Tornado
引言
回想Django的部署方式
以Django为代表的python web应用部署时采用wsgi协议与服务器对接(被服务器托管),而这类服务器通常都是基于多线程的,也就是说每一个网络请求服务器都会有一个对应的线程来用web应用(如Django)进行处理。
考虑两类应用场景
-
用户量大,高并发
如秒杀抢购、双十一某宝购物、春节抢火车票
-
大量的HTTP持久连接
使用同一个TCP连接来发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方法。
对于HTTP 1.0,可以在请求的包头(Header)中添加Connection: Keep-Alive。
对于HTTP 1.1,所有的连接默认都是持久连接。
对于这两种场景,通常基于多线程的服务器很难应对。
C10K问题
对于前文提出的这种高并发问题,我们通常用C10K这一概念来描述。C10K—— Concurrently handling ten thousand connections,即并发10000个连接。对于单台服务器而言,根本无法承担,而采用多台服务器分布式又意味着高昂的成本。如何解决C10K问题?
Tornado
Tornado在设计之初就考虑到了性能因素,旨在解决C10K问题,这样的设计使得其成为一个拥有非常高性能的解决方案(服务器与框架的集合体)。
1 关于Tornado
知识点
- 了解什么是Tornado框架
- 了解Tornado与Django的区别
1.1 Tornado是为何物
Tornado全称Tornado Web Server,是一个用Python语言写成的Web服务器兼Web应用框架,由FriendFeed公司在自己的网站FriendFeed中使用,被Facebook收购以后框架在2009年9月以开源软件形式开放给大众。
特点:
- 作为Web框架,是一个轻量级的Web框架,类似于另一个Python web框架Web.py,其拥有异步非阻塞IO的处理方式。
- 作为Web服务器,Tornado有较为出色的抗负载能力,官方用nginx反向代理的方式部署Tornado和其它Python web应用框架进行对比,结果最大浏览量超过第二名近40%。
性能: Tornado有着优异的性能。它试图解决C10k问题,即处理大于或等于一万的并发,下表是和一些其他Web框架与服务器的对比:

Tornado框架和服务器一起组成一个WSGI的全栈替代品。单独在WSGI容器中使用tornado网络框架或者tornaod http服务器,有一定的局限性,为了最大化的利用tornado的性能,推荐同时使用tornaod的网络框架和HTTP服务器
1.2 Tornado与Django
Django
Django是走大而全的方向,注重的是高效开发,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。
Django提供的方便,也意味着Django内置的ORM跟框架内的其他模块耦合程度高,应用程序必须使用Django内置的ORM,否则就不能享受到框架内提供的种种基于其ORM的便利。
- session功能
- 后台管理
- ORM
Tornado
Tornado走的是少而精的方向,注重的是性能优越,它最出名的是异步非阻塞的设计方式。
- HTTP服务器
- 异步编程
- WebSockets
2 初识Tornado
知识点
- Tornado的安装
- 了解Tornado的原理
- 掌握Tornado的基本写法
- 掌握Tornado的基本模块
- tornado.web
- tornado.ioloop
- tornado.httpserver
- tornado.options
2.1 安装
自动安装
1.查看自己当前的环境是否已安装
$ pip list
2.安装
$ pip install tornado
手动安装
- 下载安装包tornado-4.3.tar.gz(https://pypi.python.org/packages/source/t/tornado/tornado-4.3.tar.gz)
$ tar xvzf tornado-4.3.tar.gz $ cd tornado-4.3 $ python setup.py build $ sudo python setup.py install
关于使用平台的说明
Tornado should run on any Unix-like platform, although for the best performance and scalability only Linux (with epoll) and BSD (with kqueue) are recommended for production deployment (even though Mac OS X is derived from BSD and supports kqueue, its networking performance is generally poor so it is recommended only for development use). Tornado will also run on Windows, although this configuration is not officially supported and is recommended only for development use.
Tornado应该运行在类Unix平台,在线上部署时为了最佳的性能和扩展性,仅推荐Linux和BSD(因为充分利用Linux的epoll工具和BSD的kqueue工具,是Tornado不依靠多进程/多线程而达到高性能的原因)。
对于Mac OS X,虽然也是衍生自BSD并且支持kqueue,但是其网络性能通常不太给力,因此仅推荐用于开发。
对于Windows,Tornado官方没有提供配置支持,但是也可以运行起来,不过仅推荐在开发中使用。
2.2 Hello Itcast
上代码
新建文件hello.py,代码如下:

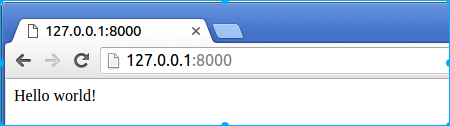
# coding:utf-8 import tornado.web import tornado.ioloop class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) app.listen(8000) tornado.ioloop.IOLoop.current().start()
执行如下命令,开启tornado:
$ python hello.py打开浏览器,输入网址127.0.0.1:8000(或localhost:8000),查看效果:
代码讲解
1. tornado.web
tornado的基础web框架模块
-
RequestHandler
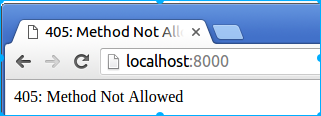
封装了对应一个请求的所有信息和方法,write(响应信息)就是写响应信息的一个方法;对应每一种http请求方式(get、post等),把对应的处理逻辑写进同名的成员方法中(如对应get请求方式,就将对应的处理逻辑写在get()方法中),当没有对应请求方式的成员方法时,会返回“405: Method Not Allowed”错误。
我们将代码中定义的get()方法更改为post()后,再用浏览器重新访问(浏览器地址栏中输入网址访问的方式为get请求方式),演示如下:
# coding:utf-8 import tornado.web import tornado.ioloop class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def post(self): # 我们修改了这里 """对应http的post请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) app.listen(8000) tornado.ioloop.IOLoop.current().start()
-
Application
Tornado Web框架的核心应用类,是与服务器对接的接口,里面保存了路由信息表,其初始化接收的第一个参数就是一个路由信息映射元组的列表;其listen(端口)方法用来创建一个http服务器实例,并绑定到给定端口(注意:此时服务器并未开启监听)。
2. tornado.ioloop
tornado的核心io循环模块,封装了Linux的epoll和BSD的kqueue,tornado高性能的基石。 以Linux的epoll为例,其原理如下图:

-
IOLoop.current()
返回当前线程的IOLoop实例。
-
IOLoop.start()
启动IOLoop实例的I/O循环,同时服务器监听被打开。
总结Tornado Web程序编写思路
- 创建web应用实例对象,第一个初始化参数为路由映射列表。
- 定义实现路由映射列表中的handler类。
- 创建服务器实例,绑定服务器端口。
- 启动当前线程的IOLoop。
2.3 httpserver
上一节我们说在tornado.web.Application.listen()(示例代码中的app.listen(8000))的方法中,创建了一个http服务器示例并绑定到给定端口,我们能不能自己动手来实现这一部分功能呢?
现在我们修改上一示例代码如下:
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver # 新引入httpserver模块 class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) # ------------------------------ # 我们修改这个部分 # app.listen(8000) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(8000) # ------------------------------ tornado.ioloop.IOLoop.current().start()
在这一修改版本中,我们引入了tornado.httpserver模块,顾名思义,它就是tornado的HTTP服务器实现。
我们创建了一个HTTP服务器实例http_server,因为服务器要服务于我们刚刚建立的web应用,将接收到的客户端请求通过web应用中的路由映射表引导到对应的handler中,所以在构建http_server对象的时候需要传出web应用对象app。http_server.listen(8000)将服务器绑定到8000端口。
实际上一版代码中app.listen(8000)正是对这一过程的简写。
单进程与多进程
我们刚刚实现的都是单进程,可以通过命令来查看:
$ ps -ef | grep hello.py

我们也可以一次启动多个进程,修改上面的代码如下:
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) # -----------修改---------------- http_server.bind(8000) http_server.start(0) # ------------------------------ tornado.ioloop.IOLoop.current().start()
http_server.bind(port)方法是将服务器绑定到指定端口。
http_server.start(num_processes=1)方法指定开启几个进程,参数num_processes默认值为1,即默认仅开启一个进程;如果num_processes为None或者<=0,则自动根据机器硬件的cpu核芯数创建同等数目的子进程;如果num_processes>0,则创建num_processes个子进程。
本例中,我们使用http_server.start(0),而我的虚拟机设定cpu核数为2,演示结果:
我们在前面写的http_server.listen(8000)实际上就等同于:
http_server.bind(8000)
http_server.start(1)
说明
1.关于app.listen()
app.listen()这个方法只能在单进程模式中使用。
对于app.listen()与手动创建HTTPServer实例
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(8000)
这两种方式,建议大家先使用后者即创建HTTPServer实例的方式,因为其对于理解tornado web应用工作流程的完整性有帮助,便于大家记忆tornado开发的模块组成和程序结构;在熟练使用后,可以改为简写。
2.关于多进程
虽然tornado给我们提供了一次开启多个进程的方法,但是由于:
- 每个子进程都会从父进程中复制一份IOLoop实例,如过在创建子进程前我们的代码动了IOLoop实例,那么会影响到每一个子进程,势必会干扰到子进程IOLoop的工作;
- 所有进程是由一个命令一次开启的,也就无法做到在不停服务的情况下更新代码;
- 所有进程共享同一个端口,想要分别单独监控每一个进程就很困难。
不建议使用这种多进程的方式,而是手动开启多个进程,并且绑定不同的端口。
2.4 options
在前面的示例中我们都是将服务端口的参数写死在程序中,很不灵活。
tornado为我们提供了一个便捷的工具,tornado.options模块——全局参数定义、存储、转换。
tornado.options.define()
用来定义options选项变量的方法,定义的变量可以在全局的tornado.options.options中获取使用,传入参数:
- name 选项变量名,须保证全局唯一性,否则会报“Option 'xxx' already defined in ...”的错误;
- default 选项变量的默认值,如不传默认为None;
- type 选项变量的类型,从命令行或配置文件导入参数的时候tornado会根据这个类型转换输入的值,转换不成功时会报错,可以是str、float、int、datetime、timedelta中的某个,若未设置则根据default的值自动推断,若default也未设置,那么不再进行转换。可以通过利用设置type类型字段来过滤不正确的输入。
- multiple 选项变量的值是否可以为多个,布尔类型,默认值为False,如果multiple为True,那么设置选项变量时值与值之间用英文逗号分隔,而选项变量则是一个list列表(若默认值和输入均未设置,则为空列表[])。
- help 选项变量的帮助提示信息,在命令行启动tornado时,通过加入命令行参数 --help 可以查看所有选项变量的信息(注意,代码中需要加入tornado.options.parse_command_line())。
tornado.options.options
全局的options对象,所有定义的选项变量都会作为该对象的属性。
tornado.options.parse_command_line()
转换命令行参数,并将转换后的值对应的设置到全局options对象相关属性上。追加命令行参数的方式是--myoption=myvalue
新建opt.py,我们用代码来看一下如何使用:
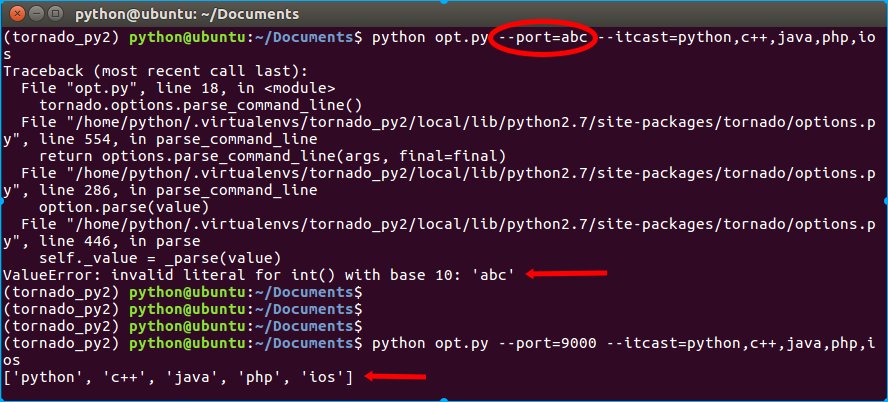
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options # 新导入的options模块 tornado.options.define("port", default=8000, type=int, help="run server on the given port.") # 定义服务器监听端口选项 tornado.options.define("itcast", default=[], type=str, multiple=True, help="itcast subjects.") # 无意义,演示多值情况 class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": tornado.options.parse_command_line() print tornado.options.options.itcast # 输出多值选项 app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(tornado.options.options.port) tornado.ioloop.IOLoop.current().start()
执行如下命令开启程序:
$ python opt.py --port=9000 --itcast=python,c++,java,php,ios
效果如下:
tornado.options.parse_config_file(path)
从配置文件导入option,配置文件中的选项格式如下:
myoption = "myvalue" myotheroption = "myothervalue"
我们用代码来看一下如何使用,新建配置文件config,注意字符串和列表按照python的语法格式:
port = 8000 itcast = ["python","c++","java","php","ios"]
修改opt.py文件:
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options # 新导入的options模块 tornado.options.define("port", default=8000, type=int, help="run server on the given port.") # 定义服务器监听端口选项 tornado.options.define("itcast", default=[], type=str, multiple=True, help="itcast subjects.") # 无意义,演示多值情况 class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" def get(self): """对应http的get请求方式""" self.write("Hello Itcast!") if __name__ == "__main__": tornado.options.parse_config_file("./config") # 仅仅修改了此处 print tornado.options.options.itcast # 输出多值选项 app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(tornado.options.options.port) tornado.ioloop.IOLoop.current().start()

说明
1. 日志
当我们在代码中调用parse_command_line()或者parse_config_file()的方法时,tornado会默认为我们配置标准logging模块,即默认开启了日志功能,并向标准输出(屏幕)打印日志信息。

如果想关闭tornado默认的日志功能,可以在命令行中添加--logging=none 或者在代码中执行如下操作:
from tornado.options import options, parse_command_line options.logging = None parse_command_line()
2. 配置文件
我们看到在使用prase_config_file()的时候,配置文件的书写格式仍需要按照python的语法要求,其优势是可以直接将配置文件的参数转换设置到全局对象tornado.options.options中;然而,其不方便的地方在于需要在代码中调用tornado.options.define()来定义选项,而且不支持字典类型,故而在实际应用中大都不使用这种方法。
在使用配置文件的时候,通常会新建一个python文件(如config.py),然后在里面直接定义python类型的变量(可以是字典类型);在需要配置文件参数的地方,将config.py作为模块导入,并使用其中的变量参数。
如config.py文件:
# conding:utf-8 # Redis配置 redis_options = { 'redis_host':'127.0.0.1', 'redis_port':6379, 'redis_pass':'', } # Tornado app配置 settings = { 'template_path': os.path.join(os.path.dirname(__file__), 'templates'), 'static_path': os.path.join(os.path.dirname(__file__), 'statics'), 'cookie_secret':'0Q1AKOKTQHqaa+N80XhYW7KCGskOUE2snCW06UIxXgI=', 'xsrf_cookies':False, 'login_url':'/login', 'debug':True, } # 日志 log_path = os.path.join(os.path.dirname(__file__), 'logs/log')
使用config.py的模块中导入config,如下:
# conding:utf-8 import tornado.web import config if __name__ = "__main__": app = tornado.web.Application([], **config.settings) ...
2.5 练习
-
尝试解释清Tornado利用epoll机制实现支持高并发的原因。
-
能够不参考课件熟练默写出Tornado的基本代码案例。
3 深入Tornado
知识点
- Application设置
- debug模式
- 路由设置扩展
- RequestHandler的使用
- 输入方法
- 输出方法
- 可重写接口
3.1 Application
settings
前面的学习中,我们在创建tornado.web.Application的对象时,传入了第一个参数——路由映射列表。实际上Application类的构造函数还接收很多关于tornado web应用的配置参数,在后面的学习中我们用到的地方会为大家介绍。
我们先来学习一个参数:
debug,设置tornado是否工作在调试模式,默认为False即工作在生产模式。当设置debug=True 后,tornado会工作在调试/开发模式,在此种模式下,tornado为方便我们开发而提供了几种特性:
- 自动重启,tornado应用会监控我们的源代码文件,当有改动保存后便会重启程序,这可以减少我们手动重启程序的次数。需要注意的是,一旦我们保存的更改有错误,自动重启会导致程序报错而退出,从而需要我们保存修正错误后手动启动程序。这一特性也可单独通过autoreload=True设置;
- 取消缓存编译的模板,可以单独通过compiled_template_cache=False来设置;
- 取消缓存静态文件hash值,可以单独通过static_hash_cache=False来设置;
- 提供追踪信息,当RequestHandler或者其子类抛出一个异常而未被捕获后,会生成一个包含追踪信息的页面,可以单独通过serve_traceback=True来设置。
使用debug参数的方法:
import tornado.web app = tornado.web.Application([], debug=True)
路由映射
先前我们在构建路由映射列表的时候,使用的是二元元组,如:
[(r"/", IndexHandler),]
对于这个映射列表中的路由,实际上还可以传入多个信息,如:
[ (r"/", Indexhandler), (r"/cpp", ItcastHandler, {"subject":"c++"}), url(r"/python", ItcastHandler, {"subject":"python"}, name="python_url") ]
对于路由中的字典,会传入到对应的RequestHandler的initialize()方法中:
from tornado.web import RequestHandler class ItcastHandler(RequestHandler): def initialize(self, subject): self.subject = subject def get(self): self.write(self.subject)
对于路由中的name字段,注意此时不能再使用元组,而应使用tornado.web.url来构建。name是给该路由起一个名字,可以通过调用RequestHandler.reverse_url(name)来获取该名子对应的url。
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import url, RequestHandler define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def get(self): python_url = self.reverse_url("python_url") self.write('<a href="%s">itcast</a>' % python_url) class ItcastHandler(RequestHandler): def initialize(self, subject): self.subject = subject def get(self): self.write(self.subject) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", Indexhandler), (r"/cpp", ItcastHandler, {"subject":"c++"}), url(r"/python", ItcastHandler, {"subject":"python"}, name="python_url") ], debug = True) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()
3.2 输入
下面几节主要讲解tornado.web.RequestHandler。
回想一下,利用HTTP协议向服务器传参有几种途径?
- 查询字符串(query string),形如key1=value1&key2=value2;
- 请求体(body)中发送的数据,比如表单数据、json、xml;
- 提取uri的特定部分,如/blogs/2016/09/0001,可以在服务器端的路由中用正则表达式截取;
- 在http报文的头(header)中增加自定义字段,如X-XSRFToken=itcast。
我们现在来看下tornado中为我们提供了哪些方法来获取请求的信息。
1. 获取查询字符串参数
从请求的查询字符串中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default为设值未传name参数时返回的默认值,如若default也未设置,则会抛出tornado.web.MissingArgumentError异常。
strip表示是否过滤掉左右两边的空白字符,默认为过滤。
get_query_arguments(name, strip=True)
从请求的查询字符串中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]。
strip同前,不再赘述。
2. 获取请求体参数
get_body_argument(name, default=_ARG_DEFAULT, strip=True)
从请求体中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default与strip同前,不再赘述。
get_body_arguments(name, strip=True)
从请求体中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]。
strip同前,不再赘述。
说明
对于请求体中的数据要求为字符串,且格式为表单编码格式(与url中的请求字符串格式相同),即key1=value1&key2=value2,HTTP报文头Header中的"Content-Type"为application/x-www-form-urlencoded 或 multipart/form-data。对于请求体数据为json或xml的,无法通过这两个方法获取。
3. 前两类方法的整合
get_argument(name, default=_ARG_DEFAULT, strip=True)
从请求体和查询字符串中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default与strip同前,不再赘述。
get_arguments(name, strip=True)
从请求体和查询字符串中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]。
strip同前,不再赘述。
说明
对于请求体中数据的要求同前。 这两个方法最常用。
用代码来看上述六中方法的使用:
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import RequestHandler, MissingArgumentError define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def post(self): query_arg = self.get_query_argument("a") query_args = self.get_query_arguments("a") body_arg = self.get_body_argument("a") body_args = self.get_body_arguments("a", strip=False) arg = self.get_argument("a") args = self.get_arguments("a") default_arg = self.get_argument("b", "itcast") default_args = self.get_arguments("b") try: missing_arg = self.get_argument("c") except MissingArgumentError as e: missing_arg = "We catched the MissingArgumentError!" print e missing_args = self.get_arguments("c") rep = "query_arg:%s<br/>" % query_arg rep += "query_args:%s<br/>" % query_args rep += "body_arg:%s<br/>" % body_arg rep += "body_args:%s<br/>" % body_args rep += "arg:%s<br/>" % arg rep += "args:%s<br/>" % args rep += "default_arg:%s<br/>" % default_arg rep += "default_args:%s<br/>" % default_args rep += "missing_arg:%s<br/>" % missing_arg rep += "missing_args:%s<br/>" % missing_args self.write(rep) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()
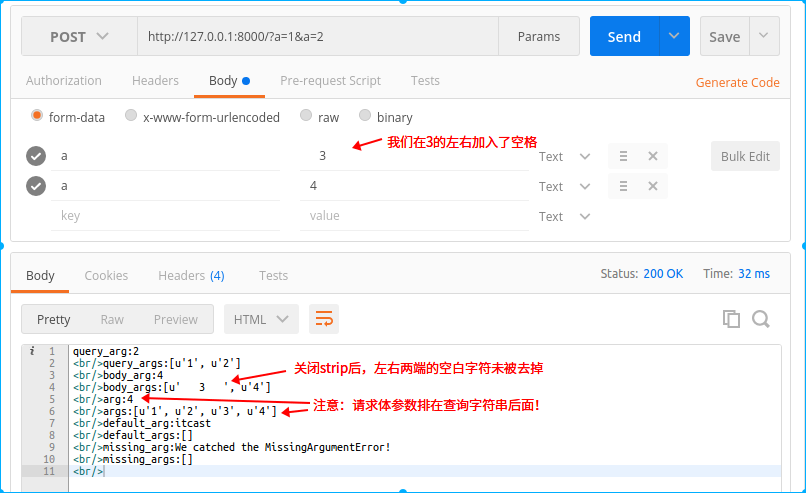
注意:以上方法返回的都是unicode字符串
思考
- 什么时候设置default,什么时候不设置default?
- default的默认值_ARG_DEFAULT是什么?
- 什么时候使用strip,亦即什么时候要截断空白字符,什么时候不需要?
4. 关于请求的其他信息
RequestHandler.request 对象存储了关于请求的相关信息,具体属性有:
- method HTTP的请求方式,如GET或POST;
- host 被请求的主机名;
- uri 请求的完整资源标示,包括路径和查询字符串;
- path 请求的路径部分;
- query 请求的查询字符串部分;
- version 使用的HTTP版本;
- headers 请求的协议头,是类字典型的对象,支持关键字索引的方式获取特定协议头信息,例如:request.headers["Content-Type"]
- body 请求体数据;
- remote_ip 客户端的IP地址;
- files 用户上传的文件,为字典类型,型如:
{ "form_filename1":[<tornado.httputil.HTTPFile>, <tornado.httputil.HTTPFile>], "form_filename2":[<tornado.httputil.HTTPFile>,], ... }
tornado.httputil.HTTPFile是接收到的文件对象,它有三个属性:- filename 文件的实际名字,与form_filename1不同,字典中的键名代表的是表单对应项的名字;
- body 文件的数据实体;
- content_type 文件的类型。 这三个对象属性可以像字典一样支持关键字索引,如request.files["form_filename1"][0]["body"]。
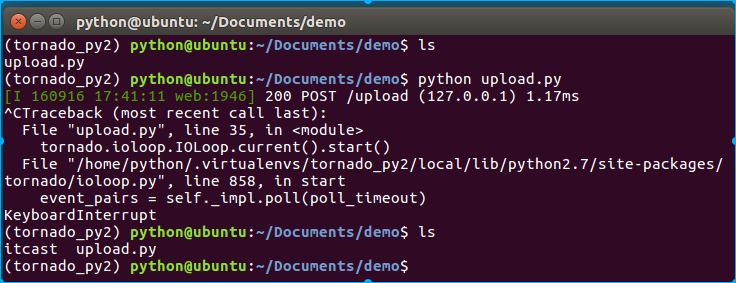
我们来实现一个上传文件并保存在服务器本地的小程序upload.py:
# coding:utf-8
import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import RequestHandler define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def get(self): self.write("hello itcast.") class UploadHandler(RequestHandler): def post(self): files = self.request.files img_files = files.get('img') if img_files: img_file = img_files[0]["body"] file = open("./itcast", 'w+') file.write(img_file) file.close() self.write("OK") if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), (r"/upload", UploadHandler), ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()

5. 正则提取uri
tornado中对于路由映射也支持正则提取uri,提取出来的参数会作为RequestHandler中对应请求方式的成员方法参数。若在正则表达式中定义了名字,则参数按名传递;若未定义名字,则参数按顺序传递。提取出来的参数会作为对应请求方式的成员方法的参数。
# coding:utf-8 import tornado.web import tornado.ioloop import tornado.httpserver import tornado.options from tornado.options import options, define from tornado.web import RequestHandler define("port", default=8000, type=int, help="run server on the given port.") class IndexHandler(RequestHandler): def get(self): self.write("hello itcast.") class SubjectCityHandler(RequestHandler): def get(self, subject, city): self.write(("Subject: %s<br/>City: %s" % (subject, city))) class SubjectDateHandler(RequestHandler): def get(self, date, subject): self.write(("Date: %s<br/>Subject: %s" % (date, subject))) if __name__ == "__main__": tornado.options.parse_command_line() app = tornado.web.Application([ (r"/", IndexHandler), (r"/sub-city/(.+)/([a-z]+)", SubjectCityHandler), # 无名方式 (r"/sub-date/(?P<subject>.+)/(?P<date>\d+)", SubjectDateHandler), # 命名方式 ]) http_server = tornado.httpserver.HTTPServer(app) http_server.listen(options.port) tornado.ioloop.IOLoop.current().start()
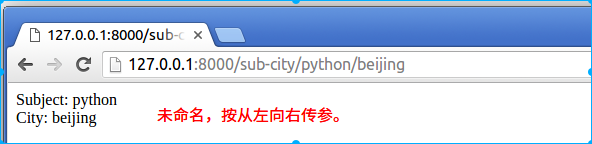

建议:提取多个值时最好用命名方式。
3.3 输出
1. write(chunk)
将chunk数据写到输出缓冲区。如我们在之前的示例代码中写的:
class IndexHandler(RequestHandler): def get(self): self.write("hello itcast!")
想一想,可不可以在同一个处理方法中多次使用write方法?
下面的代码会出现什么效果?
class IndexHandler(RequestHandler): def get(self): self.write("hello itcast 1!") self.write("hello itcast 2!") self.write("hello itcast 3!")
write方法是写到缓冲区的,我们可以像写文件一样多次使用write方法不断追加响应内容,最终所有写到缓冲区的内容一起作为本次请求的响应输出。
想一想,如何利用write方法写json数据?
import json class IndexHandler(RequestHandler): def get(self): stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json)
实际上,我们可以不用自己手动去做json序列化,当write方法检测到我们传入的chunk参数是字典类型后,会自动帮我们转换为json字符串。
class IndexHandler(RequestHandler): def get(self): stu = { "name":"zhangsan", "age":24, "gender":1, } self.write(stu)
两种方式有什么差异?
对比一下两种方式的响应头header中Content-Type字段,自己手动序列化时为Content-Type:text/html; charset=UTF-8,而采用write方法时为Content-Type:application/json; charset=UTF-8。
write方法除了帮我们将字典转换为json字符串之外,还帮我们将Content-Type设置为application/json; charset=UTF-8。
2. set_header(name, value)
利用set_header(name, value)方法,可以手动设置一个名为name、值为value的响应头header字段。
用set_header方法来完成上面write所做的工作。
import json class IndexHandler(RequestHandler): def get(self): stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json) self.set_header("Content-Type", "application/json; charset=UTF-8")
3. set_default_headers()
该方法会在进入HTTP处理方法前先被调用,可以重写此方法来预先设置默认的headers。注意:在HTTP处理方法中使用set_header()方法会覆盖掉在set_default_headers()方法中设置的同名header。
class IndexHandler(RequestHandler): def set_default_headers(self): print "执行了set_default_headers()" # 设置get与post方式的默认响应体格式为json self.set_header("Content-Type", "application/json; charset=UTF-8") # 设置一个名为itcast、值为python的header self.set_header("itcast", "python") def get(self): print "执行了get()" stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json) self.set_header("itcast", "i love python") # 注意此处重写了header中的itcast字段 def post(self): print "执行了post()" stu = { "name":"zhangsan", "age":24, "gender":1, } stu_json = json.dumps(stu) self.write(stu_json)
终端中打印出的执行顺序:

get请求方式的响应header:

post请求方式的响应header:

4. set_status(status_code, reason=None)
为响应设置状态码。
参数说明:
- status_code int类型,状态码,若reason为None,则状态码必须为下表中的。
- reason string类型,描述状态码的词组,若为None,则会被自动填充为下表中的内容。
| Code | Enum Name | Details |
|---|---|---|
| 100 | CONTINUE | HTTP/1.1 RFC 7231, Section 6.2.1 |
| 101 | SWITCHING_PROTOCOLS | HTTP/1.1 RFC 7231, Section 6.2.2 |
| 102 | PROCESSING | WebDAV RFC 2518, Section 10.1 |
| 200 | OK | HTTP/1.1 RFC 7231, Section 6.3.1 |
| 201 | CREATED | HTTP/1.1 RFC 7231, Section 6.3.2 |
| 202 | ACCEPTED | HTTP/1.1 RFC 7231, Section 6.3.3 |
| 203 | NON_AUTHORITATIVE_INFORMATION | HTTP/1.1 RFC 7231, Section 6.3.4 |
| 204 | NO_CONTENT | HTTP/1.1 RFC 7231, Section 6.3.5 |
| 205 | RESET_CONTENT | HTTP/1.1 RFC 7231, Section 6.3.6 |
| 206 | PARTIAL_CONTENT | HTTP/1.1 RFC 7233, Section 4.1 |
| 207 | MULTI_STATUS | WebDAV RFC 4918, Section 11.1 |
| 208 | ALREADY_REPORTED | WebDAV Binding Extensions RFC 5842, Section 7.1 (Experimental) |
| 226 | IM_USED | Delta Encoding in HTTP RFC 3229, Section 10.4.1 |
| 300 | MULTIPLE_CHOICES | HTTP/1.1 RFC 7231, Section 6.4.1 |
| 301 | MOVED_PERMANENTLY | HTTP/1.1 RFC 7231, Section 6.4.2 |
| 302 | FOUND | HTTP/1.1 RFC 7231, Section 6.4.3 |
| 303 | SEE_OTHER | HTTP/1.1 RFC 7231, Section 6.4.4 |
| 304 | NOT_MODIFIED | HTTP/1.1 RFC 7232, Section 4.1 |
| 305 | USE_PROXY | HTTP/1.1 RFC 7231, Section 6.4.5 |
| 307 | TEMPORARY_REDIRECT | HTTP/1.1 RFC 7231, Section 6.4.7 |
| 308 | PERMANENT_REDIRECT | Permanent Redirect RFC 7238, Section 3 (Experimental) |
| 400 | BAD_REQUEST | HTTP/1.1 RFC 7231, Section 6.5.1 |
| 401 | UNAUTHORIZED | HTTP/1.1 Authentication RFC 7235, Section 3.1 |
| 402 | PAYMENT_REQUIRED | HTTP/1.1 RFC 7231, Section 6.5.2 |
| 403 | FORBIDDEN | HTTP/1.1 RFC 7231, Section 6.5.3 |
| 404 | NOT_FOUND | HTTP/1.1 RFC 7231, Section 6.5.4 |
| 405 | METHOD_NOT_ALLOWED | HTTP/1.1 RFC 7231, Section 6.5.5 |
| 406 | NOT_ACCEPTABLE | HTTP/1.1 RFC 7231, Section 6.5.6 |
| 407 | PROXY_AUTHENTICATION_REQUIRED | HTTP/1.1 Authentication RFC 7235, Section 3.2 |
| 408 | REQUEST_TIMEOUT | HTTP/1.1 RFC 7231, Section 6.5.7 |
| 409 | CONFLICT | HTTP/1.1 RFC 7231, Section 6.5.8 |
| 410 | GONE | HTTP/1.1 RFC 7231, Section 6.5.9 |
| 411 | LENGTH_REQUIRED | HTTP/1.1 RFC 7231, Section 6.5.10 |
| 412 | PRECONDITION_FAILED | HTTP/1.1 RFC 7232, Section 4.2 |
| 413 | REQUEST_ENTITY_TOO_LARGE | HTTP/1.1 RFC 7231, Section 6.5.11 |
| 414 | REQUEST_URI_TOO_LONG | HTTP/1.1 RFC 7231, Section 6.5.12 |
| 415 | UNSUPPORTED_MEDIA_TYPE | HTTP/1.1 RFC 7231, Section 6.5.13 |
| 416 | REQUEST_RANGE_NOT_SATISFIABLE | HTTP/1.1 Range Requests RFC 7233, Section 4.4 |
| 417 | EXPECTATION_FAILED | HTTP/1.1 RFC 7231, Section 6.5.14 |
| 422 | UNPROCESSABLE_ENTITY | WebDAV RFC 4918, Section 11.2 |
| 423 | LOCKED | WebDAV RFC 4918, Section 11.3 |
| 424 | FAILED_DEPENDENCY | WebDAV RFC 4918, Section 11.4 |
| 426 | UPGRADE_REQUIRED | HTTP/1.1 RFC 7231, Section 6.5.15 |
| 428 | PRECONDITION_REQUIRED | Additional HTTP Status Codes RFC 6585 |
| 429 | TOO_MANY_REQUESTS | Additional HTTP Status Codes RFC 6585 |
| 431 | REQUEST_HEADER_FIELDS_TOO_LARGE Additional | HTTP Status Codes RFC 6585 |
| 500 | INTERNAL_SERVER_ERROR | HTTP/1.1 RFC 7231, Section 6.6.1 |
| 501 | NOT_IMPLEMENTED | HTTP/1.1 RFC 7231, Section 6.6.2 |
| 502 | BAD_GATEWAY | HTTP/1.1 RFC 7231, Section 6.6.3 |
| 503 | SERVICE_UNAVAILABLE | HTTP/1.1 RFC 7231, Section 6.6.4 |
| 504 | GATEWAY_TIMEOUT | HTTP/1.1 RFC 7231, Section 6.6.5 |
| 505 | HTTP_VERSION_NOT_SUPPORTED | HTTP/1.1 RFC 7231, Section 6.6.6 |
| 506 | VARIANT_ALSO_NEGOTIATES | Transparent Content Negotiation in HTTP RFC 2295, Section 8.1 (Experimental) |
| 507 | INSUFFICIENT_STORAGE | WebDAV RFC 4918, Section 11.5 |
| 508 | LOOP_DETECTED | WebDAV Binding Extensions RFC 5842, Section 7.2 (Experimental) |
| 510 | NOT_EXTENDED | An HTTP Extension Framework RFC 2774, Section 7 (Experimental) |
| 511 | NETWORK_AUTHENTICATION_REQUIRED | Additional HTTP Status Codes RFC 6585, Section 6 |
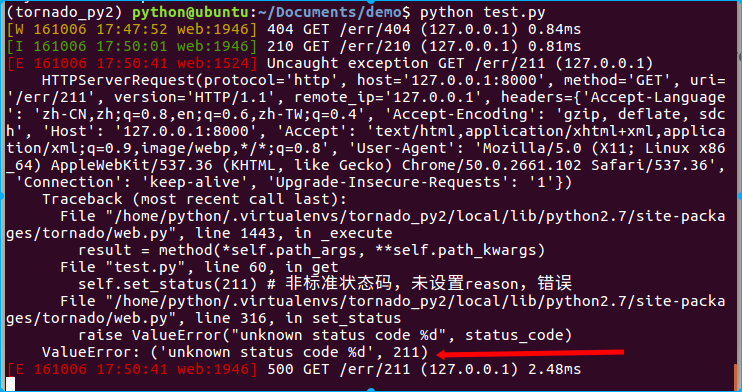
class Err404Handler(RequestHandler): """对应/err/404""" def get(self): self.write("hello itcast") self.set_status(404) # 标准状态码,不用设置reason class Err210Handler(RequestHandler): """对应/err/210""" def get(self): self.write("hello itcast") self.set_status(210, "itcast error") # 非标准状态码,设置了reason class Err211Handler(RequestHandler): """对应/err/211""" def get(self): self.write("hello itcast") self.set_status(211) # 非标准状态码,未设置reason,错误


5. redirect(url)
告知浏览器跳转到url。
class IndexHandler(RequestHandler): """对应/""" def get(self): self.write("主页") class LoginHandler(RequestHandler): """对应/login""" def get(self): self.write('<form method="post"><input type="submit" value="登陆"></form>') def post(self): self.redirect("/")
6. send_error(status_code=500, **kwargs)
抛出HTTP错误状态码status_code,默认为500,kwargs为可变命名参数。使用send_error抛出错误后tornado会调用write_error()方法进行处理,并返回给浏览器处理后的错误页面。
class IndexHandler(RequestHandler): def get(self): self.write("主页") self.send_error(404, content="出现404错误")
注意:默认的write\_error()方法不会处理send\_error抛出的kwargs参数,即上面的代码中content="出现404错误"是没有意义的。
尝试下面的代码会出现什么问题?
class IndexHandler(RequestHandler): def get(self): self.write("主页") self.send_error(404, content="出现404错误") self.write("结束") # 我们在send_error再次向输出缓冲区写内容
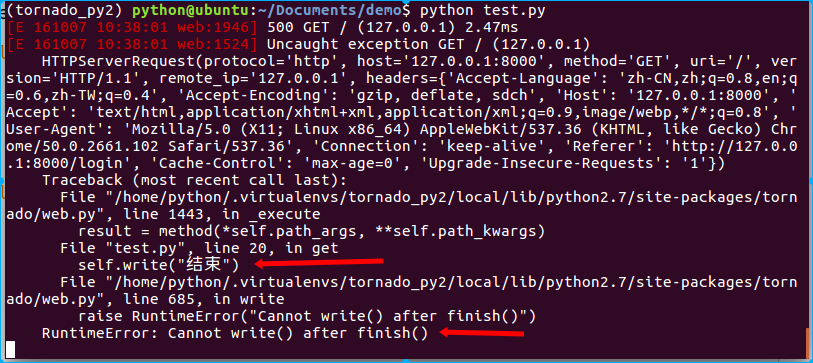
注意:使用send_error()方法后就不要再向输出缓冲区写内容了!
7. write_error(status_code, **kwargs)
用来处理send_error抛出的错误信息并返回给浏览器错误信息页面。可以重写此方法来定制自己的错误显示页面。
class IndexHandler(RequestHandler): def get(self): err_code = self.get_argument("code", None) # 注意返回的是unicode字符串,下同 err_title = self.get_argument("title", "") err_content = self.get_argument("content", "") if err_code: self.send_error(err_code, title=err_title, content=err_content) else: self.write("主页") def write_error(self, status_code, **kwargs): self.write(u"<h1>出错了,程序员GG正在赶过来!</h1>") self.write(u"<p>错误名:%s</p>" % kwargs["title"]) self.write(u"<p>错误详情:%s</p>" % kwargs["content"])

3.4 接口与调用顺序
下面的接口方法是由tornado框架进行调用的,我们可以选择性的重写这些方法。
1. initialize()
对应每个请求的处理类Handler在构造一个实例后首先执行initialize()方法。在讲输入时提到,路由映射中的第三个字典型参数会作为该方法的命名参数传递,如:
class ProfileHandler(RequestHandler): def initialize(self, database): self.database = database def get(self): ... app = Application([ (r'/user/(.*)', ProfileHandler, dict(database=database)), ])
此方法通常用来初始化参数(对象属性),很少使用。
2. prepare()
预处理,即在执行对应请求方式的HTTP方法(如get、post等)前先执行,注意:不论以何种HTTP方式请求,都会执行prepare()方法。
以预处理请求体中的json数据为例:
import json class IndexHandler(RequestHandler): def prepare(self): if self.request.headers.get("Content-Type").startswith("application/json"): self.json_dict = json.loads(self.request.body) else: self.json_dict = None def post(self): if self.json_dict: for key, value in self.json_dict.items(): self.write("<h3>%s</h3><p>%s</p>" % (key, value)) def put(self): if self.json_dict: for key, value in self.json_dict.items(): self.write("<h3>%s</h3><p>%s</p>" % (key, value))
用post方式发送json数据时:
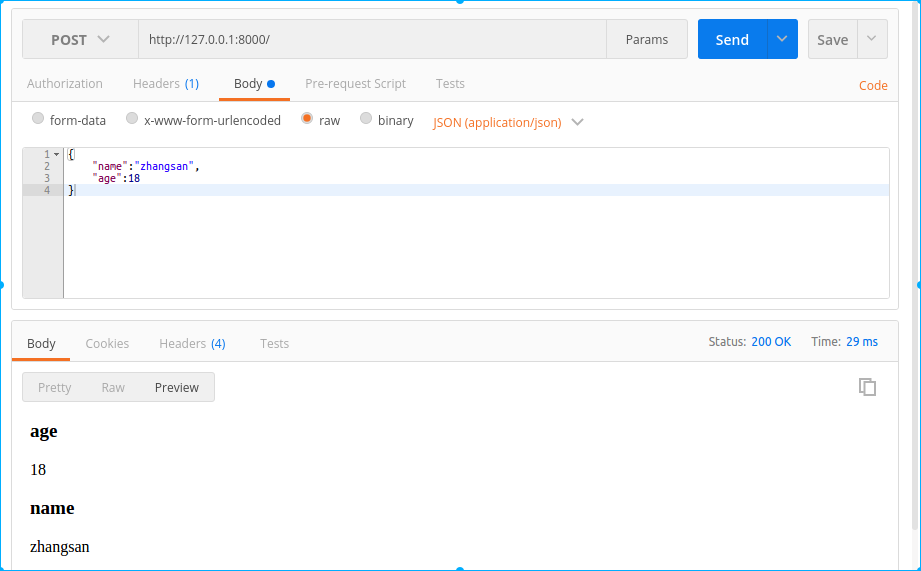
用put方式发送json数据时:
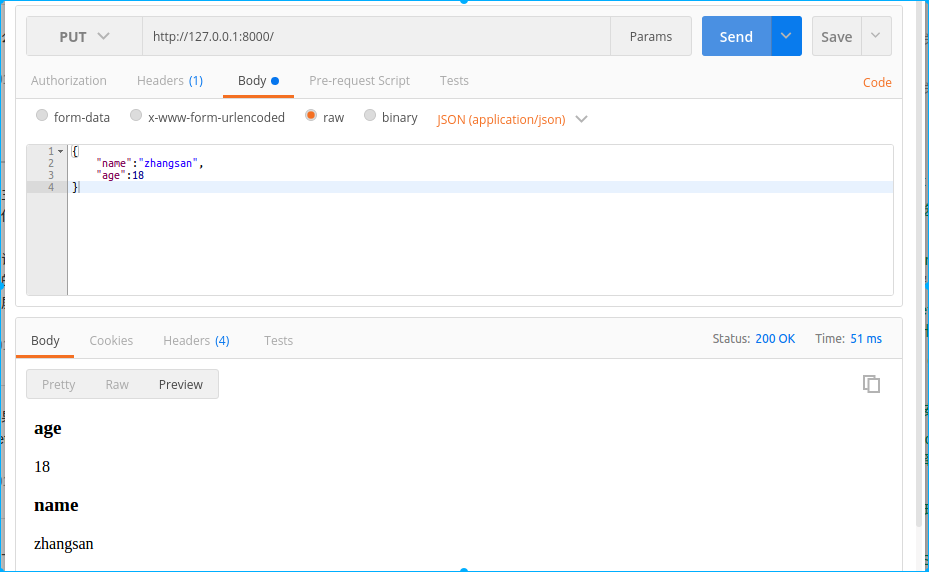
3. HTTP方法
| 方法 | 描述 |
|---|---|
| get | 请求指定的页面信息,并返回实体主体。 |
| head | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| post | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| delete | 请求服务器删除指定的内容。 |
| patch | 请求修改局部数据。 |
| put | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| options | 返回给定URL支持的所有HTTP方法。 |
4. on_finish()
在请求处理结束后调用,即在调用HTTP方法后调用。通常该方法用来进行资源清理释放或处理日志等。注意:请尽量不要在此方法中进行响应输出。
5. set_default_headers()
6. write_error()
7. 调用顺序
我们通过一段程序来看上面这些接口的调用顺序。
class IndexHandler(RequestHandler): def initialize(self): print "调用了initialize()" def prepare(self): print "调用了prepare()" def set_default_headers(self): print "调用了set_default_headers()" def write_error(self, status_code, **kwargs): print "调用了write_error()" def get(self): print "调用了get()" def post(self): print "调用了post()" self.send_error(200) # 注意此出抛出了错误 def on_finish(self): print "调用了on_finish()"
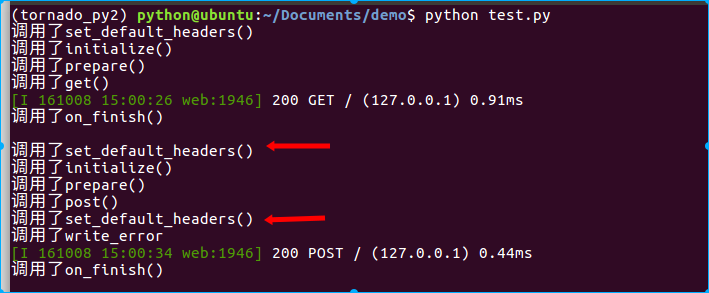
在正常情况未抛出错误时,调用顺序为:
- set_defautl_headers()
- initialize()
- prepare()
- HTTP方法
- on_finish()
在有错误抛出时,调用顺序为:
- set_default_headers()
- initialize()
- prepare()
- HTTP方法
- set_default_headers()
- write_error()
- on_finish()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号