动态分支预测 超标量处理器相关知识
一、引言
写这篇文主要是最近在学习超标量处理器的相关知识,并且在HDLBits上发现更新了几道题是与动态分支预测相关的。本人最喜欢理论结合实际工程,光看书上的理论实在理解太浅,因此特写此文作记录。
首先给出相关例题的链接 动态分支预测,没有相关知识基础去做这个题就非常迷惑,因此先打好理论基础。
二、理论内容
动态分支预测分为分支方向预测和分支目标地址预测,这里展开的内容是分支方向预测,即对于一个分支指令是采取跳转(taken)还是不跳转(not taken),分别用1和0来表示。
2.1 两位饱和计数器
要使用分支预测,首先看一个计数器——两位饱和计数器:
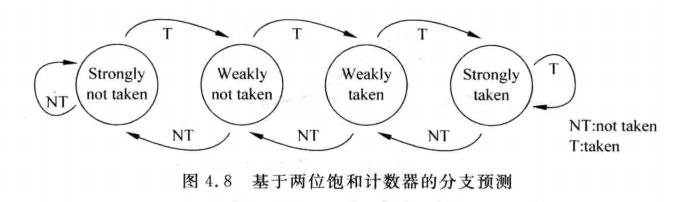
状态分别用00-01-10-11来表示,00和01表示不跳转,10和11表示跳转(至于编码也可以用Gray-code,低功耗且不易出错)。这个计数器的好处在于:如果处于11强跳转状态或00强不跳转状态,这个时候的预测指向很明显是固定的,但是如果中途有个小的跳变,也能抱有一定的裕量,因为会有一个弱跳转或弱不跳转的状态来延迟。但是这样预测也存在缺陷:如果是TNTNTN这样的情况,也就是一次跳转一次不跳转(一般计数器复位到01即弱不跳转的状态),就会导致预测正确率很低。
但是这个计数器依然重要,因为它是构成模式历史表(Pattern History Table,PHT)的基本元素。
2.2 PHT
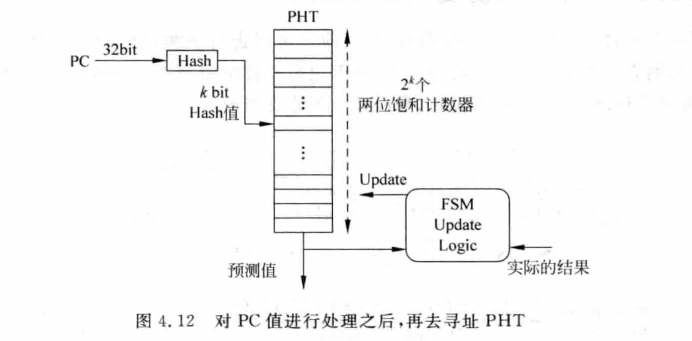
这里用PC值进行哈希计算得到一个k bit数值来寻址PHT,需要解释一下:
如果一条PC值对应一个PHT的表项(Entry),则需要的空间太大了(230x2 bit),所以可以用PC的一部分来寻址,比如中间k-bit大小的数值。但是用分支指令PC的k bit来寻址一个PHT,则可能会出现两个k值相同的分支指令PC值寻址到同一个表项(此现象称为别名-aliasing),因此用哈希计算得到一个固定数值的值来寻址,就能有效避免上述现象。一般可以用异或计算来计算出hash值。
2.2.1 两位饱和计数器的更新时间
那么什么时候更新PHT中两位饱和计数器的值呢?流水线的取指阶段?执行阶段?提交阶段?
答案是提交(Commit)阶段。因为对于取指阶段来说,此时分支预测的结果可能是错的,不能用错误的结果来更新PHT。对于执行阶段来说,如果采用了乱序执行的指令顺序,那么执行阶段得到的分支结果也不一定正确,它可能处在分支预测失败(misprediction)的路径上,会导致后续一个flush刷新流水线的操作。故只有在提交阶段,确保分支指令已经正确执行的情况下才可以进行PHT的更新。
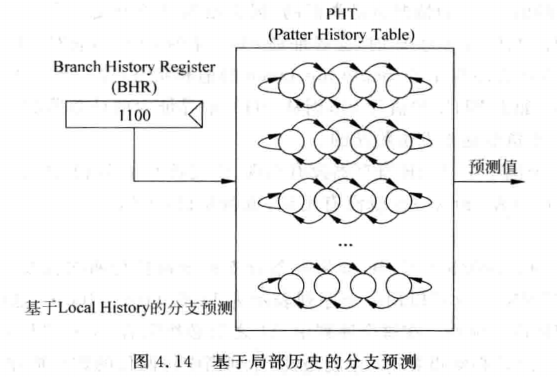
2.3 基于局部历史的分支预测-又称自适应两级分支预测(Adaptive Two-level Predictor)
考虑上文提到的TNTNTNTNTN情况,此时的分支预测准确率为0,当然这与计数器初始状态相关。但是这个跳转的情况其实是规律的,在这个基础上可以使用基于局部历史的分支预测器。在这个设计中一个关键的部件就是分支历史寄存器(Branch History Register-BHR)。
2.4 BHR
分支历史寄存器用于记录一个分支指令在过去的历史状态,比如上文提到的TNTNTNTNT(永远都是这个案例...),用一个2bit的BHR,则寄存器会出现01->10->01这样的情况,则这个分支指令的PC值对应的PHT的entry的两位饱和计数器会发生什么呢?BHR的2bit对应PHT有22=4个entry,地址分别是00,01,10,11。因此BHR=01对应的值寻址到第二个地址,BHR=10对应的地址寻址到底三个地址,因为BHR=01后面移入的值是0,因此地址01的的计数器会翻转到stronly not taken的状态,而BHR=10后面移入的是1,因此对应PHT地址10的计数器会翻转到strongly taken的状态。一段时间后PHT捕捉到这个分支指令的规律,后续用PHT的结果来输出预测值就能得到很高的准确率了。使得PHT中饱和计数器达到饱和的时间称为训练时间(Trainning time)。下图给出一个4-bitBHR的图示情况。
当然也要考虑到BHR的宽度,这里要考虑一个历史跳转情况的序列周期长度,比如000100010001这个跳转情况对应的T就是3(连续出现数字的周期),因此大于3的值都可以作为BHR的宽度。
上文的前提是每条分支指令都有一个对应的BHR和PHT,实际上不会有这么大的存储空间。真实情况如下图所示:
一般是对PC值进行哈希计算得到的结果来寻址BHT的地址,再用BHR的值与PC的一部分进行处理得到PHT的地址。
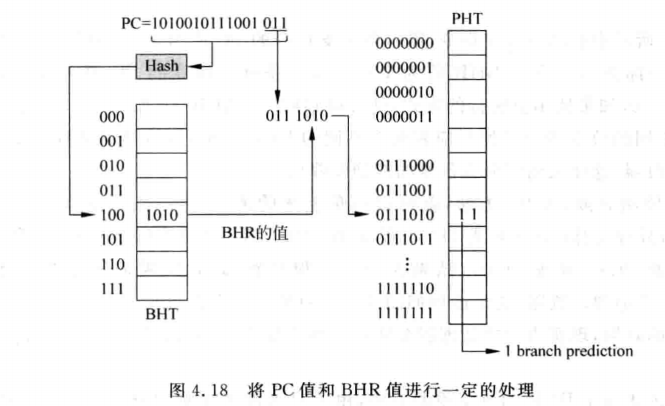 对PC值和BHR进行处理一个比较常用的方法就是异或,如下图所示:
对PC值和BHR进行处理一个比较常用的方法就是异或,如下图所示:
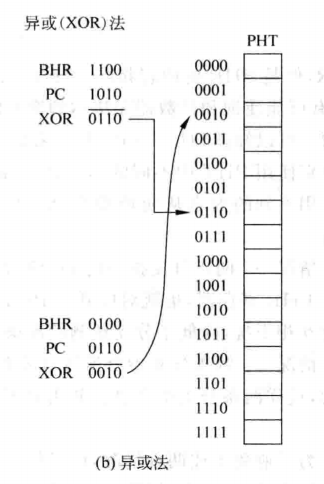
2.4 基于全局历史的分支预测
当遇到分支指令的循环周期太大的情况时,BHR的长度就需要非常大,且训练时间也会过长,在这之前分支预测的准确率会比较低,效率不高。同时PHT所占用的存储空间也过多,非常不适用。
基于全局和基于局部的分支预测最大的差别就是:基于局部历史的分支预测是根据分支指令自身在过去的执行情况来进行预测的,也就是说,它们并没有考虑到一条分支指令之前的其他分支指令对自身预测结果的影响。而有些时候,一条分支指令的结果并不取决于自身在过去的执行情况,而是和它前面的分支指令的结果是息息相关的,这就需要使用到基于全局历史的分支预测。
一个浅显易懂的例子:

上图的程序,如果如果分支b1和b2都执行了,那么分支b3就不会执行,只依靠分支b3的局部历史进行分支预测,是永远不会发现这个规律的,因此需要在预测分支b3的时候将前面的分支b1和b2的结果也考虑进去。基于全局,那么就需要一个全局历史寄存器(Global History Register-GHR),全局历史——但是这个寄存器不会保存所有的分支情况(那像话吗?),所以也是有限长的。其余部分跟基于局部历史的分支预测类似,需要用到GHR来寻址PHT,PHT还是两位饱和计数器的设计。上例中如果GHR的LSB2位为11,代表两个分支都taken,所以b3就会预测not taken,一段时间训练后就能捕捉到这个规律,计数器也能饱和了,后续的预测就是正确率比较高了。
理想情况下应该是下图所示:
也是对PC值进行哈希计算得到的数值用来寻址对应的那一个PHT,然后GHR数值寻址PHT的对应entry。

不过一个特别的点是:上图中只用到一个GHR,而基于历史的分支预测使用到了BHT,一组分支历史寄存器的表。如果对PHT也简化设计,即PHTs只用到一个PHT,那就如下图所示
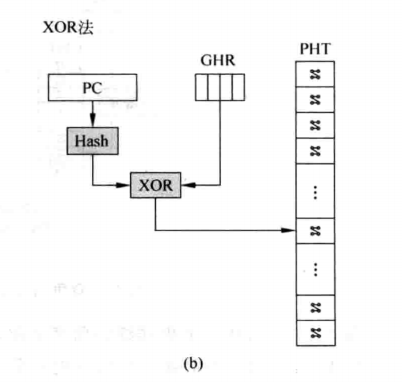
利用PC的哈希值与GHR进行异或得到PHT的entry地址,就可以完成训练和预测了。
2.5 分支预测的更新
对于分支指令的方向预测,需要更新的内容是BHR/GHR和PHT。这里对2.2.1的更新方法要重新定义,GHR该在哪个阶段更新,取指阶段?执行阶段?提交阶段?
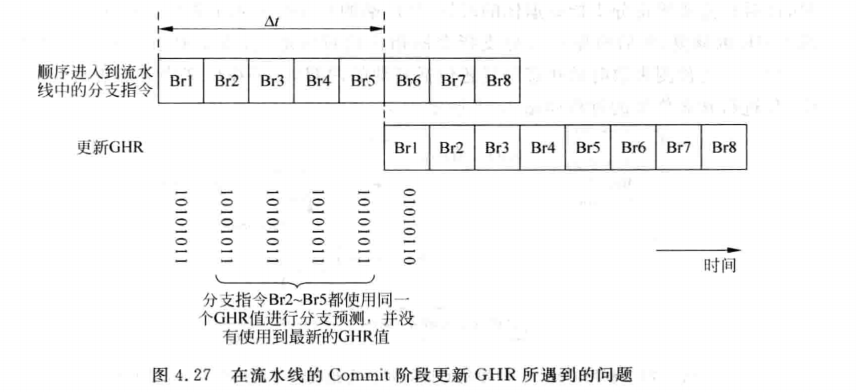
如果是按照方法三提交阶段更新,那么虽然保守且安全,但考虑到现代超标量处理器每周期执行多条指令,并且流水线深度比较大。当一条分支指令提交时,跟随其后的很多指令已经进入流水线了,这样后续的指令都无法使用分支预测器的结果。更概括地来说,一条分支指令b在时间 t 被分支预测,在时间 t+△t 从流水线中退休并更新GHR,任何在 △t 时间段之内被预测的分支指令,都不会从分支指令b的结果中获益(因为此时分支指令b的结果还没有写入到GHR当中)。尤其是当分支指令b前面存在产生D-Cache缺失的load指令时,会使分支指令b到达退休阶段所需要的时间变得更长,后续很多的分支指令在进行分支预测的时候,都无法使用分支指令b的结果,这就降低了分支预测的准确度,如下图所示:
如果是按照方法二在执行阶段更新,那么会提早几个周期,这样一定程度上减小了后续分支指令使用GHR进行预测时的负面影响。但是超标量处理器流水线取指与执行阶段仍然会有很多的指令在执行,考虑到乱序执行,执行阶段的分支指令可能处在预测失败的路径上,所以这个阶段更新GHR也不合理。
综合下来应该采用方法一,在取指阶段进行更新!根据分支预测的结果对GHR进行更新可以使后续指令使用到最新的GHR,若预测失败后续指令使用了错误的GHR也没影响,因为都处在预测失败mis-prediction的路径上,到最后都会被flush掉。需要关注的是预测失败应该采用一种机制来恢复GHR。
2.5.1 修复机制一
在提交阶段进行修复。这里用到两个GHR,前端的GHR用于预测,后端的GHR已经是正确的结果了,因此需要修复时把后端的GHR写到前端的GHR就可实现修复。然后根据这条分支指令的目标地址重新取指执行即可,具体架构如下图所示:
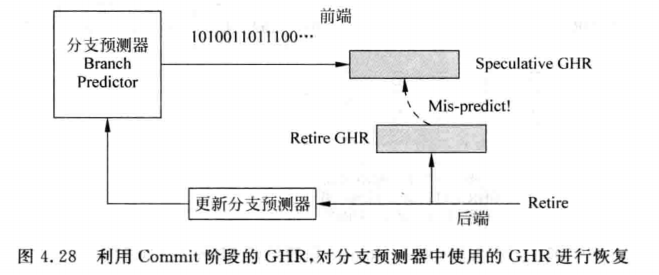
这种方式的缺点是预测失败时penalty过大,因为此时进入流水线的所有指令都要flush掉,会大幅降低处理器的性能。
2.5.2 修复机制二
Checkpoint修复法,对于GHR的更新是在取指阶段,但是更新后可以将旧的GHR保存起来,称为Checkpoint GHR,任意时刻这个分支是否执行的结果被计算出来就可以检查跳转正确与否了,若预测失败就把Checkpoint GHR更新到GHR即可,如下图所示:
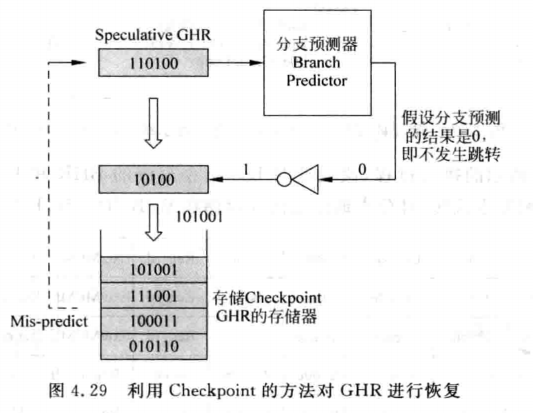
由于新的分支指令的结果会从GHR的右边移入,此处将分支预测结果相反的值移入到GHR,当发生分支预测失败时,就可以直接将这个值写到前端的GHR中,这样就完成了恢复。如果是顺序执行的处理器,那么这里用同步FIFO作为Checkpoint GHR即可。但是乱序执行的方式就需要改变存储器的设计了。
对于乱序执行分支指令的流水线来说,在执行阶段得到的分支指令的结果的旧有可能是错误的,因为这条分支指令可能处于分支预测失败(mis-prediction)的路径上,也可能处于异常(exception)的路径上,所以仍旧需要在流水线的提交(Commit)阶段对分支指令的预测是否正确进行检查。正因为有这种需求,在提交阶段仍需要放置一个Retired GHR,当分支指令退休的时候发现分支预测失败了,或者一条普通的指令发现了异常,都可以将此时的Retired GHR写回到前端的GHR中,这样就对GHR值进行了恢复。因此,从本质上来看,这种Checkpoint方法就相当于对方法一进行了补充,除了在流水线的提交阶段可以对GHR进行恢复,还可以在流水线的执行阶段对它进行恢复,这样就可以加快分支指令在分支预测失败时的修复时间,使处理器的执行效率得到提高。
三、设计实践
先看HDLBits的描述:
具体的描述如下:
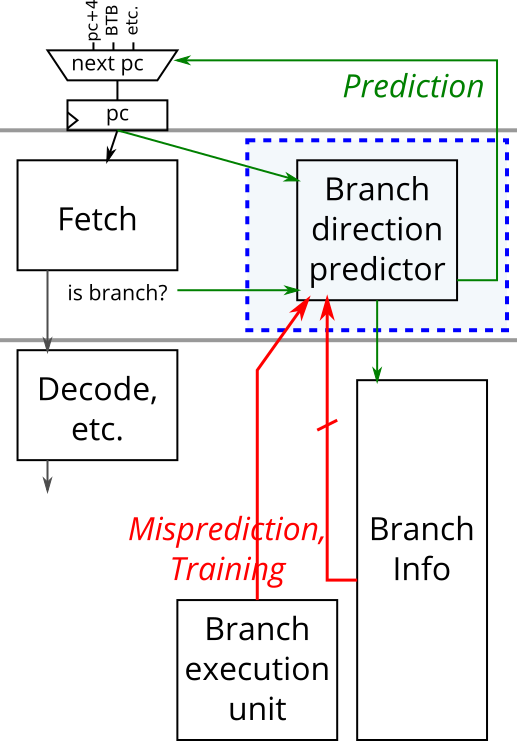
分支预测器有两套接口。一个用于预测,另一个用于训练。预测接口用于处理器的取指阶段,要求分支预测器对正在取指的指令进行分支方向的预测。一旦这些分支沿着流水线前进并被执行,分支的真正结果就会被知道。然后使用实际的分支方向结果来训练分支预测器。
当一个分支预测被请求时(predict_valid = 1),分支预测器产生预测的分支方向和用于进行预测的分支历史寄存器的状态。然后,分支历史寄存器被更新(在下一个正时钟沿)来进行分支预测。
当请求对一个分支进行训练时(train_valid = 1),分支预测器被告知正在训练的分支的pc和分支历史寄存器值,以及实际的分支结果和该分支是否是错误预测(需要管道刷新)。更新模式历史表(PHT),以训练分支预测器下次更准确地预测这个分支。此外,如果被训练的分支是错误预测的,也要将分支历史寄存器恢复到错误预测的分支完成执行后的即时状态。
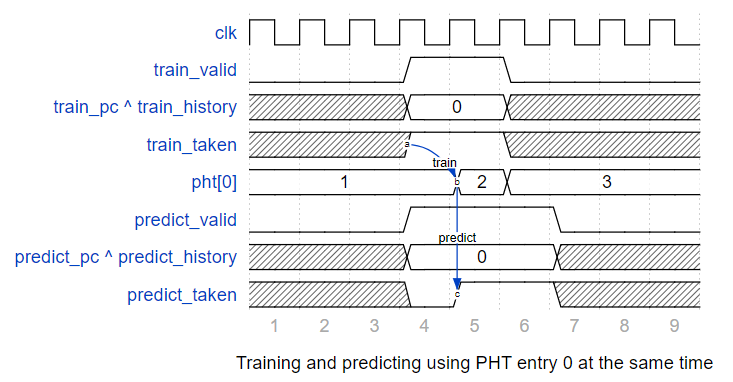
如果错误预测的训练和预测(不同的、较年轻的指令)发生在同一周期,两个操作都要修改分支历史寄存器。当这种情况发生时,训练优先,因为被预测的分支无论如何都会被丢弃。如果训练和预测同一PHT条目同时发生,预测会在训练前看到PHT状态,因为训练只在下一个正时钟沿修改PHT。下面的时序图显示了训练和预测PHT条目0同时发生时的时序。第4周期的训练请求改变了第5周期的PHT入口状态,但是第4周期的预测请求输出第4周期的PHT状态,没有考虑第4周期训练请求的影响。
具体的RTL代码如下所示:


1 module top_module( 2 input clk, 3 input areset, 4 5 input predict_valid, 6 input [6:0] predict_pc, 7 output predict_taken, 8 output [6:0] predict_history, 9 10 input train_valid, 11 input train_taken, 12 input train_mispredicted, 13 input [6:0] train_history, 14 input [6:0] train_pc 15 ); 16 wire [6:0] train_hash; 17 wire [6:0] predict_hash; 18 reg [1:0] PHT [0:127]; 19 reg [6:0] speculative_GHR; 20 21 integer i; 22 23 assign predict_hash = predict_pc ^ predict_history; 24 assign train_hash = train_history ^ train_pc; 25 assign predict_history = speculative_GHR; 26 27 assign predict_taken = PHT[predict_hash][1]; 28 29 //GHR 30 always@(posedge clk or posedge areset)begin 31 if(areset)begin 32 speculative_GHR <= 'd0; 33 end 34 else if(train_valid & train_mispredicted)begin 35 speculative_GHR <= {train_history[5:0],train_taken}; 36 end 37 else if(predict_valid)begin 38 speculative_GHR <= {speculative_GHR[5:0],predict_taken}; 39 end 40 end 41 42 //PHT 43 always@(posedge clk or posedge areset)begin 44 if(areset)begin 45 for(i=0;i<128;i=i+1)begin 46 PHT[i] <= 2'b01; 47 end 48 end 49 else if(train_valid)begin 50 if(train_taken)begin 51 PHT[train_hash] <= PHT[train_hash]==2'b11 ? PHT[train_hash] : PHT[train_hash] + 1; 52 end 53 else begin 54 PHT[train_hash] <= PHT[train_hash]==2'b00 ? PHT[train_hash] : PHT[train_hash] - 1; 55 end 56 end 57 /*else if(predict_valid)begin 58 if(predict_taken)begin 59 PHT[predict_hash] <= PHT[predict_hash]==2'b11 ? PHT[predict_hash] : PHT[predict_hash] + 1; 60 end 61 else begin 62 PHT[predict_hash] <= PHT[predict_hash]==2'b00 ? PHT[predict_hash] : PHT[predict_hash] - 1; 63 end 64 end*/ 65 end 66 67 endmodule
这里我以为PHT也要根据predict的hash值来更新,但是实际上代码不需要,还需要根据理论知识多分析。
参考文献
超标量处理器设计--姚永斌
HDLBits
