python常用包
今日所得
collections模块
时间模块
random模块
os模块
sys模块
序列化模块
subprocess模块
collections模块
namedtuple:具名元组
#定义方式一: #Point = namedtuple(类名, '由空格分开的字段名的字符串') Point = namedtuple('Point', 'x y') #定义方式二: #Point = nametuple(typename, '一个可迭代对象,里面元素是字段名,字段名是str类型') Point = namedtuple('Point', ['x', 'y']) #赋值方式 p = Point(1, 2) #1对应的就是x, 2对应的就是y #调用方式 print(p.x) #结果为:1 print(p.y) #结果为:2
例子1:扑克牌
''' 扑克:54张牌 四种花色 ♠️ ♥️ ♣️ ♦️ 每种花色 1-13 两张王牌 大王、小王 ''' from collections import namedtuple import random # Card = namedtuple('card', ['suit', 'num']) Card = namedtuple('card', 'suit num') suit = ['♠️', '♥️', '♣️', '♦️'] card_list = [] for s in suit: for num in range(1, 14): card = Card(s, num) card_list.append(card) #洗牌 random.shuffle(card_list) #发牌 player_one_cards = [] player_two_cards = [] player_three_cards = [] for index, card in enumerate(card_list, 1): if index % 3 == 1: player_one_cards.append(card) elif index % 3 == 0: player_three_cards.append(card) else: player_two_cards.append(card) print(player_one_cards) print(player_two_cards) print(player_three_cards) player_one_cards =[(card.suit, card.num) for card in player_one_cards] print(player_one_cards)
例子2:用具名元组namedtuple,用坐标和半径表示一个圆。
Circle = namedtuple('Circle', 'x y r') #Circle = namedtuple('Circle', ['x', 'y', 'r']) c = Circle(1, 2, 1)
deque 双端队列
队列,先进先出 FIRST IN FIRST OUT FIFO
import queue q = queue.Queue() #生成队列对象 #添加值:put, 取值:get q.put(1) q.put(2) q.put(3) print(q.get()) #打印:1 先进先出 print(q.get()) #打印 2 print(q.get()) #打印 3 print(q.get()) #没有东西 #注:如果队列中没值了,程序会原地等待,只带队列中有值为止。
双端队列:队列只能从一端进,一端出。而双端队列就牛逼了,两头都能进,都能出。
from collections import deque d = deque(['a', 'b', 'c']) d.append(1) print(d) #结果:deque(['a', 'b', 'c', 1]) d.appendleft(2) #结果:deque([2, 'a', 'b', 'c', 1]) res = d.pop() #结果:res = 1 res = d.popleft() #结果:res = 2 res = d[1] #结果: res = 'a' 双端队列deque可以跟列表一样取值。 #deque可以插入值 d.insert(0,'哈哈哈') # 特殊点:双端队列可以根据索引在任意位置插值 #注意:队列不应该支持从中间插值,应该只能从一端插值。不能插队!这是一个设计的缺陷
OrderedDict
python中,dict是无序的,如果想让字典有序,就要使用collections的模块OrderedDict。OrderedDict是dict的一个示例。
from collections import OrderedDict #例1: ordered_dict = OrderedDict([('x', 1), ('y', 2), ('z', z)]) print(ordered_dict) #结果: OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(ordered_dict['x']) # 1 #例2: ordered_dict = OrderedDict() ordered_dict['a'] = 1 ordered_dict['c'] = 2 ordered_dict['b'] = 3 print(ordered_dict.keys()) #结果:odict_keys(['a', 'c', 'b']) for key in ordered_dict.keys(): print(key) #结果:a # c # b #注意:这里keys返回的顺序是key插入的顺序。
defaultdict
#案例:将列表中大于66的值存入字典中,小于66存入字典另一个key from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) #说明:这里的list表明,新建的字典的key的值是一个列表。 for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value) my_dict1 = defaultdict(int) print(my_dict1['xxx']) #结果:0 my_dict2 = defaultdict(bool) print(my_dict2['kkk']) #结果:False my_dict3 = defaultdict(tuple) print(my_dict3['mmm']) #结果:()
Counter
from collections import Counter s = 'abcdeabcdabcaba' res = Counter(s) print(res) #结果:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1}) print(dict(res)) #结果:{'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1}
time、datetime模块
time
.time() 时间戳
.localtime('时间戳') 时间戳转结构化时间
.mktime(’结构化时间‘) 结构化时间转时间戳
.strftime(’格式‘,结构化时间) 结构化时间转格式化时间
.strptime('格式化时间字符串', '格式') 格式化时间转结构化时间
三种形式:
- 时间戳:time.time()
- 结构化时间: 元组(struct_time),struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
- 格式化时间(给人看的)
时间戳:time.time()
格式化时间:
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
结构化时间:是一个元组
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
例子:
#导入时间模块 >>>import time #时间戳 >>>time.time() 1500875844.800804 #时间字符串 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 13:54:37' >>>time.strftime("%Y-%m-%d %H-%M-%S") '2017-07-24 13-55-04' #时间元组:localtime将一个时间戳转换为当前时区的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
重点:时间转换
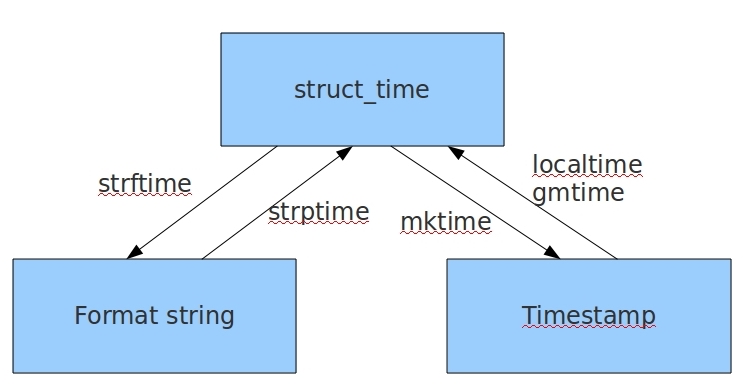
import time #时间戳转结构化时间:time.localtime(时间戳) t = time.time() #时间戳 print(time.localtime(t)) #结果:time.struct_time(tm_year=2019, tm_mon=7, tm_mday=18, tm_hour=18, tm_min=57, tm_sec=27, tm_wday=3, tm_yday=199, tm_isdst=0) #结构化时间转时间戳:time.mktime(结构化时间) time.mktime(time.localtime()) #结构化时间转格式化时间(给人看):time.strftime('格式定义', '结构化时间') time.strftime('%Y-%m-%d %X', time.localtime()) #格式化时间转结构化时间:time.strptime('格式化时间的字符串', '格式') 注意:格式要与时间的字符串相对应。格式不对应,就会报错。 struct_time = time.strptime('2019-7-10', '%Y-%m-%d') print(struct_time) #结果:time.struct_time(tm_year=2019, tm_mon=7, tm_mday=10, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=2, tm_yday=191, tm_isdst=-1)
datetime
datetime 日期时间(年月日时分秒)
.date 日期(年月日)
import datetime print(type(datetime.datetime(2019, 1, 1))) #结果:<class 'datetime.datetime'> print(type(datetime.date(2019, 1, 1))) #结果:<class 'datetime.date'> print(datetime.datetime(2019, 1, 1)) #结果:2019-01-01 00:00:00 print(datetime.date(2019, 1, 1)) #结果:2019-01-01 # 获取本地时间 # 年月日 now_date = datetime.date.today() print(now_date) #结果:2019-07-01 # 年月日时分秒 now_time = datetime.datetime.today() print(now_time) #结果:2019-07-01 17:46:08.214170 # 无论是年月日,还是年月日时分秒对象都可以调用以下方法获取针对性的数据 # 以datetime对象举例 print(now_time.year) # 获取年份2019 print(now_time.month) # 获取月份7 print(now_time.day) # 获取日1 print(now_time.weekday()) # 获取星期(weekday星期是0-6) 0表示周一 print(now_time.isoweekday()) # 获取星期(weekday星期是1-7) 1表示周一
.timedelta
定义timedelta对象之后,可以使用date对象或是datetime对象对timedelta对象进行操作运算。
date对象操作的话,返回的就是date对象。
datetime对象操作的话,返回的就是datetime对象。
# 定义日期对象 now_date1 = datetime.date.today() # 定义timedelta对象 lta = datetime.timedelta(days=6) now_date2 = now_date1 + lta # 重点:日期对象 = 日期对象 +/- timedelta对象 print(now_date2) #结果:2019-07-24 print(type(now_date2)) #结果: <class 'datetime.date'> lta2 = now_date1 - now_date2 #重点: timedelta对象 = 日期对象 +/- 日期对象 print(lta2) #结果: -6 days, 0:00:00 print(type(lta2)) #结果: <class 'datetime.timedelta'> d = datetime.date.today() d2 = datetime.date(2019, 1, 1) print((d-d2).days) # 198 #d-d2返回的是一个timedelta对象
重点:日期对象 = 日期对象 +/- timedelta对象
重点: timedelta对象 = 日期对象 +/- 日期对象
time:对日期的时间戳、结构化时间、格式化时间进行互相转化。
datetime:对日期进行相加减(依靠timedelta对象)
random模块
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
os、sys模块
os、sys模块的区别?
os:跟操作系统打交道的模块
sys:跟Python解释器打交道的模块
os模块
#找到当前文件所属的文件夹:os.path.dirname(__file__) BASE_DIR = os.path.dirname(__file__) print(BASE_DIR) #结果:/Users/mac/Desktop/ #组合路径: os.path.join(BASE_DIR,'movie') MOVIE_DIR = os.path.join(BASE_DIR,'movie') print(MOVIE_DIR) #结果: /Users/mac/Desktop/movie #os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False #os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 #os.remove() 删除一个文件 #os.rename("oldname","newname") 重命名文件/目录 #os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname #os.rmdir(r'/Users/mac/Desktop/movie') # 只能删空文件夹 #os.path.getsize(r'/Users/mac/Desktop/movie.txt')) # 获取文件字节大小
sys模块
# 将某个路径添加到系统的环境变量中 #将文件当成项目启动文件的时候,需要把项目所在路径添加进sys.path,python的环境变量中。 sys.path.append() print(sys.version) # python解释器的版本 print(sys.platform) #系统平台 #重点:sys.argv ''' 当执行python3 xxx.py文件的时候,使用sys.argv,能获取到命令行输入的参数 例1: python3 test.py print(sys.argv) #结果:['test.py', 'test'] 例2: python3 test.py username password print(sys.argv) #结果:['test.py', 'test', 'username', 'password'] '''
序列化模块
什么叫序列化?
答:1、序列指的就是字符串
2、序列化指的就是把其他数据类型转化为字符串的过程
3、Python中的反序列化是什么意思?反序列化操作,将str字符串转换成python中的数据结构
写入文件时的数据必须是字符串,但是我们要将一个字典类型的数据写入文件的时候,就会报错:TypeError: write() argument must be str, not dict。这个时候,就需要用到序列化操作,将字典类型的对象序列化为一个字符串、然后写入文件中。
字符串 ——> 反序列化(loads) ——> 数据结构 ——> 序列化(dumps) ——> 字符串
json模块
json.dumps():
将一个对象序列化为一个具有json格式的字符串。
import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串 print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json转换完的字符串类型的字典中的字符串是由""表示的
json.loads():
将一个字符串反序列化为一个对象
dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典 #注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示 print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
json.dump()、json.load()
dump:****
接收一个文件句柄作为对像,直接将字典序列化为一个json格式字符串写入文件句柄中。写入中文的时候,参数ensure_ascii要设置成False,不然写入的会是所有非ASCII码字符显示为\uXXXX序列。为了显示中文,就必须设置为False。例如下面序列字典时:
import json data = {'username':['李华','二愣子'],'sex':'male','age':16} with open('1.txt', 'w', encoding='utf-8') as f: json.dump(data, f) ''' 文件中的内容是: {"username": ["\u674e\u534e", "\u4e8c\u6123\u5b50"], "sex": "male", "age": 16} 显然不是我们想要的。 这时候就需要设置ensure_ascii=False json.dump(data, f, ensure_ascii=False) '''
load:
接收一个文件句柄对象,直接将文件中的json格式的字符串反序列化为一个字典对象返回。
注意:文件内容必须是json格式的字符串,如果不是,就会报错:json.decoder.JSONDecodeError:
with open('1.txt', 'r', encoding='utf-8') as f: d = json.load(f) print(d)
picker模块
用于Python程序之间的序列化。
picker和json两个模块的不同:
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换。
- pickle可以对Python的对象进行序列化,而json模块就不行,支持的数据类型很少 字符串 列表 字典 整型 元组(转成列表) 布尔值。
- pickle对Python所有的数据类型都支持。
- 方法都是dumps/dump, loads/load
dumps/loads
import pickle d = {'name':'jason'} res = pickle.dumps(d) # 将对象直接转成二进制 print(pickle.dumps(d)) #结果:b'\x80\x03}q\x00X\x04\x00\x00\x00nameq\x01X\x05\x00\x00\x00jasonq\x02s.' res1 = pickle.loads(res) print(res1,type(res1)) #结果:{'name': 'jason'} <class 'dict'>
dump/load:用pickle操作文件的时候 文件的打开模式必须是b模式
""" 用pickle操作文件的时候 文件的打开模式必须是b模式 """ with open('userinfo_1','wb') as f: pickle.dump(d,f) with open('userinfo_1','rb') as f: res = pickle.load(f) print(res,type(res))
posted on 2019-07-18 22:05 AbrahamChen 阅读(741) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号