MySQL优化Explain命令简介(一)
最近碰到MySQL需要写入大量数据并查询的场景,于是学习了一下MySQL的查询优化,想找关于explain命令的详细资料,然而网上并没有找全,最后终于在《高性能MySQL》中找到了对这一命令的详细介绍,以下摘录出来记录一下。
EXPLAIN的用法很简单,将其加入SELECT 关键字前面即可,MySQL将会对这条查询做个特殊标记,实际执行时会将其执行计划中具体执行的每一步的相关信息反馈回来,一个步骤占一行。
一个简单的EXPLAIN执行结果:
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+
查询中的每个table都将有一行记录描述其相关信息,这个table是一个广义的概念,一个子查询、一个UNION结果属于其定义范围。
EXPLAIN会实际执行吗?
记住EXPLAIN只是一个sql执行的模拟近似,有时候能真实反应sql实际执行的步骤和实际情况,然而有时候也可能和实际执行情况相差甚远。
下面是EXPLAIN的几个无能为力的情况:
- EXPLAIN不会分析关于触发器、存储函数(stored function?)或者自定义函数会如何影响实际查询。
- EXPLAIN对存储过程无效,当然你可以将其具体语句抽取出来,单独执行EXPLAIN
- EXPLAIN不会显示查询执行过程中做的特定的优化
- EXPLAIN并不会显示关于查询执行计划的所有相关信息(MYSQL开发人员一直在尝试增加进尽可能多的相关信息)
- EXPLAIN并不会区分一些同名但实际有差别的概念。比如“filesort”同时用于描述内存排序和临时文件,对于硬盘和内存中的临时表也都使用“temporary”表示。
- EXPLAIN有时可能反而具有误导性。例如它会对一个很小的limit查询显示会进行全索引扫描(MYSQL5.1的EXPLAIN会展示更加精确的相关信息)
重写Non-SELECT查询
MYSQL EXPLAIN只能分析SELECT查询,无法分析存储过程、INSERT/UPDATE/DELET或者其他语句。用户可以通过将其转化为等效的的SELECT语句,将其中访问到的所有列表都放入SELECT字段、join或者WHERE条件中去。
EXPLAIN中的列字段
EXPLAIN的输出总是相同的列字段和格式(EXPLAIN EXTENDED增加了filtered列字段,EXPLAIN PARTITIONS增加了partions列字段),而其行数和具体值内容则会根据具体语句变化。接下来我们将为读者解释一个具体EXPLAIN执行结果的每列字段的具体含义。注意输出结果中的行顺序反映了MYSQL实际执行查询语句中各部分的顺序,这个顺序不一定和原始SQL语句中看到的顺序相同。
id列
这一列总是一个数字,用于标识SELECT所属的行,如果原始语句中没有任何子查询或union,就只有一个SELECT,该列的每一行都将显示1,否则,内部的SELECT语句通常会根据他们在原始语句中的顺序递增标号。
MYSQL将SELECT查询分为简单(simple)和(complex)类型,complex类型则进一步分为三组:简单子查询(simple subqueris),所谓的派生表查询(FROM子句中的子查询)和联合(UNIONS)查询。下面是一个简单的子查询:
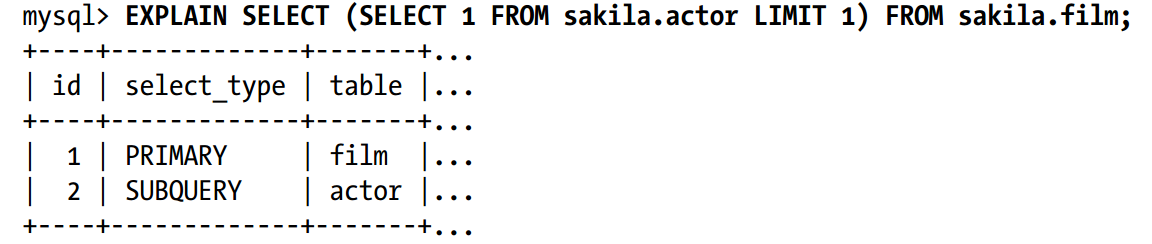
FROM子句和UNIONS中的子查询会增加id列的复杂度,以下是一个FROM 子句中有简单子查询的语句:

这个查询会产生一个匿名的临时表,MYSQL内部通过临时表的别名(der)在外层查询中引用它,在之后讲解的更复杂的查询语句EXPLAIN的ref列中将能看到实际的例子。
最后,下面是一个联合(UNION)查询:
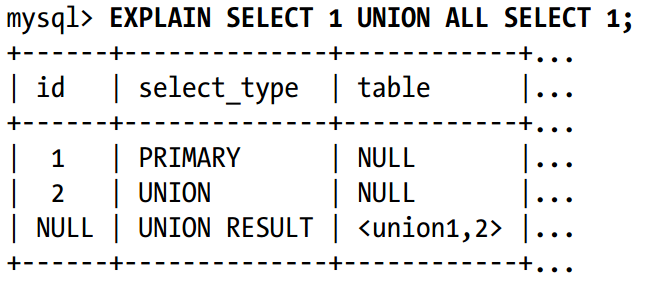
注意UNION结果输出的额外那行,UNION结果总是被放入一个匿名临时表中,然后MYSQL从其中都会查询结果,这个临时表并不会出现在原始的SQL中,所以它的id是NULL。相比之前的例子(FROM子句中的一个子查询),这个UNION结果的临时表被放在了结果中的最后一行,而不是首行。
目前为止的例子都非常简单直接,不过下面将这三类语句混合使用后,我们将可以产生更加复杂的分析结果。
select_type列
select_type显示该行代表的查询是简单查询和复杂查询(如果是复杂查询,进一步细分为三种复杂查询中的一种)。值SIMPLE标识该查询不包含任何子查询与联合查询UNIONS,如果查询语句包含任何复杂查询类型,最外层的查询部分被标为PRIMARY,其他部分则分为如下情况:
子查询(SUBQUERY)
包含在SELECT部分嵌套SELECT语句(即不再FROM子句中)会被标为SUBQUERY
派生(DERIVED)
包含在FROM子句中的子查询被标识为DERIVED,MYSQL会递归执行这类查询并放入临时表中。MYSLQ内部通过“derived table”引用这张临时表,因为这张临时表派生自子查询。
联合(UNION)
UNION语句中的第二个和后续SELECTS会被标为UNION,第一个SELECT则被视为作为外层查询执行,会被标识为PRIMARY,如果UNION被包含在一个子查询中执行,第一个SELECT则会被标识为DERIVED。
联合结果(UNION RESULT)
这个SELECT用于从UNION执行产生的匿名临时表中检索结果,因而被标识为UNION SELECT。
除了这些值,SUBQUERY和UNION也可能被标识为DEPENDENT和UNCACHEABLE。DEPENDENT表示SELECT依赖于外层查询中的某些数据;UNCACHEABLE则表示SELECT中的某些部分会阻止结果被Item_cache缓存(Item_cahe并没有被文档正式记录,它和query cache不是一个东西,尽管它也会因为一些同样的原因而无法使用,比如RAND()函数)
table列
table列标识对应行访问的是哪一张表,一般就是sql中显式使用的表名或其别名。
可以通过从上到下观察到join optimizer为一般查询优化过后join操作的实际执行次序。比如下例:

派生表与联合
如果在FROM子句中存在子查询或者UNION操作,table列就变得起来了。因为在这些情况下MYSQL会创建仅在查询执行期间存在的匿名临时表,所以实际上并没有真正的“表”可以被这一列引用。
对于FROM子句中的子查询,table列的值是<derivedN>的形式,N代表子查询的id,总是执行EXPLAIN输出中后面的某一行。
而当有UNION操作时,其联合结果 table列包含一系列参与UNION操作的id,这些id总是执行EXPLAIN结果中该行前面的某些行,因为UNION操作总是会在所有参与UNION的子查询执行完之后才会真正执行。如果有超过20个id参与了UNION操作,table列可能会被截断以防止结果太长,所以会看不到全部id列表,不过其实第一个id到UNION RESULt行之间的所有行,就是参与UNION操作的所有子查询。
一个复杂的SELECT类型
下面是一个没有实际意义的复杂select查询,仅仅作为一个说明例子:

LIMIT语句是为了方便不使用EXPLAIN语句直接执行时查看结果,上面语句对应的EXPLAIN结果如下:

让我们从上到下仔细分析一下这个结果:
- 第一行前向引用了der_1,即标识的<derived3>,这一行来源于原始SQL中的line2
- 第二行的id是3,这是因为它是第三个SELECT查询的一部分,由于它嵌套于FROM子句中的一个子查询中,它被标识为DERIVED,这一行来源于line6和line7
- 第三行的id是2,它来源于line3,注意这一行位于第二行之后,表明它应该之后执行。正如其select_type的值DEPENDENT SUBQUERY所示,它依赖于一个外层查询的结果(关联子查询,correlated subquery),这个case中的外层子查询正是line2中从der_1检索数据的SELECT。
- 第四列值为UNION,标识其是UNION查询中后面的部分,table是<derived6>,意味着它是从一个FROM子句中的子查询检索数据并将生成一个临时表加入到UNION中,和之前一样,未了找到这个子查询对应的行结果,必须往其之后看。
- 第五列是der_2的子查询,对应line13,line14和line15,正是第五行中引用的<derived6>
- 第六行是一个<derived6>中的普通子查询,id是7,这一点很重要
- 因为id7>5,意味着<derived6>子查询的边界,当EXPLAIN输出select_type为DERIVED的一行的时候,它标识一个嵌套作用域的起始。如果后面行中子查询的id更小,意味着嵌套域已经被关闭了。我们知道第七行是从<derived6>中检索数据的SELECT查询的一部分,即第四个SELECT查询的一部分(line11),这个例子并不需要知道嵌套作用域的意义和规则也可以简单理解,但有时就比这个复杂了。另一个需要注意的点是第七行中的select type值为UNCACHEABLE SUBQUERY,这是用户变量使用引起的。
- 最后一行是UNION RESULt,代表从UNION的临时表中读取数据的阶段,这一行返回id为1和4的查询结果,即<derivied3>和<derived6>的结果。
正如你看到的,这些复杂的SELECT组合会导致EXPLAIN结果难以分析和理解,需要熟悉规则并多加练习。
理解EXPLAIN结果的时候,需要上下来回观察、分析。上例中,如果仅看第一行的话,根本不会知道其是UNION的一个部分,只有看到最后一行才会发现这一情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号