使用xinference推理框架接入Langchain3.0部署各类LLM教程
使用Langchain部署各类LLM
一. 配置环境
-
安装anaconda,方便管理包
参考链接> https://blog.csdn.net/fly_enum/article/details/139753360 -
安装Visual studio2019,一站式解决Cmake编译器等需要
安装包在u盘里,解压后双击vs_setup.exe。
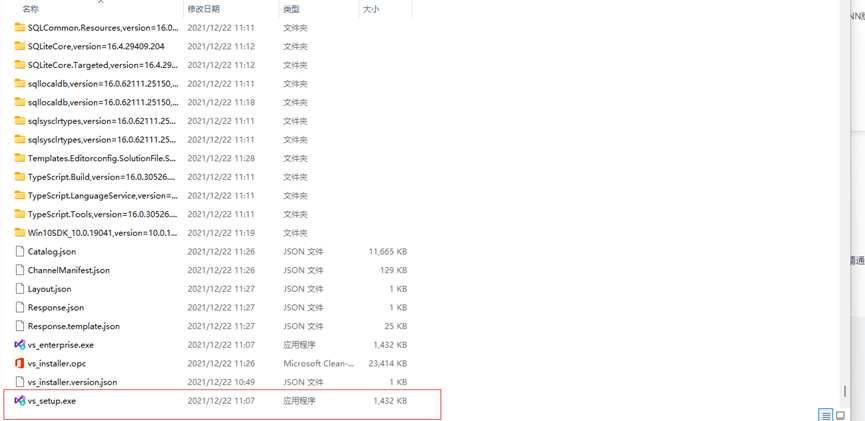
安装需要将使用c++的桌面开发勾选,剩下看自己需要是否安装。
3.安装CUDA、cuDNN 和 PyTorch,使用深度学习和GPU需要(注意版本)
安装的CUDA版本需要大于11.8,最好是CUDA 版本: == 12.1 ,Python 版本 == 3.11.
参考链接:> https://blog.csdn.net/2301_81210371/article/details/140492162
CUDA版本推荐

CUdnn版本推荐
Pytorch版本推荐

二 部署模型
参考视频
- 安装xinferenc推理框架
参考链接
https://blog.csdn.net/YWGGWY/article/details/140399092
从0.3.0版本起,Langchain-Chatchat不再根据用户输入的本地模型路径直接进行模型加载,涉及到的模型种类包括LLM、Embedding、Reranker及后续会提供支持的多模态模型等,均改为支持市面常见的各大模型推理框架接入,如Xinference、Ollama、LocalAI、FastChat、OneAPI等。因此,请确认在启动Langchain-Chatchat项目前,首先进行模型推理框架的运行,并加载所需使用的模型。
2.新建一个虚拟环境
conda create -n xinference python==3.11
3.开始激活新建好的环境
conda activate xinference
4.Xinference 在 Linux, Windows, MacOS 上都可以通过 pip 来安装。如果需要使用 Xinference 进行模型推理,可以根据不同的模型指定不同的引擎。
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
5.PyTorch(transformers) 引擎支持几乎有所的最新模型,这是 Pytorch 模型默认使用的引擎:
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
3.安装lanchain
看langchain下载的readme文件和前面的视频
需再次新建一个环境
conda create -n langchain python=3.10(默认版本)
pip install langchain-chatchat -U
pip install "langchain-chatchat[xinference]" -U
参考链接
模型可以直接在xinference里下载直接加载,但是最好把模型下载到本地加载到langchain里,这样里面的代码部分可以调整更改包括模型微调,下载模型不FQ可以去魔塔社区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号