 main () at test.cc:9
不难看出,unordered 系列哈希表都是使用了同一个哈希表,他们只是封装了一层而已。
确实没有渐进式rehash
可以从下面的代码中看出,它先分配了一个__new_buckets,然后遍历旧表的链表,再rehash到这个新表上,并且构件新的链表。
因为它会遍历完这个链表,所以STL的哈希表可能会造成较大延迟,所以在延迟较为敏感的服务上,请小心!
void
_Hashtable<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_Hash, _RangeHash, _Unused, _RehashPolicy, _Traits>::
_M_rehash(size_type __bkt_count, true_type /* __uks */)
{
__buckets_ptr __new_buckets = _M_allocate_buckets(__bkt_count);
__node_ptr __p = _M_begin();
_M_before_begin._M_nxt = nullptr;
std::size_t __bbegin_bkt = 0;
while (__p)
{
__node_ptr __next = __p->_M_next();
std::size_t __bkt
= __hash_code_base::_M_bucket_index(*__p, __bkt_count);
if (!__new_buckets[__bkt])
{
__p->_M_nxt = _M_before_begin._M_nxt;
_M_before_begin._M_nxt = __p;
__new_buckets[__bkt] = &_M_before_begin;
if (__p->_M_nxt)
__new_buckets[__bbegin_bkt] = __p;
__bbegin_bkt = __bkt;
}
else
{
__p->_M_nxt = __new_buckets[__bkt]->_M_nxt;
__new_buckets[__bkt]->_M_nxt = __p;
}
__p = __next;
}
_M_deallocate_buckets();
_M_bucket_count = __bkt_count;
_M_buckets = __new_buckets;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号