


1、schema和数据类型优化
1、Schema优化
Schema的设计非常重要,良好的Schema设计能够提高mysql的性能
1.1.一些错误的Schema设计:
太多的列
MySQL的存储引擎API工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列。从行缓冲中将编码过的列转换成行数据结构的操作代价是非常高的。MyISAM的定长行结构实际上与服务器层的行结构正好匹配,所以不需要转换。然而,MyISAM的变长行结构和InnoDB的行结构则总是需要转换。转换的代价依赖于列的数量。如果计划使用数千个字段,必须意识到服务器的性能运行特征会有一些不同。
太多的关联
所谓的“实体-属性-值”(EAV)设计模式是一个常见的糟糕设计模式,尤其是在MySQL下不能靠谱地工作。MySQL限制了每个关联操作最多只能有61张表,但是EAV数据库需要许多自关联。我们见过不少EAV数据库最后超过了这个限制。事实上在许多关联少于61张表的情况下,解析和优化查询的代价也会成为MySQL的问题。一个粗略的经验法则,如果希望查询执行得快速且并发性好,单个查询最好在5个表以内做关联。
1.2.小结
1、 尽量避免过度设计,例如会导致及其复杂查询的schema设计,或者有很多列的表的设计
2、 使用小而简单的合适数据类型,除非真实数据模型中有确切的需要,否则应该尽可能地避免使用null值
- 如果查询中包含可为NULL的列,对Mysql来说更难优化,因为可为NULL的列使得索引,索引统计和值比较都更复杂。
- 含NULL复合索引无效.
- 可为NULL的列会使用更多的存储空间,在Mysql中也需要特殊处理。
- 当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在MyISAM里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
2、数据类型优化
mysql支持很多数据类型,在项目开发时,如何根据业务选择正确的数据类型非常重要
2.1.原则
- 更小的通常更好
- 一般情况下,应该尽量使用可以正常存储数据的最小数据类型。更小的数据类型通常更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少
- 简单就好
- 简单数据类型需要更少的CPU周期,整型比字符串操作代价更低,比如应该用整型存储ip地址,使用mysql内建的date,time,datetime而不是字符串储存时间
- 尽量避免null
- 通常情况下最好制定列为not null,因为可为null的列使得索引、索引统计和值比较都更复杂。可为null的列占据更多的存储空间,被索引时也需要一个额外的字节
- 选择数据类型时首先确定合适的大类型,比如数字、字符串、时间,然后选择具体类型
2.2.整数类型
数字有两个类型:整数和实数,如果存整数可以选择
TINYINT , SMALLINT , MEDIUMINT , INT , BIGINT 分别使用 8 16 24 32 64位存储空间,存储的值范围从 -2的(N-1)次方到2的(N-1)次方-1,N是存储空间位数
整数类型有可选的UNSIGNED属性,表示不允许负值,可以使正数的上限提高一倍
mysql可以为整数类型指定宽度,比如INT(11),但是没有什么太大意义,INT(1)和INT(20)是相同的

2.3.实数类型
实数就是带小数部分的数字。然而,它们不只是为了存储小数部分,也可以使用DECIMAL存储比BIGINT还大的整数
CPU不支持对DECIMAL的直接计算,在MySQL5.0以及更高版本中,MySQL服务器自身实现了对DECIMAL的高精度计算,相对而言,CPU直接支持原生浮点计算,所以浮点运算明显更快
浮点类型在存储同样范围的值时,通常比DECIMAL使用更少的控件,FLOAT使用4个字节,DOUBLE占用8个字节,DOUBLE相比FLOAT有更高的精度和更大的范围,Mysql使用DOUBLE作为内部浮点计算的类型,在数据量较大时采用BIGINT
2.4.字符串类型
VARCHAR和CHAR类型是最主要的字符串类型
VARCHAR
VARCHAR类型用于存储可变长字符串,是最常见的字符串数据类型,他比定长类型更省空间,因为它仅仅使用必要的空间
VARCHAR需要使用1或者2个额外字节记录字符串的长度,如果列的最大长度小于等于255字节,则只使用一个字节表示,否则使用2个字节,MySQL 5.0以上的VARCHAR在存储和检索时会保留末尾空格,过长的VARCHAR存储为BLOB
在以下场景使用VARCHAR:
- 字符串列的最大长度比平均长度大很多
- 列的更新很少
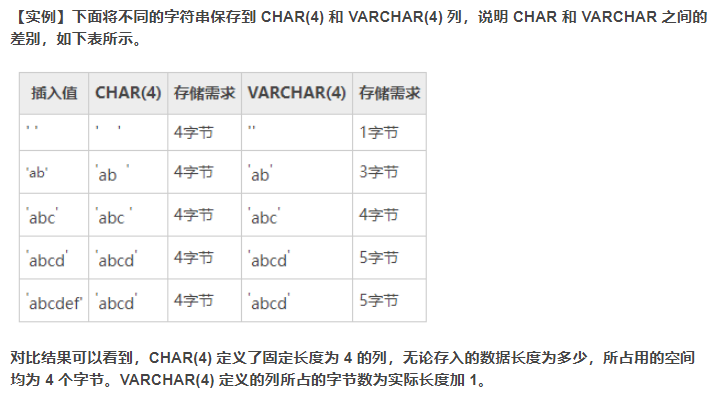
注:VARCHAR虽然是可变长字符串,但是还是要根据业务需要设置长度,因为变长是需要消耗性能的,如果差距较大意味着CPU消耗大
使用VARCHAR(5)和VARCHAR(200)存储‘hello’的空间开销是一样的,但是更长的列会消耗更多的了内存,因为mysql通常会分配固定大小的内存来保存内部值。最好的策略是只分配真正需要的空间
CHAR
CHAR是定长的,当存储CHAR时会删除所有的末尾空格,CHAR适合存储很短的字符串,或者所有值都接近同一个长度,对于经常变动的值CHAR的表现也比VARCHAR要好很多
2.5.日期和时间类型
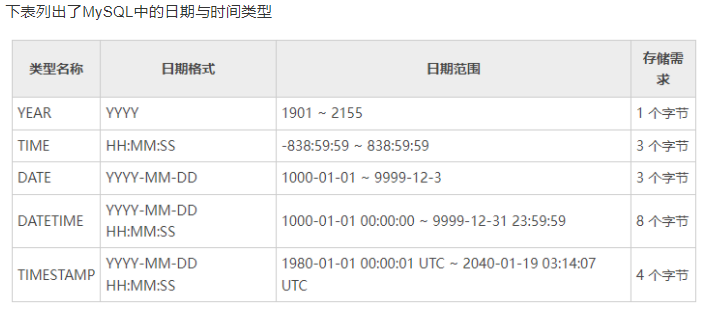
mysql有很多类型保存日期和时间值,比如YEAR和DATE,mysql能存储的最小时间粒度为秒,mysql提供两种近似的日期类型,DATETIME和TIMESTAMP,在很多场景他们是类似的,但是也有区别
DATETIME
这个类型能保存大范围的值,从1001年到9999年,精度为秒,使用8个字节空间
TIMESTAMP
TIMESTAMP类型保存了从1970年1月1日午夜以来的秒数,只使用4个字节的存储空间,范围要比DATETIME小很多,只能表示1970年到2038年
TIMESTAMP 的特殊属性:
在插入数据时如果没有指定值,会自动填充为当前时间。
TIMESTAMP 默认为 NOT NULL。
通常应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高。
如果需要存储比秒更小粒度的日期和时间值,可以使用BIGINT类型存储微秒级别的时间截,或者使用DOUBLE存储秒之后的小数部分。
3、范式与反范式
原则
1、 核心业务使用范式。类似于交易这种敏感核心业务,强调数据安全和一致性,需要遵循范式保证机密数据不被破坏,核心业务不出现不一致的情况
2、 弱一致性-反ACID.在一些对数据要求一致性不高的场合,不必完全遵循ACID。如在线人数统计,用户选择习惯等。流行的NoSQL技术,就是基于弱一致性需求,降低数据完整性和一致性换取效率的
3、 空间换时间,冗余换效率。如冗余表,在一些联合查询耗时间,且不需要有实时性要求的情况下,可以考虑冗余表。一般是定期转储。如美术外包外包商活跃度,可以按每天进行一次数据转储到冗余表。
4、存储引擎选择
选择存储引擎的基本原则如下:
1、采用innoDB
- 读写比较小(小于100:1),频繁更新大字段
- 表数据量大(其实大部分情况选择innoDB即可),并发高
- 安全性和可用性高
2、采用MyISAM
- 读写比大于100:1且update相对较少
- 并发不高,不需要事务
- 表数据量小
3、采用Memory
- 有足够内存
- 对数据一致性要求不高,如在线人数和session等应用
- 如果需要一个用于查询的临时表,可以选择MEMORY存储引擎。

