
CMU15445 数据库项目3 Executor & Optimizer
复杂任务的分解是一项技术活
这次 Project3,没想到那么多天才做完。倒也不是说花了那么多时间,而是在找时间写(什么鬼课程安排,早上一节课下午一节课),中间也因为面试而停下一段时间。不过总算是通过了。
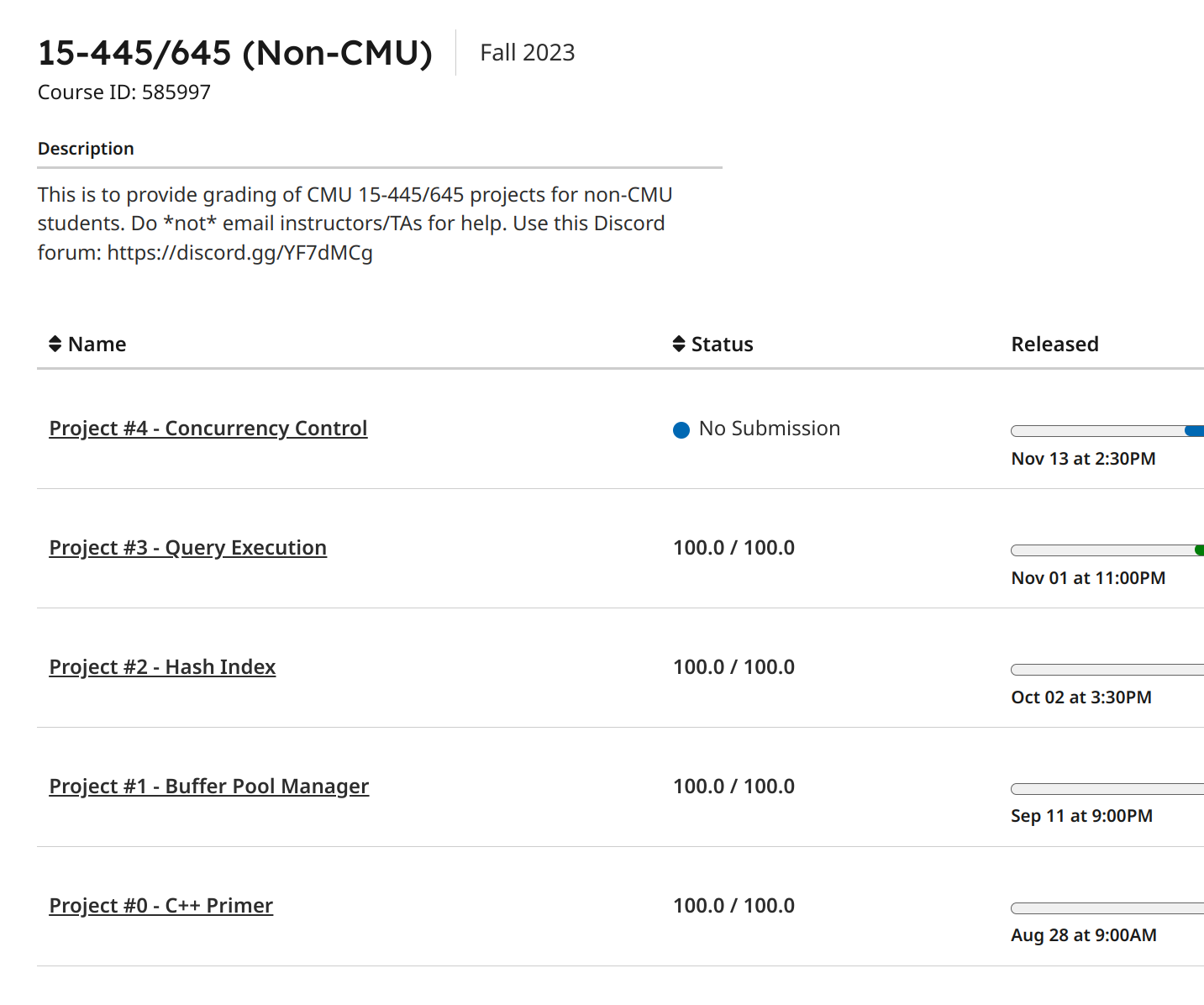
Project3 的难度和 Project1 比较接近,但是任务量大了很多,并且对不知道怎么阅读代码的人极度不友好——它需要你会用调试工具,边调试,边理解,边写代码,边修bug。
根据 Andy 大佬的要求,我不能够在此公开任何源代码,所以只能够写一些思路,以及自己踩到的坑。
基本执行过程
一句 sql 的执行过程,在 Project3 的 Specification 中已经给明了:

传递给 Executor 的参数,是一个执行计划(Planner),它是一棵树的根指针,AbstractPlanNode,所以你使用 Explain 来解释 Sql 的时候,会看到这些东西:
bustub>
... explain select * from
... __mock_table_tas_2023_fall inner join __mock_table_schedule_2023
... on office_hour = day_of_week;
......
=== PLANNER ===
Projection { exprs=["#0.0", "#0.1", "#0.2", "#0.3"] }
NestedLoopJoin { type=Inner, predicate=(#0.1=#1.0) }
MockScan { table=__mock_table_tas_2023_fall }
MockScan { table=__mock_table_schedule_2023 }
=== OPTIMIZER ===
HashJoin { type=Inner, left_key=["#0.1"], right_key=["#1.0"] }
MockScan { table=__mock_table_tas_2023_fall }
MockScan { table=__mock_table_schedule_2023 }
那么怎么根据这个树来执行的?一般是由叶节点,向其父节点发送数据(Tuple,这是一个二进制数据,里面有数据长度信息,但是没有类型信息,存储的是数据库中的一行数据),父节点根据子节点的 Schema(真正存储了类型信息的),来解析 Tuple,反向解析为 vector<Value>,之后进行计算。
上述的例子,MockScan 读取到一行后,以 Tuple 的形式发送给 NestedLoopJoin,它再进行 Join。
其中的编号,比如predicate=(#0.1=#1.0)中的#0.1、#1.0,其含义分别是左表的第 1 列,右表的第 0 列。下面是我写的一段注释,本质上左右两个表的行,只是简单地拼接到一起了。你读了 InferJoinSchema,用 GDB 确定了会调用它,你就明白为什么是这样的了:
// In plan_node.h:
// auto NestedLoopJoinPlanNode::InferJoinSchema(const AbstractPlanNode &left,
// const AbstractPlanNode &right)
// -> Schema;
// Go through the codes, it just connect left and right schema together.
自动机警告
大一的时候,学校开了自动机的课程,这是整个大学里唯一有用的课程。很多同学以为它没用。这里就用上它了,在 NestedLoopJoinExecutor,HashJoinExecutor 中,本来挺好写的两层循环,你要改写为迭代器形式。也就是说类似于这样的代码:
result = []
for i in left_tuple:
for j in right_tuple:
if predicate(i, j) == True:
result.append((i, j))
你要改写成迭代器,每一次获得一个 result 中的结果。
# 想什么嘞?怎么可能放 C++ 代码
def find_matched_right(Tuple left):
while right = rexec->next():
if predicate(left, right):
return True, connect(left, right)
return False, None
left = None
def next():
while True:
if 左表遍历完成:
return False, None
elif 右表已经遍历完成:
left = lexec->next()
rexec->init()
found, result = find_matched_right(left)
if found == False:
continue
else: return True, result
如何表示左右表遍历的情况?直接上自动机吧。实际上我在实现中,next 调用一个函数,它在去调用前文说的 find_matched_right。
为什么要改写成迭代器形式?如果是双层循环,那么这个 Executor 将会成为一个 Pipeline breaker,必须等他执行完成之后,其父节点才可以执行,那万一父节点也是个 Pipeline breaker?这样做,节省内存,还避免了 Pipeline breaker,不用阻塞执行流程。
这种自动机改写两层循环,我还真是第一次写,有机会写个改写的通式来。
Update
本以为 UpdateExecutor 是直接替换原来的 Tuple 即可,我也看到了一个这样的函数,以为确实可以这么做:
/**
* Update a tuple in place. Should NOT be used in project 3. Implement your project 3 update executor as delete and
* insert. You will need to use this function in project 4.
* @param meta new tuple meta
* @param tuple new tuple
* @param rid the rid of the tuple to be updated
* @param check the check to run before actually update.
*/
auto UpdateTupleInPlace(const TupleMeta &meta, const Tuple &tuple, RID rid,
std::function<bool(const TupleMeta &meta,
const Tuple &table,
RID rid)> &&check = nullptr) -> bool;
当我测试不通过的时候才发现那句Should NOT be used in project 3。所以正确的做法是标记为删除,然后新插入。为什么这么做?就是为了后面的事务管理。
rank() of Window functions
window function 的功能和 group by 相似,但是也有区别,特别是 rank()。一般用rank() over (order by v1),输出结果,如果 order by 指定的值(这里是 v1)不变,输出与上一个输出相同的值。否则从输出的总行数开始输出。也就是说:
select v1, rank() over (order by v1) from t1;
----
-99999 1
0 2
1 3
1 3
2 5
3 6
3 6
99999 8
而不是
select v1, rank() over (order by v1) from t1;
----
-99999 1
0 2
1 3
1 3
2 4
3 5
3 5
99999 8
我的想法是,反正有 order by,那就在聚合的时候,对 rank() 的记录改写为(该聚合键上一次选中的 tuple id,上一次输出的 rank 值。如果不同,就输出该 tuple,以及输出的总 tuple 数量,并更新聚合信息。
Optimizer 的二叉树花式遍历
以前听说过:程序猿每天喜欢在两棵树上跳来跳去,一颗是二叉树,另一棵,还是二叉树。
直到写 Optimizer 的时候我才明白为什么,因为这就是在花式遍历二叉树。
遍历的是表达式树,用 AbstractExpression 指针代表根节点。遍历的时候统计信息,来进行一些优化。比如:
- 是否有 or 表达式
- 是否有 not 表达式
- 有哪些 and 表达式
- 有哪些 = 表达式
- 哪些表达式可以让子 Executor 处理
- 有哪些地方可能可以用索引
没有 or 和 not,意味着你可以放心地提取所有的比较表达式,<=, >, !=之类的表达式你提取成 vector,可以方便地构建一个新的表达式。第 0 个和第 1 个组成一个 and 表达式,然后该 and 表达式和第 2 个组成 and 表达式...
测试用例中有一个对三张 1000k 行 join 的 sql,默认用 NestedLoopJoin,但是如果过滤条件是 =,且是 and 表达式,那么你的执行时间可以优化到 6 分钟。也就是说:
select count(*), max(__mock_t4_1m.x), max(__mock_t4_1m.y), max(__mock_t5_1m.x), max(__mock_t5_1m.y), max(__mock_t6_1m.x), max(__mock_t6_1m.y)
from __mock_t4_1m, __mock_t5_1m, __mock_t6_1m
where (__mock_t4_1m.x = __mock_t5_1m.x)
and (__mock_t6_1m.y = __mock_t5_1m.y)
and (__mock_t4_1m.y >= 1000000)
and (__mock_t4_1m.y < 1500000)
and (__mock_t6_1m.x < 150000)
and (__mock_t6_1m.x >= 100000);
改写为:
select count(*), max(__mock_t4_1m.x), max(__mock_t4_1m.y), max(__mock_t5_1m.x), max(__mock_t5_1m.y), max(__mock_t6_1m.x), max(__mock_t6_1m.y)
from (
select * from __mock_t4_1m, __mock_t5_1m on (
__mock_t4_1m.x = __mock_t5_1m.x
) where (__mock_t4_1m.y >= 1000000) and (__mock_t4_1m.y < 1500000)
), __mock_t6_1m on (__mock_t6_1m.y = __mock_t5_1m.y)
where (__mock_t6_1m.x < 150000) and (__mock_t6_1m.x >= 100000);
所以节点为:
Agg { types=["count_star", "max", "max", "max", "max", "max", "max"], aggregates=["1", "#0.0", "#0.1", "#0.2", "#0.3", "#0.4", "#0.5"], group_by=[] }
Filter { predicate=((#0.4<150000)and(#0.4>=100000)) }
HashJoin { type=Inner, left_key=["#0.3"], right_key=["#1.1"] }
Filter { predicate=((#0.1>=1000000)and(#0.1<1500000)) }
HashJoin { type=Inner, left_key=["#0.0"], right_key=["#1.0"] }
MockScan { table=__mock_t4_1m }
MockScan { table=__mock_t5_1m }
MockScan { table=__mock_t6_1m }
因为整个 Sql optimize rule 有应用顺序的。Filter 会尝试和 NestedLoopJoin 合并,所以你写完了优化函数后,顺序还得考虑。不过这个是小问题了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号