《UNIFusion: A Lightweight Unified Image Fusion Network》论文解读+代码【更新中】
论文+代码链接
摘要
作者提出了一个轻量化的网络模型,用来解决不同的图像融合任务(通用模型)。使用了一个引导滤波的操作,将图像分解,从而不同层级可以使用不同的融合策略,为融合策略组合提供了更多可能。其中为多聚焦图像融合任务设计了一个梯度感知融合策略。指标SOTA。
引言
引言部分,分成传统和深度方法做介绍,然后提了一下传统,逐渐过渡到深度方法的简介。最早的深度融合,还是17年的用CNN来生成聚焦决策块,手工生成的数据集,性能有限。然后说一嘴GAN和Autoencoder类型的方法。但是都是针对单一任务的,没有做到通用。
通用方法部分,IFCNN用一个景深数据集生成多聚焦图像,来做通用模型,但是同样手工数据集,面向单一任务,泛化性能有限。相比于目标不明确的融合任务,自编码器的训练更容易。
提到了GhostNet这个轻量化的网络模型,介绍了一下GhostModule这个分组卷积的操作减少计算量。
提了下梯度感知的操作, 强调了下该策略在多聚焦图像融合中有很好的表现。
相关工作
- 主要介绍了基于自编码网络的一些方法,画了个图展示了下框架。
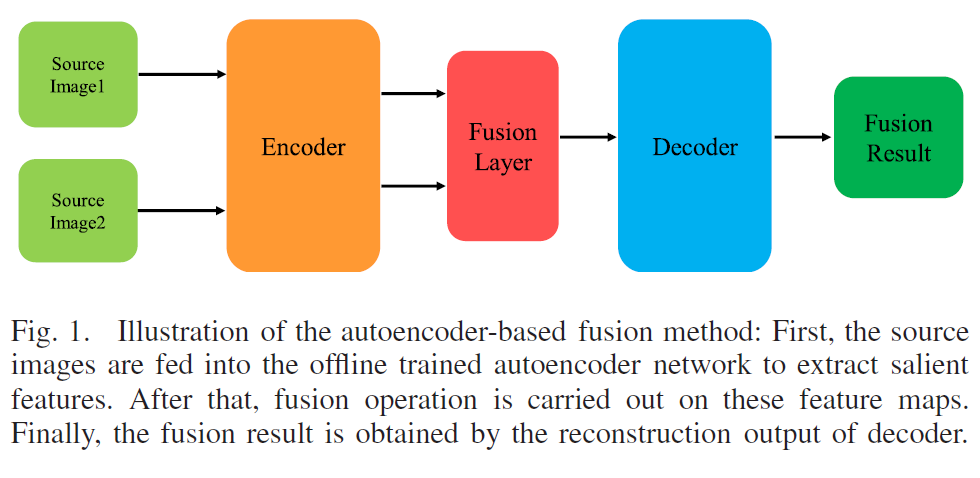
-
说了下基于深度学习的图像融合方法的一些进展。
-
介绍了GhostMoule模块,主要是针对特征图里有冗余的通道,所以先生成本质特征图,再基于这些本质特征图生成剩余冗余部分。
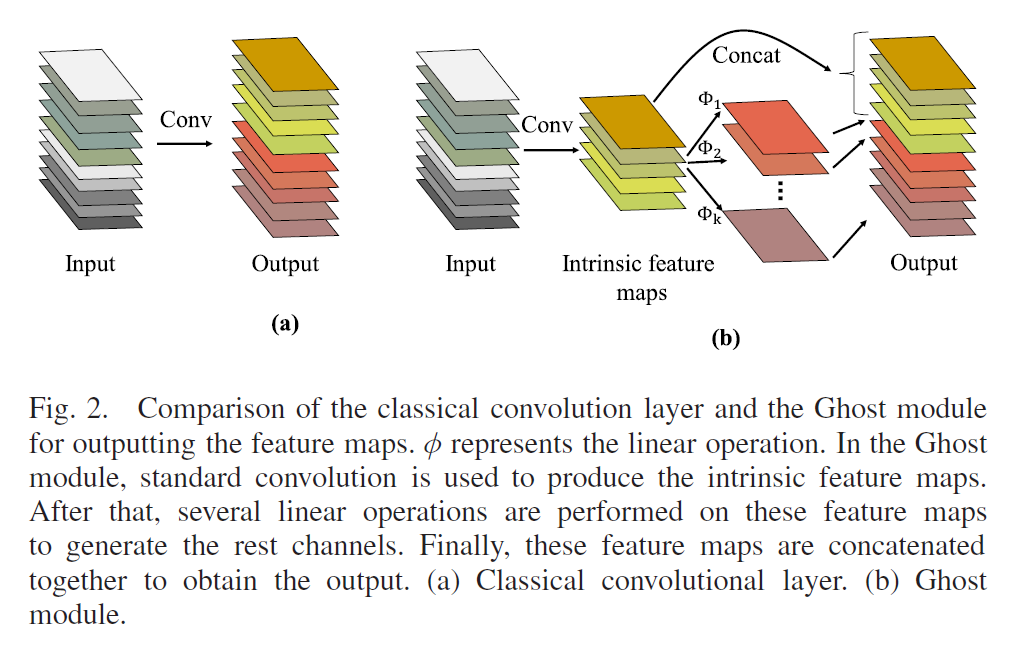
方法论
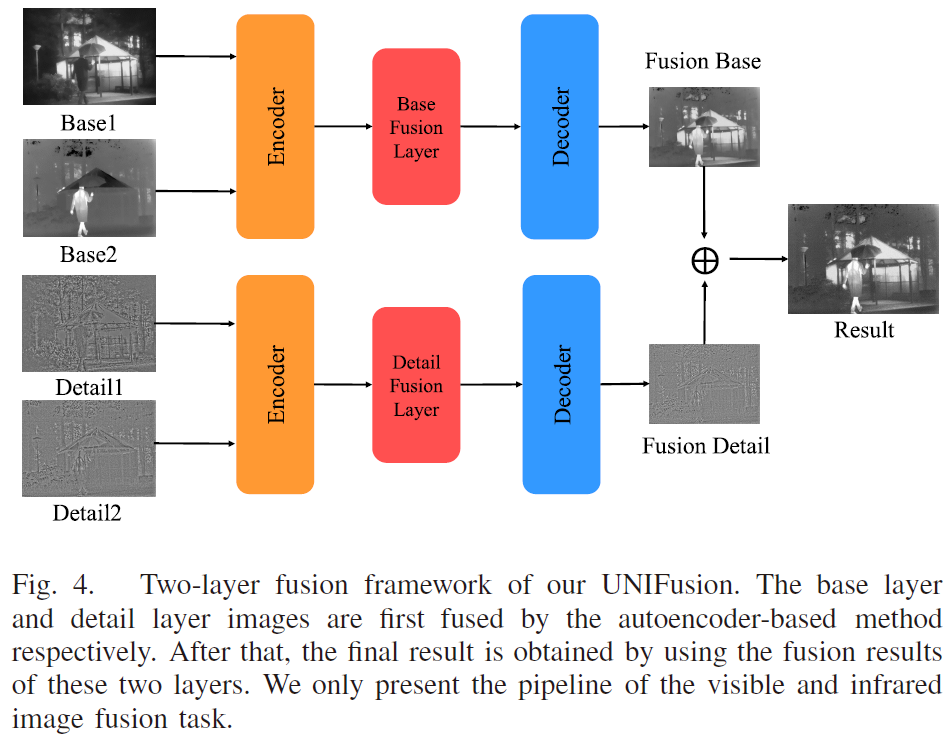
首先是将源图像转换成了base层和detail层,这里的分解是通过TPAMI的一篇互引导滤波的方法实现的。base层更多保留的是除去纹理材质之后的主体成分。而Detai层就是纹理材质啦。
代码中后续会知道,这里的Detai层,作者把它加上了base层的均值做了一个调制。然后就能够把Detail层也当成是普通的图像进行操作了。
其实蛮多方法也都有这样的操作,在这篇文章投稿前TCSVT上就有看到一个针对红外和可见光图像的融合论文了。但是本文作者提出的是一个通用的模型。
分解为Base和Detail层之后,就可以针对这两个层级的信息分别用不同的融合策略进行融合了。相当于是实现了图像的解纠缠过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号