
零拷贝-zero copy
Efficient data transfer through zero copy
Zero Copy I: User-Mode Perspective
0. 前言
在阅读RocketMQ的官方文档时,发现Chapter6.1中关于零拷贝的叙述中有点不理解,因此查阅了相关资料,来解释文中的说法。
Consumer消费消息过程,使用了零拷贝,零拷贝包含以下两种方式
- 使用mmap + write方式 优点:即使频繁调用,使用小块文件传输,效率也很高 缺点:不能很好的利用DMA方式,会比sendfile多消耗CPU,内存安全性控制复杂,需要避免JVM Crash问题。
- 使用sendfile方式 优点:可以利用DMA方式,消耗CPU较少,大块文件传输效率高,无内存安全新问题。 缺点:小块文件效率低于mmap方式,只能是BIO方式传输,不能使用NIO。
RocketMQ选择了第一种方式,mmap+write方式,因为有小块数据传输的需求,效果会比sendfile更好。
为什么mmap会多消耗CPU?
为什么mmap比sendfile内存安全性控制复杂,为什么mmap会引起JVM Crash?
为什么sendfile只能是BIO的,不能使用NIO?
为什么mmap对于小块数据传输的需求效果更好?
- 这个问题其实很好解答,如果上一个说法成立,mmap支持NIO,sendfile只能BIO传输,那么NIO的特性本身就会对数据块小、请求个数多的传输需求有很好的支持。
1. 零拷贝 Zero copy
1.1 no zero-copy
Web应用程序通常提供大量静态内容,例如使用聊天工具向好友发送了一张本地图片,应用程序需要从磁盘读取图片数据,并将完全相同的数据写到响应socket中,通过网络发送给对方。这个操作看起来貌似不需要占用过多的CPU资源,因为没有计算的需求,但仍然效率较低:内核从磁盘读取数据并将其推送到应用程序,然后应用程序将其推回到内核写到套接字。这种场景下,应用程序充当了一个低效的中介,它将数据从磁盘文件获取到套接字。
1.2 zero copy
每次数据经过用户内核边界时,都必须复制一次数据,这会消耗CPU周期和内存带宽。zero-copy技术的出现就是通过减少复制次数来消除这些副本。使用零拷贝请求的应用程序,内核将数据直接从磁盘文件复制到套接字,而不用 无需通过应用程序。零拷贝极大地提高了应用程序性能,并减少了内核和用户模式之间的上下文切换次数。
1.3 Java中的zero copy
Java类库通过java.nio.channels.FileChannel中的transferTo()方法在Linux和UNIX系统上支持零拷贝。使用transferTo()法将字节直接从调用它的通道传输到另一个可写字节通道,而不需要数据流经应用程序。
本文先解释下传统复制,然后介绍zero copy的几种机制,最后解释前言中的疑问。
1.4 类比举例
在干货之前,先喝口汤压压惊。举个通俗点的例子来类比描述传统的 no zero-copy的做法,A用左手拿筷子要吃饭,B告诉你A,你需要用右手拿筷子,然后A把筷子从左手给了B,然后B又把筷子塞到A的右手里,A开始吃饭。
A和B这里可以看成两个上下文,A的左手传递筷子给B之后,切换到了B的上下文,B传递给A的右手,又切换回A的上下文,这个代价其实是非常昂贵的。
为了减少这种昂贵的代价,我们可以想象一些场景来逐步降低事情的复杂度。
最直观最简单的方法,B只需要告诉A,也就是说B发出一条指令,A接收指令之后,自己把筷子从左手换到右手,就可以既减少了上下文的切换,减轻了B的压力,又减少了传递的次数和沟通代价。然而这需要A具备这样的功能,计算机中某些硬件可以提供这样的支持,但是如果A是一个不满3岁的孩子,他可能听不懂你的话,又或者不明白如何把筷子从左手转到右手。
这个时候B只需要扶住A的左手,帮他把筷子换到右手里。这样,也缩减了这个过程中的代价。
2. 传统传输方式
Linux标准访问文件方式
在Linux中,访问文件的方式是通过两个系统调用实现的:read()和write()。
当应用程序调用read()系统调用读取一块数据的时候:
- 如果该块数据已经在内存中,就直接从内存中读取数据并返回给应用程序;
- 如果该块数据不在内存中,name数据会被从磁盘上读取到页缓存中,再从页缓存中拷贝到用户地址空间中去。
如果一个进程读取某个文件,那么其他进程就都不可以读取或者更改该文件;对于写操作,当一个进程调用了write()系统调用往某个文件中写数据的时候,数据会先从用户地址空间拷贝到操作系统内核地址空间的页缓存中,然后才被写到磁盘上。
对于这种标准的访问文件方式,在数据被写到页缓存中时,write()系统调用就算执行完成,并不会等数据完全写入到磁盘上。
Linux在这里采用的是延迟写机制。
一般情况下,应用程序采取的写操作机制有三种:
- 同步写(Synchronous Writes),数据会立即从缓存页写回磁盘,应用程序会一直等待到写入磁盘的结束。
- 异步写(Asynchronous Writes),数据写入缓存页后,操作系统会定期将页缓存中的数据刷到磁盘上,在写入磁盘结束后,系统会通知应用程序写入已完成。
- 延迟写(Deferred Writes),数据写入缓存页后立即返回应用程序写入成功,操作系统定期将页缓存中是数据刷入磁盘,由于写入页缓存时已经返回吸入成功,写入磁盘之后不会通知应用程序。因此延迟写机制是存在数据丢失的风险的。
2.1 传输过程
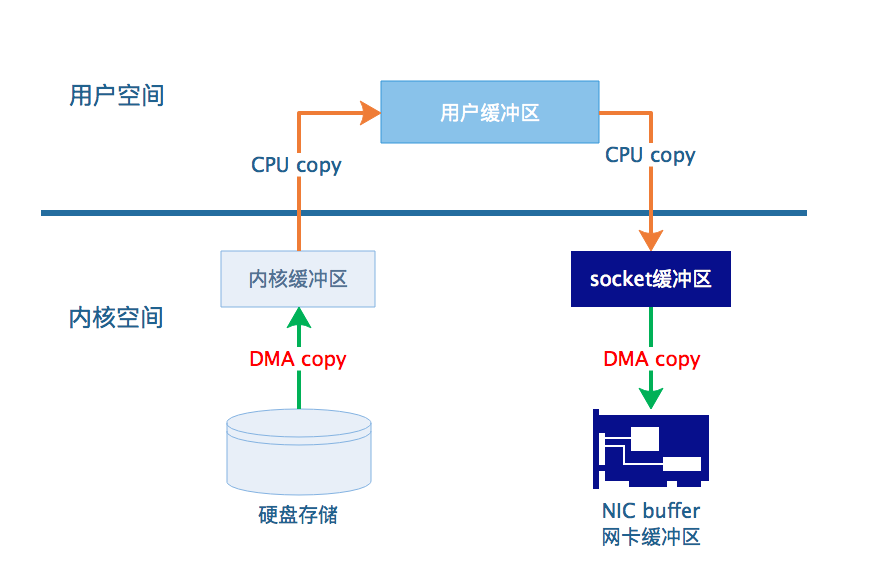
图1. 传统方式数据传输示意图
如上图所示,数据按箭头的方向流动,从本地终端的硬盘存储中读取数据,经过4次copy,最终到达NIC buffer,通过网卡再发送给其他终端。
这种传输方式实际上是一种经过优化的设计,虽然看起来效率比较低下,但是内核缓冲区的存在使得整个流程的性能得到了提升。内核缓冲区的引入充当了预读缓存的角色,使得数据并不是直接从硬盘到用户缓冲区,而是允许应用程序在未请求的情况下,内核缓冲区中已经存在了相应的数据。
内核空间内,内存与硬件存储之间的数据传输使用了DMA直接内存存取的复制方式,这种方式不需要CPU的参与,并且提高读取速度。CPU也因此可以趁机去完成其他的工作。
例如用户缓冲区大小为4K,内核缓冲区大小为8K,文件总大小为40K,每次用户请求读取4K数据时,内核缓冲区中已经预读存入了相应的数据。
硬盘到内存(内核缓冲区)的数据传输速度是比较慢的,尤其是SSD应用之前,而内核缓冲区到用户缓冲区这种内存到内存的复制相对较快,用户缓冲区就不用等待硬盘数据传输到内存。广义上也是一种空间换时间的做法。
然而,一些情况下内核缓冲区也无法完全跟上应用程序的步伐,比如用户缓冲区的大于内核缓冲区的大小。预读的数据无法满足需要,仍然需要等待硬盘到内存的缓慢传输。此时性能将会大打折扣。
尽管做了很多优化,如图所示,数据已经被复制了至少四次,并且执行了多次的用户和内核上下文的切换。实际上这个过程比图示要复杂得多。
2.2 上下文切换和数据复制过程
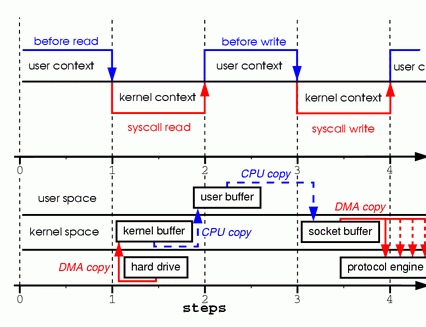
图2.上下文切换和数据复制
图2所示是传统方式数据传输(图1)时上下文切换和数据复制的过程。上半部分表示上下文切换,下半部分表示数据复制流程。
step 1
系统调用读操作时,上下文会从用户模式切换到内核模式。在内核空间中,DMA引擎执行了第一次数据拷贝,将数据从硬盘等其他存储设备上导入到内核缓冲区。
step 2
数据从内核缓冲区拷贝到用户缓冲区,系统调用读操作结束并返回。调用的返回会导致又一次的上下文切换,上下文从内核又切换到用户模式。
step 3
系统写操作开始调用,进行第三次数据复制,将数据从用户缓冲区写回内核的socket缓冲区,此时回引起一次从用户模式到内核模式的上下文切换。
step 4
写操作的系统调用返回,引起第四次上下文切换。开始第四次数据复制,数据从内核缓冲区复制到协议引擎。这次复制是异步并且独立的,系统不保证数据一定会传输,这次返回只是任务提交成功,数据包进入了队列,等待传输。就像线程池模型中任务提交时,任务只是成功提交到任务队列,何时开始执行上游调用程序并不知情。
summary
传统的传输方式会存在大量的数据复制和上下文切换,如果这些重复可以消除一部分,就可以减少开销并提升性能。某些硬件可以绕过主存储器将数据直接传输到另一个设备,但是如1.4中的类比描述一样,并不是所有硬件都支持这项功能,而且这项功能的实现远非这么简单。
为了降低开销,我们可以减少复制,而不是直接消除复制。
系统为了减少复制所采用的所有方式中,最多的就是让这些传输尽可能不跨越用户空间和内核空间的边界,因为每次跨越边界就意味着一次复制。
3. zero-copy mmap
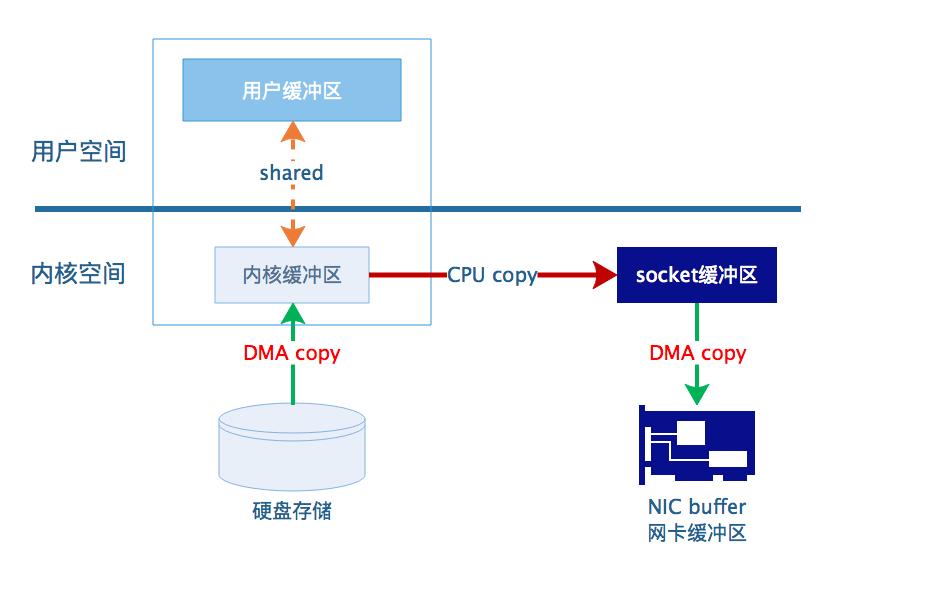
图3. mmap方式零拷贝数据传输示意图
mmap系统调用的方式如下:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
这种方式用到两种系统调用,mmap+write。
这种传输方式使用mmap()代替了read(),磁盘上的数据会通过DMA被拷贝到内核缓冲区,然后操作系统会把这块内核缓冲区与应用程序共享,这样就避免了跨越边界的一次复制。应用程序再调用write()直接将内核缓冲区的内容拷贝到socket缓冲区,最后系统把数据从socket缓冲区传输到网卡。
mmap减少了一次拷贝,提升了效率。但是mmap也可能遇到一些隐藏的问题。例如,当应用程序map了一个文件,但是这个文件被另一个进程截断时,write()系统调用会因为访问非法地址而被SIGBUS信号终止。SIGBUS信号默认会杀死你的进程并产生一个coredump。
解决mmap上述问题的方式通常有两种:
- 增加对
SIGBUS信号的处理程序
当遇到SIGBUS信号时,处理程序可以直接去调用return,这样,write调用在被中断之前返回已经写入的字节数并且将errno设置为success。但是这么处理显得较为粗糙。 - 使用文件租借锁
在文件描述符上使用租借锁,这样当有进程要截断这个文件时,内核会立刻发送一个RT_SIGNAL_LEASE信号,这样在程序访问非法内存之前,中断write调用,返回已经写入的字节数,并将errno设置为success,而不必等到write被SIGBUS杀死再做处理。
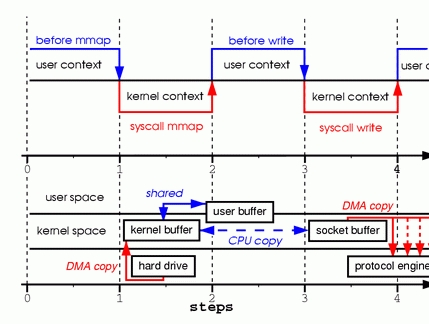
图4 mmap上下文切换与数据传输
如上图所示,mmap+write的复制减少了文件的复制,但是上下文切换的次数和read+write的方式是一样的。
4. sendfile
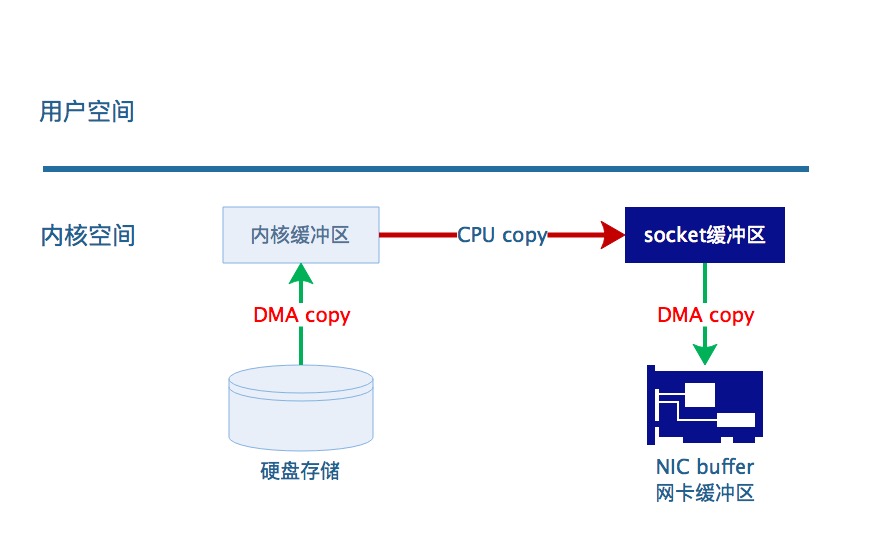
图5 sendfile数据传输示意图
Linux的内核版本2.1之后,系统引入了sendfile来简化文件传输到网络的工作,这种方式不仅减少了拷贝次数,也减少了上下文的切换。
使用sendfile代替了read+write操作。
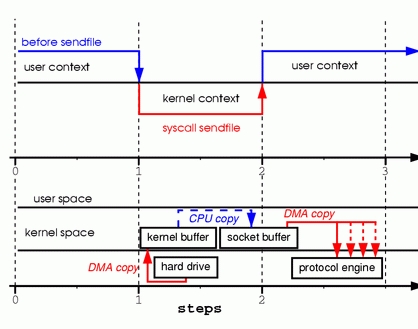
图6 sendfile上下文切换与数据传输
数据发生三次拷贝,首先sendfile系统调用,通过DMA引擎将文件复制到内核缓冲区。
在内核区,内核将数据复制到socket缓冲区。
最后,DMA引擎将数据从内核socket缓冲区传递到协议引擎中(网卡)。
sendfile是否会遇到和mmap同样的隐藏问题?
- 如果另一个进程截断了使用
sendfile传输的文件,sendfile在没有任何信号处理程序的情况下,会返回被中断前传输的字节数,并且errno被设置为success。 - 如果使用了文件租借锁,sendfile可以获得
RT_SIGNAL_LEASE信号,并给出和没有使用文件租借锁同样的返回。
5. 使用DMA gather copy的sendfile
在内核2.4版本之后,sendfile可以在硬件支持的情况下实现更高效的传输。
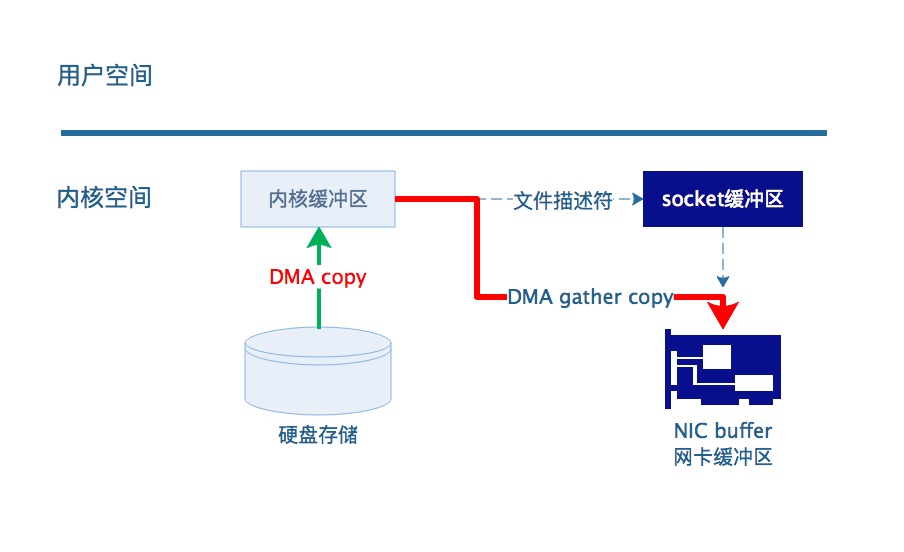
图7 使用DMA gather copy的sendfile数据传输示意图
在硬件的支持下,不再从内核缓冲区的数据拷贝到socket缓冲区,取而代之的仅仅是缓冲区文件描述符和数据长度的拷贝。
这样DMA引擎直接将页缓存中数据打包发送到网络中即可。
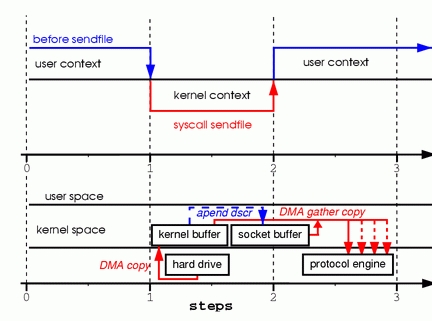
图8 DMA gather copy的sendfile上下文切换与数据传输
这种方式避免了最后一次拷贝,并且减轻了CPU的负担,省去了页缓存到socket缓冲区的CPU Copy。这种sendfile是Linux中真正的零拷贝,虽然依然需要磁盘到内存的复制,但是内核空间和用户空间内已经不存在任何多余的复制。
这种方式的前提是硬件和相关驱动程序支持DMA Gather Copy。
6.总结
通过以上描述,可以解答文章开始的几个问题。
为什么mmap会多消耗CPU?
mmap没有完全消除内存中的文件复制,从页缓存到socket缓冲区需要进行CPU Copy,并且上下文的切换次数和传统的read+write方式一样。
因此,相对于sendfile,mmap会占用更多的CPU资源。
为什么mmap比sendfile内存安全性控制复杂,为什么mmap会引起JVM Crash?
mmap没有提供被其他进程截断时的处理,需要添加对SIGBUS信号中断的处理。由于截断后,mmap访问了非法内存,SIGBUS信号会导致JVM Crash的问题。
为什么sendfile只能是BIO的,不能使用NIO?(个人理解,未验证)
sendfile在使用DMA gather copy的情况下,降低了CPU资源的占用,减少了文件复制和上下文切换次数,但是由于socket缓冲区中拿到的只是文件描述符和数据长度,并没有拿到真正的文件,因此并不能执行write等相关操作异步写或者延迟写,只能进行同步写。这也是减少上下文切换付出的代价,接收到sendfile后,都在内核态执行,缺少应用程序的干预因此可控性也较差。所以sendfile只能使用BIO这种同步阻塞的IO。
However, 在大文件的传输上,sendfile依然是最佳的方式。
Java中NIO的类库通过java.nio.channels.FileChannel中的transferTo()依赖的零拷贝是sendfile,因此实质上transferTo并不支持真正意义上的NIO。
而mmap+write的方式,使真正的文件被复制到socket缓冲区,从socket缓冲区到网卡的复制过程是可以异步的,但是这种操作意味着更多的CPU消耗。
RocketMQ中更多的需求是小文件的传输,而NIO的特性可以更快更高效的应对这种场景。在这种权衡考量下,牺牲部分CPU资源来换取更高的文件传输效率的选择显然是一种更优的方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号