
虚拟化技术概述(一)
之前在 Intel 做开源虚拟化项目 ACRN (https://projectacrn.github.io/latest/index.html),现在虚拟化还是很火热,所以希望总结下之前的学习和开发经验,也由浅到深分享下,从虚拟化的分类,实现,和我们 ACRN 中的实现;
0. Term
一些简称的介绍:
- DMA,Direct Memory Access,直接访问 IO 设备的内存地址
- DMA Remapping
- GPA,Guest Physical Address,客户机物理地址
- GVA,Guest Virtual Address,客户机虚拟地址
- HPA,Host Physical Address,主机物理地址
- IEC,Interrupt Entry Cache
- MSI,Message Signaled Interrupts
- MGAW,Max Guest Address Width
- VMM,Virtual Machine Monitor
- VMX,Virtual Machine Extensions
- VA,Virtual Address
1. 虚拟化概述
1.0 概述
区别与直接调度片上资源/使用物理平台,使用虚拟化技术对于资源的调度会更加灵活和高效,而且可以达到硬隔离的目的;
我们需要 Hypervisor / VMM ( Virtual Machine Monitor) 来实现虚拟化;
虚拟化的目的可以用一句话来概述:虚拟化技术的目的是希望能够截获上层操作系统应用对硬件资源的访问,然后重定向到 VMM 的资源池中,再由 VMM 来对片上资源进行管理;
“虚拟机可以看作是物理机的一种高效隔离的复制”,有以下三个典型特征:
- 同质,虚拟机的运行环境和物理机的环境本质上相同,但是表现上能够有一些差异;
- 高效,虚拟机中运行的软件需要有接近物理机(native)中运行的性能;
- 资源受控,VMM 需要对系统资源有完全控制能力和管理权限,资源的分配 / 监控 / 回收;
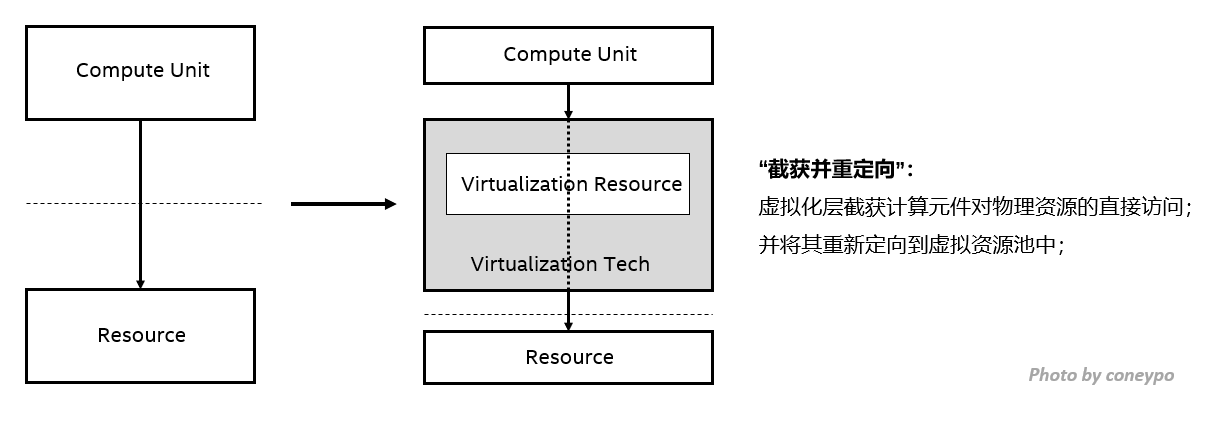
基于这样的需求,我们有了虚拟机方案, 比如 KVM, Xen, VMware, ACRN 等等;
1.1 内核态(Kernel mode) 和 用户态(User mode)
x86 CPU 中的操作有两个特权形态:内核态 和 用户态
- 内核态:如果 CPU 处于内核态,执行的程序可以执行任何 CPU 指令,并且访问内存中的所有地址,包括外围设备,比如硬盘/网卡等等;
- 用户态:如果处于用户态,只能访问受限的资源,而且不能引用内存或者直接访问外围设备;
所有用户程序运行在用户态,但是有些程序需要做内核态的事情(比如读取硬盘数据,获取硬盘输入),所以这个应用程序 APP x 就需要进行从用户态到内核态的切换,简单来说过程如下:用户态执行 APP x 收到一个 system call,然后设置 mode bit=0 切换到内核态,当内核态中执行完,设置 mode bit=1 切换回到用户态;
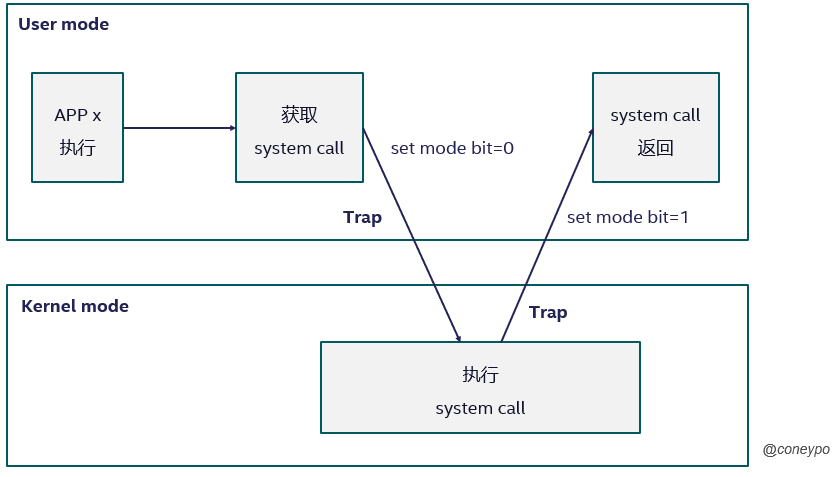
1.2 特权指令与敏感指令
首先引入 特权指令(Privileged Instruction)和 敏感指令(Sensitive Instruction)的概念:
- 特权指令(Privileged Instruction):对于系统中一些敏感资源的管理和读写的指令被定位特权指令,只有处于 Ring 0 才能进行正确执行,否则会丢出异常;
- 敏感指令(Sensitive Instruction):由于虚拟化的引入,由于 OS 现在处于 Ring1 所以不能执行特权指令,所以交由 Ring 0 的 VMM 来处理执行,这部分指令称为敏感指令;可以理解为客户机中必须交由 VMM 处理的指令;
对于有虚拟化的环境,客户机处于 Ring 1 而不是 Ring 0,如果所有的敏感指令都是特权指令,那么执行任意的敏感指令都会产生 trap,这样保证了客户机中如果进行这些“敏感”操作的指令,都会交给处于 Ring 0 的 VMM 处理;
敏感指令包括:
- 所有 I/O 指令;
- 企图访问或者修改 VM mode 或者机器状态的指令;
- 企图访问或者修改敏感寄存器 / 存储单元的指令;
- 企图访问存储保护系统或内存 / 地址分配系统的指令;
但是 x86 中有些指令,必须由处于 Ring 0 状态的 VMM 处理,但是工作在 Ring 1 不会产生 Trap,这样的话如果处于 Ring 1 的客户机执行这些指令,不会产生 Trap,也不能被定义为特权指令,这与上一句中的目的相冲突,所以必须也要 Trap 这些 “非特权指令”,x86 中称之为 临界指令(Critical Instructions);
所以 x86 中,敏感指令 = 特权指令 + 非特权指令 / 临界指令,如果一个系统上 敏感指令 = 特权指令,那么为了让 VMM 完全控制硬件资源,我们让虚拟机上的 OS 处于 Ring 1,不能直接执行 敏感/特权指令,而 VMM 处于 RIng 0 ,所以 OS 上执行 敏感/特权指令 的时候,就会 引起陷入 / cause a trap 到 VMM,再由 VMM 来模拟执行引起异常的指令;
临界指令 包括 敏感指令 中的 敏感寄存器指令 和 保护系统指令;
2. 虚拟化分类
根据虚拟化实现的方法,我们可以大概分为 操作系统级别虚拟化(OS-level virtulization),全虚拟化(Full virtualization),类/半虚拟化(Para virtulization)和 混合虚拟化(Hybrid-Para virtualization);
操作系统级别的虚拟化技术 不需要对于底层进行改动或者考虑 OS 下面,也没有所谓的 VMM 去监管分配底层资源,而是通过 OS 共享内核的方式,为上层应用提供多个完成且隔离的环境("the kernel allows the existence of multiple isolated user space instances"),这些 实例(instances),就被称之为 容器(container),虚拟化资源和性能开销很小,而且也不需要硬件的支持,是一种轻量化的虚拟化实现技术;
VMM 虚拟的是现实存在的平台,而且客户机不知道自己是虚拟出来的平台,以为是真实的平台,不需要对于 OS 进行修改,这是 完全虚拟化(Full virtulization);
但是有些情况 VMM 虚拟的平台是现实中不存在的(要经过 VMM 重新定义,需要对于客户机的 OS 进行修改),这是 类/半虚拟化(Para virtulization);
对于完全虚拟化,可以通过硬件/软件辅助的方式来实现;
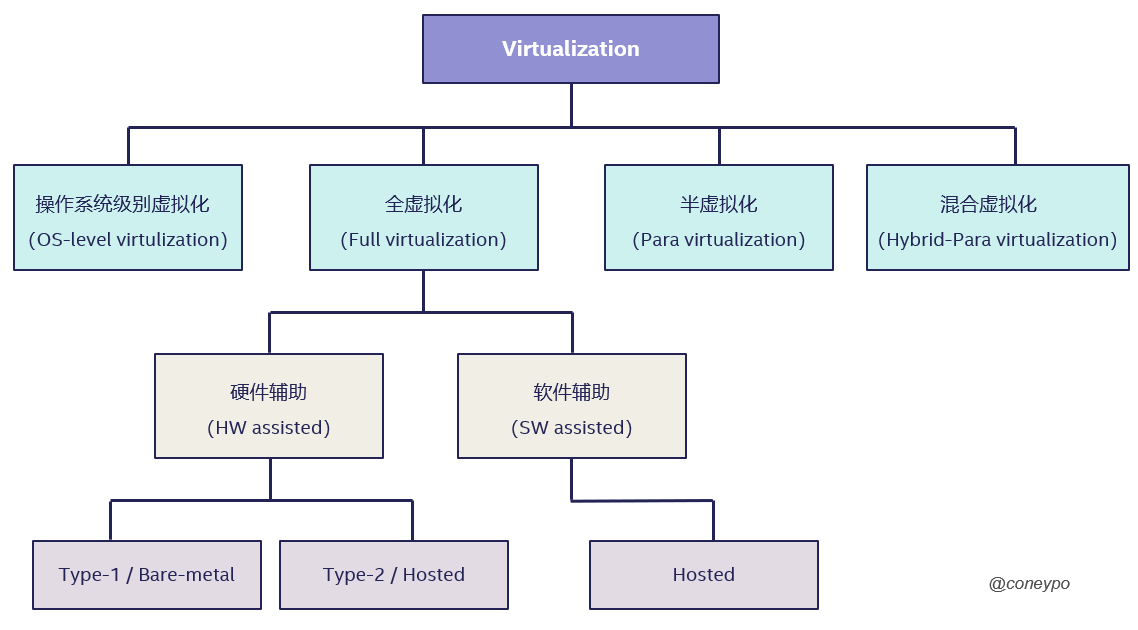
2.1 全虚拟化(Full virtualization)
全虚拟化会模拟足够的硬件设备,而且不需要对操作系统内核进行修改;
客户机(Guest OS)不知道自己在一个虚拟化的环境,所以硬件的虚拟化都在 VMM 或者宿主机中完成,所以客户机可以调用它以为真实硬件的控制命令;
根据“截获并重定向”的实现方式,我们将全虚拟化分为 软件虚拟化 和 硬件虚拟化;
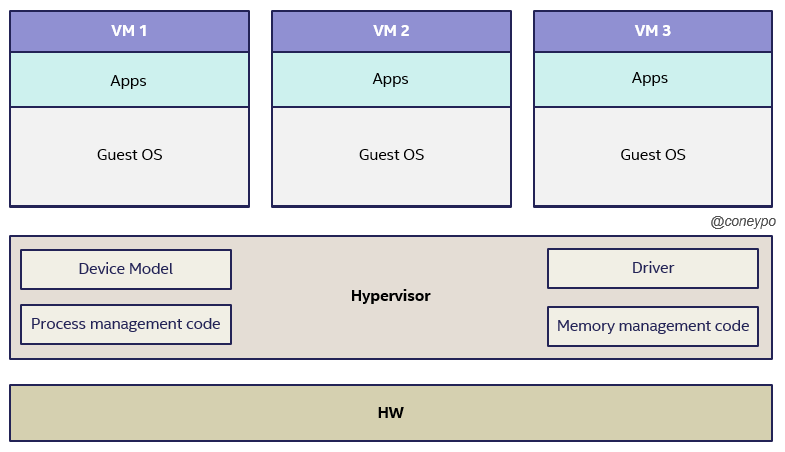
2.1.1 全虚拟化中的软件辅助虚拟化
因为之前 x86 的平台的硬件没有从硬件层面支持虚拟化,所以采用纯软件的方式实现 “截获重定向”;
通过让客户机的特权指令陷入异常,从而触发宿主机进行虚拟化处理的机制来处理,具体的实现方法通过以下两种方式相结合;
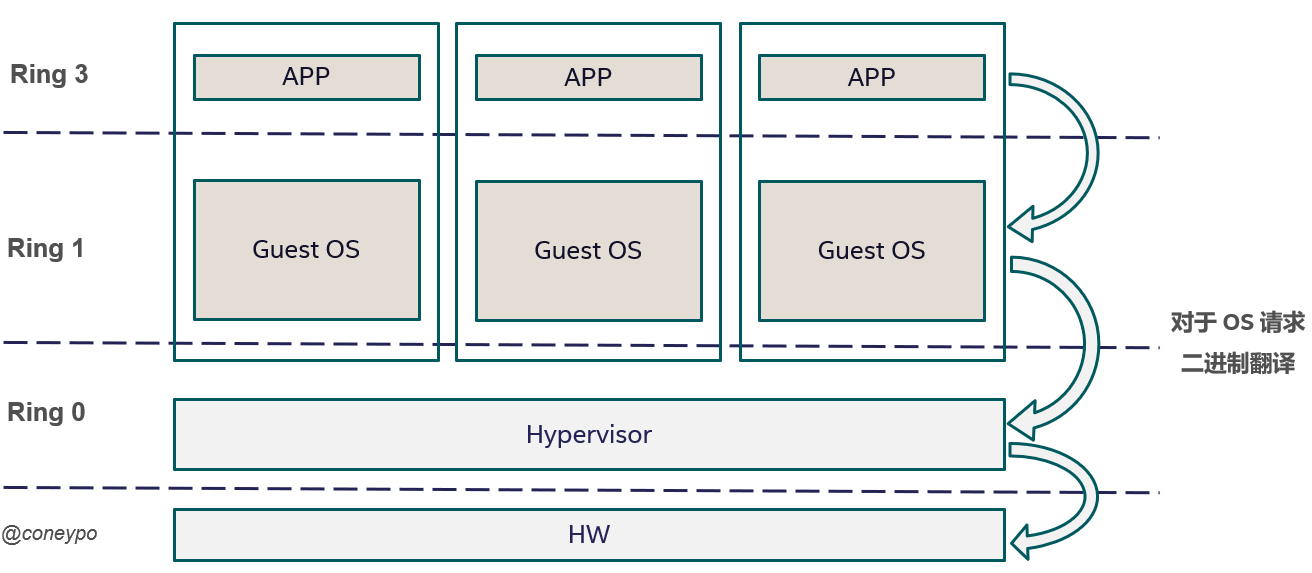
- 优先级压缩 (由于虚拟化的引入,应用从 Ring 3 -> Ring 3, 操作系统从 Ring 0 -> Ring 1,VMM 将取代 OS 处于 Ring 0)
- 二进制代码翻译(优先级压缩并不能很好的处理截获所有的特权指令,需要通过二进制翻译来扫描修改客户机的二进制代码,来将这些难以虚拟化的指令转换为支持虚拟化的指令)
2.1.2 硬件虚拟化
后来 x86 平台的物理设备本身慢慢的开始支持虚拟化,提供了对特殊指令截获重定向的硬件支持;
比如 Intel 的 VT-x 技术;
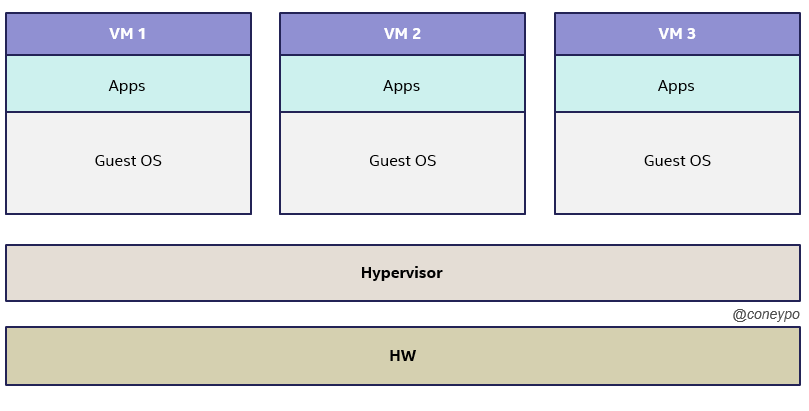
2.1.2.1 硬件虚拟化中的 Type-1 Hypervisor
Type-1 Hypervisor,或者称之为 Bare-metal Hypervisor,虚拟机直接运行在 Hardware 之上,系统上电之后加载运行虚拟机监控程序,资源的调度是 HW->VMM->VM;
这种虚拟机将上层的 OS 和底层的硬件脱离,所以上层的软件也不依赖或者局限于特殊的硬件设备或者驱动;
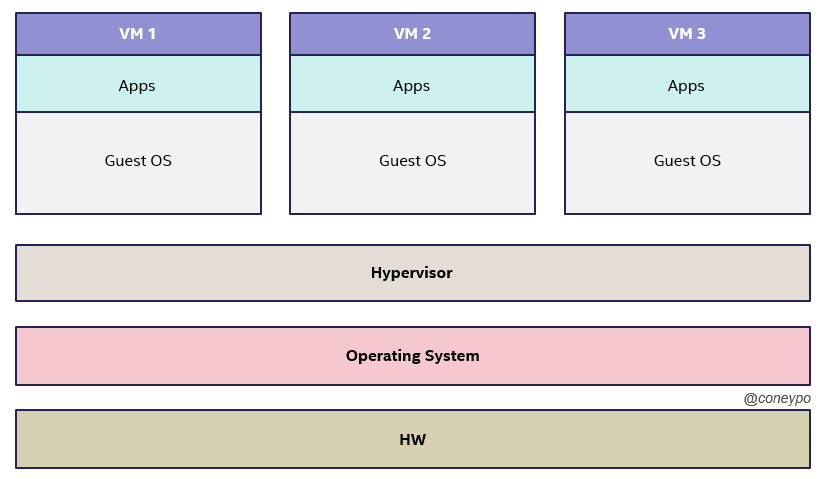
2.1.2.2. 硬件虚拟化中的 Type 2 hypervisor
Type-2 Hypervisor,或者称之为 Hosted Hypervisor,虚拟机不是直接运行在硬件资源之上,而是在操作系统之上;
所以系统上电之后,会先启动操作系统,然后加载运行虚拟机监控程序,资源的调度是 HW -> OS -> VMM -> VM;
比如 VMware Workstation (需要先启动 Windows,再启动 VMware 来启动 Ubuntu);
Type 1 的虚拟机监控程序可以视为一个为虚拟机进行设计裁剪的操作系统内核,Type 2 的虚拟机监控程序依赖于操作系统来进行调度和管理,所以会有限制性;
2.2 类/半虚拟化(Para virtulization)
完全虚拟化中会遇到一些,需要通过二进制代码翻译的方式来处理的不友好的特权指令集合,而类虚拟化采用另一种处理方式来解决这种问题;
类虚拟化(或称之为半虚拟化)需要修改客户机内核源码( API 级别),使得不再需要去模拟硬件设备,取而代之的是通过调用这个特殊 API 来实现虚拟化 ;
在源代码级别修改指令集,来避免虚拟化漏洞的方式,使得 VMM 能够管理片上资源实现虚拟化;
而且这种情况下,客户机(Guest OS)是知道自己是一个客户机;

根据片上硬件资源,我们将逐步介绍 CPU 虚拟化 / 内存虚拟化 / IO 虚拟化 / GPU 虚拟化 / ..
3. 虚拟化的实现
3.1 CPU 虚拟化
3.1.1 Socket / Core / Thread, Physical / Logical CPU
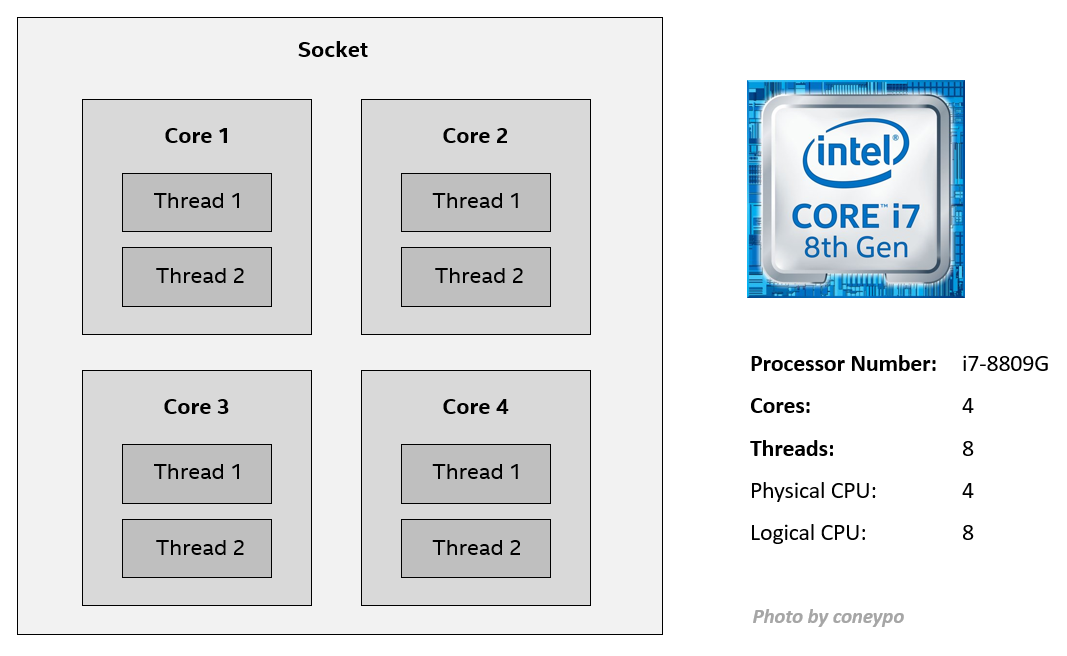
在介绍 CPU 虚拟化之前,要了解 Socket / Core / Thread 以及 物理 / 逻辑 CPU 的概念:
- Socket / 插槽: 主板上提供给一个物理封装处理器的插槽;
- Core / 核心: 一个完整的一套寄存器,执行单元,消息队列,代表一个独立的 CPU;
- Thread / 线程: 一个核心中有一个或者多个线程,线程是操作系统能够进行运算调度的最小单元,是进程中的实际运作单位;
- Physical CPU: 每颗芯片上的物理 CPU 个数,Cores 数目,4C8T 有4个物理 CPU;
- Logical CPU: 考虑多线程,比如 4C8T,有8个 Logical CPU;
以 Intel i7-8809G 为例,是 4C8T,4核8线程,
因为支持超线程 (Hyper-threading),所以线程数是核心数的两倍,4个 Physical CPU / 物理 CPU,8个 Logical CPU / 逻辑 CPU:
在 Linux 中 check CPU,可以得到 逻辑 CPU / 每个物理 CPU 上面的 cores / 每个物理 CPU 上面的逻辑 CPU
# Check physical CPUs echo "physical_cpu:" cat /proc/cpuinfo |grep "physical id"|sort |uniq |wc -l # 1, 一个物理 CPU,socket # Check logical CPUs echo "logical_cpu:" cat /proc/cpuinfo |grep "processor" -c # 8,4核8线程,8个逻辑 CPU # Check cores on each physical CPU (Hyper-threading not include) echo "core_per_phy_cpu:" cat /proc/cpuinfo |grep "core id" |sort |uniq |wc -l # 4,4个核心 cores # Check logical CPU nums on each physical CPU echo "logical_core_per_phy_cpu:" cat /proc/cpuinfo |grep "sib" |sort |uniq |awk -F ' ' '{print $3}' # 8,8个逻辑 CPU
3.1.2 CPU 虚拟化的实例
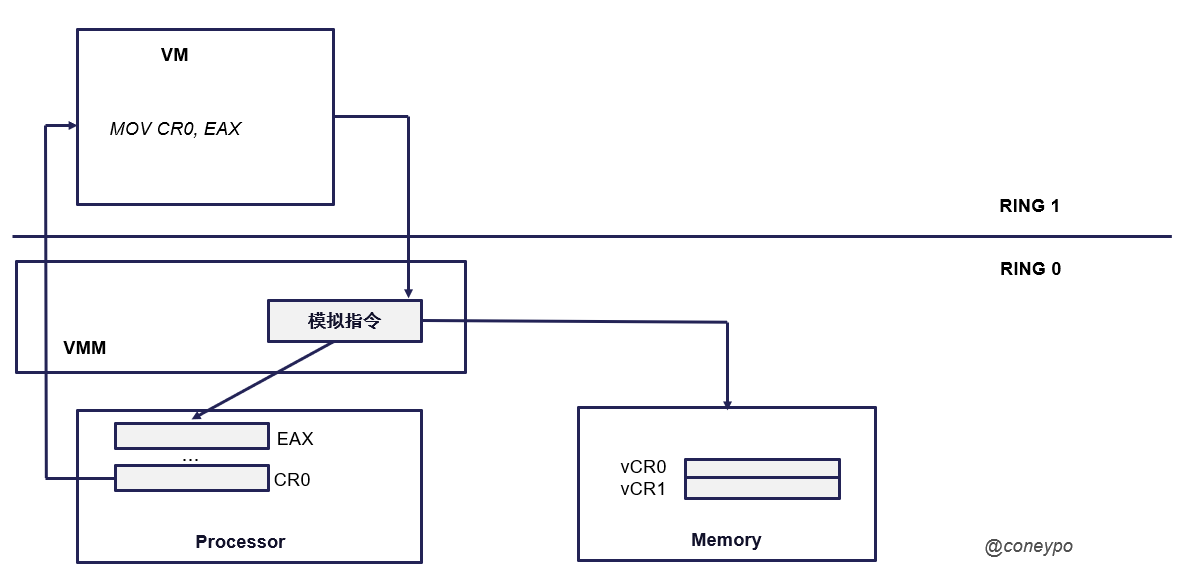
举一个例子,有一条指令 "MOV CR0, EAX",也就是将 EAX 寄存器的值,传给给寄存器 CR0;
3.1.2.1 无虚拟化
如果没有 VMM,那么处理器将这条指令丢给 VM,操作系统可以访问物理处理器,处在最高特权模式,可以控制片上所有物理资源,直接对物理寄存器 CR0 进行赋值修改;
3.1.2.2 虚拟化引入
VMM 加入之后,我们的 VM 不是最高特权了,而 VMM 现在是最高特权,这时候对于片上关键资源的访问,就成了敏感指令,VMM 对于这种敏感指令的执行,会触发异常处理,从而陷入 VMM 进行模拟;
因为 VMM 的加入,所以会拦截掉处理器丢给 VM 的这条指令,读取 EAX 的值然后放到内存中,虚拟的 vCR0 中,这样的话执行该条 MOV 指令并不会改变真实的 CR0 的值;
下次如果要访问 CR0 值的时候,VMM 进行截获,返回的也是内存中虚拟的 vCR0 的值,而不是物理的 CR0;
3.2 内存虚拟化(Memory Virtualization)
3.2.1 无虚拟化
对于没有虚拟化的 native 环境,操作系统 OS 对于内存的管理和使用需要满足以下两点:
- 内存都是从物理地址 0 开始;
- 内存是连续的,或者至少在一些大的粒度(如 256MB)上是连续的;
3.2.2 虚拟化引入
虚拟化的引入,也要满足以上两点,所以我们对于 VM,引入了虚拟的 客户机物理地址空间 (Guest Physical Address, GPA) 概念;
关于地址和地址空间的介绍:
地址 是访问 地址空间 的索引,可以分为:
- 逻辑地址
- 存在于 X86 机制中,程序直接使用的地址,由 16位段选择符 和 23位偏移量 构成;
- 线性地址
- 又称虚拟地址,是逻辑地址转换后的结果,用于索引线性地址空间;当 CPU 使用 paging 分页机制时,线性地址必须转为物理地址才能访问平台内存/硬件资源
- 物理地址
- 用于索引物理地址空间;
- 分页和分段机制都启动:逻辑地址 -> 线性地址 -> 物理地址
- 分段启动,分页不启动:逻辑地址 -> 线性地址 = 物理地址
Address Space, 地址空间
Memory, 内存可以视为一个大的数组,地址就是这个大数据的索引;
而地址空间则是一个更大的数组,是所有可用资源的集合,地址就是这个数组的索引;
Address Space 可以分为两类:
- Physical Address Space / 物理地址空间
- Linear Address Space / 线性地址空间
在虚拟化环境下,内存的调度使用,需要进行两层转换(GVA->GPA,GPA->HPA):
- 从 客户机虚拟地址 (GVA, Guest Virtual Address) 到 客户机物理地址 (GPA,Guest Physical Address)(由客户机操作系统负责)
- 从 客户机物理地址 (GPA,Guest Physical Address)到 宿主机物理地址 (HPA, Host Physical Address)(由 Hypervisor 负责)
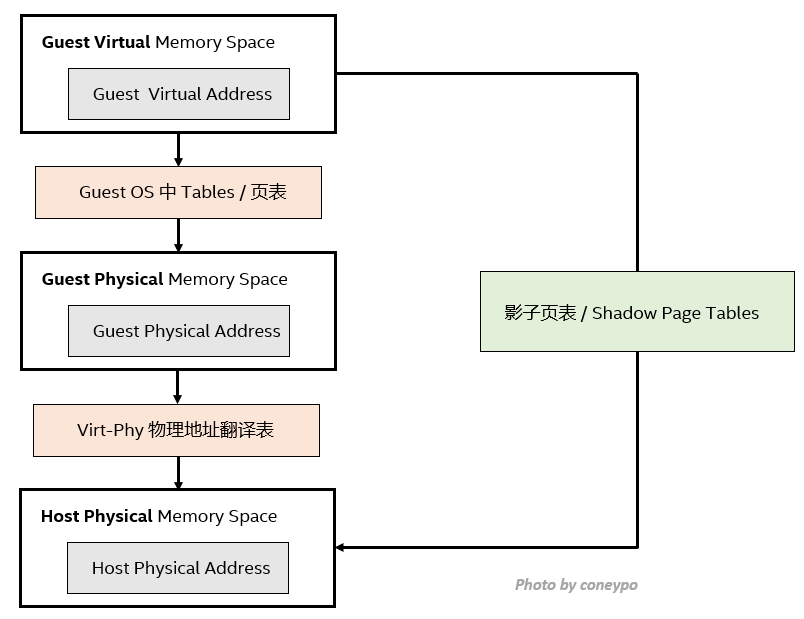
所以内存虚拟化其实解决了如下两个问题:
1. 虚拟机维护 客户机物理地址 / GPA 到 宿主机物理地址 / HPA 的映射;
2. 截获 VM 对于 客户机物理地址 / GPA 的访问,并且根据映射关系,将其转换为 宿主机物理地址 / HPA;
3.3 I/O 虚拟化
3.3.1 I/O 访问方式
CPU 需要通过 I/O 来访问外部资源,x86 中的 I/O 根据访问方式不同,可以分为两类:
- Port I/O,通过 I/O 端口号来访问设备寄存器;
- MMIO(Memory Map I/O),通过内存访问的方式访问设备寄存器或者设备 RAM;
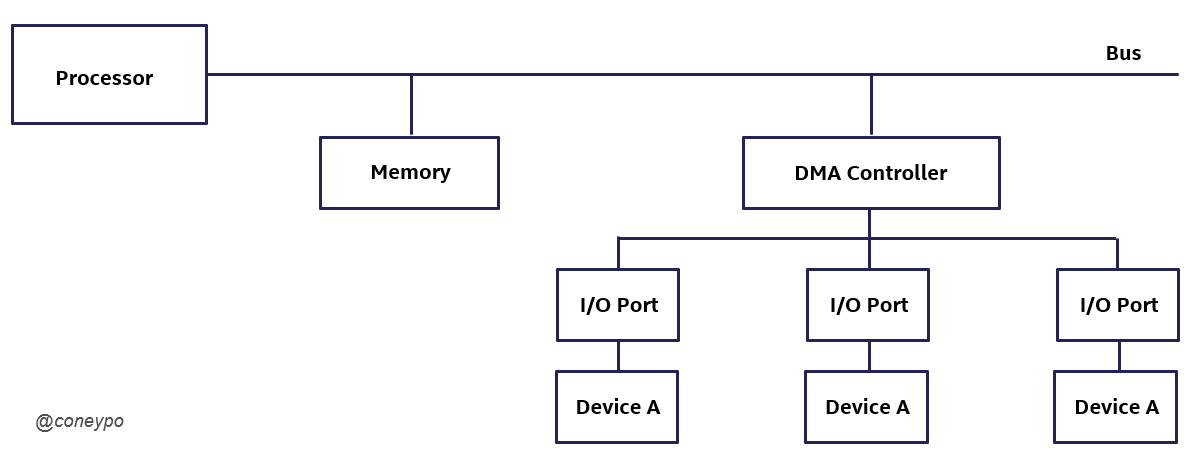
3.3.2 DMA
引入 DMA (Direct Memory Access) / 直接内存读取 的概念;
通过 DMA 控制器可以直接访问硬件设备资源,不需要 CPU 的参与(如果设备向内存复制数据都要经过 CPU 的话,会占用 CPU 时间降低系统性能);
根据 DMA 的特性,如果一个 I/O 设备是支持 DMA 的,那么我们可以绕过处理器来直接访问目标内存(如果设备的驱动未加修改,那么设备模拟器接收到的 DMA 目的地址就是客户机的物理地址);
3.3.3 设备模型(Device Model)
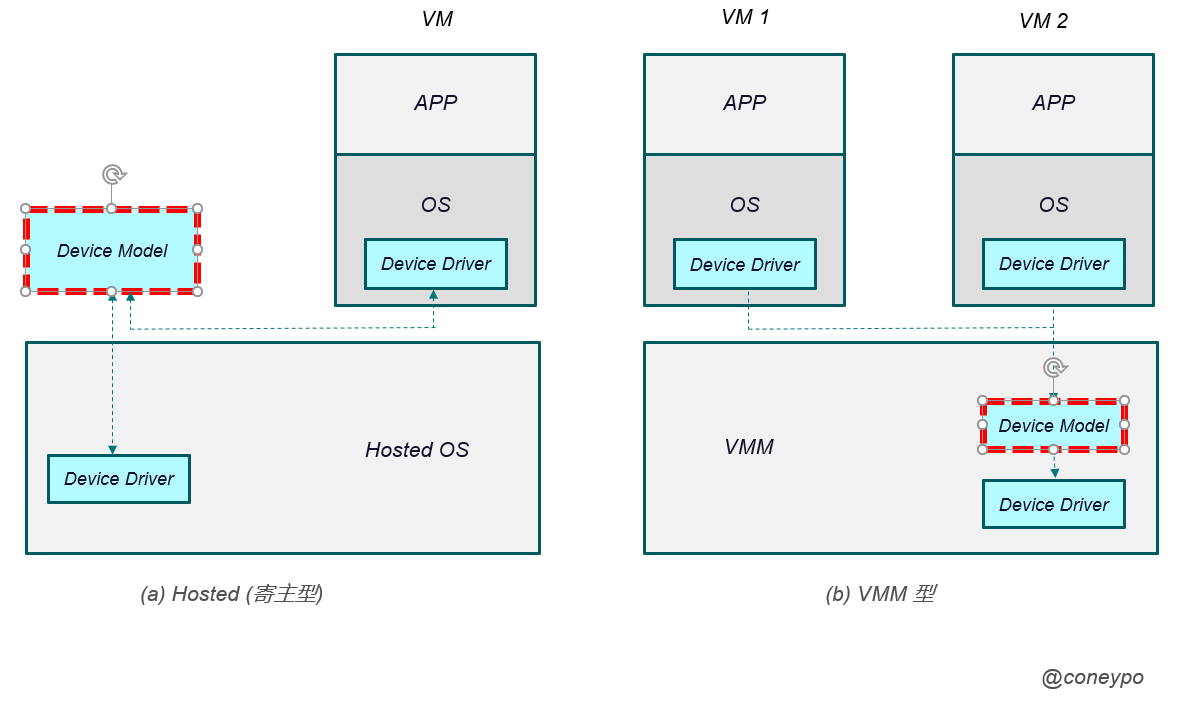
VMM 中要进行 I/O 设备的模拟,并且要能够处理和响应设备的请求,这个功能由 设备模型(Device Model) 来完成;
设备模型 需要模拟出目标设备的软件接口和功能,独立于设备的驱动,通过下图中这种调用方式:

设备模型 是虚拟机设备驱动(Device Driver)和实际设备驱动之间的一个模块;
当客户机请求 I/O,作为内核模块的 VMM 会将 I/O 请求进行拦截,然后通过宿主机的内核态-用户态接口,传递给用户态的 设备模型 进行处理;
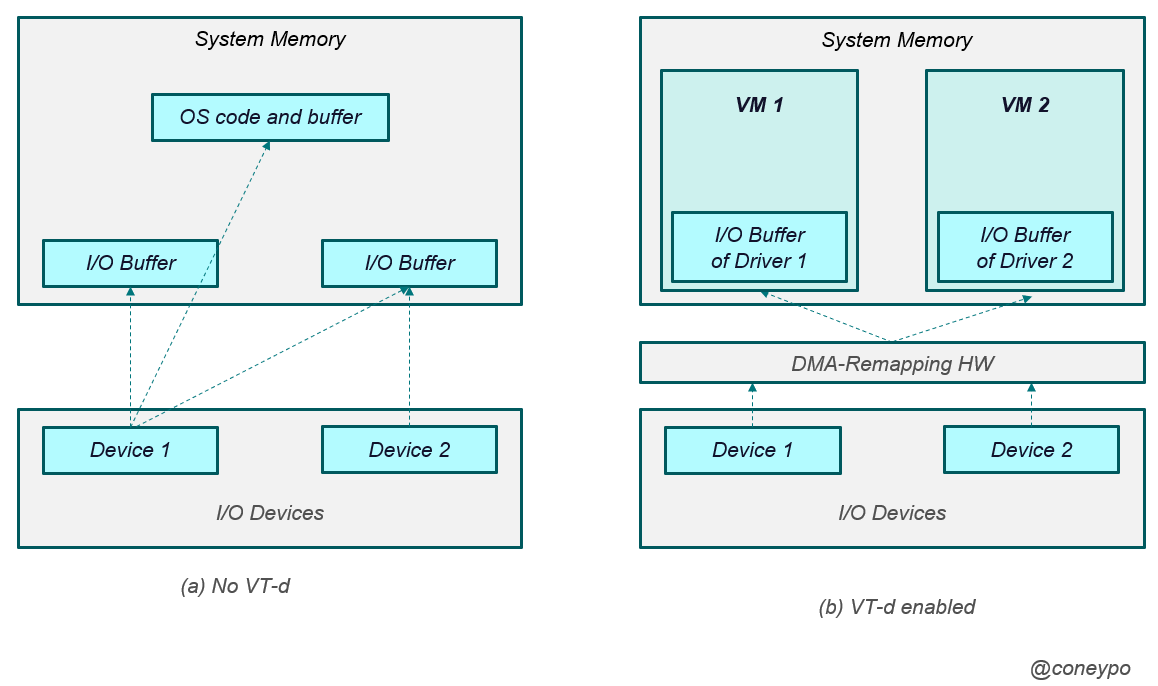
3.3.5 Intel VT-d
无 VT-d 引入,那么 I/O 设备的 DMA 可以访问整个物理内存;
如果我们引入 VT-d, Intel 的 VT-d 是从硬件上支持 I/O 虚拟化,在北桥上引入 DMA-Remapping (DMA 重映射)硬件,如下图中的右图(DMA-Remapping HW);
这样的话,虚拟机中对于 I/O 设备的访问,都会被 DMA 重映射硬件 截获,然后查找对应 I/O 设备的页表,重映射硬件对 DMA 中的地址进行转换,而不是让 I/O 设备直接对物理内存直接访问;
、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号