信息量、熵、KL散度、交叉熵
信息量、熵、KL散度、交叉熵
相信很多小伙伴在学习交叉熵时,对交叉熵感觉到非常的迷惑。"交叉熵怎么来的?","为什么交叉熵的表达式是这样婶儿的?","熵和交叉熵到底有什么关系?"。本文通过由浅到深的顺序,来引入交叉熵,希望能对各位学习路上的小伙伴有所帮助,不足的地方恳请批评指正
一、 信息量
1. 何为信息量?
从字面意思来看,直观理解:如果我们知道一件事情,这件事情给我们带来的信息有多少。
2. 信息量如何定义?
让我们想象一个能带给我们信息量的例子:四个人比赛争夺冠军,编编号为1,2,3,4,每个人每场胜利的概率是\(\frac{1}{2}\)
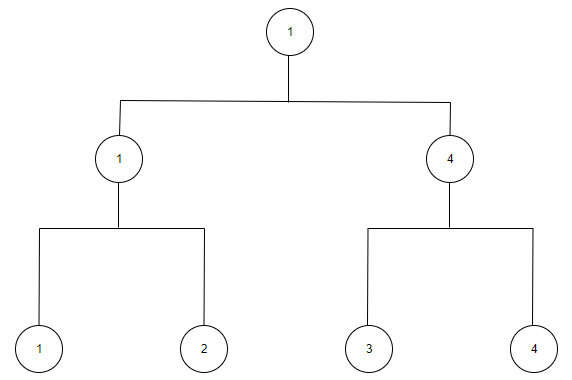
选手1、2比赛,1获胜的概率是\(\frac{1}{2}\);选手3、4比赛,4获胜的概率是\(\frac{1}{2}\);1、4再比赛,1获胜的概率还是\(\frac{1}{2}\);我们关注1号选手,并设信息\(x\)所具有的信息量为\(f(x)\),即
设选手1第一场获胜的事件为\(x_1\),选手1第二场获胜的事件为\(x_2\),选手1获得冠军的事件为\(x = x_1 * x_2\),表示\(x_1\)与\(x_2\)同时发生. 为了保证信息量量纲的一致性,我们猜想
之所以是加法而不是乘法,是为了保证量纲的一致性。
根据上式,我们就能断定:信息量的计算一定是一个对数函数。接下来我们猜想下一个问题,一个事情发生的概率越小还是越大,他能带来的信息量越大?思考一下我们就能发现,一个事情发生的概率越小,它所带来的信息量就越大,如中国国足夺冠(手动狗头)。至于对数函数的底数,什么值都没有关系,为了更好的进行运算,信息论中将其定义为以2为底。故信息量定义如下:
\(x\)为事件,\(p_x\)为事件\(x\)发生的概率,信息量的单位为奈特 nat.
二、熵
熵是衡量一个信息系统的混乱程度,定义为信息量的期望。故其计算表达式为:
其中,\(X\)的分布为\(\{p_1,p_2,\cdots,p_n\}\). 熵用来衡量一个信息系统的混乱程度
三、KL散度
有了熵,我们就能衡量一个信息系统或一个概率分布的分布情况,那么肯定会有同学思考,如何衡量两个分布的"距离"呢?
- 对于相同的分布,如高斯分布,我们只需要比较均值\(\mu\)与标准差\(\sigma\)
- 对于不同的分布,我们必须通过一个更高层的指标来比较
由此,我们引入KL散度(Kullback-Leibler Divergence)的概念,用于度量两个分布之间的"距离"。设有两个概率分布\(P(X)\)与\(Q(X)\),定义以\(P\)为基础的\(P,Q\)之间的KL散度为
四、交叉熵
1. 交叉熵引入
我们观察KL散度的公式:
为了让分布\(Q(x)\)更接近分布\(P(x)\). 上式必须趋近于0,但我们并不知道$\sum_{x \in X}[-P(x)logQ(x)] \(与\) \sum_{x \in X}[-P(x)logP(x)]$谁大谁小。当然已经有人帮我们解决了这个问题,根据吉布斯不等式:
恒成立,所以为了为了让分布\(Q(x)\)更接近分布\(P(x)\).我们只需要让$\sum_{x \in X}[-P(x)logQ(x)] $尽可能的小即可。
2. 交叉熵定义
为了更方便描述,我们给$\sum_{x \in X}[-P(x)logQ(x)] $取了个名字,叫做交叉熵。
在机器学习中,我们常用一个已知数据集来训练一个机器学习模型,故我们想让模型预测的概率分布更接近已知数据集的概率分布,所以我们将已知数据集的分布看作\(P(x)\),模型预测的分布看作\(Q(x)\).
由于数据集已知,则\(P(x)\)已知,故我们需要优化\(Q(x)\). 在深度学习神经网络上,我们要做分类任务时,经常用全连接层后的神经元输出,经过\(Softmax\)得到模型预测的概率分布,所以对分类神经网络来说,交叉熵损失函数即为
其中,\(p_{i,k}\)为第i个样本预测为标签k的概率,\(y_{i,k}\)是样本\(i\)真实的标签的one-hot编码,当样本属于类别\(k\)时,\(y_k = 0\),即\(y_{i,k} \in R^{K}\),第\(k\)位为1,其余位为0.
3. 二分类问题
当分类为二分类问题时,\(x\)的取值只能为0或1,\(Softmax\)的输出只有一个值,即预测标签为1的概率。此时,
又因为:
故上式可写为:
即:
其中,\(P\)为标签的具体值(0或1),\(\widetilde{P}\)为模型的预测值(标签为1的概率).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号