ELFK+Kafka+Zookeeper企业级日志架构
文章目录
ELFK+Kafka+Zookeeper企业级日志架构
1.了解
生产初期,Service服务较少,访问量较少,使用ELFK集群就可以满足生产需求。但随着业务量的不断增加,日志量成倍增长,针对此情况,需要对ELFK增加消息队列,以减轻前端ES集群的压力。
附:日志告警收集文档
1)前言
目前常用的日志解决方案为两种:ELK、EFK,前者因为Logstash的笨重,才有了EFK来代替ELK;虽说代替,却又不可能完全取代。
L和F请看下面的介绍,因为F不可完全代替L,所以可以相结合,都发挥自己的长处,故才有了ELFK这个新的解决方案;只用F来轻量采集,只用Logstash来分析、过滤,取长补短,如此都能发挥自己所长!
2)介绍
ELK 是 Elastic 公司提供的一套完整的日志收集以及展示的解决方案。
- Elasticsearch:是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能
- Logstash:是一个用来搜集、分析、过滤日志的工具(过滤强大,耗内存)
- Filebeat:轻量级采集、处理日志组件,Logstash的替代品(无过滤功能)
- Kibana:是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据
由于 Logstash 在数据收集上并不出色,强项是过滤日志,而且作为 Agent,其性能并不达标。基于此,Elastic 发布了 beats 系列轻量级采集组件,即EFK中的F,只是Logstash强大的过滤功能还是不可替代的,不过一般的场景Filebeat也够用了!
3)采集插件
采集插件可代替Logstash,规避了Logstash的缺点,目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Heartbeat:运行时间监控(收集系统运行时的数据)
2.应用场景与方案
1)普通场景
相对于普通场景,参考下图的架构图来看,用EFK就够用了:Filebeat、Elasticsearch、Kibana
1、每台部署服务的服务器上装一个Filebeat组件服务,来采集服务日志;
2、Filebeat将采集的日志传送给Logstash或Elasticsearch(若要求较高需做日志过滤清洗,则在某节点安装Logstash);
3、Elasticsearch将处理后的日志发送给Kibana进行展示。
-
中小型企业日志架构图
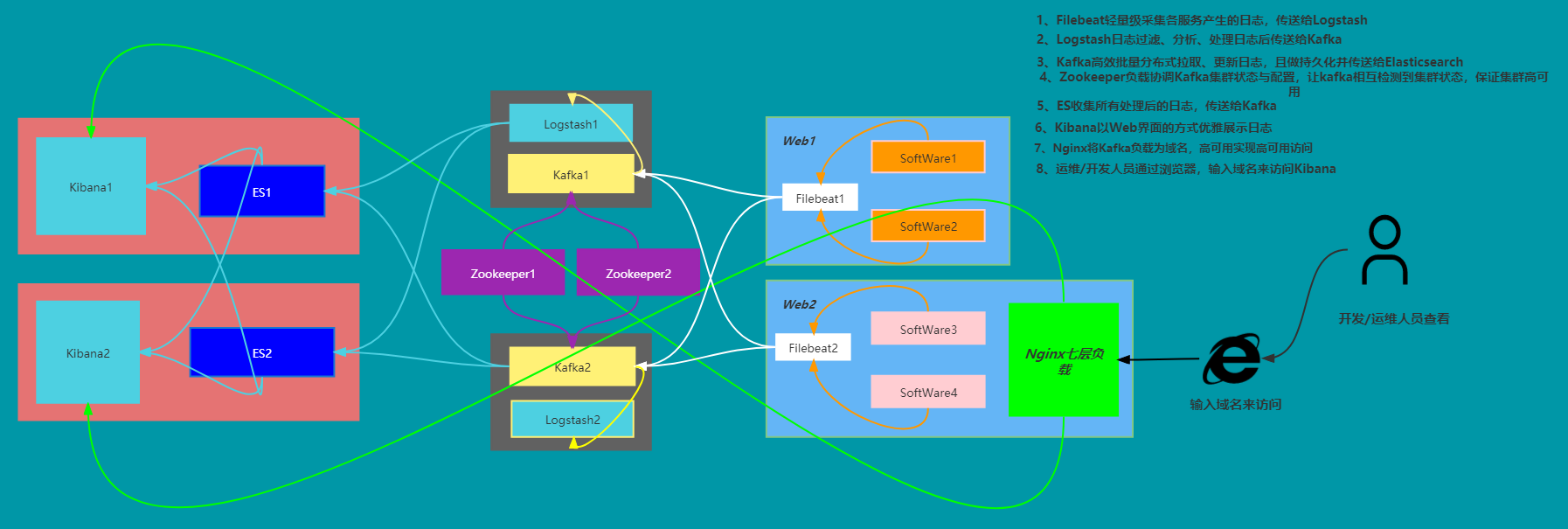
2)大型场景
PS:Logstash与Kafka
若应用比较多,所以如果所有的日志采集都直接连kafka的话,对kafka来说的压力太大,所以我们在中间接了一层logstash用来减少连接kafka的线程数,并且在logstash层我们配置了两台logstash,用来容灾;在其中一台挂掉的情况下,短时间内不影响日志采集。
PS:kafka 中 zookeeper 具体是做什么的?
参考:zookeeper在kafka中的作用
Kafka:数据缓冲队列,可批量拉取、更新日志,作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃;Kafka本身不具备多节点自动感知,故需zookeeper来协调管理。
Zookeeper:协调管理Kafka日志队列最终推送给Logstash集群处理,并帮助Kafka协调管理零散配置、实现Kafka集群高可用负载。
PS:此处Kafka与Logstash位置调换,为减轻Kafka收集日志的压力(也可以不调换)
- 日志流向

- 大型企业ELFK日志解决方案架构图

相对于大型场景,企业可能要求比较高,比如日志需标准化,分析过滤的很细致,保持日志服务架构处于高可用:
1、每台部署服务的服务器上装一个Filebeat组件服务,将采集的日志输出到Logstash;
2、Logstash将收取的日志过滤并处理,输出到Kafka;
3、Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志;
4、Zookeeper负责Kafka的负载与配置选举,保证Kafka高可用性(Kafka本身不具备多节点自动感知);
5、Kafka将生产者(Logstash)收集的日志发送给消费者(Elasticsearch);
6、Elasticsearch收集所有处理后的日志,并发送给Kibana集群;
7、Kibana将汇总处理好的日志以web页面展示;
7、我们可以通过Nginx来负载Kibana,实现高可用,进而访问Kibana集群的web页面,查看日志。
-
大型企业日志架构图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JQ9jSNiJ-1635481440510)(https://i.loli.net/2021/10/26/wPkUbBCK1OaMJhY.png)]
3.服务安装规划
这些服务应该分别装在哪台机器?
1)资金充足
1、所需收集日志的机器,必须安装Filebeat组件或其他日志采集工具;
2、其余服务单独给出一台服务器。
2)合理节省
1、所需收集日志的机器,必须安装Filebeat组件或其他日志采集工具;
2、Zookeeper+Elasticsearch;
3、Kafka+Logstash;
4、Kibana+Web;
5、Nginx+Web,但最好不与Kibana在同一台,这样负载就意义不大了。
3.企业级ELFK日志架构搭建
这里选择【合理节省】的搭建方案做案例,参考中小型企业日志架构图,并全部采用Docker的方式来搭建部署
- 准备机器与环境
| Host Name | IP | Mem/CPU/Disk | Server | Kernel Version | System Version |
|---|---|---|---|---|---|
| web1 | 172.23.0.235 | 4G/4U/40G | Docker、Log_Server、Nginx(access.log/error.log) | 3.10.0-1160.el7.x86_64 | 7.9.2009 (Core) |
| web2 | 172.23.0.236 | 4G/4U/40G | Docker、Nginx(负载kibana) | 3.10.0-1160.el7.x86_64 | 7.9.2009 (Core) |
| logstash1_zoo1_kafka1 | 172.23.0.237 | 4G/4U/40G | Docker、Logstash、Zookeeper、Kafka | 3.10.0-1160.el7.x86_64 | 7.9.2009 (Core) |
| logstash2_zoo2_kafka2 | 172.23.0.238 | 4G/4U/40G | Docker、Logstash、Zookeeper、Kafka | 3.10.0-1160.el7.x86_64 | 7.9.2009 (Core) |
| es2_kibana1 | 172.23.0.239 | 4G/4U/40G | Docker、Elasticsearch、Kibana | 3.10.0-1160.el7.x86_64 | 7.9.2009 (Core) |
| es2_kibana2 | 172.23.0.240 | 4G/4U/40G | Docker、Elasticsearch、Kibana | 3.10.0-1160.el7.x86_64 | 7.9.2009 (Core) |
-
搭建流程:
- 根据环境介绍所需安装的Server进行对应安装搭建···
- 服务安装搭建完毕后,麻烦的就是配置而已,只要将各个服务对应连接起来,就可以了
-
搭建思路:
第一层:数据采集层
应用服务器上安装了filebeat做日志采集,同时把采集的日志分别发送给kafka服务。
第二层:数据处理层
zookeeper协调kafka将日志/数据进行持久化处理后,交由logstash进行过滤清洗;
Logstash节点会实时去kafka broker_topic拉数据,经过处理后输出到Elasticsearch。
第三层:数据转发、展示层
ES DataNode 会把收到的数据,写磁盘,建索引库;
ES Master + Kibana 主要 协调 ES集群,处理数据检索请求,数据展示。
准备环境
- 所有机器
1)安装Docker服务
-
参考:安装Docker
-
可直接复制粘贴执行,安装后启动Docker服务
2)安装JDK环境
- 安装JDK环境
- 参考:JDK官方下载
mkdir /root/packages
cd /root/packages && rz
[root@logstash_kafka1 packages]# ll -h
总用量 142112
-rw-r--r-- 1 root root 139M 9月 26 13:36 jdk-8u301-linux-x64.tar.gz
# 推送到logstash_kafka1、es_zoo_kibana机器,kafka与zookeeper需依赖JDK环境
[root@logstash_kafka1 ~]# for i in {37,38,39,40};do scp -r /root/packages 172.23.0.2$i:/root/;done
# 加压安装
tar xf /root/packages/jdk-8u301-linux-x64.tar.gz -C /usr/local/
# 目录结构
tree -L 1 /usr/local/jdk1.8.0_301/
├── bin
├── COPYRIGHT
├── include
├── javafx-src.zip
├── jmc.txt
├── jre
├── legal
├── lib
├── LICENSE
├── man
├── README.html
├── release
├── src.zip
├── THIRDPARTYLICENSEREADME-JAVAFX.txt
└── THIRDPARTYLICENSEREADME.txt
ES+Zoo+Kibana2-172.23.0.240
# 添加到环境变量
echo 'export PATH=$PATH:/usr/local/jdk1.8.0_301/bin' >> /etc/profile
source /etc/profile
3)修复时区
echo "Asia/Shanghai" > /etc/timezone
4)搭建要求
1、web端配置输出Nginx访问日志(access.log)与错误日志(error.log)
2、通过一系列清洗及处理后,最终要展示在kibana界面,需创建索引:
- nginx-access
- nginx-error
3、最终实用域名 www.kibana.local 通过Nginx来访问两台kibana,实现负载均衡来查看日志
1.数据采集层
部署Nginx+Filebeat
Web端:
这里直接拿 /var/log/nginx/*.log 作为服务日志
若自己用Docker运行服务产生日志,则运行时需将宿主机自定义日志目录挂载到容器日志目录上,这样产生日志就可在宿主机采集到了
1)Nginx
运行nginx容器,将配置复制到宿主机,启动nginx时修改配置直接挂载即可!
mkdir /config/nginx -p
docker run -d \
--name nginx \
-p 80:80 \
-v /config/nginx:/etc/nginx \
-v /var/log/nginx:/var/log/nginx nginx:latest
docker cp nginx:/usr/lib/nginx /usr/lib/
docker cp nginx:/etc/nginx /config/nginx
1> 配置
-
nginx.conf
PS:所有web端可通用一个nginx配置文件,因ip不同,其余无碍
修改项:
1、加入错误日志文件路径:error_log
2、json日志格式定义:log_format
3、http访问日志日志:access_log
[root@web1 ~]# cat /config/nginx/nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log notice; # 加入错误日志 pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; # json日志格式定义 log_format main ''{"@timestamp":"$time_iso8601",'' ''"host": "$server_addr",'' ''"clientip": "$remote_addr",'' ''"size": $body_bytes_sent,'' ''"responsetime": $request_time,'' ''"upstreamtime": "$upstream_response_time",'' ''"upstreamhost": "$upstream_addr",'' ''"http_host": "$host",'' ''"url": "$uri",'' ''"xff": "$http_x_forwarded_for",'' ''"referer": "$http_referer",'' ''"agent": "$http_user_agent",'' ''"status": "$status"}''; access_log /var/log/nginx/access.log main; # http访问日志日志(默认) sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf; }
PS:若终端能curl到Nginx的内容,而浏览器却访问失败,则需要重启一下Docker服务,再将容器启动,即可访问成功!
原因:
docker服务启动时定义的自定义链DOCKER由于 centos7 firewall 被清掉,firewall的底层是使用iptables进行数据过滤,建立在iptables之上,这可能会与 Docker 产生冲突; 当 firewalld 启动或者重启的时候,将会从 iptables 中移除 DOCKER 的规则,从而影响了 Docker 的正常工作;
当你使用的是 Systemd 的时候, firewalld 会在 Docker 之前启动,但是如果你在 Docker 启动之后再启动 或者重启 firewalld ,你就需要重启 Docker 进程了。
重启docker服务及可重新生成自定义链DOCKER
2> 启动
-
启动nginx
docker run -d \ --name nginx \ -p 80:80 \ -v /config/nginx:/etc/nginx \ -v /var/log/nginx:/var/log/nginx \ nginx:latest
2)Filebeat
PS:
因Nginx产生的日志为.log文件,所以采用Filebeat,其他类型可参考上面介绍
新建容器配置文件目录,运行时挂载
注:
因只需替换filebeat.yml,所以直接挂载此文件到容器来启动(官方也支持此配置目录【/usr/share/filebeat】被挂载,可能含有其他配置内容
- 对每一台机器上都装一个filebeat,然后都指向同一个logstash,这时不同的filebeat传输的数据过来,需要输出到不同的索引,
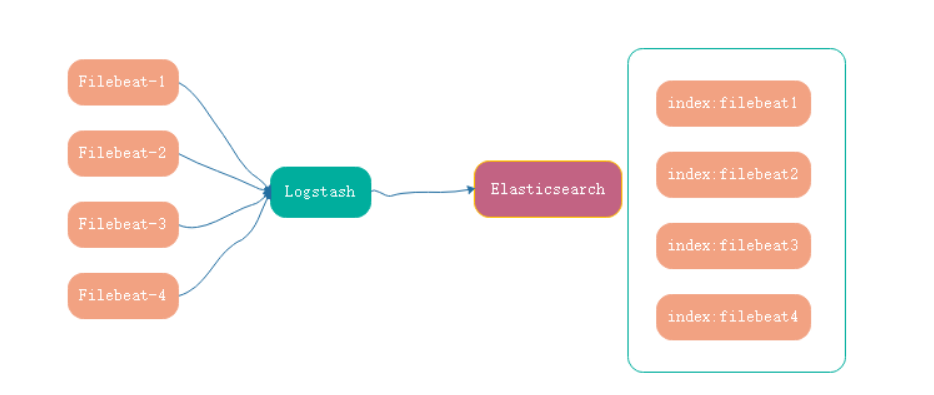
1> 配置
-
filebeat.yml
-
关闭其他output输出项,只开启output.logstash(也可开启多个输出项,没必要)
-
支持多索引模式定义【filebeat的input与logstash的output都要配置对应的type】
mkdir /config/filebeat # 宿主机创建配置文件挂载目录# 配置文件 cat > /config/filebeat/filebeat.yml <<EOF ################### 多索引配置 ################### filebeat.inputs: - type: log paths: - /var/log/nginx/access.log fields: topic: "nginx_access" # 这一行的key:value都可以自己定义 # fields_under_root: true - type: log enabled: true paths: - /var/log/nginx/error.log fields: topic: "nginx_error" output.kafka: enabled: true #fields_under_root: true hosts: ["172.23.0.237:9092","172.23.0.238:9092"] topic: "%{[fields.topic]}" ################### 默认单索引配置 ################### #filebeat.inputs: #- type: log # enabled: true # paths: # # 需要收集的日志所在的位置,可使用通配符进行配置 # - /var/log/nginx/*.log # #output.logstash: # hosts: # - 172.23.0.237:5044 # - 172.23.0.238:5044 ##日志输出配置(采用 logstash 收集日志,5044为logstash端口) #output.kafka: # hosts: # - 172.23.0.237:9092 # - 172.23.0.238:9092 EOF
2> 启动
-
运行容器
-
【-v /var/log/nginx:/var/log/nginx】:日志收集目录
docker run -d \ --restart=always \ --name=filebeat \ -v /var/log/nginx:/var/log/nginx \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \ docker.elastic.co/beats/filebeat:7.15.0
2.数据处理层
部署Logstash+Zookeeper+Kafka
思路:
1、先部署启动Zookeeper,Kafka集群本身不具备相互感知,需依赖Zookeeper来协调管理;
2、Kafka部署后,配置去找Zookeeper,进行建立连接(若先启动Kafka,则报错【zookeeper没有配置安全监听器!】);
3、kafka是为了减轻Logstash的压力并持久化,提前筛选过滤日志,再输出给Logstash进行清洗。
PS:
因做了kafka高可用,kafka启动时需指定zookeeper的ip,所以需依赖zookeeper启动后才能正确启动!
1)Zookeeper
1> 配置
-
准备配置文件挂载目录
mkdir /config/zoo1/{config,data,datalog} # zoo1节点 mkdir /config/zoo2/{config,data,datalog} # zoo2节点 docker network create zoo # 所有节点 -
配置文件
1、zoo.cfg:除server地址顺序外,其余配置多节点相同
2、若是在同一台机器部署zookeeper高可用,则需要更改clientPort,避免端口冲突
3、四字命令:zk可以通过它自身提供的简写命令来和服务器进行交互,交互之后可以提供一些服务器的状态信息、环境变量、包括一些临时会话(session)等等,四字命名非常适合运维去监控,需要使用到nc命令,安装:yum install nc
注意:server.1与server.2配置注意,本机需写为0.0.0.0,其他server写对应主机ip,若本机也写为自身ip,则会报错拒绝连接/无法选举等错误!
- zoo1.cfg
dataDir=/data dataLogDir=/datalog tickTime=2000 initLimit=5 syncLimit=2 autopurge.snapRetainCount=3 autopurge.purgeInterval=0 maxClientCnxns=60 standaloneEnabled=true admin.enableServer=true server.1=0.0.0.0:2888:3888;2181 server.2=172.23.0.238:2888:3888;2181 #开启四字命令 4lw.commands.whitelist=*- zoo2.cfg
dataDir=/data dataLogDir=/datalog tickTime=2000 initLimit=5 syncLimit=2 autopurge.snapRetainCount=3 autopurge.purgeInterval=0 maxClientCnxns=60 standaloneEnabled=true admin.enableServer=true server.1=172.23.0.237:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 #开启四字命令 4lw.commands.whitelist=*
2> 启动
-
zoo1
docker run -d \ --restart always \ --name zoo1 \ --net zoo \ -p 2181:2181 \ -p 2888:2888 \ -p 3888:3888 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/zoo1/data:/data \ -v /config/zoo1/datalog:/datalog \ -v /config/zoo1/config/zoo1.cfg:/conf/zoo.cfg \ zookeeper:latest -
zoo2
docker run -d \ --restart always \ --name zoo2 \ --net zoo \ -p 2181:2181 \ -p 2888:2888 \ -p 3888:3888 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/zoo2/data:/data \ -v /config/zoo2/datalog:/datalog \ -v /config/zoo2/config/zoo1.cfg:/conf/zoo.cfg \ zookeeper:latest
3> 检测集群状态
[root@logstash1_zoo1_kafka1 ~]# docker exec -it zoo1 bash
root@f709aa033aab:/apache-zookeeper-3.7.0-bin# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower # 成功
[root@logstash2_zoo2_kafka2 ~]# docker exec -it zoo2 bash
root@b840e2285f45:/apache-zookeeper-3.7.0-bin# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader # 成功
4> 强制删除topic
针对于kafka节点无法成功删除topic(可能是正在写入内容的topic),可用此方法删除
-
登录到某一台zookeeper节点操作即可
[root@logstash1_zoo1_kafka1 ~]# docker exec -it zoo1 bash root@e6417d1103f3:/apache-zookeeper-3.7.0-bin# zkCli.sh -server localhost [zk: localhost(CONNECTED) 23] ls /brokers/topics [__consumer_offsets, nginx_ac, nginx_er, nginx-access1] [zk: localhost(CONNECTED) 23] delete /brokers/topics/nginx-access1 [zk: localhost(CONNECTED) 23] ls /brokers/topics [__consumer_offsets, nginx_ac, nginx_er]
2) Kafka
参考下述kafka配置文件,每台机器broker.id不能相同,其余可一致
注:请勿将Kafka配置文件挂载到容器内,需要配置在创建容器时指定即可,其他配置到容器内进行修改,否则启动失败【提示:无权修改】
PS:创建容器时使用 -e 选项注入配置,会自动加载到配置文件内
1> 配置
-
宿主机创建容器服务持久化目录
mkdir /config/{logstash1,kafka1} -p # 节点1 mkdir /config/{logstash2,kafka2} -p # 节点2 -
Kafka配置文件参考(已将无用部分清除)
启动容器时注入参数:
-e ALLOW_PLAINTEXT_LISTENER=yes
-e KAFKA_BROKER_ID=1
-e KAFKA_ZOOKEEPER_CONNECT=ip1:2181,ip2:2181
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka自身ip:9092
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \PS:kafka节点2的配置:只是【advertised.listeners=PLAINTEXT】不同,为主机自身ip
[root@logstash1_zoo1_kafka1 ~]# docker exec -it kafka1 bash I have no name!@logstash1_zoo1_kafka1:/$ cat /opt/bitnami/kafka/config/server.properties ################## 主要配置 ################## #broker的全局唯一编号,不能重复 broker.id=1 # 用来监听链接的端口,producer或consumer将在此端口建立连接 listeners=PLAINTEXT://0.0.0.0:9092 # 本机IP,如果不改为本机ip,则客户端会抛出【Producer connection to localhost:9092 unsuccessful 错误!】 advertised.listeners=PLAINTEXT://172.23.0.237:9092 # zookeeper集群的IP地址 zookeeper.connect=172.23.0.239:2181,172.23.0.240:2181 # 接收消息的最大字节数,应该比消费端的fetch.message.max.bytes更小才对,否则broker就会因为消费端无法使用这个消息而挂起(默认:1000000) message.max.byte=5242880 # topic主题副本数,一个主题宕机时保证高可用 default.replication.factor=2 replica.fetch.max.bytes=5242880 # kafka日志 logs.dirs=/opt/bitnami/kafka/logs ################## 其余保持默认 ################## num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connection.timeout.ms=18000 group.initial.rebalance.delay.ms=0 auto.create.topics.enable=true max.partition.fetch.bytes=1048576 max.request.size=1048576 sasl.enabled.mechanisms=PLAIN,SCRAM-SHA-256,SCRAM-SHA-512 sasl.mechanism.inter.broker.protocol= -
开启IPV4转发功能
vim /etc/sysctl.conf #开启IPv4转发功能 net.ipv4.ip_forward=1 #重启服务,让配置生效 systemctl restart network, #执行后若提示=1,则表示成功 sysctl net.ipv4.ip_forward
2> 启动
PS:将Kafka日志目录挂载出来之后,并未显示产生的服务日志,容器内却可见,原因未知
-
Kafka1
docker run -d \ --restart=always \ --name=kafka1 \ --net=host \ -p 9092:9092 \ -e ALLOW_PLAINTEXT_LISTENER=yes \ -e KAFKA_BROKER_ID=1 \ -e KAFKA_ZOOKEEPER_CONNECT=172.23.0.237:2181,172.23.0.238:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.23.0.237:9092 \ -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /opt/bitnami/kafka/logs:/config/kafka1/logs \ bitnami/kafka:latest -
Kafka2
docker run -d \ --restart=always \ --name=kafka2 \ --net=host \ -p 9092:9092 \ -e ALLOW_PLAINTEXT_LISTENER=yes \ -e KAFKA_BROKER_ID=2 \ -e KAFKA_ZOOKEEPER_CONNECT=172.23.0.237:2181,172.23.0.238:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://172.23.0.238:9092 \ -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /opt/bitnami/kafka/logs:/config/kafka1/logs \ bitnami/kafka:latest
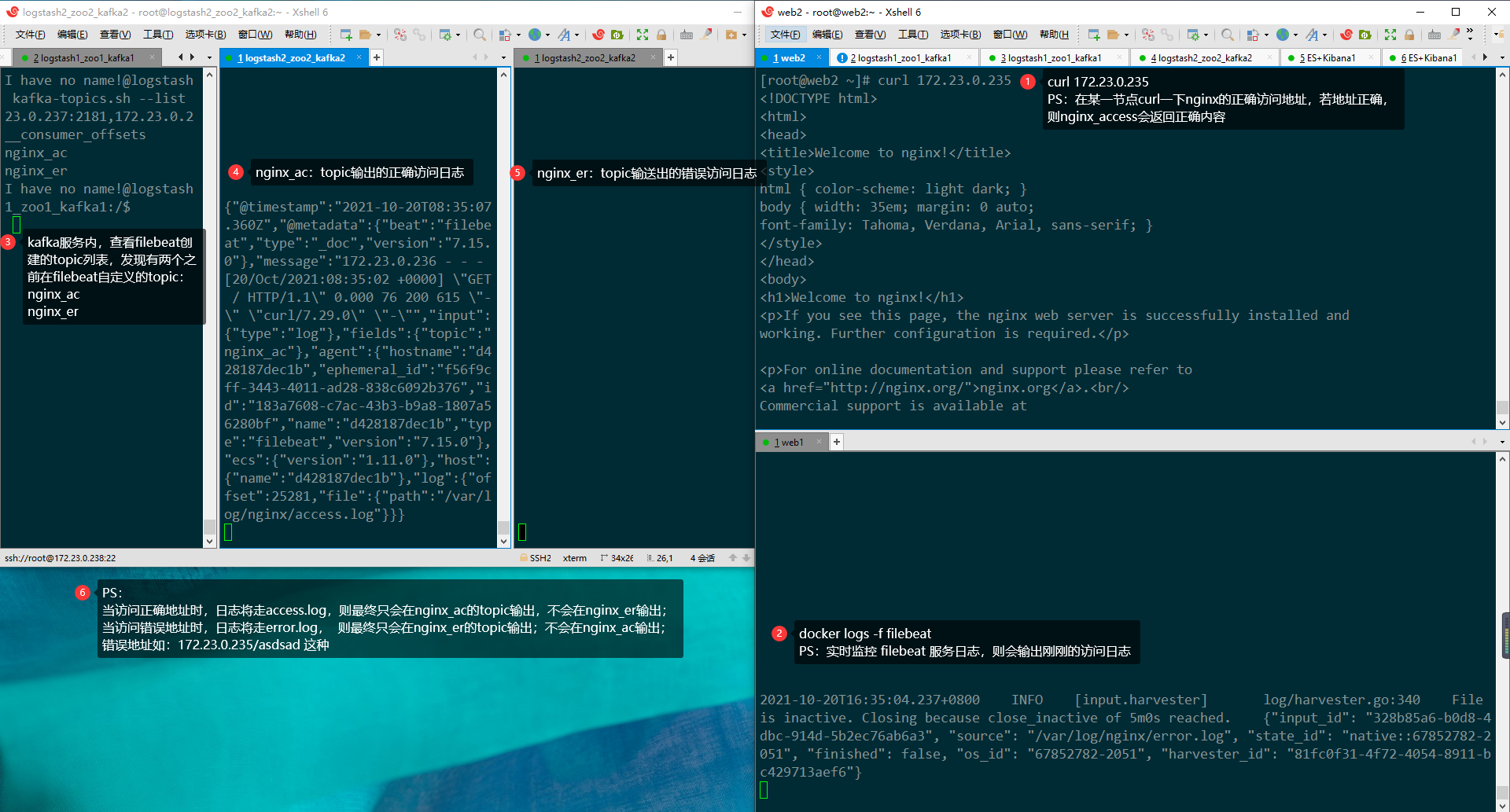
3>测试集群
若在kafka1创建一个topic主题并写入内容,kafka2能收到,则证明kafka集群部署成功!
写入/消费消息时:
回车后ctrl+c保存并退出撰写控制台,broker-list随意指定一个kafka集群内存在的节点ip即可;
删除字符需按住crtl+删除键;
无论指定的哪个broker-list发送的消息,就可以收到同一topic内的所有消息;
1.创建topic
[root@logstash1_zoo1_kafka1 ~]# docker exec -it kafka1 bash
logstash1_zoo1_kafka1:/$ kafka-topics.sh --create --zookeeper 172.23.0.237:2181,172.23.0.238:2181 --topic test --partitions 2 --replication-factor 1
Created topic test.
2.查看topic列表
除了新建的test外,__consumer_offsets则是kafka自己创建的;
考虑到一个 kafka 生成环境中可能有很多 consumer 和 consumer group,如果这些 consumer 同时提交位移,则必将加重 consumer_offsets 的写入负载,因此 kafka 默认为该 topic 创建了50个分区,并且对每个 group.id 做哈希求模运算,从而将负载分散到不同的 consumer_offsets 分区上。
logstash1_zoo1_kafka1:/$ kafka-topics.sh --list --zookeeper 172.23.0.237:2181,172.23.0.238:2181
__consumer_offsets
test
3.写入消息内容
回车后ctrl+c即可保存并退出
格式:
kafka-console-producer.sh --broker-list zookeeper_ip:9092 --topic topic_name
# kafka1测试写入
logstash1_zoo1_kafka1:/$ kafka-console-producer.sh --broker-list 172.23.0.237:9092 --topic test
>I'm Kafka1
>^C
# kafka2测试写入
logstash2_zoo2_kafka2:/$ kafka-console-producer.sh --broker-list 172.23.0.237:9092 --topic test
>I'm Kafka2
>^C
4.消费/查看消息
格式:
kafka-console-consumer.sh --bootstrap-server zookeeper_ip:9092 --topic topic_name --from-beginning
# kafka1查看
logstash1_zoo1_kafka1:/$ kafka-console-consumer.sh --bootstrap-server=172.23.0.237:9092,172.23.0.238:9092 --topic test --from-beginning
I'm Kafka1
I'm Kafka2
# kafka2查看
logstash2_zoo2_kafka2:/$ kafka-console-consumer.sh --bootstrap-server=172.23.0.237:9092,172.23.0.238:9092 --topic test --from-beginning
I'm Kafka1
I'm Kafka2
5.删除topic
logstash2_zoo2_kafka2:/$ kafka-topics.sh --delete --zookeeper 172.23.0.237:2181 --topic test
Topic test is marked for deletion. # 主题测试被标记为删除
Note: This will have no impact if delete.topic.enable is not set to true. # enable没有设置为true,则没有影响
3)Logstash
input:
收取定义目录下的所有日志文件,如【/var/log/*.log】
output:
检测定义的log目录下所有日志文件内容,并输出到相关服务【如kafka、Elasticsearch等】;
参考:多索引模式配置
可定义多个索引模式:若日志内容含有nginx,可定义一个索引,若含有xxx,可再定义一个索引;还可同时输出到多个不同或相同的服务【如kafka、Elasticsearch等】,定义地址与端口即可。
PS:阅读完本章节,可先进行本地测试,进行本地输入与输出测试,无误后,再进行正常配置
1> 配置文件结构
-
创建挂载目录,将配置文件挂载到容器,将容器日志挂载出来
mkdir /config/logstash1 -p # 节点1 mkdir /config/logstash2 -p # 节点2 -
运行容器将配置文件copy出来
docker run -d \ --name=logstash \ -p 5044:5044 \ docker.elastic.co/logstash/logstash:7.15.0 docker cp logstash:/usr/share/logstash/config /config/logstash1/ docker cp logstash:/usr/share/logstash/pipeline /config/logstash1/ docker cp logstash:/usr/share/logstash/data /config/logstash1/ docker rm -f logstash # 查看配置文件结构,最终就是为了最下面的nginx访问和错误日志 [root@logstash1_zoo1_kafka1 ~]# tree /config/logstash1 /config/logstash1/ ├── config │ ├── jvm.options │ ├── log4j2.properties │ ├── logstash-sample.conf │ ├── logstash.yml │ ├── pipelines.yml │ └── startup.options ├── data │ ├── dead_letter_queue │ ├── queue │ └── uuid ├── logs └── pipeline └── nginx_access.conf └── nginx_error.conf -
配置文件介绍
config目录下: jvm.options # 程序运行参数,内存与堆栈等其他限制,一般设置这两项,其余默认【-Xms1g(总堆空间的初始大小)、-Xmx1g(总堆空间的最大大小】) log4j2.properties # 可以在控制台打印输出debug信息,方便项目调试,pipeline/下的测试文件里指定产生日志的目录配置就在此文件配置 logstash-sample.conf # logstash.conf的示例文件,放在此处与pipelins内都可,建议后者,专门用来放配置文件使用 pipelines.yml # 定义管道配置文件,比如在pipeline目录下的配置文件的执行路径,就要在此配置指定 startup.options # logstash运行相关参数,logstash启动用户、命令、pid等,无需修改,详细参考同下 logstash.yml # 主要用于控制logstash运行时的状态,一般只定义【path.data(日志产生的目录)】 # 详细参考:https://www.cnblogs.com/wangchengyi/p/12185884.html data目录下:默认生成的文件,勿动 pipeline目录下: logstash.conf # 需产生日志的主配置文件,可编辑多个【logstash_nginx.conf,logstash_es.conf】
2> 配置
-
/usr/share/logstash/pipeline/
-
管道具体配置文件
/usr/share/logstash/pipeline/logstash_nginx.conf
主要控制日志文件的输入输出,可新建多个文件【如logstash_nginx.conf,logstash_es.conf】,配个文件收发自己的日志
input接收端口指定好,filebeat配置输出到此ip+端口即可接收日志
关闭其他output,只开启kafka即可(若有需求可开启多个output)
支持多索引模式定义【filebeat的input与logstash的output都要配置对应的type】
1>> 修改资源占用
调整内存,只用于转发,降低资源消耗
[root@es1_kibana1 ~]# vim /config/logstash-send/config/jvm.options
-Xms256m
-Xmx256m
2>> 配置输入输出
-
/config/logstash1/config/logstash.yml
主要用于控制logstash运行时的状态
PS:
node.name: logstash1 # 节点1
node.name: logstash2 # 节点2# 节点名称,各节点不同 node.name: logstash1 # 日志文件目录配置,一会测试的日志文件将写到此目录下 path.logs: /usr/share/logstash/logs # 指标REST端点的绑定地址,用户指标收集,默认即可 http.host: 0.0.0.0 # 日志格式 json/plain log.format: json # 以下默认即可 # 验证配置文件及存在性 config.test_and_exit: false # 配置文件改变时是否自动加载 config.reload.automatic: false # 重新加载配置文件间隔 config.reload.interval: 60s # debug模式 开启后会打印解析后的配置文件 包括密码等信息 慎用 # 需要同时配置日志等级为debug config.debug: true log.level: debug
3>> 配置Nginx日志访问
两个重要的配置文件:
nginx_access.conf:Nginx访问日志
nginx_error.conf :Nginx错误日志
PS:
主输入与输出配置文件,所有节点配置相同
注意!!!bootstrap_servers的ip引号与其他配置不同,一个引号即可!
-
/config/logstash1/pipeline/nginx_access.conf
################### 多索引模式 ################### input { kafka { bootstrap_servers => ["172.23.0.237:9092,172.23.0.238:9092"] topics => "nginx_access" # 使用kafka传过来的topic,多topic方式:["nginx_access","nginx_error"] # topics_pattern => "logstash-.*" # 使用正则匹配topic,前缀加了个名字logstash-,后面为nginx的所有topic codec => 'json' } } ################### nginx_access过滤 ################### filter { ruby { init => "@kname =['http_x_forwarded_for','time_local','request','status','body_bytes_sent','request_body','content_length','http_referer','http_user_agent','http_cookie','remote_addr','hostname','upstream_addr','upstream_response_time','request_time']" code => " new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('|'))]) new_event.remove('@timestamp') event.append(new_event) " } if [request] { ruby { init => "@kname = ['method','uri','verb']" code => " new_event = LogStash::Event.new(Hash[@kname.zip(event.get('request').split(' '))]) new_event.remove('@timestamp') event.append(new_event) " } } if [uri] { ruby{ init => "@kname = ['url_path','url_args']" code => " new_event = LogStash::Event.new(Hash[@kname.zip(event.get('uri').split('?'))]) new_event.remove('@timestamp') event.append(new_event) " } } kv { prefix =>"url_" source =>"url_args" field_split =>"&" include_keys => ["uid","cip"] remove_field => ["url_args","uri","request"] } mutate { convert => [ "body_bytes_sent","integer", "content_length","integer", "upstream_response_time","float", "request_time","float" ] } date { match => [ "time_local","dd/MMM/yyyy:hh:mm:ss Z" ] locale => "en" } } ################### 输出到es ################### output { stdout { codec => rubydebug } elasticsearch { hosts => ["172.23.0.239:9200","172.23.0.240:9200"] index => "nginx-access-%{+YYYY-MM-dd}" #codec => json } } -
/config/logstash1/pipeline/nginx_error.conf
################### 多索引模式 ################### input { kafka { bootstrap_servers => ["172.23.0.237:9092,172.23.0.238:9092"] topics => "nginx_error" # 使用kafka传过来的topic,多topic方式:["nginx_access","nginx_error"] # topics_pattern => "logstash-.*" # 使用正则匹配topic codec => 'json' } } ################### nginx_error过滤 ################### filter { ruby { init => "@kname =['http_x_forwarded_for','time_local','request','status','body_bytes_sent','request_body','content_length','http_referer','http_user_agent','http_cookie','remote_addr','hostname','upstream_addr','upstream_response_time','request_time']" code => " new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('|'))]) new_event.remove('@timestamp') event.append(new_event) " } if [request] { ruby { init => "@kname = ['method','uri','verb']" code => " new_event = LogStash::Event.new(Hash[@kname.zip(event.get('request').split(' '))]) new_event.remove('@timestamp') event.append(new_event) " } } if [uri] { ruby{ init => "@kname = ['url_path','url_args']" code => " new_event = LogStash::Event.new(Hash[@kname.zip(event.get('uri').split('?'))]) new_event.remove('@timestamp') event.append(new_event) " } } kv { prefix =>"url_" source =>"url_args" field_split =>"&" include_keys => ["uid","cip"] remove_field => ["url_args","uri","request"] } mutate { convert => [ "body_bytes_sent","integer", "content_length","integer", "upstream_response_time","float", "request_time","float" ] } date { match => [ "time_local","dd/MMM/yyyy:hh:mm:ss Z" ] locale => "en" } } ################### 输出到es ################### output { stdout { codec => rubydebug } elasticsearch { hosts => ["172.23.0.239:9200","172.23.0.240:9200"] index => "nginx-error-%{+YYYY-MM-dd}" #codec => json } }
3> 启动
-
递归授权配置文件挂载目录,否则提示无权限
chmod -R 777 /config/logstash1 -
启动logstash1
docker run -d \ --name=logstash \ --restart=always \ -p 5044:5044 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/logstash1/config:/usr/share/logstash/config \ -v /config/logstash1/pipeline:/usr/share/logstash/pipeline \ docker.elastic.co/logstash/logstash:7.15.0 -
拉取配置文件
拉取logstash1配置,并修改【node.name】
scp -r /config/logstash1/* 172.23.0.238:/config/logstash2/ sed -i 's#logstash1#logstash2#g' /config/logstash2/config/logstash.yml -
启动logstash2
docker run -d \ --name=logstash \ --restart=always \ -p 5044:5044 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/logstash2/config:/usr/share/logstash/config \ -v /config/logstash2/pipeline:/usr/share/logstash/pipeline \ docker.elastic.co/logstash/logstash:7.15.0
4> 本地测试
测试输入与输出到屏幕是否正常,若正常,再进行正规的配置与启动
此处仅以logstash1节点为例,节点2同理,略~
1>> 配置
-
/config/logstash1/config/pipelines.yml
管道配置文件,测试logstash能否正常输入输出
PS:
这个文件是你定义管道的地方,你可以定义多个。
可参考:更多管道文档# 默认开启,生效pipeline目录下的所有.conf文件,推荐 - pipeline.id: main path.config: "/usr/share/logstash/pipeline" ####################### 以下为单独指定开启某个配置文件,一般为测试使用 ####################### #- pipeline.id: main # path.config: /usr/share/logstash/pipeline/test1.conf # #- pipeline.id: file2 # path.config: /usr/share/logstash/pipeline/test2.conf -
准备本地测试文件
test1.conf
test2.conf
-
/config/logstash1/pipeline/test1.conf
input { file{ path => "/usr/share/logstash/logs/test1.log" codec => json start_position => "beginning" } } output { stdout { codec => rubydebug } } -
/config/logstash1/pipeline/test2.conf
input { file{ path => "/usr/share/logstash/logs/test2.log" codec => json start_position => "beginning" } } output { stdout { codec => rubydebug } }
-
2>> 启动并测试
-
递归授权配置文件挂载目录,否则提示无权限
chmod -R 777 /config/logstash1 -
启动
docker run -d \ --name=logstash \ --restart=always \ -p 5044:5044 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/logstash1/config:/usr/share/logstash/config \ -v /config/logstash1/data:/usr/share/logstash/data \ -v /config/logstash1/logs:/usr/share/logstash/logs \ -v /config/logstash1/pipeline:/usr/share/logstash/pipeline \ docker.elastic.co/logstash/logstash:7.15.0 -
测试输入与输出
打开两个终端,终端1运行后实时监控日志,在终端2追加内容到文件的挂载目录,返回终端1查看
可直接测试多个配置文件,进行实时监控【如:test1.conf|test2.conf】
# echo内容分别到test1.conf、test2.conf,都可以成功从日志输出 [root@logstash1_zoo1_kafka1 ~]# echo 1111111111 >> /config/logstash1/logs/test1.log [root@logstash1_zoo1_kafka1 ~]# docker logs -f logstash ··· {"level":"ERROR","loggerName":"logstash.codecs.json","timeMillis":1634527784326,"thread":"[main]<file","logEvent":{"message":"JSON parse error, original data now in message field","message":"incompatible json object type=java.lang.Integer , only hash map or arrays are supported","exception":{"metaClass":{"metaClass":{"exception":"LogStash::Json::ParserError","data":"1111111111"}}}}} { "host" => "ed95aa01a6cb", "@timestamp" => 2021-10-18T03:29:44.334Z, "@version" => "1", "message" => "1111111111", "tags" => [ [0] "_jsonparsefailure" ], "path" => "/usr/share/logstash/logs/test1.log" } [root@logstash1_zoo1_kafka1 ~]# echo 1111111111 >> /config/logstash1/logs/test2.log {"level":"DEBUG","loggerName":"logstash.inputs.file","timeMillis":1634527799225,"thread":"[file2]<file","logEvent":{"message":"Received line","path":"/usr/share/logstash/logs/test2.log","text":"1111111111"}} {"level":"ERROR","loggerName":"logstash.codecs.json","timeMillis":1634527799233,"thread":"[file2]<file","logEvent":{"message":"JSON parse error, original data now in message field","message":"incompatible json object type=java.lang.Integer , only hash map or arrays are supported","exception":{"metaClass":{"metaClass":{"exception":"LogStash::Json::ParserError","data":"1111111111"}}}}} { "host" => "ed95aa01a6cb", "@timestamp" => 2021-10-18T03:29:59.235Z, "@version" => "1", "message" => "1111111111", "tags" => [ [0] "_jsonparsefailure" ], "path" => "/usr/share/logstash/logs/test2.log" }
4.数据转发、展示层
部署:Kibana+Elasticsearch
1)Elasticsearch
查看所有索引:curl -XGET 127.0.0.1:9200/_cat/indices
附rpm官方下载地址:wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.1-x86_64.rpm
1> 配置
-
/etc/hosts
添加解析
172.23.0.239 es-master1 172.23.0.240 es-node1 -
elasticsearch.yml(不同节点一般只是node.name不同,其余可相同)
其他节点直接拷贝即可,需修改如下两项配置:
node.name:节点名称
network.publish_host:节点IP
# 集群名称,所有节点务必相同 cluster.name: es-cluster # 每个节点的名字务必唯一 node.name: es-master1 # 开启表示该节点有参与选举主节点的资格,并不表示这个就是主节点 node.master: true #允许该节点存储数据(默认开启) node.data: true #注意一定要是路径后面加上/var/lib/elasticsearch/nodes,要不然无法加入集群 path.data: /usr/share/elasticsearch/data path.logs: /usr/share/elasticsearch/logs # 有内网IP的话可以配置只监听本机127.0.0.1的IP network.host: 0.0.0.0 # 设置对外服务的http端口,默认为9200 http.port: 9200 # 用于与群集其他节点通信(docker部署的es集群务必配置,否则就算添加hosts解析也无济于事) network.publish_host: 172.23.0.239 # 设置节点间交互的tcp端口,默认是9300 transport.tcp.port: 9300 # 开启跨域功能【elasticsearch-head管理插件检测集群状态需用此配置】 http.cors.enabled: true http.cors.allow-origin: "*" # 开启xpack认证机制 xpack.security.enabled: false # 设置集群中master节点的初始列表(所有节点的ip,端口默认9300,可不配,端口号若更改,上面http.port与此处都要改) # 可以通过这些节点来自动发现新加入集群的节点(所有节点相同) discovery.seed_hosts: ["172.23.0.239:9300","172.23.0.240:9300"] # 参与选举主节点的节点,务必与node.name的值完全匹配且至少有一个节点,不能为空或不配置 cluster.initial_master_nodes: ["node-1"] # 保证集群中的节点可以知道其它N个有master资格的节点,默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 1 # # 设置内存锁定 bootstrap.memory_lock: false # 这是在因为Centos6不支持SecComp,而ES5.2.0默认bootstrap.system_call_filter为true进行检测,所以导致检测失败 # 失败后直接导致ES不能启动,注意要在Memory下面 bootstrap.system_call_filter: false -
jvm.options(其余节点相同)
# 最大锁定内存 -Xms1g # 最大锁定内存 -Xmx1g # 若不修改文件,则在启动时指定环境变量:-e ES_JAVA_OPTS="-Xms256m -Xmx256m"
2> 启动
-
es-node1
docker run -d \ --restart always \ --name es \ --net elastic \ -p 9200:9200 \ -p 9300:9300 \ -e ES_JAVA_OPTS="-Xms256m -Xmx256m" \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/es1/config/jvm.options:/usr/share/elasticsearch/config/jvm.options \ -v /config/es1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /config/es1/data/:/usr/share/elasticsearch/data \ -v /config/es1/logs:/usr/share/elasticsearch/logs \ docker.elastic.co/elasticsearch/elasticsearch:7.15.0 -
es-node2(集群状态错误)
docker run -d \ --restart always \ --name es \ --net elastic \ -p 9200:9200 \ -p 9300:9300 \ -e ES_JAVA_OPTS="-Xms256m -Xmx256m" \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/es2/config/jvm.options:/usr/share/elasticsearch/config/jvm.options \ -v /config/es2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /config/es2/data/:/usr/share/elasticsearch/data \ -v /config/es2/logs:/usr/share/elasticsearch/logs \ docker.elastic.co/elasticsearch/elasticsearch:7.15.0
3> 检查集群状态
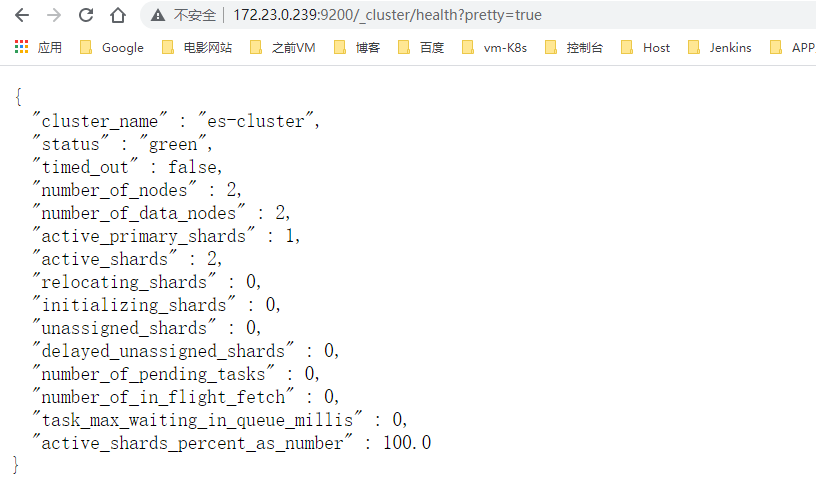
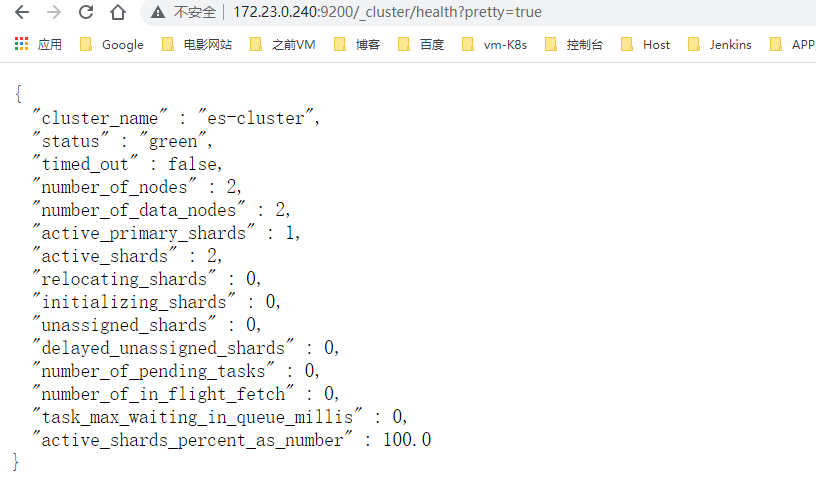
- 状态描述
各节点执行检查命令进行状态检查:三个状态:
"status" : "green"
最健康,所有的分片、副本分片都已分配,Elasticsearch集群是100% 可用的
"status" : "yellow"
亚健康,基本的分片可用,副本不可用(或无副本)
这种情况Elasticsearch集群所有的主分片已经分片了,但至少还有一个副本是缺失的;不会有数据丢失,所以搜索结果依然是完整的
如果更多的分片消失,就会丢数据了,可以把 yellow 想象成一个需要及时调查的警告
"status" : "red"
非健康,部分的分片可用,表明分片有一部分损坏。
一般情况下,表明存在 unassigned 的索引分片(shards:碎片,分片),此时执行查询部分数据仍然可以查到,还是赶快解决比较好;
这种情况Elasticsearch集群至少一个主分片(以及它的全部副本)都在缺失中。
这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
- 服务器查询状态
[root@es2_kibana2 ~]# curl http://172.23.0.239:9200/_cluster/health?pretty=true
{
"cluster_name" : "es-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1,
"active_shards" : 1,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
[root@es2_kibana2 ~]# curl http://172.23.0.240:9200/_cluster/health?pretty=true
{
"cluster_name" : "es-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 1,
"active_shards" : 1,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
4> 集群报错解决
ES报错解决参考:
ES的那些坑
PS:单节点启动参数:-e “discovery.type=single-node”
-
报错:No route to host
配置文件指定publish_host的ip (用于与群集其他节点通信,特别是已docker部署的es集群,不同服务器默认会以容器内部的ip来通信,所以会识别不了)
就算添加了hosts解析,也无济于事,所以需要配置
若节点状态不健康(yellow状态,则会在web页面若有若无)
network.publish_host: 本机IP -
报错:Error opening log file ‘logs/gc.log’: Permission denied
# 原因:配置文件、日志或其他目录权限不足,授权即可 # 解决:chmod 775 /config/es2/* [root@es2_kibana2 ~]# ll /config/es2 总用量 0 drwxrwxr-x 3 root root 229 10月 12 16:18 config drwxrwxr-x 3 root root 19 10月 11 19:07 data drwxrwxr-x 2 root root 207 10月 12 16:22 logs -
报错:memory locking requested for elasticsearch process but memory is not locked
原因:elasticsearch进程请求内存锁定,但内存未锁定,参考:解决方法
解决:关闭bootstrap.memory_lock:,会影响性能(有效)vim /etc/elasticsearch/elasticsearch.yml bootstrap.memory_lock: false # 报错内容:maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] # 原因:可能node是原先es被占用,导致启动异常 # 解决:清除原先的数据文件即可 rm -rf /config/es2/data/* docker restart es2 -
数据冲突导致
某些情况下,可能是启动集群之前启动过某节点,产生了节点信息数据,导致集群启东时报错
解决方式:清空Elasticsearch数据目录,重启集群即可(配置好所有节点后,尽量保证多节点同时启动)
docker stop es1 docker stop es2 rm -rf /config/es1/data/* rm -rf /config/es2/data/* docker restart es1 docker restart es2
5> 配置ES图形化
由于Elasticsearch-Head插件在5.x版本之后已不再维护,因此建议使用Cerebro访问
两种集群管理工具:
-
cerebro:是使用Scala、Play Framework、AngularJS和Bootstrap构建的开源的基于Elasticsearch Web可视化管理工具。您可以通过Cerebro对集群进行web可视化管理,如执行rest请求、修改Elasticsearch配置、监控实时的磁盘,集群负载,内存使用率等。
- 功能:
- 完全兼容开源Cerebro,适配最新0.8.4版本
- 支持Elasticsearch可视化实时负载监控
- 支持Elasticsearch可视化数据管理
- 使用参考:cerebro 使用教程
- 功能:
-
es-head:ES集群管理工具,相交互的Web前台,它是完全由html5编写的独立网页程序
- 功能:
- 它展现ES集群的拓扑结构,并且可以通过它来进行索引(Index)和节点(Node)级别的操作;
- 它提供一组针对集群的查询API,并将结果以json和表格形式返回;
- 它提供一些快捷菜单,用以展现集群的各种状态
- 使用参考:es-head 使用教程
- 功能:
1>> cerebro
cerebro(elasticsearch监控工具)
依赖于Java 环境:在功能上cerebro支持节点状态监控服务器cpu,load,索引数量大小 ,数据分布位置等监控。 支持查询
参考:部署cerebro
- 拉取镜像并启动
docker run -d \
--name cerebro \
-p 9000:9000 \
-v /etc/localtime:/etc/localtime \
lmenezes/cerebro:latest
-
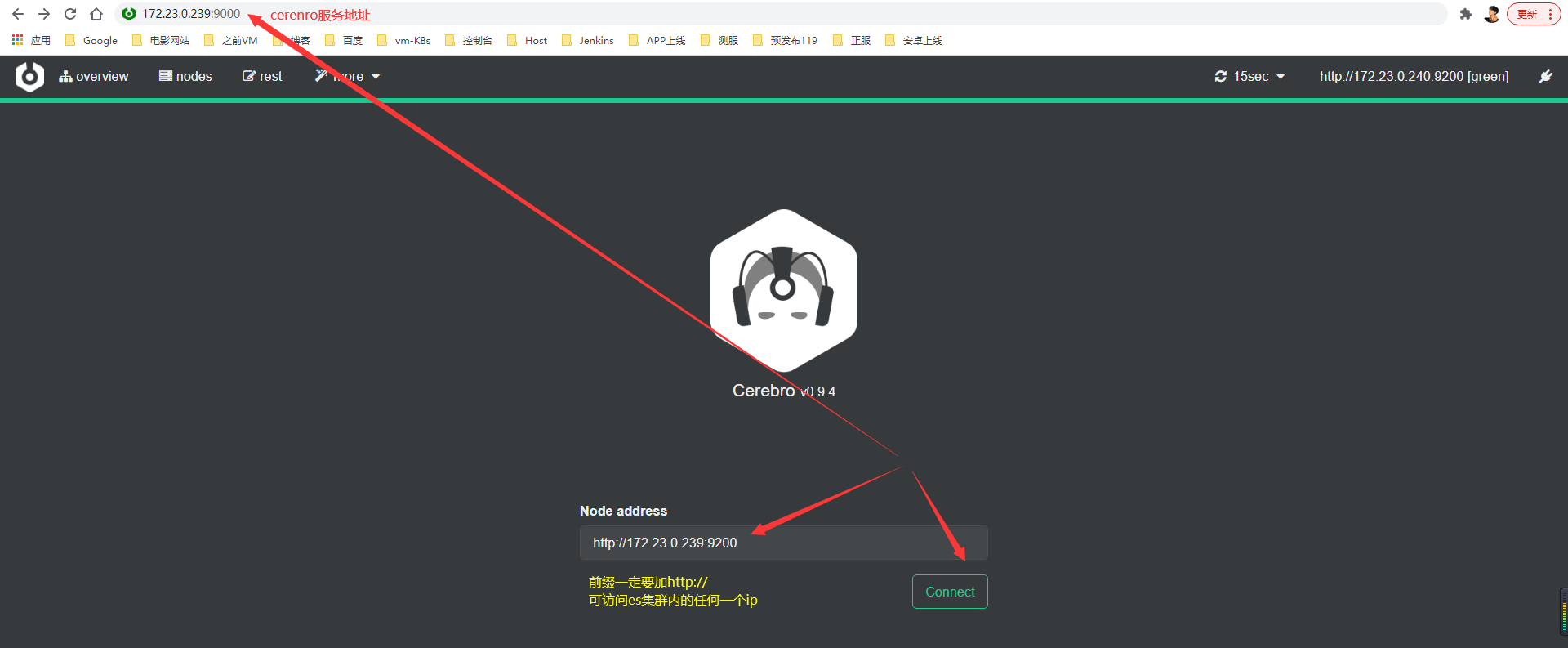
访问测试
-
访问:http://172.23.0.239:9000
-
查看节点信息(可管理节点)
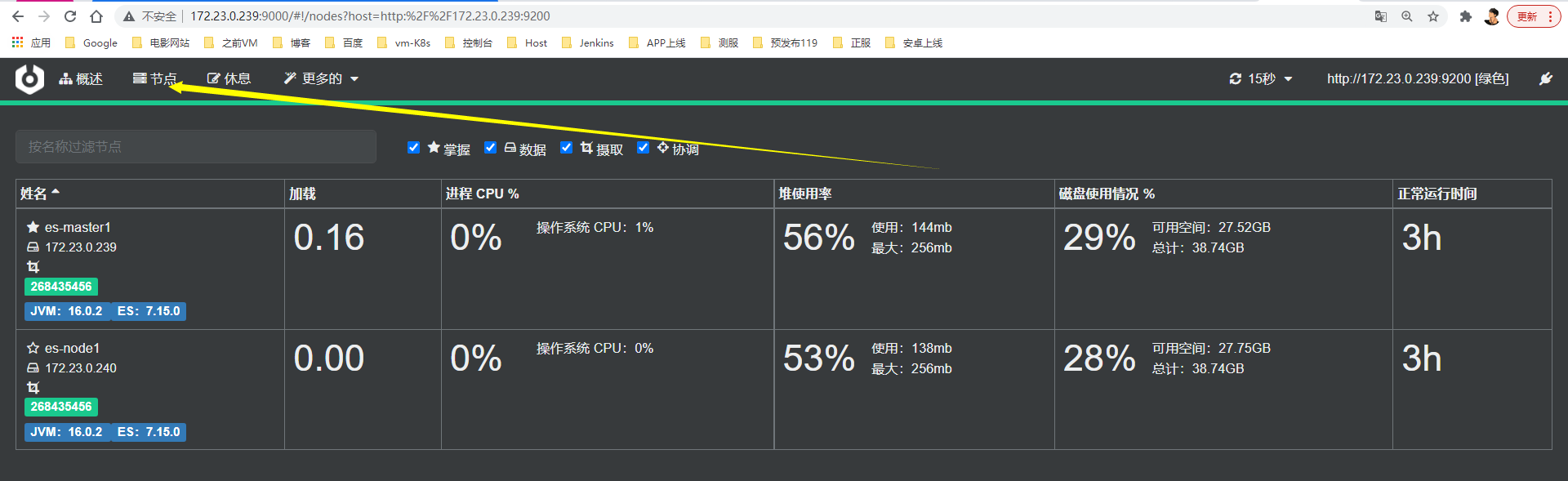
2>> es-head
1、单ES1节点安装即可,方便查看并管理集群状态、及索引列表,无需全节点安装
2、可通过图形界面访问了,添加主从后,可通过它来管理:172.23.0.239:9100
3、多节点部署及配置Elasticsearch,可参考:https://blog.csdn.net/qq_23995091/article/details/120410913#t9
4、status:green即为正常状态
- 启动
docker run -d \
--name es_cluster \
-p 9100:9100 \
alvinos/elasticsearch-head
-
访问
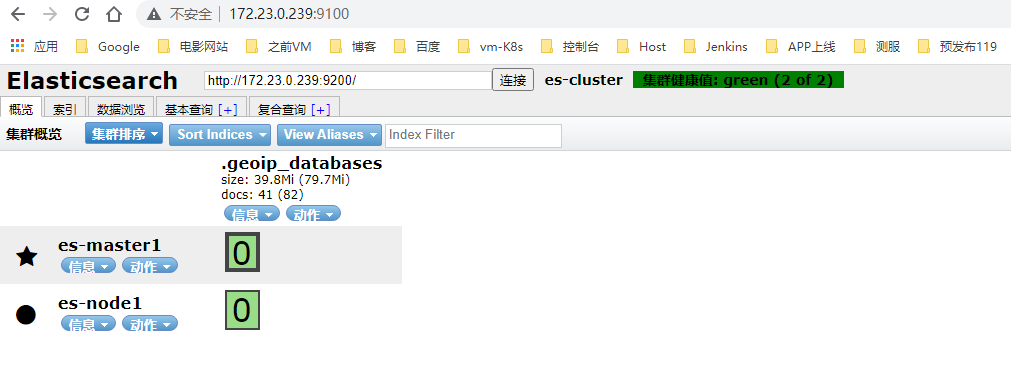
-
es-master1
-
http://172.23.0.239:9200/_cluster/health?pretty=true
-
-
es-node1
-
http://172.23.0.240:9200/_cluster/health?pretty=true
-
6> ES常用命令
-
查看集群健康
[root@es1_kibana1 ~]# curl http://localhost:9200/_cat/health?v epoch timestamp cluster status node.total node.data active_shards_percent 1636005449 05:57:29 es-cluster green 2 2 100.0% -
查看集群所有节点
[root@es1_kibana1 ~]# curl http://localhost:9200/_cat/nodes?v ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 172.23.0.239 66 96 1 0.07 0.11 0.10 cdfhilmrstw * es-master1 172.23.0.240 55 96 1 0.01 0.03 0.05 cdfhilmrstw - es-node1 -
查看索引
[root@es1_kibana1 ~]# curl http://localhost:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .kibana_7.15.0_001 u_15QkrbTViHbT9dJwyH2Q 1 1 75 15 4.7mb 2.3mb green open .kibana-event-log-7.15.0-000001 G272PvLNSpSkCSRAj3AooQ 1 1 4 0 36.3kb 18.1kb green open dynamic_mapping_test zOnAMjTrQXmYK9iN_ke1dg 1 1 1 0 6kb 3kb green open .apm-agent-configuration FCF1P7biRDab38FxNU6LwQ 1 1 0 0 416b 208b green open nginx-access-2021-10-26 670_iTT2Ss2Gxw9x1bXBYw 1 1 649 0 488.1kb 239.2kb green open nginx-access-2021-10-27 UBwUX7yEQvSnq8IvwzQG2Q 1 1 2 0 33kb 16.5kb green open .kibana_task_manager_7.15.0_001 Qa8EPhILQV-yY_k9o-GhLQ 1 1 15 89332 32.6mb 16.3mb green open users 61j44l33RbyZCSXopGa8Rw 1 1 1 1 26.6kb 13.3kb green open .tasks YppHQAXdQJmqsPvCAXKO2Q 1 1 5 0 56.4kb 22.2kb green open .geoip_databases MC_5M_hMSK-4Hm8b4ZtOSA 1 1 41 38 115.2mb 39.6mb green open .apm-custom-link uFY4XpyoSeKxocb1FGEbbQ 1 1 0 0 416b 208b green open peng lFEgg_-OTVm0gHrDp4lozg 3 0 0 0 624b 624b green open .async-search umFv-JlcSRe-W-JpJX5T0w 1 1 0 0 468b 234b green open nginx-error-2021-10-26 4k29FePrQ_qLVtLSOBQXUg 1 1 649 0 625.9kb 337.9kb green open nginx-error-2021-10-27 qZchuaNDRmSz6Plw8-uZFg 1 1 2 0 44.7kb 28.1kb green open elk-%{[@metadata][index]} Nkr-5Q3QRLKjpOU3yqYOog 1 1 621 0 552.7kb 270kb -
创建/获取索引
此处是在命令行执行,建议去kibana执行put操作, 参考:Elasticsearch索引详解
# 创建一个索引 curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d' { "name": "John Doe" } ' # 从customer索引中获取指定id的文档 [root@es1_kibana1 ~]# curl -X GET "localhost:9200/customer/_doc/1?pretty" { "_index" : "customer", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "name" : "John Doe" } }
2)Kibana
1> 配置
-
配置文件(多节点相同)
cat /config/kibana2/kibana.yml #----------kibana服务相关----------# server.host: "0" server.port: 5601 server.shutdownTimeout: "5s" monitoring.ui.container.elasticsearch.enabled: true #----------elasticsearch相关----------# elasticsearch.hosts: ["http://172.23.0.239:9200","http://172.23.0.240:9200"] xpack.monitoring.ui.container.elasticsearch.enabled: true
2> 启动
-
kibana-node1
-
访问kibana:172.23.0.239:5601
docker run -d \ --restart always \ --name kibana \ --net elastic \ -p 5601:5601 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/kibana1/kibana.yml:/usr/share/kibana/config/kibana.yml \ docker.elastic.co/kibana/kibana:7.15.0 -
kibana-node2
-
访问kibana:172.23.0.240:5601
docker run -d \ --restart always \ --name kibana \ --net elastic \ -p 5601:5601 \ -v /etc/localtime:/etc/localtime \ -v /etc/timezone:/etc/timezone \ -v /config/kibana2/kibana.yml:/usr/share/kibana/config/kibana.yml \ docker.elastic.co/kibana/kibana:7.15.0 -
设置与重置密码
Elasticsearch/kibana密码设置
设置密码参考:
https://blog.csdn.net/weixin_39305029/article/details/118606827?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-1.no_search_link&spm=1001.2101.3001.4242
重置密码参考:
https://blog.csdn.net/qq_35425070/article/details/106096987
3> 访问日志测试
区别:
处理前:原始日志内容紊乱、不全,不易查看
处理后:经过一系列处理后的日志,规则清晰,就像【变量名:变量值】,对应关系明确,易查询。
-
正确日志
浏览器访问:172.23.0.235 或终端输入:172.23.0.235-
原始终端界面访查看日志效果

-
Kibana查看展示效果
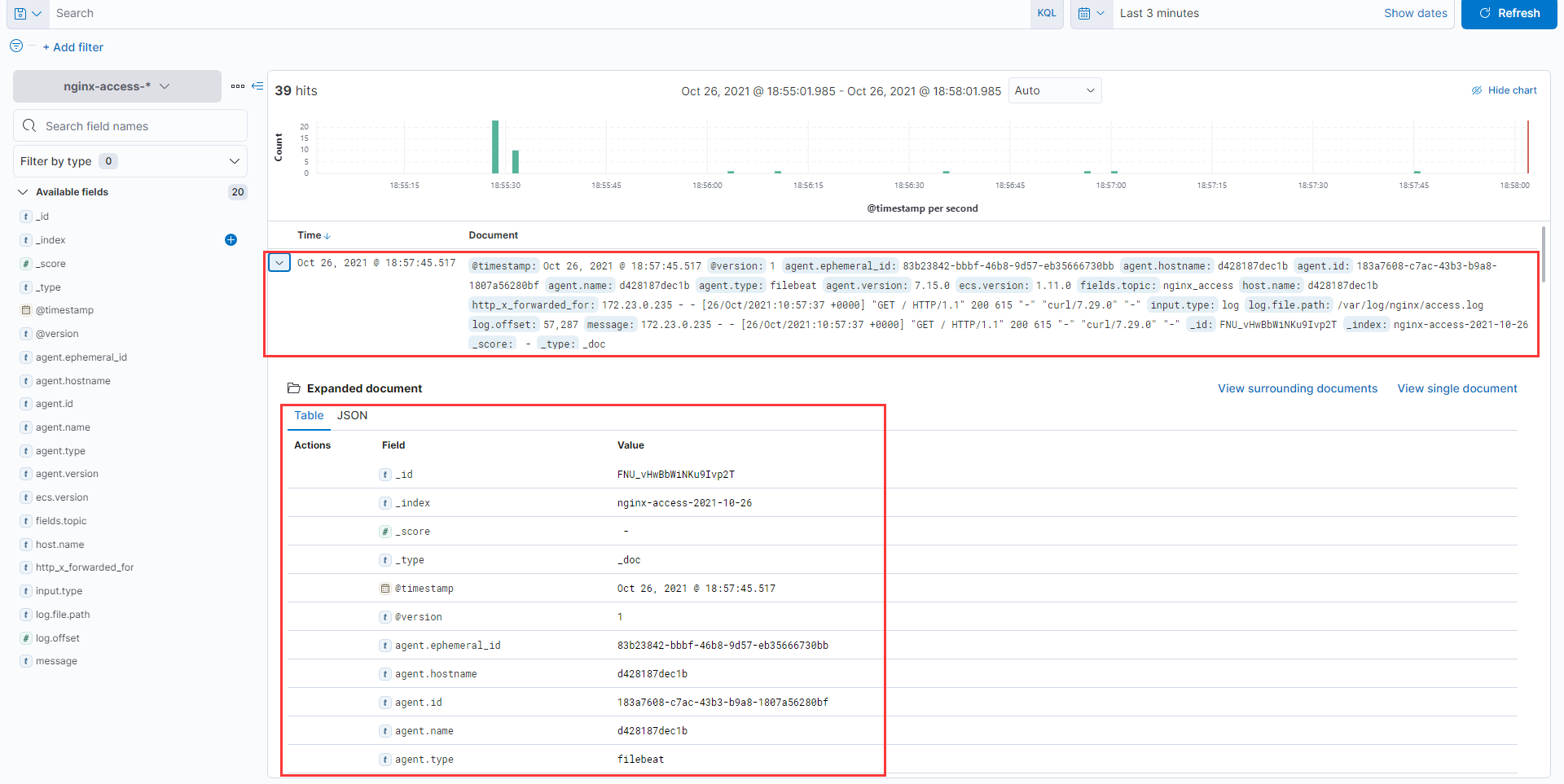
-
-
错误日志
浏览器访问:curl 172.23.0.235/我就是个错误日志························ 或终端输入:curl 172.23.0.235/我就是个错误日志························-
原始终端界面访查看日志效果
,

-
Kibana查看展示效果
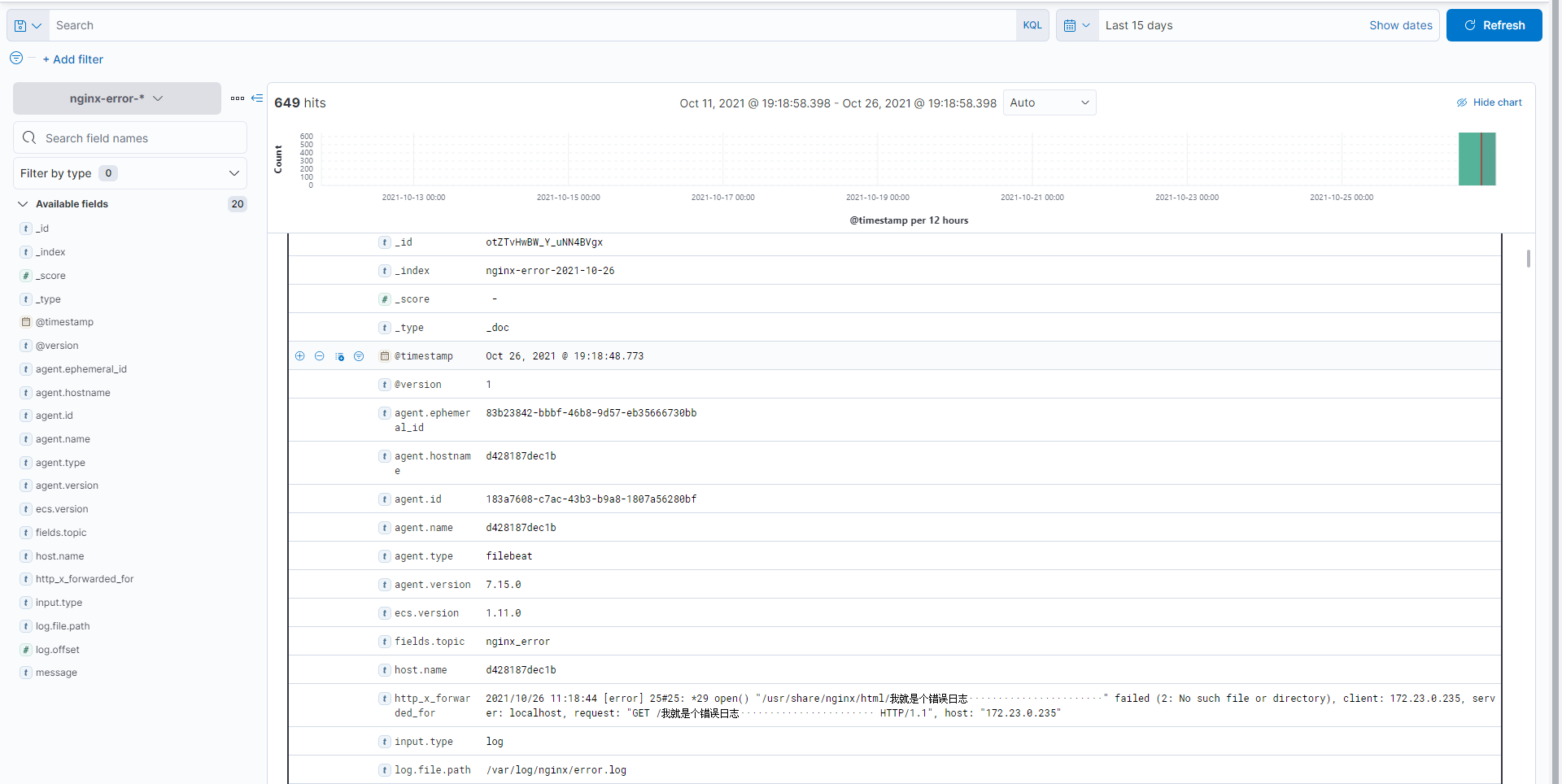
-
5.配置负载均衡
要求nginx装在web2上,则在web2上进行操作
1)配置nginx
1> 拉取web1上的nginx配置文件
scp -r 172.23.0.235:/config/nginx /config
rm -rf /config/nginx/conf.d/*
2> 编辑kibana配置文件
cat > /config/nginx/conf.d/kibana.conf <<EOF
upstream kibna {
ip_hash;
server 172.23.0.239:5601;
server 172.23.0.240:5601;
}
server {
listen 80;
server_name www.kibana.local;
location / {
proxy_pass http://kibana;
}
}
EOF
2) 启动Nginx
docker run -d \
--name nginx \
-p 80:80 \
-v /config/nginx:/etc/nginx \
-v /var/log/nginx:/var/log/nginx nginx:latest
3) 访问域名测试
Windows需添加hosts解析下域名:172.23.0.236 www.kibana.local
-
通过域名进入kibana
-
web1打入日志信息
[root@web1 ~]# curl localhost/我就是个域名··················我就是个域名··················我就是个域名··················我就是个域名·················· -
域名实时查看日志
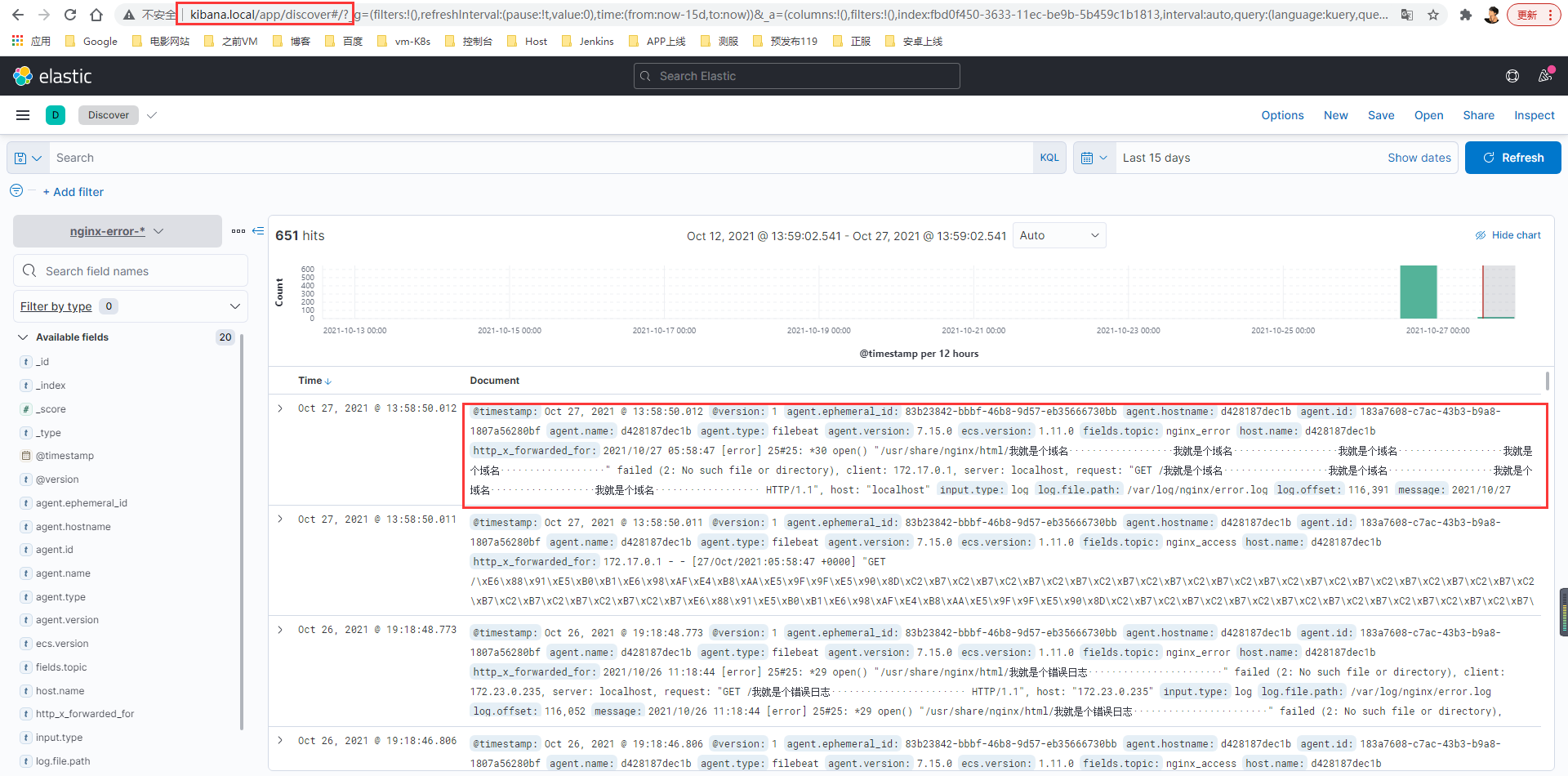

 浙公网安备 33010602011771号
浙公网安备 33010602011771号