计算机体系结构--指令Cache设计verilog实现
前段时间一直在做MIPS CPU的设计,并且同步学习了一些计算机体系结构的相关知识,五级流水线单周期CPU设计已经完善了,本文主要记录一下指令Cache的设计及实现。
一、Cache设计思路
很多文章和书籍都详细得介绍了Cache的内容,具体内容可以自行查阅,本人参考的书籍是姚永斌老师著的《超标量处理器设计》以及网上一些优秀的博客。
指令Cache (ICache) 的模块框架如下:(一般L1-Cache是集成在CPU内的,这里框图描述将两者分开了)
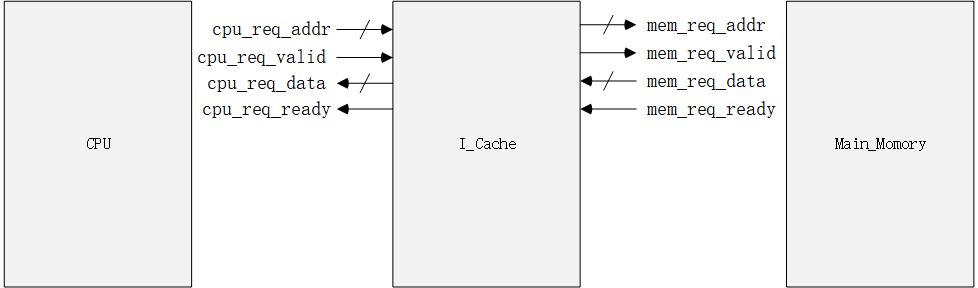
端口信号比较清晰,与CPU的接口有:来自CPU的请求信号和地址信号,返回给CPU的有效与数据信号。而访问指令存储器的接口信号也一样,对称设计。
这里唯一的区别是访存时Cache一次读取4个字,也就是128bit。但是Cache返回给CPU是一个字(一条指令)也就是32bit。所以mem_req_data与cpu_req_data数据位宽是不一样的。这样的差别主要与Cacheline的设计相关,一次从内存取多少数据完全是根据具体需求来。
I_Cache内部的逻辑实现主要由状态机来进行控制。我们知道Cache得到一个地址先要查询地址中对应的Index,寻址到对应的Cacheline,判断有效位V是否为1,如果为0那么代表这条Cacheline还没被主存映射,如果为1那么再对比Tag位,如果相等就表示命中hit,就可以根据地址中的offset位来寻址Cacheline中具体的数据位置,返回需要的数据给CPU。指令Cache一般是不往里面写数据的,但是必须要注意到Cacheline中有一个脏位Dirty,是在写入策略中起到作用的。程序中的store指令需要往主存中写入数据,如果直接写到主存中那么速度很慢,CPU没法等,就可以先写到Cacheline中,并把Dirty位置1,如果下次需要替换这条Cacheline,那么再把这条Cacheline的内容写到主存中,并把dirty位清0。相当于缓存了需要store的数据。这种方式称之为写回策略Write Back。直接写到主存中的写入策略称之为写通Write Through。
本文的I_Cache是基于2路组相连 2-way set-associated映射方式的Cache,主存设计为128KB,Cache一共有16组。因此PC地址划分为:

当然上面只介绍了命中Cache的行为,当Cache丢失miss怎么办呢?这时候就需要用地址访问主存,并把对应的数据加载到Cache中,替换策略可以分为写替换策略和读替换策略,具体的实现方法也很多,比如LRU近期最少使用算法,FIFO替换,或者随机替换算法。本文使用了一个简单的替换方法。打算后续在实现数据Cache时学习LRU算法的设计。
从上面的分析可以以及模块接口信号的描述可以设计状态机,具体实现如下:
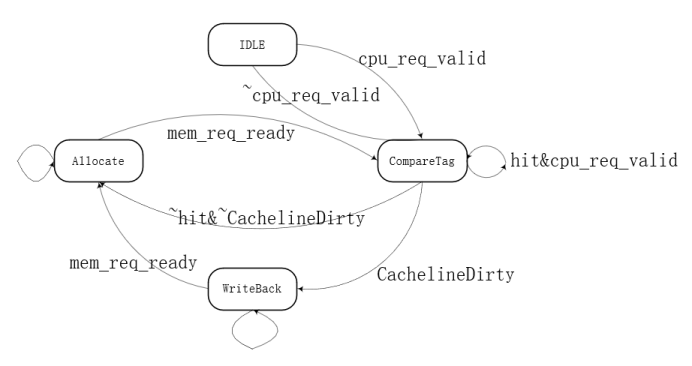
状态机分为四个状态:IDLE+CompareTag+WriteBack+Allocate 分别对应上文对应的Cache行为,这里就不阐述了。
RTL代码如下:


1 //2-way set associate cache 2 //addressing 2*index+0/1 3 //capacity 4Kb 4 `include "macro.v" 5 module I_Cache( 6 input wire clk, 7 input wire rst, 8 //to mem 9 output reg [`InstAddrBus] mem_req_addr, 10 output reg [127:0] mem_wr_data, 11 output reg mem_req_valid, 12 output reg mem_req_wr, //read only 13 input wire [127:0] mem_req_data, 14 input wire mem_req_ready, 15 //to CPU 16 input wire [`InstAddrBus] cpu_req_addr, 17 input wire cpu_req_valid, 18 input wire cpu_req_wr, 19 output reg [`RegBus] cpu_req_data, 20 output reg cpu_req_ready 21 ); 22 23 24 localparam IDLE=4'b0001,CompareTag=4'b0010,WriteBack=4'b0100,Allocate=4'b1000; 25 localparam V=141,D=140,U=139,TagMSB=138,TagLSB=128,DataMSB=127,DataLSB=0; 26 wire hit,way1hit,way2hit; 27 wire CachelineDirty; 28 reg way; //cache miss,evict cacheline 29 wire [3:0] cpu_req_index; 30 wire [23:0] cpu_req_tag; 31 wire [1:0] cpu_req_offset; 32 integer i; 33 wire mem_ready_valid; 34 reg [141:0] cache_data [31:0]; 35 reg [3:0] state,next_state; 36 37 38 assign way1hit = cache_data[2*cpu_req_index][V]==1'b1 && cache_data[2*cpu_req_index][TagMSB:TagLSB]==cpu_req_tag; 39 assign way2hit = cache_data[2*cpu_req_index+1][V]==1'b1 && cache_data[2*cpu_req_index][TagMSB:TagLSB]==cpu_req_tag; 40 41 //Byte addressing 42 assign cpu_req_index = cpu_req_addr[7:4]; 43 assign cpu_req_tag = cpu_req_addr[31:8]; 44 assign cpu_req_offset = cpu_req_addr[3:2]; 45 46 assign mem_ready_valid = mem_req_valid & mem_req_ready; 47 48 assign hit = way1hit | way2hit; 49 assign CachelineDirty = cache_data[2*cpu_req_index+way][V:D]==2'b11; 50 51 //FSM 52 always @(posedge clk) begin 53 if (rst) begin 54 // reset 55 state <= IDLE; 56 end 57 else begin 58 state <= next_state; 59 end 60 end 61 62 always @(*) begin 63 case(state) 64 IDLE: next_state = cpu_req_valid ? CompareTag : IDLE; 65 CompareTag:begin 66 if (cpu_req_valid) begin 67 if (hit) begin 68 next_state = CompareTag; 69 end 70 else if (CachelineDirty) begin 71 next_state = WriteBack; 72 end 73 else begin 74 next_state = Allocate; 75 end 76 end 77 else begin 78 next_state = IDLE; 79 end 80 end 81 WriteBack: next_state = mem_req_ready ? Allocate : WriteBack; 82 Allocate: next_state = mem_req_ready ? CompareTag : Allocate; 83 default:begin 84 next_state = IDLE; 85 end 86 endcase 87 end 88 89 //way 90 always @(*) begin 91 if (!hit) begin 92 case({cache_data[2*cpu_req_index][V],cache_data[2*cpu_req_index+1][V]}) 93 2'b00:way=1'b0; 94 2'b01:way=1'b0; 95 2'b10:way=1'b1; 96 2'b11:way=1'b0; 97 default:way=1'b0; 98 endcase 99 end 100 end 101 102 //cpu_req_data 103 always @(*) begin 104 if (rst) begin 105 // reset 106 cpu_req_data <= 'd0; 107 end 108 else if (state==CompareTag && hit) begin 109 cpu_req_data <= way1hit ? cache_data[2*cpu_req_index][(3-cpu_req_offset)<<5+:31] : 110 cache_data[2*cpu_req_index+1][(3-cpu_req_offset)<<5+:31]; 111 end 112 else begin 113 cpu_req_data <= cpu_req_data; 114 end 115 end 116 117 //cache_line data update 118 always @(posedge clk) begin 119 if (rst) begin 120 // reset 121 for(i=0;i<32;i=i+1)begin 122 cache_data[i] <= 'd0; 123 end 124 end 125 else if (state==WriteBack && mem_ready_valid==1'b1) begin 126 cache_data[2*cpu_req_index+way][D] <= 1'b0; 127 end 128 else if (state==CompareTag && CachelineDirty==1'b1) begin 129 cache_data[2*cpu_req_index+way][D] <= 1'b1; 130 end 131 else if (state==Allocate && mem_ready_valid==1'b1) begin 132 cache_data[2*cpu_req_index+way][V] <= 1'b1; 133 cache_data[2*cpu_req_index+way][DataMSB:DataLSB] <= mem_req_data; 134 cache_data[2*cpu_req_index+way][TagMSB:TagLSB] <= cpu_req_addr[cpu_req_tag]; 135 end 136 end 137 138 //cpu_req_ready 139 always @(*) begin 140 if (state==CompareTag && hit==1'b1) begin 141 cpu_req_ready <= 1'b1; 142 end 143 else begin 144 cpu_req_ready <= 1'b0; 145 end 146 end 147 148 //mem_req_addr 149 always @(*) begin 150 if (rst) begin 151 // reset 152 mem_req_addr <= 'd0; 153 end 154 else if (state==WriteBack || state==Allocate) begin 155 mem_req_addr <= cpu_req_addr; 156 end 157 end 158 159 //mem_req_valid 160 always @(posedge clk) begin 161 if (rst) begin 162 // reset 163 mem_req_valid <= 1'b0; 164 end 165 else if (state==CompareTag && hit==1'b0) begin 166 mem_req_valid <= 1'b1; 167 end 168 else if (state==WriteBack && mem_req_ready==1'b1) begin 169 mem_req_valid <= 1'b0; 170 end 171 else if (state==Allocate && mem_req_ready==1'b1) begin 172 mem_req_valid <= 1'b0; 173 end 174 end 175 176 //mem_wr_data 177 always @(posedge clk) begin 178 if (rst) begin 179 // reset 180 mem_wr_data <= 'd0; 181 end 182 else if (state==WriteBack) begin 183 mem_wr_data <= cache_data[2*cpu_req_index+way][DataMSB:DataLSB]; 184 end 185 end 186 187 endmodule
二、仿真验证
本人在进行设计与验证时也遇到了不少麻烦,主要是要与MIPS-CPU和主存协同设计,并不是只是设计个Cache和主存进行仿真就ok了,所以还涉及CPU中Program Couter模块部分的指令跳转问题,对于流控也进行了一些修改,可能代码也存在一些遗漏与不足,各位在阅读本文时可以根据思路自行修改与设计。
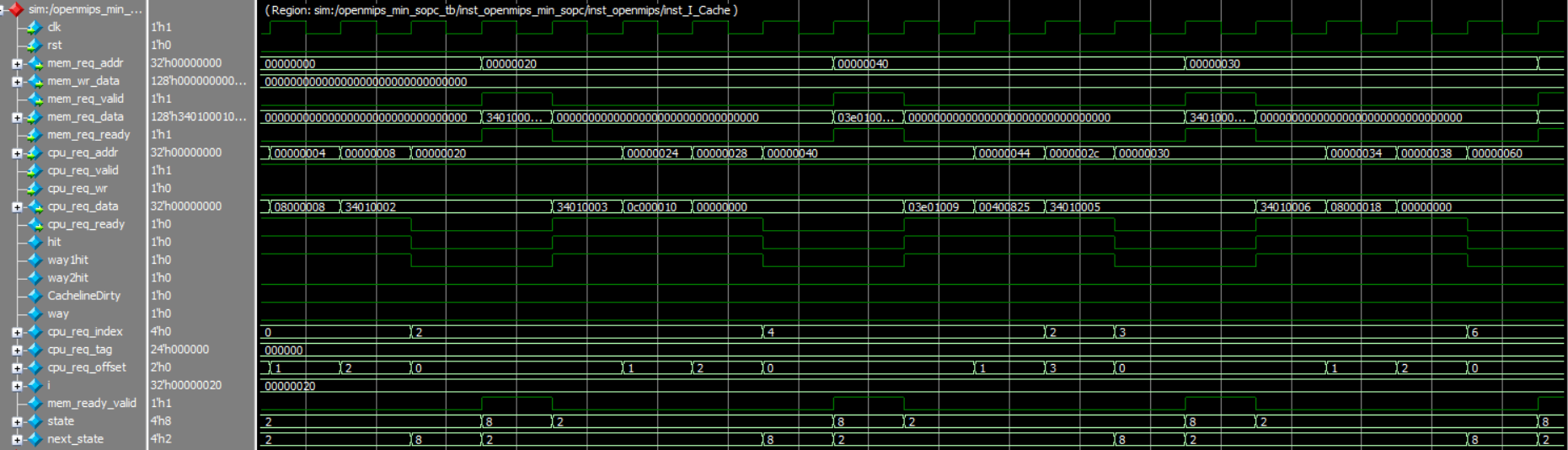
I_Cache模块的信号如上图所示,可以看到状态正确的实现跳转,state信号=8代表着进入Allocate阶段,=2表示进入了CompareTag阶段。同时可以看到Cache hit与miss情况。
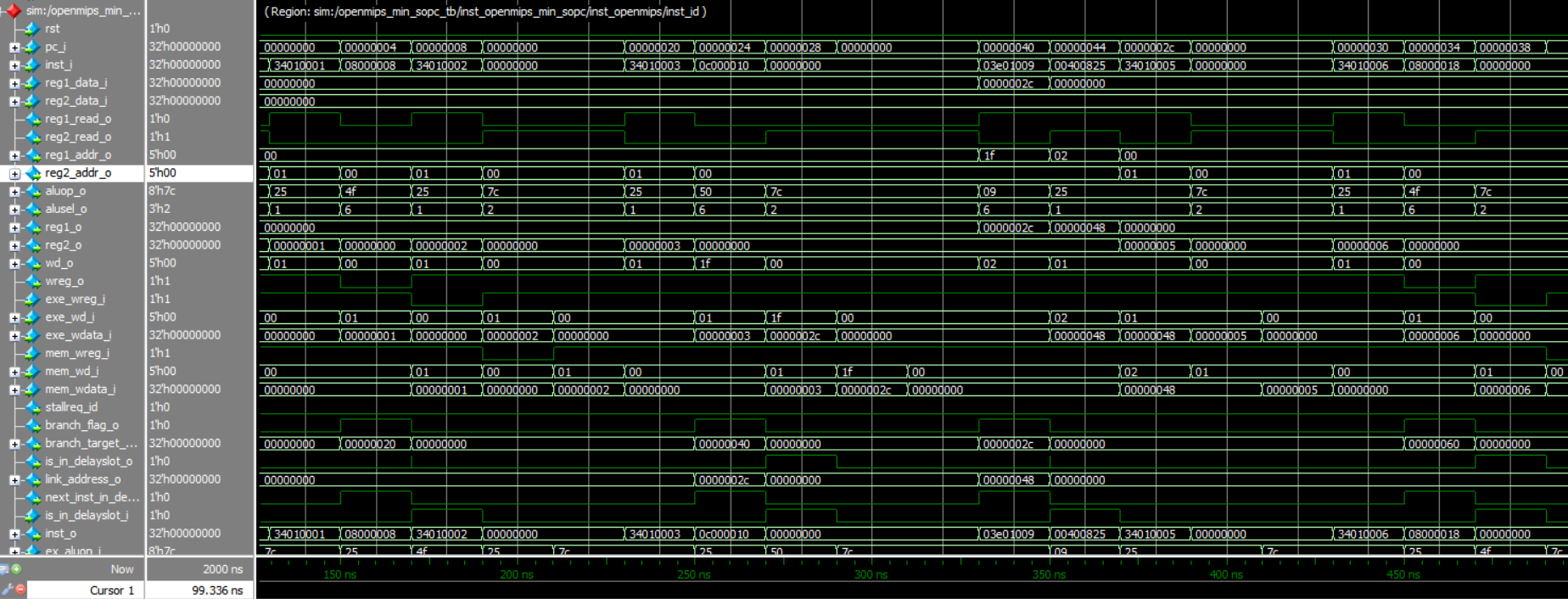
上图展示了CPU中译码阶段的执行情况,可以看到PC按顺序增加,并且在碰到跳转指令时正确的执行了跳转。pc_i信号中间为0的部分就是表示正在经历Cache读取主存进入了Allocate阶段,因此存在一些空指令,还存在可以优化的空间。
实际上如果能FPGA上板验证的话能更好的感受Cache的加速效果,毕竟modelsim仿真没法涉及真实的访存时间。 因此还需要更深入的学习与探讨!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号