

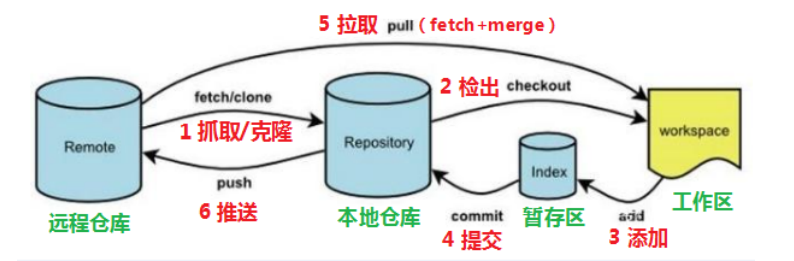
Git的工作流程图
基本命令:
clone:从远程仓库克隆代码到本地仓库
checkout:从本地仓库检出一个仓库分支,然后进行修订
add:在提交前,先将代码提交到暂存区
commit:提交到本地仓库。本地仓库中保存修改的各个版本
fetch:从远程仓库抓取到本地仓库,不进行合并操作(使用较少)
pull:从远程仓库拉取到本地仓库,总合并,然后放到工作区
push:修改完成后,需要和团队成员共享代码,将代码推送到仓库
status:查看一些状态信息
log:查看提交日志
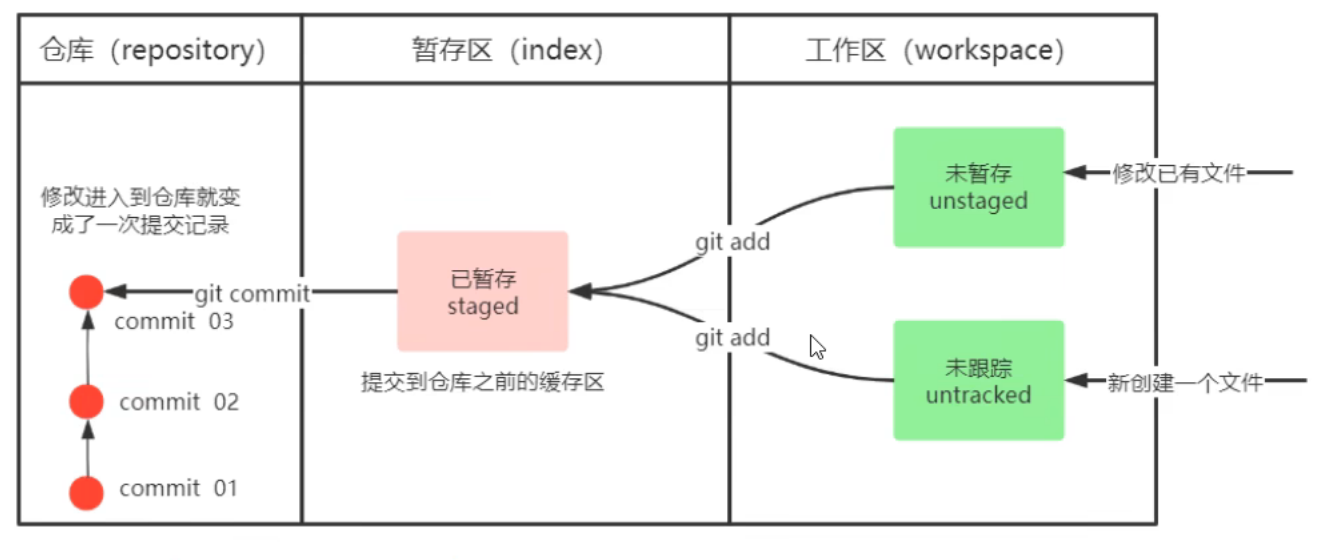
commit的工作流程
log命令的查看
alias git-log='git log --pretty=oneline --abbrev-commit --all --graph'
--pretty=oneline 表示commit信息压缩成一行
--abbrev-commit表示commitID最小长度
--all显示所有分支的提交
--graph以图的形式显示
版本回退
版本切换:git reset --hard commitID
具体了解 reset 不同参数对本地仓库、暂存区和工作区的影响。
commitID 可以通过 git log 查看
已经删除了的分支可以通过 git reflog 分析出来删除的分支的 commitID
告诉git别管哪些文件
创建一个 .gitignore 文件,在里面写上不用git管理的文件(可以使用通配符)
比如我不想 .a 后缀不需要管理,所以我们就可以在 .gitignore 写上 *.a
被选中的文件不在通过git进行管理。
git的分支
真实的开发中是会使用很多个分支的,分支之间经常会产生冲突,下面我就通过类似实验的方式,一步步探究:git的分支是如何产生的。
假设在最开始,一个人单人开发一个 master 分支,这个分支的状况如下
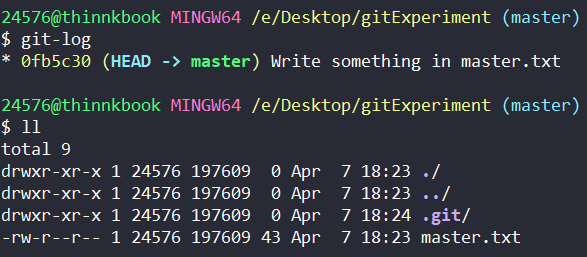
master 分支原来只有一个人开发,并把内容写在 master.txt 中。
后来,本项目变成了两个人开发,这个时候,一条分支不够用了,需要另外一条分支。
两个人商议决定开一条新的分支 workerA 给新加入进来的人开发
git checkout -b 新分支名
可以创建一个新分支,并切换到新分支中
workerA 刚创建好的项目状况如下:
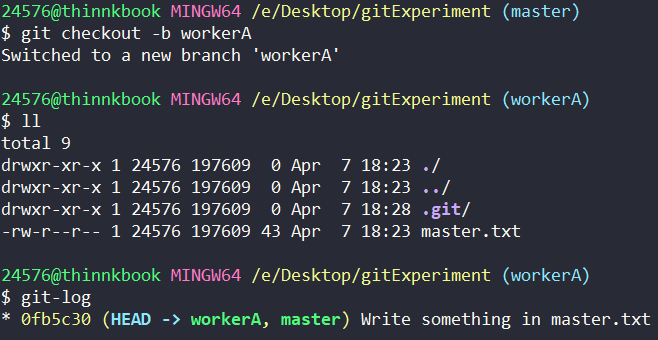
由于 master.txt 是已经有人在开发了,workerA 只能另开一个工作文件 workerA.txt 来进行开发。
注意:在workerA.txt创建完成后,但还没有commit到workerA分支时,master是能看见workerA.txt的。
按理说master不合并workerA分支是看不见workerA分支新增的内容的,但上述的情况除外。
假设一段时间过后,workerA 在 workerA.txt 里完成了很多东西,但 master 没做任何事。master 分支能正确地合并 workerA 分支而不发生冲突吗?
合并前的状态:

合并后的状态:
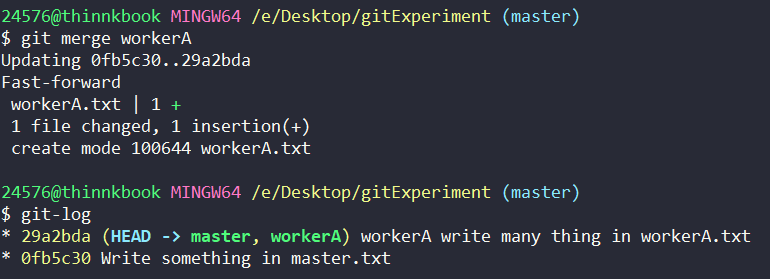
这里给人的感觉就是:master 分支什么都没做,直接转入了workerA的劳动成果。
可以发现,在上述情况下,并不会出现分支合并冲突的情况。
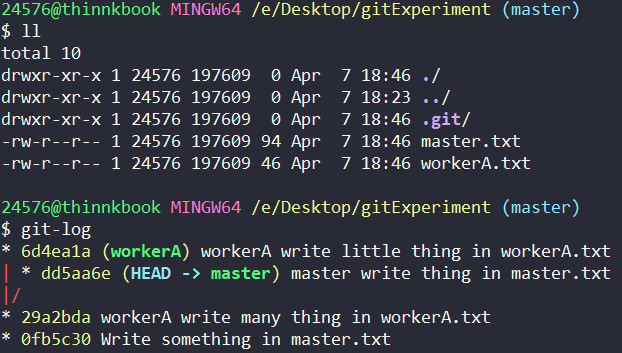
以上面的结果为起始状态,workerA 又在 workerA.txt 上写了一些东西,而这一次 master 也干了点正事,写了一些东西在 master.txt 中。
这个时候,master 和 workerA 合并,会不会发生冲突?
合并前:
合并后:
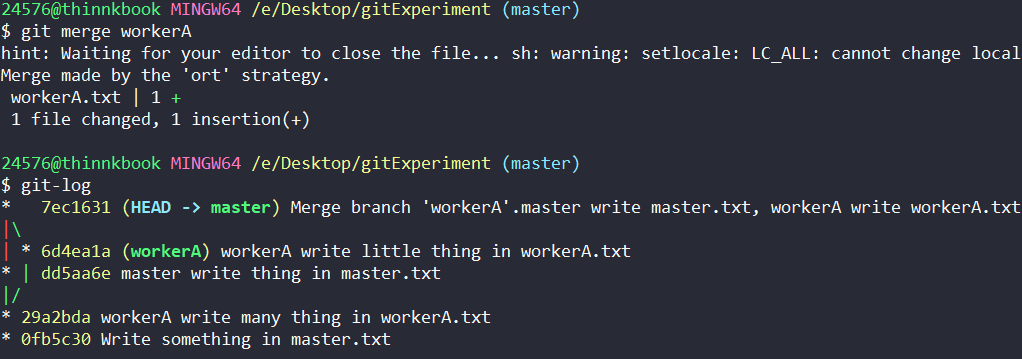
可以发现,两个分支依旧能正常合并,不会产生冲突。
通过上述实验,大概可以判断一件事:
不同的分支如果工作在不同的文件中,不管他们怎么样改变自己的文件的状态,最终都能不会产生冲突地合并。
那如果 workerA 不满意 master 所写的 master.txt 内容,想要将其全部进行修改。而 master 不知道 workerA 所做的修改,依然在 master.txt 上工作,那最终很可能产生冲突。
先将上一步的 master 合并到 workerA 以更新其状态
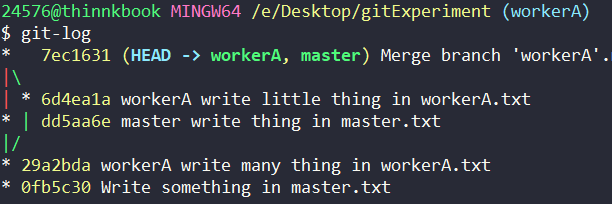
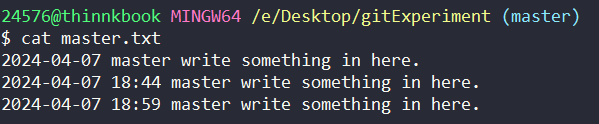
下面我就来进行实验。master.txt 的初始状态如下:

workerA 对其工作区的 master.txt 做出了修改并commit,做出的修改如下:

而master只是单纯对master.txt增加了一些东西:
这种情况下,master 合并 workerA 会不会产生冲突?
合并前:
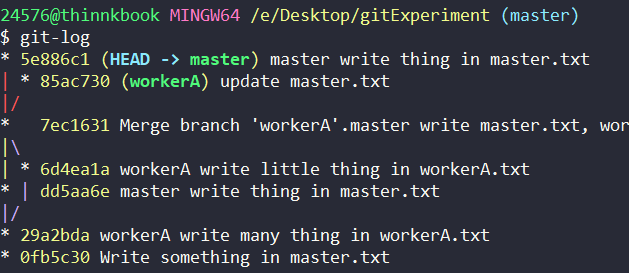
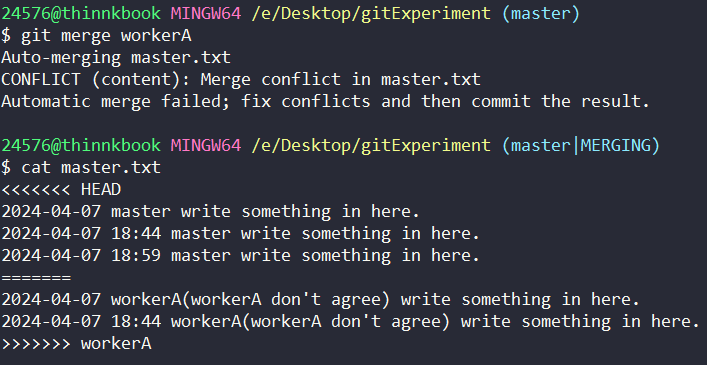
此时,冲突产生,git帮我们标记处了冲突的地方,让我们做出选择。
根据上面的结果,可以分析出怎样的结论?
只要各分支工作在只属于自己的工作区上,不去干扰其他分支的工作区,那就可以避免冲突。
可是,我们可能会想:执行的时候可能只有一个主函数,如果我们需要测试自己的代码,那不都是要改主函数吗?
关于这个问题,如果我们是用Java进行开发,那Junit可以一定程度上解决这个问题,因为每个人都能拥有自己的测试类。
但是对于其他编程语言,我能想到的方案就是,你可以修改main函数,但永远记住不要commit它,这样就不会让别人看见你修改了main,冲突就不会发生。
从这里我们可以窥探到真实开发中的一些情况:一个团队肯定是通过分支进行协作的,每个人各自工作在自己的工作区上,不去影响他人的代码(信任你的同事)。
如果写好的代码想要进行测试,其实可以将使用的方法交给测试人员,让测试人员进行测试,他会告诉你测试的结果,你需要进行改进(信任你的同事)。
如果你认为自己的代码还没有完成,需要通过调试的方式完成编写,可以去改main函数,但不要将其加入暂存区也就是不要 git add 这样的话你的修改没有commit就是没有修改,合并依然能正常进行。
远程仓库
我在本地有一个git仓库,想要将这个git仓库提交到github,该如何做?
首先,在github上准备一个空仓库,必须是没有任何东西的仓库,创建好后效果是这样的:

其实上面有说操作的方法,我这里主要是解释一下它上面的方法主要干了什么。

我这里使用的是ssh作为演示,大家在使用的时候可能会遇到公钥或者防火墙等相关的问题。如果不在乎传输是否安全,大可以放心使用HTTP。
git remote add origin git@github.com:Aderversa/GitExperiment.git
上面这句命令说的是:创建一个远程仓库,这个远程仓库的名字是 origin,这个远程仓库的URL是 git@github.com:Aderversa/GitExperiment.git。
比如,我这里有一个刚创建好的仓库

看执行上述命令后会发生什么?
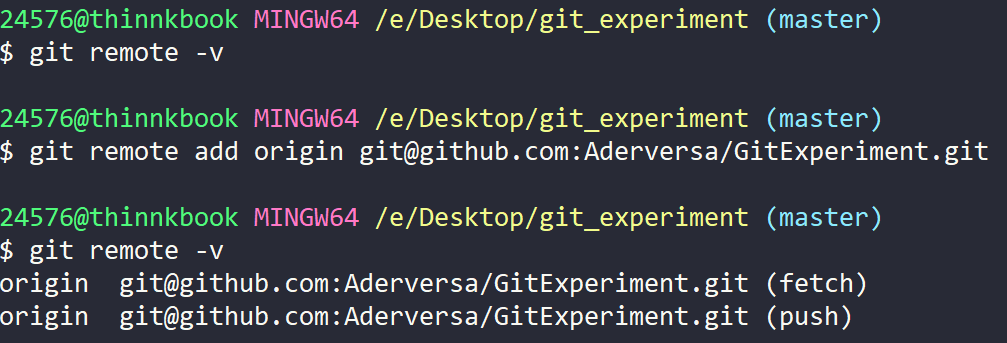
可以看到,原本远程分支中是没有 origin 的,但在使用上述命令后,我们成功将远程仓库的信息添加到了本地。
如果对git remote的其他用法感兴趣,可以使用 git remote -h 查看其详细信息
git branch -M main
# 上面的-M参数指的是:移动或者重命名一个分支,即使目标存在(move/rename a branch, even if target exists)
只是看的话,我们不知道到底有什么用,执行一下试试:
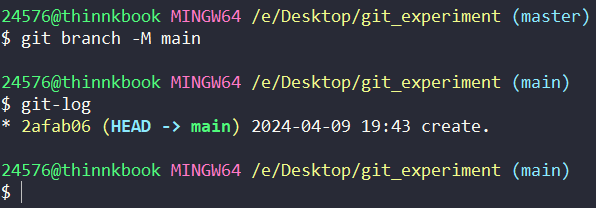
看完这个结果大概就能猜到了,这就是如果不指定旧分支,那就默认是对本分支进行改名,main是新的分支名
这玩意有没有一个让,github让我们这样做的原因大概是:鼓励我们使用他们的规范。
git push -u origin main
这个命令说的是,将本分支push到远程仓库origin的main分支(这个origin是我们前面配置好的)。如果main分支在远程仓库不存在,那远程仓库就会自动创建一个main分支来接收我们的push。-u 后面进行详解,执行的结果如下:
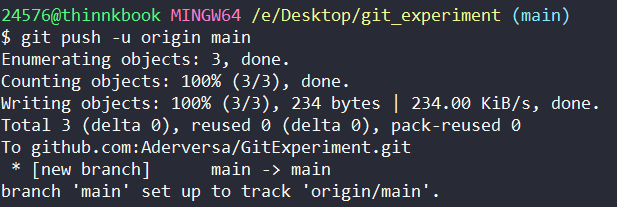
这样之后,我们在github的远程仓库就会有了提交信息
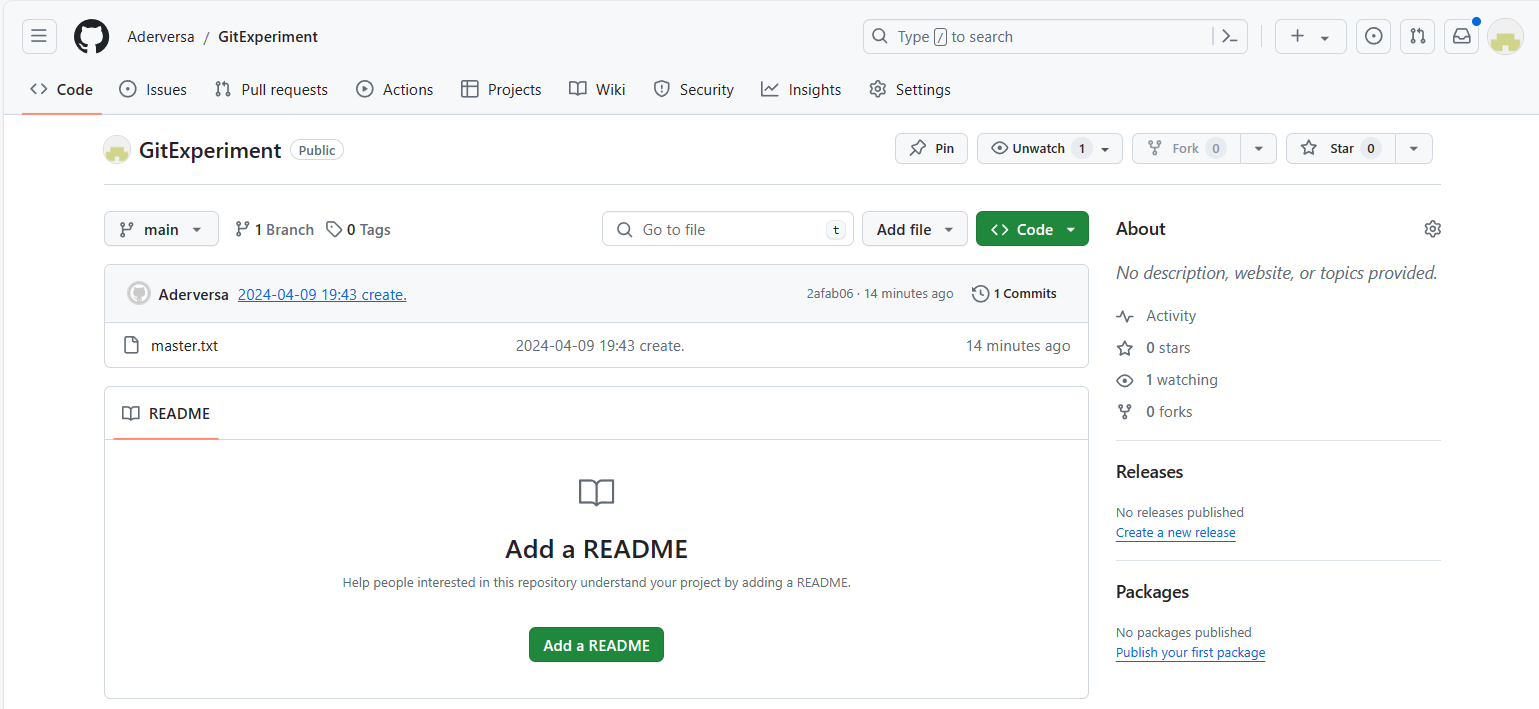
git push
在本地仓库放到远程仓库的例子中,我们做的有效步骤有两步:
- 为本地仓库设置关联的远程仓库
- 将本地仓库的某一分支 push 上远程仓库
在后续完成项目的过程中,我们肯定需要不断地往远程仓库中提交我们所写的代码,也肯定需要不断往远程仓库中拉取同事的代码。
而且我们的本地仓库中,肯定不止一个分支需要 push,也不止一个分支需要 pull,如果每次的 git push/git pull 都需要指定远程仓库的名字,和远程仓库的某个分支,那样可能稍显麻烦。
所以,我们可以将本地仓库的某一分支和远程仓库的某一分支相关联,这样我们直接使用 git push/git pull 的时候,就会不用指定远程仓库的名字和分支,直接push/pull关联好的远程仓库的分支。
git push 中的 -u 参数 就是用来设置这样一种关联的,我们可以通过 git branch -vv 查看这种关联:

可以看到,本地的main分支与远程仓库的main分支相联系。
这样提前搞好分支之间的联系,可以让我们在项目开始的初期就从本地分支和远程分支的管理中解放出来,专心于代码编写
前面提到了 git pull ,这个命令可以让我们从远程仓库中拉取远程仓库的某一分支,如果是通过 git push -u 配置好了的,那就可以不用每次都指定远程仓库名和分支名。
我这里在本地,clone下来了两个项目文件夹,以模拟开发中遇到的:需要拉取最新代码的情况:

一开始,双方状态相同。
但是,右边的开发人员做出了一个新的提交:
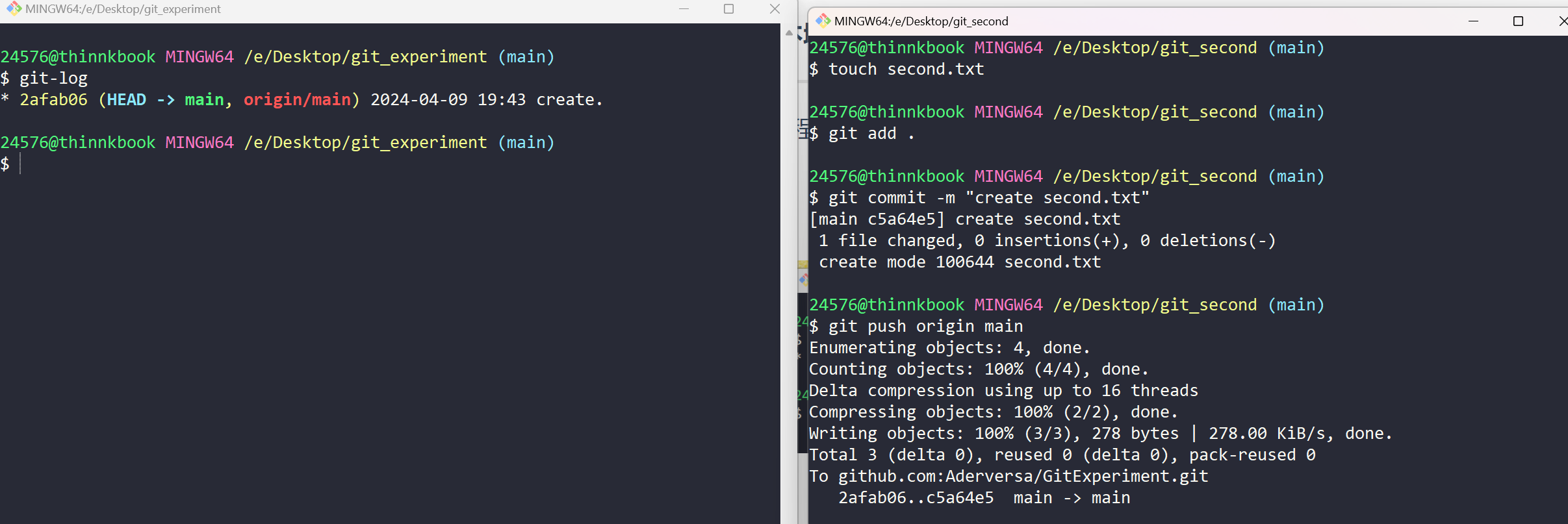
如今的github仓库状态如下:
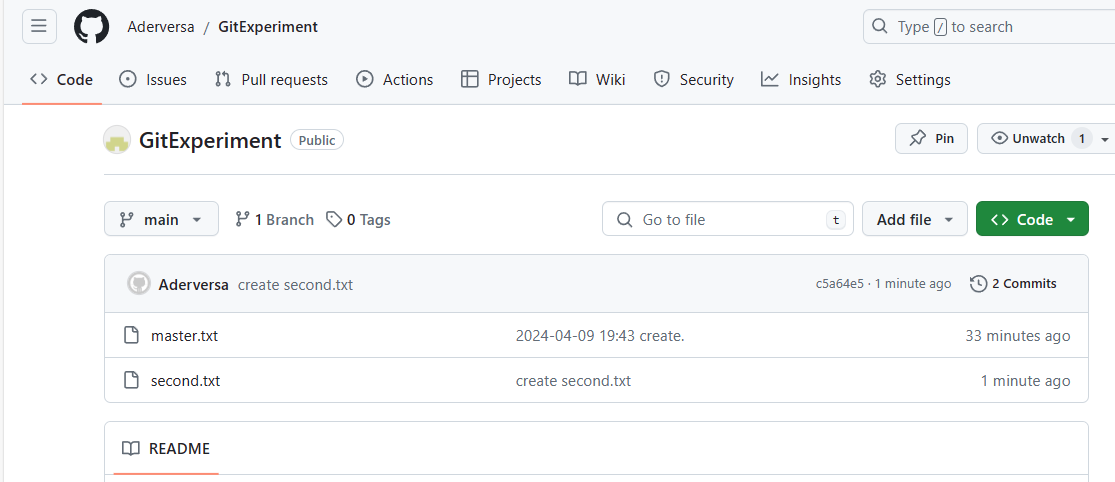
我们转头看看左边开发人员的仓库状态:
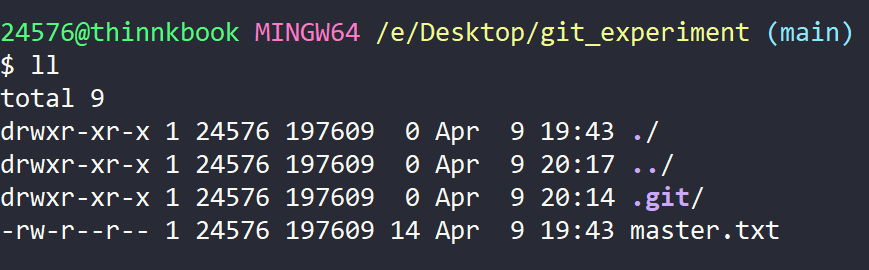
没有更新到最新状态,于是可以使用 git pull 从预先关联好的远程分支中拉取最新的代码。

成功更新到远程仓库的最新状态。
在开发中,时常更新自己的仓库状态有利于获取项目最新进展,所以学会高效地使用 git pull
项目中真实的开发状态
上面的例子只是作为演示而存在的,真实的开发中可能远比上述例子要复杂。
下面是,我对git在项目中的使用做出的一些猜测:
(1)远程仓库中,需要有多少个分支才合适?
假设远程仓库中只有一个 main 分支,用来存放测试合格,功能合格的模块。那我们开发人员要做的是什么?
将远程仓库的main分支clone下来本地,这个main就应该与远程的main分支相关联。开发人员当这个本地的main分支就是远程的那个,所以他必然不会在本地的main上进行开发,他需要另外一个分支用于开发这个项目,假设这个分支是 develop。
而由于开发人员负责的模块可能会由几个子模块构成,所以他还需要单独地对各个子模块进行开发,这需要其他几个分支假设是 features1,features2......在子分支测试 features1 合格后,开发人员将 feature1 合并到 develop 分支。
然后,他陆续完成了,feature2 ...子模块全部完成后,就可以将这些子模块组合,并在 develop 进行功能测试。测试完成确保无误后,将 develop 分支正式合并到本地main分支中,合并的时候注意不要把测试时不属于开发人员自己的工作范围的文件提交上来(以避免发生冲突)。
合并到本地 main 分支后,由于 develop 已经确实没有发现什么大问题了,所以就提交到远程的 main 分支中。
为什么不再本地main分支中进行测试?
这是可能是因为,开发人员负责的模块确实已经完成了,但其他人员还没有完成,组合成的项目也就无从测试。开发人员只用负责好将自己的模块写好,剩下的就是项目的测试人员的任务。
以上纯属本人根据已有的经验进行的瞎猜,具体开发过程如有不同请不要感到奇怪。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗