python | scrapy
进入某网页的步骤分为
- 域名解析,找到域名对应的ip地址
- 向ip地址的服务器发送请求
- 服务器响应,返回内容(html/json
- 浏览器解析网页内容
爬虫即实现浏览器功能,通过发送请求而后解析内容返回自己想要的
解决如何请求和解析就可以了
请求先看看那个网页F12查看一下Network中发送的请求(如果只是获取页面内容的话,单纯像我练习里一样,就是直接get请求了
解析我认为重点是正则表达式,对样式class name id的取用方法要有了解,多加尝试
先入个门吧,这个是作为爬虫新手的必要练手网站
http://news.163.com/special/000120FU/test080617.html
抓取页面
request请求是必要的,导包,写个方法表示爬取页面,用utf-8解码即可,这里我们已经完成了上述讲的23步骤,获取页面只用最简单的get即可
get(url)得到一个res,请求状态,content获得返回的内容再通过utf-8解码即可


import requests def Spider(url): print("拉取",url) page = requests.get(url).content.decode("utf-8")
用print(page)打印查看
分解
我们主要爬取的是如下的每个标题下的新闻,F12查看源码找到这个标签的html代码块
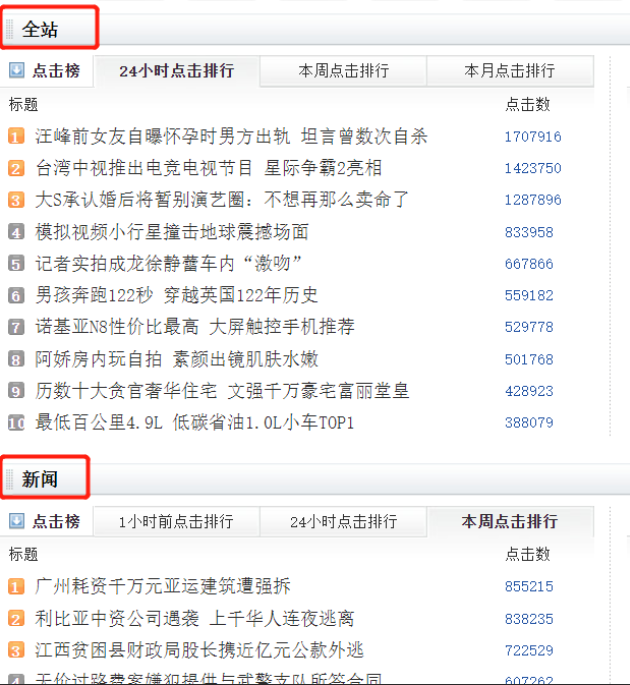
可以看到作为卡片标题的全站、新闻、娱乐等等,都是一个class为titleBar的div标签内的h2标签,而后是一个left、right作为点击榜和跟贴榜
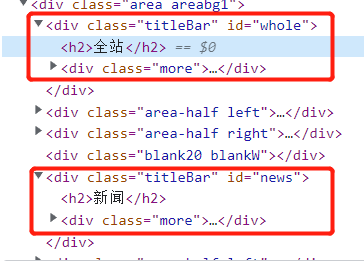
把代码块复制出来,这一段除了whole、全站和a中的链接部分,均是一样的,用.*?正则代替取出
<div class="titleBar" id="whole"> <h2>全站</h2> <div class="more"> <a href="http://news.163.com/special/0001386F/rank_whole.html">更多</a> </div> </div>
👇得到一个list
page_info = re.findall( r'<div class="titleBar" id=".*?">' r'<h2>(.*?)</h2>' r'<div class="more">' r'<a href="(.*?)">.*?</a>' r'</div>' r'</div>', page, re.S) # re.S就是把字符串里的\n也算在匹配里面 # [('全站', 'http://news.163.com/special/0001386F/rank_whole.html'), # ('新闻', 'http://news.163.com/special/0001386F/rank_news.html'), # ('娱乐', 'http://news.163.com/special/0001386F/rank_ent.html'), # ('体育', 'http://news.163.com/special/0001386F/rank_sports.html'), # ... # ]
二次抓取
获得分类和其对应链接后,要做的就是进入更多的链接中,但是哈但是,我发现用浏览器打开最后总是会跳到163.com(可恶的网易,只能用postman来请求一下了,乱码,idcare,姐只要你html代码
它藏了个跳转👇 全部复制出来新建一个html,把这段删掉也行,乱码的话把meta里的gb2312改成utf-8即可
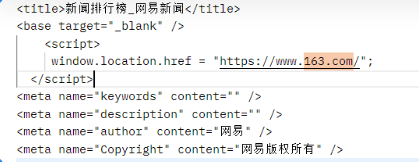
点击榜和跟帖榜差不太多,一个class是left一个是right,然后是同样的tabBox、title-tab......二者都会有重复的新闻,去除重复的然后存起来
dom
dom树,之前写vue的时候老整这出。就是浏览器把html里面标签嵌套标签那种联系成树结构
item_title = dom.xpath('//tr/td/a/text()')
像这样就可以轻而易举的获得<tr><td><a>text</a></td></tr>里面的text,在这里也就是新闻标题,关于a标签的链接就是href属性用@来获得
item_link = dom.xpath('//tr/td/a/@href')
去重
没有含量的去重,本来想的是转set再转回list,但是获得新闻标题的时候有一些字数限制所以导致还会有重复,主要还是看跳转链接是否重复,是否有更简单的表达方式还带讨论,这里就是很随便的用set判断了,不做赘述
new_list = [] for d in item_list: t = d[1] if t not in new_seen: new_seen.add(t) new_list.append(d)
完整代码
短短几行代码道尽了Java的心酸
from lxml import etree import requests import re def Spider(url): print("拉取",url) page = requests.get(url).content.decode("utf-8") page_info = re.findall( r'<div class="titleBar" id=".*?">' r'<h2>(.*?)</h2>' r'<div class="more">' r'<a href="(.*?)">.*?</a>' r'</div>' r'</div>', page, re.S) new_seen = set() # 根据链接去重 new_dict = {} # {新闻标签,新闻list}格式 for item in page_info: new_page = requests.get(item[1]).content.decode("utf-8") dom = etree.HTML(new_page) # dom树解析html页面 item_title = dom.xpath('//tr/td/a/text()') item_link = dom.xpath('//tr/td/a/@href') item_list = zip(item_title,item_link) # 迭代对象压缩打包成一个元组 new_list = [] # 新闻list for d in item_list: t = d[1] if t not in new_seen: new_seen.add(t) new_list.append(d) new_dict[item[0]] = new_list print(new_dict) if __name__ == '__main__': print("那我们开始吧!") start_url = "http://news.163.com/special/000120FU/test080617.html" Spider(start_url) print("end")
scrapy框架
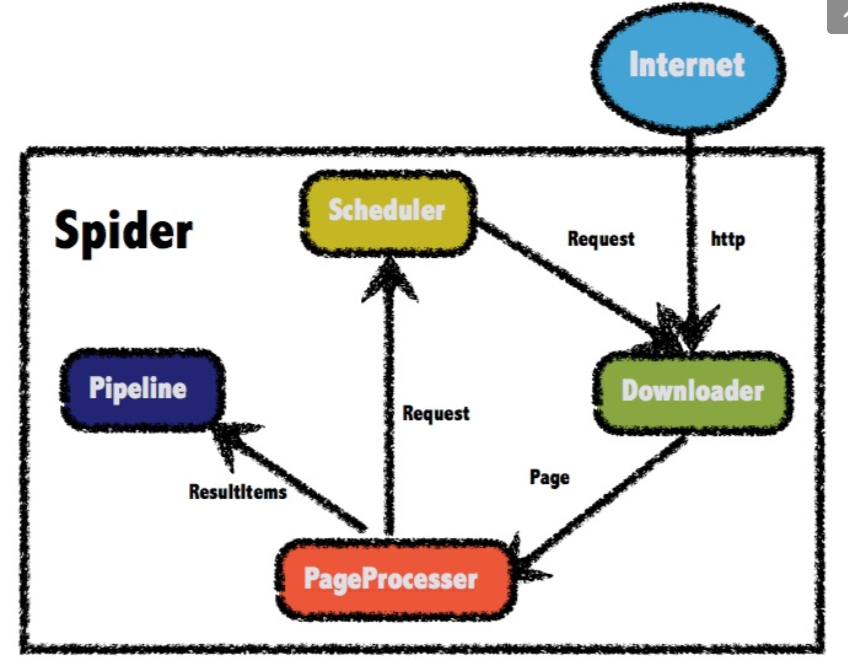
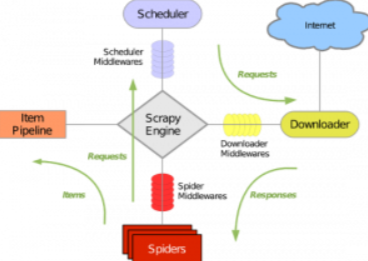
一样的,由一个Downloader来拉取页面,Scheduler调度器等待请求,Spiders(PageProcesser)制定解析规则,Pipeline对Spiders完成的数据进行后续存储/处理工作;scrapy通过一个引擎作为中心处理事务,还有一些中间件。
大概就这么一个流程吧!
环境
pip install scrapy scrapy startproject test0927 cd test0927
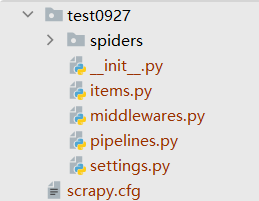
创建的文件目录
cfg —— 配置文件
items —— 抓取的内容(/dict
middlewares —— 中间件
pipelines —— 如上所述
settings —— 设置文件
spider(制作爬虫)
菜鸟网站拿https://www.itcast.cn/举例,是个广告耶
进入创建的目录后使用 scrapy genspider 文件名 "域名"
name作为识别名称/allowed_domains作为域名范围/start_urls作为爬取的URL元组,parse()定义解析的方法,download结束后就调用parse解析
跟着教程走将itcast修改如下,即抓取链接页面,返回的信息写入teacher.html中
因为发现response.body是bytes类型的无法直接写入在这里decode解码后再写入,用了codecs免去了很多因为编码问题无法写入的问题(因为报错了,gbk什么的太讨人厌啦
import scrapy import codecs class ItcastSpider(scrapy.Spider): name = "itcast" allowed_domains = ["itcast.cn"] start_urls = ( "http://www.itcast.cn/channel/teacher.shtml", ) def parse(self, response): filename = "teacher.html" codecs.open(filename,"w","utf-8").write(response.body.decode("utf-8"))
输入 scrapy crawl itcast 运行当前我们编写的爬虫
items(数据)
获取标题然后输出
response带的xpath,这样就不用自己导入dom树了,直接找到对应的html代码片段右键把xpath拷贝出来即可
context = response.xpath('/html/head/title/text()') title = context.extract_first() print(title)
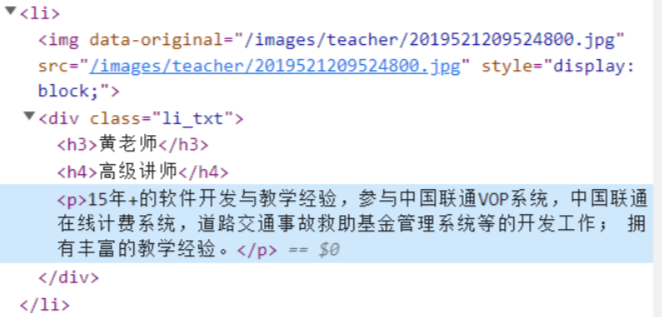
以上是简单的爬取标题,使用items将数据封装到items中,瞅一眼老师的属性,名字、职称、介绍
在<div class="li_txt">下
在items下建一个类
class Teacher(scrapy.Item): # define the fields for your item here like: name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()
引入 然后通过xpath和extract获得对应属性 存入list中
from test0927.items import Teacher class ItcastSpider(scrapy.Spider): name = "itcast" allowed_domains = ["itcast.cn"] start_urls = ( "http://www.itcast.cn/channel/teacher.shtml", ) def parse(self, response): items = [] for each in response.xpath("//div[@class='li_txt']"): item = Teacher() item['name'] = each.xpath("h3/text()").extract()[0] item['title'] = each.xpath("h4/text()").extract()[0] item['info'] = each.xpath("p/text()").extract()[0] items.append(item) print(items) return items
数据导出
-o output输出指定格式的文件
scrapy crawl itcast -o teachers.json
json/csv/xml格式等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号