Canal全家桶+MySQL+Elasticsearch+Kibana全量+增量收取数据
文章目录
Canal全家桶+MySQL+Elasticsearch+Kibana
引:
通过canal开源服务套件,实时获取MySQL-binlog日志数据,传输给Elasticsearch,并交由Kibana展示,主要用于做数据库索引。
本文将所有配置案例都写在了二进制部署方式内,其他部署方式配置请参考二进制部署的配置。
-
所需服务:
- Java:java环境【build 1.8.0_301-b09】(v1.8x)
- canal-server:canal服务端,注意:包名可能也叫deployer(v1.1.6)
- canal-adapter:canal适配器,适配与MySQL的es索引配置文件(v1.1.6)
- MySQL:数据库5.6(v5.x)
- Elasticsearch:收集数据(v6.8.6)
- Kibana:展示数据(v6.8.6)
-
PS:canal全家桶配置文件:此处只展示需修改的部分,其余保持默认即可~
-
此案例部署方式:
- 采用的单节点、二进制的部署方式,更多部署方式请参考目录【Docker方式、集群版】
- 主要是配置文件要对,docker版无非就是将配置文件覆盖挂载到容器,集群版则多节点配置文件相同即可~
二进制方式部署
1.准备环境
1)服务部署规划
| 主机名 | IP | 服务 | 用途 | 配置 |
|---|---|---|---|---|
| canal | 172.23.0.234 | canal-server|canal-adapter|canal-admin|MySQL | 拉取MySQL的binlog日志,传输给ES | Centos7|4G+40G |
| ES+Kibana | 172.23.0.239 | Elasticsearch|Kibana | 实时接受Canal服务传送的日志,并展示 | Centos7|4G+40G |
2)下载包
- 百度网盘所有包下载 提取码:peng
MySQL下载及安装:戳我~
3)创建服务父目录
解压不会自动创建canal-server父目录,需手工指定
mkdir /etc/canal/{server,adapter,admin}
4)配置服务快速启动别名
服务的重启、实施日志监控,都对应相关文件,指定一个别名即可一键直达~
[root@myslq ~]# cat ~/.bashrc
···
# canal-server
alias start-canal-server='/etc/canal/server/bin/startup.sh'
alias stop-canal-server='/etc/canal/server/bin/stop.sh'
alias restart-canal-server='/etc/canal/server/bin/restart.sh'
alias tailfserver='tailf /etc/canal/server/logs/canal/canal.log'
# canal-adapter
alias start-canal-adapter='/etc/canal/adapter/bin/startup.sh'
alias stop-canal-adapter='/etc/canal/adapter/bin/stop.sh'
alias restart-canal-adapter='/etc/canal/adapter/bin/restart.sh'
alias tailfadapter='tailf /etc/canal/adapter/logs/adapter/adapter.log'
[root@myslq ~]# source ~/.bashrc
5)数据库创建账号并授权
创建canal账号,并授权对应权限,用于读取binlog数据
GRANT SELECT, INSERT, REPLICATION SLAVE, REPLICATION CLIENT, SHOW VIEW ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
6)安装Java环境
tar xf jdk-8u301-linux-x64.tar.gz -C /usr/local/
echo 'export PATH=$PATH:/usr/local/jdk1.8.0_301/bin' >> /etc/profile
source /etc/profile
# 查看java版本
[root@myslq ~]# java -version
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)
2.Canal-server
配置参考:canal-server配置文件解释
1)解压
tar xf canal.deployer-1.1.6-SNAPSHOT.tar.gz -C /etc/canal/server
2)配置
具体配置与解释参考:戳我~
-
/etc/canal/server/conf/canal.properties
# table meta tsdb info # 此处需指定数据库用户与密码,用于获取binlog数据的用户,自行创建 canal.instance.tsdb.dbUsername = canal canal.instance.tsdb.dbPassword = canal # 若部署了kafka或mq等服务,则打开注释,并在此处指定ip+端口,多个节点以逗号分割篇【此处举例为kafka的端口】 #canal.mq.servers = 172.23.0.237:9092,172.23.0.238:9092 -
/etc/canal/server/conf/canal_local.properties
# 若部署了canal-admin,则在此指定ip+端口,默认是无注释的,开启也无妨 canal.admin.manager = 127.0.0.1:8089 canal.admin.port = 11110 # canal-admin服务的用户与密码,默认用户admin,web登录密码为123456,但此处的123456需填写被加密后的密文,在数据库方可查看 # 登录到数据库输入:select password(123456) 即可获取密文,需把星号去除:*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 canal.admin.user = admin canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 -
/etc/canal-server-1.1.6/conf/test/instance.properties
conf下有个example示例目录,我们cp一份,每几个索引相当于有自己的库目录,便于维护,最好以某个库起名,如:test
若需多个实例,则创建多个目录,并对应修改即可
[root@myslq ~]# cp /etc/canal/server/conf/example/ /etc/canal/server/conf/test [root@myslq ~]# vim /etc/canal-server-1.1.6/conf/canal_test/instance.properties # 只需即可改数据库地址 canal.instance.master.address=172.23.0.234:3306
3)启动
看到【running now …】即为启动成功!
[root@myslq ~]# start-canal-adapter
[root@myslq ~]# tailfserver
at com.alibaba.otter.canal.deployer.CanalLauncher.main(CanalLauncher.java:117) ~[canal.deployer-1.1.6-SNAPSHOT.jar:na]
Caused by: org.apache.kafka.common.config.ConfigException: No resolvable bootstrap urls given in bootstrap.servers
at org.apache.kafka.clients.ClientUtils.parseAndValidateAddresses(ClientUtils.java:66) ~[connector.kafka-1.1.6-SNAPSHOT-jar-with-dependencies.jar:na]
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:405) ~[connector.kafka-1.1.6-SNAPSHOT-jar-with-dependencies.jar:na]
... 4 common frames omitted
2021-11-10 16:30:49.075 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler
2021-11-10 16:30:49.094 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations
2021-11-10 16:30:49.100 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server.
2021-11-10 16:30:49.124 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[172.17.0.1(172.17.0.1):11111]
2021-11-10 16:30:49.848 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
3.Canal-adapter
1)解压
tar xf canal.adapter-1.1.6-SNAPSHOT.tar.gz -C /etc/canal/adapter
2)配置
-
/etc/canal/adapter/conf/application.yml
主配置文件,主要配置数据库、zookeeper、canal-server交互的ip+端口
启动ES之前需去除一下配置文件内的中文注释,否则启动失败!!!server: port: 8081 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 default-property-inclusion: non_null canal.conf: mode: tcp # 【tcp kafka rocketMQ rabbitMQ】 # 默认tcp即可,若有kafka或其他,则填入kafka或其他服务名 flatMessage: true zookeeperHosts: syncBatchSize: 1000 retries: 0 timeout: accessKey: secretKey: consumerProperties: # canal tcp consumer # 默认为127.0.0.1:11111,建议填写服务器内网ip,127有时会不识别! canal.tcp.server.host: 172.23.0.234:11111 # 若有集群,则需填写zookeeper服务的集群地址 #canal.tcp.zookeeper.hosts: 172.23.0.237:2181,172.23.0.238:2181 canal.tcp.batch.size: 500 canal.tcp.username: canal.tcp.password: srcDataSources: defaultDS: # 数据库地址,/peng代表某个数据库,会优先扫描这个库下的索引数据(速度更快一点),其他所有库也会扫描 # 只要binlog数据更新,则canal服务就会收取所有binlog数据,但es那边不会接收所有,只会接收有对应配置的索引数据 url: jdbc:mysql://172.23.0.234:3306/peng?useUnicode=true # 数据库用户与密码 username: canal password: canal # kafka示例:若部署了kafka,则在此处配置kafka的ip+端口,并打开相关注释 # kafka consumer #kafka.bootstrap.servers: 172.23.0.237:9092,172.23.0.238:9092 #kafka.enable.auto.commit: false #kafka.auto.commit.interval.ms: 1000 #kafka.auto.offset.reset: latest #kafka.request.timeout.ms: 40000 #kafka.session.timeout.ms: 30000 #kafka.isolation.level: read_committed #kafka.max.poll.records: 1000 # 此处是将数据输送到某个服务【es、kafka...】 canalAdapters: # 若输送到es,则填写对应实例名,就是刚才复制的canal-server示例目录【test】 # 若输送到kafka,则填写topic名称,多个可用都好分割 - instance: example,test # canal instance Name or mq topic name groups: - groupId: g1 outerAdapters: - name: logger # 此处为输送到es - name: es hosts: 172.23.0.239:9200 properties: mode: rest # mode: transport模式,hosts中的端口要用9300;用rest模式,hosts中的端口要用9200 security.auth: #security.auth: admin:12345 # 若设置了es密码,则在此处指定 cluster.name: # es集群名,单节点可不填 -
/etc/canal/adapter/conf/es6/test.yml
PS1:与ES对应的索引配置,ES根据此配置文件的字段来创建索引
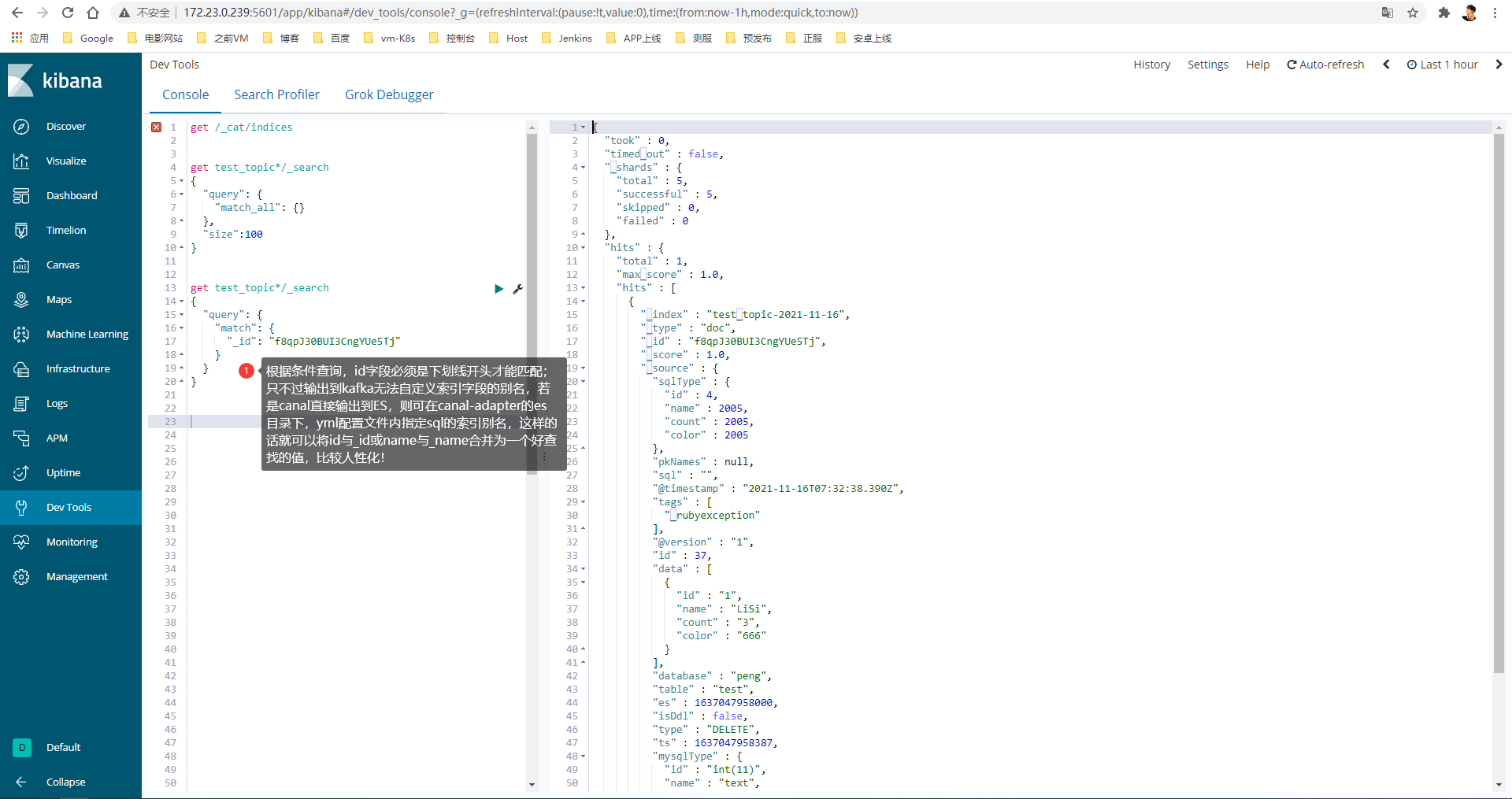
PS2:对应方式:【Kibana(ES) → Canal-adapter配置(test.yml) → MySQL(表字段)】,其实都是向MySQL的字段看齐,务必一致!
PS3:可以写:from test ti,ti为表的别名,当表名过长时可设一个别名,供上方sql调用
dataSourceKey: defaultDS destination: example # canal监控的实例名,应该与/etc/canal/server/conf/example目录名对应(即实例名) groupId: g1 esMapping: _index: test _type: _doc _id: _id sql: "select test.id, test.name, test.count, test.color from test" # 可以写:from test ti,ti为表的别名,当表名过长时可设一个别名,供上方sql调用 # etlCondition: "where t.c_time>={}" etlCondition: "where test.id >= {}" commitBatch: 3000
3)启动
最后出现【=> Subscribe destination: canal_test succeed <=】即为启动成功!
-
启动
[root@myslq ~]# start-canal-adapter -
验证启动
[root@myslq ~]# tailfadapter at com.alibaba.otter.canal.adapter.launcher.CanalAdapterApplication.main(CanalAdapterApplication.java:19) ~[client-adapter.launcher-1.1.6-SNAPSHOT.jar:na] 2021-11-11 15:44:59.967 [main] INFO c.alibaba.otter.canal.connector.core.spi.ExtensionLoader - extension classpath dir: /etc/canal/adapter/plugin 2021-11-11 15:44:59.982 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: example-g1 succeed 2021-11-11 15:44:59.982 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ...... 2021-11-11 15:44:59.984 [Thread-3] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: example <============= 2021-11-11 15:44:59.986 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"] 2021-11-11 15:44:59.991 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read 2021-11-11 15:45:00.067 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path '' 2021-11-11 15:45:00.071 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 2.758 seconds (JVM running for 3.221) 2021-11-11 15:45:00.145 [Thread-3] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: canal_test succeed <=============
4.Canal-admin
此处没用到所以就没搭建,集群方式搭建的话用admin会便于管理,可参考:canal-admin安装部署
-
说明
canal-admin:是用来管理canal集群的
PS1:针对于多个canal-server,配置文件无需在本地配置,都在canal-admin的web管理页面来统一配置管理;
PS2:针对于多个canal-adapter,/conf/application.yml也是同意在canal-admin来配置管理,但conf/es/的适配器则需在多台web保持一致!
-
canal-admin所需测试库
下载包内会含有 canal_manager.sql 文件,内容无需修改,进入数据库直接source此文件即可:
mysql> source /etc/canal/admin/canal_manager.sql;
PS:此数据库用来存储canal-admin自动生成的配置数据,包括canal-admin服务的默认用户名、密码
PS:若无sql文件,则直接复制粘贴以下sql语句,就是在canal_manager.sql拷出来的~
PS:查看canal-admin默认用户名密码:admin/123456
登录到数据库输入:select password(123456) 即可获取密文,需把星号去除:*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `canal_manager` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_bin */; USE `canal_manager`; SET NAMES utf8; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for canal_adapter_config -- ---------------------------- DROP TABLE IF EXISTS `canal_adapter_config`; CREATE TABLE `canal_adapter_config` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `category` varchar(45) NOT NULL, `name` varchar(45) NOT NULL, `status` varchar(45) DEFAULT NULL, `content` text NOT NULL, `modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for canal_cluster -- ---------------------------- DROP TABLE IF EXISTS `canal_cluster`; CREATE TABLE `canal_cluster` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(63) NOT NULL, `zk_hosts` varchar(255) NOT NULL, `modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for canal_config -- ---------------------------- DROP TABLE IF EXISTS `canal_config`; CREATE TABLE `canal_config` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `cluster_id` bigint(20) DEFAULT NULL, `server_id` bigint(20) DEFAULT NULL, `name` varchar(45) NOT NULL, `status` varchar(45) DEFAULT NULL, `content` text NOT NULL, `content_md5` varchar(128) NOT NULL, `modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `sid_UNIQUE` (`server_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for canal_instance_config -- ---------------------------- DROP TABLE IF EXISTS `canal_instance_config`; CREATE TABLE `canal_instance_config` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `cluster_id` bigint(20) DEFAULT NULL, `server_id` bigint(20) DEFAULT NULL, `name` varchar(45) NOT NULL, `status` varchar(45) DEFAULT NULL, `content` text NOT NULL, `content_md5` varchar(128) DEFAULT NULL, `modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `name_UNIQUE` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for canal_node_server -- ---------------------------- DROP TABLE IF EXISTS `canal_node_server`; CREATE TABLE `canal_node_server` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `cluster_id` bigint(20) DEFAULT NULL, `name` varchar(63) NOT NULL, `ip` varchar(63) NOT NULL, `admin_port` int(11) DEFAULT NULL, `tcp_port` int(11) DEFAULT NULL, `metric_port` int(11) DEFAULT NULL, `status` varchar(45) DEFAULT NULL, `modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Table structure for canal_user -- ---------------------------- DROP TABLE IF EXISTS `canal_user`; CREATE TABLE `canal_user` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `username` varchar(31) NOT NULL, `password` varchar(128) NOT NULL, `name` varchar(31) NOT NULL, `roles` varchar(31) NOT NULL, `introduction` varchar(255) DEFAULT NULL, `avatar` varchar(255) DEFAULT NULL, `creation_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; SET FOREIGN_KEY_CHECKS = 1; -- ---------------------------- -- Records of canal_user -- ---------------------------- BEGIN; INSERT INTO `canal_user` VALUES (1, 'admin', '6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9', 'Canal Manager', 'admin', NULL, NULL, '2019-07-14 00:05:28'); COMMIT; SET FOREIGN_KEY_CHECKS = 1;
5.安装Elasticsearch
集群部署请参考:Elasticsearch集群搭建
以下为单节点es部署
1)解压
tar xf packages/elasticsearch-6.8.6.tar.gz -C /etc/
2)配置
-
编辑配置文件
egrep -rv ‘^#’ /etc/elasticsearch-6.8.6/config/elasticsearch.yml
node.name: node-1 path.data: /etc/elasticsearch-6.8.6/data path.logs: /etc/elasticsearch-6.8.6/logs bootstrap.memory_lock: false network.host: 0.0.0.0 http.port: 9200 # 集群外部端口 network.publish_host: 172.23.0.239 # es本机ip transport.tcp.port: 9300 # 集群内部端口 discovery.zen.ping.unicast.hosts: ["172.23.0.239"] # 若是es集群,则在此处添加所有集群内es的ip # 开启跨域访问,es-head插件等其他集群管理工具需要此配置 http.cors.enabled: true http.cors.allow-origin: "*" xpack.security.enabled: false -
IK分词
由于英文句子都是使用空格进行分隔,因此在分词比较明确,但是中文由于语言特性分词比较难分,也容易产生分词歧义,如果自己开发分词器成本会比较大,所以一般在使用过程中都会用一些分词器,比较著名的有Jieba分词器,hanlp等,我们这里介绍一个es的插件分词器,ik分词器。
分词库下载与部署官方参考:戳我~
-
安装IK分词
百度网盘地址下载:戳我下载~ 网盘提取码:peng
分词案例参考:ik中文分词器及拼音分词器试用
安装:解压至Elasticsearch的plugins目录下,安装后要重启es
PS:此处我采用的是利用es插件命令直接安装:6.8.6为Elasticsearch的版本号,要对应好
# 在线安装 /etc/elasticsearch-6.8.6/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.6/elasticsearch-analysis-ik-6.8.6.zip /etc/elasticsearch-6.8.6/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v6.8.6/elasticsearch-analysis-pinyin-6.8.6.zip # 离线安装 # 下载包到本地后直接解压到plugins内即可,启动es时会自动安装加载插件 mkdir /etc/elasticsearch-6.8.6/plugins/{ik,pinyin} tar xf elasticsearch-analysis-ik-6.8.6.zip /etc/elasticsearch-6.8.6/plugins/ik/ tar xf elasticsearch-analysis-pinyin-6.8.6.zip /etc/elasticsearch-6.8.6/plugins/pinyin/
-
-
创建es用户并授权
Elasticsearch不允许root用户启动es
groupadd elasticsearch -g 666 useradd elasticsearch -g 666 chown -R elasticsearch. /etc/elasticsearch-6.8.6
3)启动
需切换到es用户进行启动,若要重启时,则需切回root用户进行kill相关进程【含有:Elasticsearch -d】
PS:es用户无权kill进程
-
启动
[root@es1_kibana1 ~]# su - elasticsearch [elasticsearch@es1_kibana1 ~]$ /etc/elasticsearch-6.8.6/bin/elasticsearch -d -
启动日志
[elasticsearch@es1_kibana1 ~]$ tailf /etc/elasticsearch-6.8.6/logs/elasticsearch.log [2021-11-11T16:50:16,640][INFO ][o.e.h.n.Netty4HttpServerTransport] [node-1] publish_address {172.23.0.239:9200}, bound_addresses {[::]:9200} [2021-11-11T16:50:16,640][INFO ][o.e.n.Node ] [node-1] started [2021-11-11T16:50:16,656][INFO ][o.w.a.d.Monitor ] [node-1] try load config from /etc/elasticsearch-6.8.6/config/analysis-ik/IKAnalyzer.cfg.xml [2021-11-11T16:50:17,140][INFO ][o.e.l.LicenseService ] [node-1] license [8bc4dc87-2103-4af7-bd48-cc9e6df92d27] mode [basic] - valid [2021-11-11T16:50:17,145][INFO ][o.e.g.GatewayService ] [node-1] recovered [6] indices into cluster_state [2021-11-11T16:50:18,676][INFO ][o.e.c.m.MetaDataIndexTemplateService] [node-1] adding template [.management-beats] for index patterns [.management-beats] -
检查状态
因为是单节点,集群状态难免为red,正常~
-
节点状态
[root@es1_kibana1 ~]# curl http://172.23.0.239:9200/_cluster/health?pretty=true { "cluster_name" : "elasticsearch", "status" : "red", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 15, "active_shards" : 15, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 22, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 40.54054054054054 }
-
6.安装Kibana
1)解压
tar xf kibana-6.8.6-linux-x86_64.tar.gz -C /etc
2)配置
egrep -rv ‘^#’ /etc/kibana-6.8.6-linux-x86_64/config/kibana.yml | grep '\ ’
server.port: 5601 # kiban端口号
server.host: "0" # 允许所有ip传送数据
elasticsearch.hosts: ["http://localhost:9200"] # 监听es的ip+端口
3)启动
-
启动
/etc/kibana-6.8.6-linux-x86_64/bin/kibana -d -
检查状态
[root@es1_kibana1 ~]# netstat -lntp | grep 5601 tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 3726/node
4)创建索引
es创建索引须知:
- 参考: 类型配置操作
- 参考:自定义mapping
理解剖析
- mapping/settings有何作用?
- 1、其实主要是在搜索的时候给ES系统内部自己用的,就算不给index指定mapping,或不进行settings设置,在很多时候也能很好的工作;
- 2、但对于操作的数据对象,我们自己了解的信息,肯定不如ES猜测的信息全并且准确;
- 3、我们自己在工程应用中,最好还是自己给索引做settings和mappings的设置!
1)格式参考
MySQL与Elasticsearch数据类型对照表
MySQL数据类型 | Elasticsearch数据类型 | 说明 |
|---|---|---|
tinyint | short | 如果源库中的类型为unsigned tinyint,在Elasticsearch中使用integer |
mediumint | integer | ~ |
smallint | short | 如果源库中的类型为unsigned smallint,在Elasticsearch中使用integer |
int | integer | 如果源库中的类型为unsigned int,在Elasticsearch中使用long |
bigint | long | ~ |
| `Bool | Boolean` | boolean |
| `Decimal | DEC` | double |
double | double | ~ |
float | float | ~ |
Real | double | ~ |
Char | text | ~ |
Varchar | text | ~ |
longtext | text | ~ |
mediumtext | text | ~ |
tinytext | text | ~ |
blob | binary | ~ |
binary | binary | ~ |
bit | long | 如果bit只有一位,建议Elasticsearch中使用的数据类型为boolean |
Date | date | 在Elaticsearch中的date format为:yyyy-MM-dd,date format的mapping 定义参考Elasticsearch文档 |
datetime | date | 在Elaticsearch中的date format为:yyyy-MM-dd’T’HH:mm:ss,如果带微秒精度,那么date_format为yyyy-MM-dd’T’HH:mm:ss.S。date format的mapping 定义参考Elasticsearch文档 |
timestamp | date | 在Elaticsearch中的date format为:yyyy-MM-dd’T’HH:mm:ss,如果带微秒精度,那么date_format为yyyy-MM-dd’T’HH:mm:ss.S。date format的mapping 定义参考Elasticsearch文档 |
time | date | 在Elaticsearch中的date format为:HH:mm:ss,如果带微秒精度,那么date_format为 HH:mm:ss.S,date format的mapping 定义参考Elasticsearch文档 |
year | date | 在Elaticsearch中的date format为:yyyy。date format的mapping 定义参考Elasticsearch文档 |
geometry | geo_shape | ~ |
point | geo_point | ~ |
linestring | geo_shape | ~ |
polygon | geo_shape | ~ |
multipoint | geo_shape | ~ |
multilinestring | geo_shape | ~ |
multipolygon | geo_shape | ~ |
geometrycollection | geo_shape | ~ |
json | object | 如果bit只有一位,建议Elasticsearch中使用的数据类型为boolean |
2)创建索引
canal服务接收MySQL的binlog日志后,回传送给ES,而ES需要创建对应索引才能获取到binlog的数据,创建索引的字段也与MySQL不同
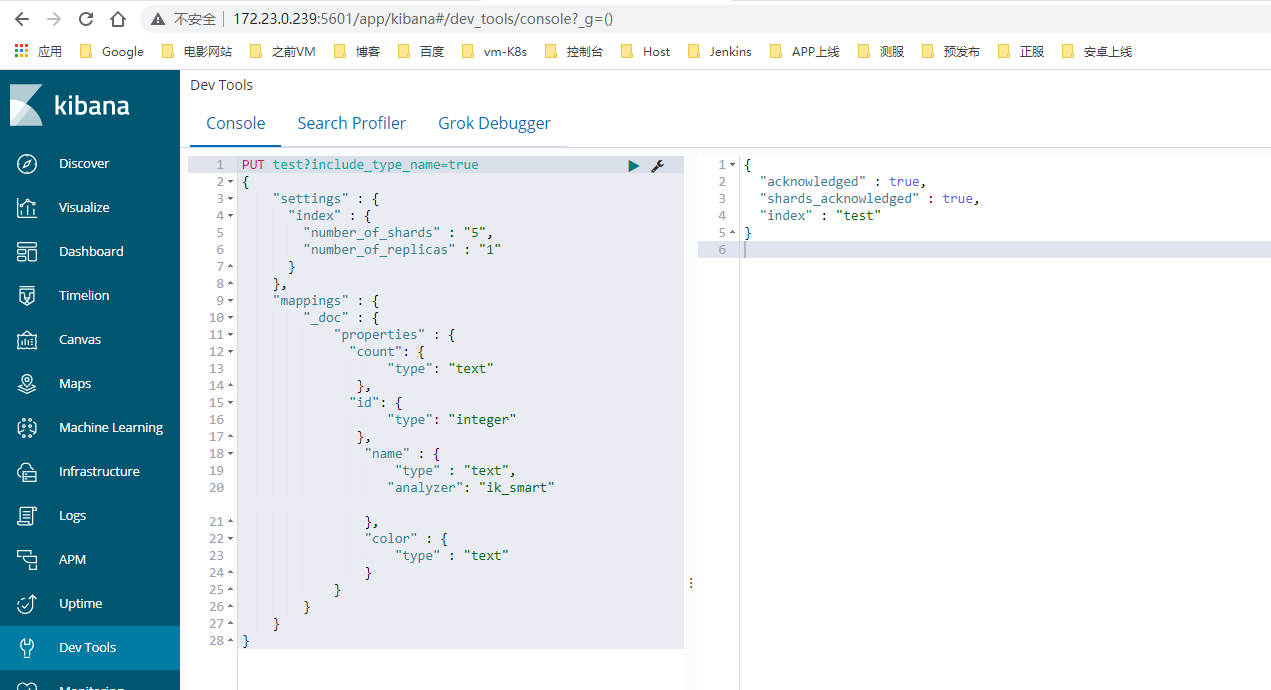
在Kibana控制台–Dev-Tools–Console 对ES进行操作:
PUT test?include_type_name=true
{
"settings" : {
"index" : {
"number_of_shards" : "5",
"number_of_replicas" : "1"
}
},
"mappings" : {
"_doc" : {
"properties" : {
"count": {
"type": "text"
},
"id": {
"type": "integer"
},
"name" : {
"type" : "text",
"analyzer": "ik_smart"
},
"color" : {
"type" : "text"
}
}
}
}
}
-
创建成功如右侧显示:true
8.插入数据并测试
1)建库
CREATE DATABASE peng CHARACTER DEFAULT set utf8mb4 collate utf8mb4_general_ci;
2)建表
CREATE TABLE `test` (
`id` int(11) DEFAULT NULL,
`name` text,
`count` text,
`color` text
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3)插入数据
插入数据看是否同步binlog的日志;
MySQL插入、更新、删除数据,看canal-adapter实施日志是否有数据更新;
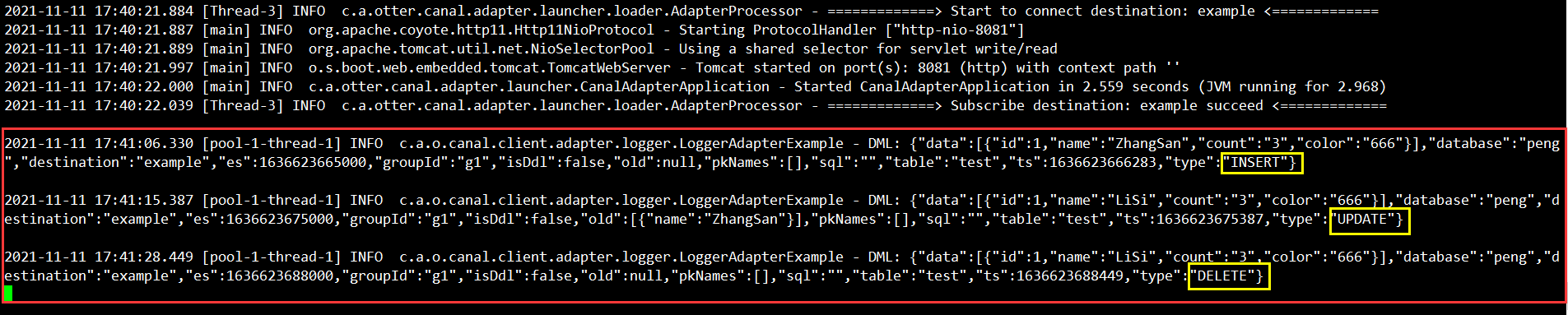
INSERT INTO `peng`.`test` (`id`, `name`, `count`, `color`) VALUES (1, 'ZhangSan', '3', '666');
UPDATE `peng`.`test` SET name = 'LiSi' WHERE count = '3';
DELETE FROM `peng`.`test` WHERE count = '3';
4)查看是否同步
1> canal-adapter端查看
查看canal-adapter实时日志
插入的数据已经实时同步过来了,依次执行日志后缀分别为【insert、update、delete】语句
2> Kibana端查看
略~
9.手动同步命令
测试:adapter管理REST接口
1)查询所有订阅同步
查询所有订阅同步的canal instance、MQ topic
curl http://127.0.0.1:8081/destinations
2)数据同步开关
针对 example 这个canal instance/MQ topic 进行开关操作;
off代表关闭, instance/topic下的同步将阻塞或者断开连接不再接收数据, on代表开启;
curl http://127.0.0.1:8081/syncSwitch/example # 查看开关
curl http://127.0.0.1:8081/syncSwitch/example/on -X PUT # 开
curl http://127.0.0.1:8081/syncSwitch/example/off -X PUT # 关
3)手动同步
导入数据到指定类型的库, 如果params参数为空则全表导入, 参数对应的查询条件在配置中的etlCondition指定
curl http://127.0.0.1:8081/etl/es/test.yml -X POST # 直接将日志导入结果打印到屏幕
curl http://106.14.76.131:8081/etl/es/test.yml -X POST -d “params>>import.log” # 导入后会在es目录下生成日志文件
cat es/import.log
{"succeeded":true,"resultMessage":"导入ES 数据:3 条"}{"succeeded":true,"resultMessage":"导入ES 数据:3 条"}
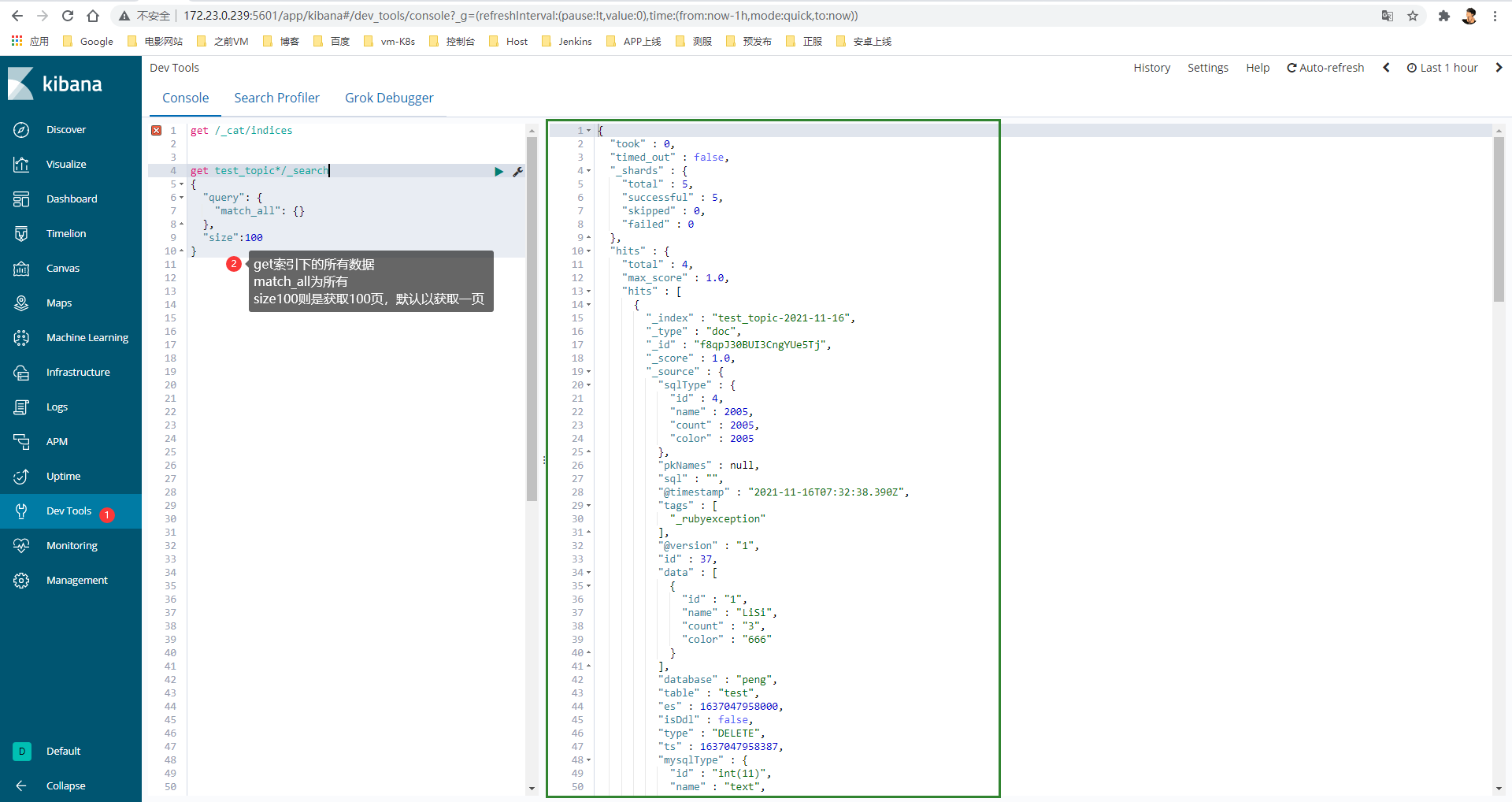
4)查询语法
Kibana内的ES查询语法
# 查看所有索引
get _cat/indices
# 查看索引字段
get c2c_goods_image
get c2c_goods_product
# 查看索引数据
get c2c_goods_image/_search
get c2c_goods_product/_search
# 查找索引数据
get c2c_goods_image/_search
{
"query": {
"match": {
"goodsId": "1535"
}
}
}
get c2c_goods_product/_search
{
"query": {
"match": {
"_id": "2222"
}
}
}
# 匹配多条件(size的大小,决定匹配出但未显示出的数据)
GET c2c_goods_product/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"goodsName": {
"value": "*四季*"
}
}
}
]
}
},
"from": 0,
"size": 2000,
"sort": [
{
"goodsId": {
"order": "desc"
}
}
]
}
# 全文模糊匹配(比上面的更广泛)
# 可搜:四豆、豆四、sidou、dousi
GET c2c_goods_product/_search
{
"query": {
"bool": {
"must": [
{
"wildcard": {
"goodsName": {
"value": "四季豆"
}
}
}
]
}
},
"from": 0,
"size": 2000,
"sort": [
{
"goodsId": {
"order": "desc"
}
}
]
}
# 删除索引
DELETE c2c_goods_image
DELETE c2c_goods_product
10.问题拍错
集群方式部署canal若监听成功,但拉取不到数据,则是zookeeper协调数据有问题,重置数据即可
参考:canal排错
# 关闭canal-adapter
# 关闭canal-server
# 进到zookeeper容器,删除对应实例的数据
[root@h48 ~]# docker exec -it zookeeper bash
root@402010bb17e5:/apache-zookeeper-3.5.6-bin# zkCli.sh -server localhost
[zk: localhost(CONNECTED) 0] delete /otter/canal/destinations/ehu-c2c/1001/cursor
# 启动canal-server
# 启动canal-adapter
Docker方式部署
Docker服务安装:戳我~
1.拉取镜像
-
Canal节点
docker pull canal-server:v1.1.4 docker pull canal-adapter:latest docker pull canal-admin:v1.1.4 docker pull mysql:5.7 -
ES+Kibana节点
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.8.6 docker pull docker.elastic.co/kibana/kibana:6.8.6
2.配置启动
1)配置
略,参考上方二进制部署的配置文件,自行配置即可~
2)启动
-
Canal节点
-
MySQL
docker run -d \ --name=mysql \ -e MYSQL_ROOT_PASSWORD=123456 \ -e MYSQL_MAJOR=5.6 \ -v /home/mysql/:/var/lib/mysql \ -v /root/backup/my.cnf:/etc/mysql/my.cnf -v /data/nfs/mysql/conf:/etc/mysql/conf.d \ -v /var/lib/mysql \ -p 3306:3306 \ --restart=no \ mysql:5.6 -
canal-server
docker run -d \ --name=canal-server \ -e canal.admin.manager=172.23.0.234:8089 \ -e canal.admin.port=11110 \ -e canal.admin.port=11110 \ -e canal.admin.user=admin \ -e canal.admin.passwd=6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 \ -e canal.admin.register.cluster=canal_manager \ -m 4096m \ -p 11110:11110 \ -p 11111:11111 \ -p 11112:11112 \ -p 9100:9100 \ -m 4096m \ -v /root/canal/canal-server/conf:/home/admin/canal-server/conf \ -v /root/canal/canal-server/logs:/home/admin/canal-server/logs \ canal/canal-server:v1.1.4 -
canal-adapter
docker run -d \ --name canal-adapter \ -v /root/canal/canal-adapter/conf:/canal-adapter/conf \ -v /root/canalcanal-adapter/logs:/canal-adapter/logs \ -p 8081:8081 \ canal-adapter:latest -
canal-admin
canal-admin并不是必须部署的,只是一个集群管理组件,便于管理集群而已
部署canal-admin,canal-server与canal-adapter的部分配置需在admin上配置,参考:canal-admin安装部署
访问:172.23.0.234:8089 进行管理集群,默认用户名/密码:admin/123456
docker run -d \ -e server.port=8089 \ -e canal.adminUser=admin \ -e canal.adminPasswd=123456 \ --name=canal-admin \ -m 1024m \ -p 8089:8089 \ canal/canal-admin:v1.1.4 -
Zookeeper
若部署了canal集群,则需zookeeper来协调:Zookeeper集群部署
查看 zookeeper集群中,canal server的 active节点信息:
docker exec -it zookeeper bash $ ./zkCli.sh -server localhost:2181 # canal server正在运行 [zk: localhost:2181(CONNECTED) 15] get /otter/canal/destinations/canal_es_Instance_config/running {"active":true,"address":"172.17.0.3:11111"} # canal server未运行 [zk: localhost:2181(CONNECTED) 14] get /otter/canal/destinations/canal_es_Instance_config/running org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /otter/canal/destinations/canal_es_Instance_config/running
-
-
ES+Kiban节点
-
Elasticsearch
-
Kibana
参考:Kibana集群部署
-
附:同步到Kafka
PS1:同步至kafka,则无需配置canal-adapter/conf/es的配置,用不到,当然配了也无碍
注:可能无法看到canal与l卡夫卡、ogstash的实时日志,就直接输出到Elasticsearch了~
注:若是直接在canal输出到Elasticsearch,则canal的日志会实时输出到屏幕~
PS2:以下配置文件有2处需对应:它们的值应为实例名称(建议定义与索引名有关)
/etc/canal/server/conf/canal.properties ---------- canal.destinations:example
/etc/canal/server/conf/example/instance.properties ---------- instance:example
1.配置canal-server
-
/etc/canal/server/conf/canal.properties
canal.destinations应与/etc/canal/adapter/conf/application.yml内的- instance 的值相同(即实例名)
canal.serverMode = kafka # 默认为tcp,可直接输出到es ################################################# ######### destinations ############# ################################################# # 此处可指定实例目录,即/etc/canal/server/conf/example,或/etc/canal/server/conf/test # 多个实例则cp多个example目录改名即可,并在此处添加新增的实例名,逗号隔开如:canal.destinations = example,test # test目录则是cp的example目录,主要修改里面的instance.properties canal.destinations = example ################################################## ######### MQ ############# ################################################## # kafka的ip+端口 canal.mq.servers = 172.23.0.237:9092,172.23.0.238:9092 -
/etc/canal/server/conf/example/instance.properties
canal.instance.master.address=127.0.0.1:3306 # username/password # canal的sql用户名密码 canal.instance.dbUsername=canal canal.instance.dbPassword=canal # mq config # kafka实例的主题名,若有多个kafka实例,则复制多个example,并对应修改此处的topic名称即可 # 不可在此处写多个topic!每个实例只能对应一个topic canal.mq.topic=test_topic
2.配置canal-adapter
-
/etc/canal/adapter/conf/application.yml
其余未展示配置保持默认即可
canal.conf: mode: kafka #tcp kafka rocketMQ rabbitMQ flatMessage: true zookeeperHosts: syncBatchSize: 1000 retries: 0 timeout: accessKey: secretKey: consumerProperties: # canal tcp consumer canal.tcp.server.host: 127.0.0.1:11111 canal.tcp.zookeeper.hosts: 172.23.0.237:2181,172.23.0.238:2181 ··· # kafka consumer kafka.bootstrap.servers: 172.23.0.237:9092,172.23.0.238:9092 srcDataSources: defaultDS: url: jdbc:mysql://172.23.0.234:3306/peng?useUnicode=true username: canal password: canal canalAdapters: # 应与/etc/canal/server/conf/canal.properties内的canal.destinations的值相同(即实例名) - instance: example # canal instance Name or mq topic name groups: - groupId: g1 outerAdapters: - name: logger # 将输出到es配置注释掉 # - name: es # hosts: 172.23.0.239:9200 # #hosts: 172.23.0.239:9200,172.23.0.240:9200 # properties: # mode: rest # mode: transport模式,hosts中的端口要用9300;用rest模式,hosts中的端口要用9200 # security.auth: # #security.auth: admin:12345 # 若设置了es密码,则在此处指定 # cluster.name: # es集群名
3.部署Logstash
用于接受kafka的topic数据,转发至Elasticsearch
PS:单、多个logstash节点都可以~
1)配置
需配置以下配置文件,参考:配置Logstash
-
cat /config/logstash1/config/jvm.options
-
/config/logstash1/config/logstash.yml
-
/config/logstash1/pipeline/canal.conf
-
接受Canal数据并输出到Elasticsearch
################### 多索引模式 ################### input { kafka { bootstrap_servers => ["172.23.0.237:9092,172.23.0.238:9092"] topics => "test_topic" # 使用kafka传过来的topic # topics_pattern => "logstash-.*" # 使用正则匹配topic codec => 'json' } } ################### 输出到es ################### output { stdout { codec => rubydebug } elasticsearch { hosts => ["172.23.0.239:9200","172.23.0.240:9200"] index => "test_topic-%{+YYYY-MM-dd}" #codec => json } }
-
2)启动
4.部署Elasticsearch
按上方配置部署即可~
5.部署Kibana
按上方配置部署即可~
6.插入数据并测试
1)插入数据
参考执行:第8小结
2)查看是否同步
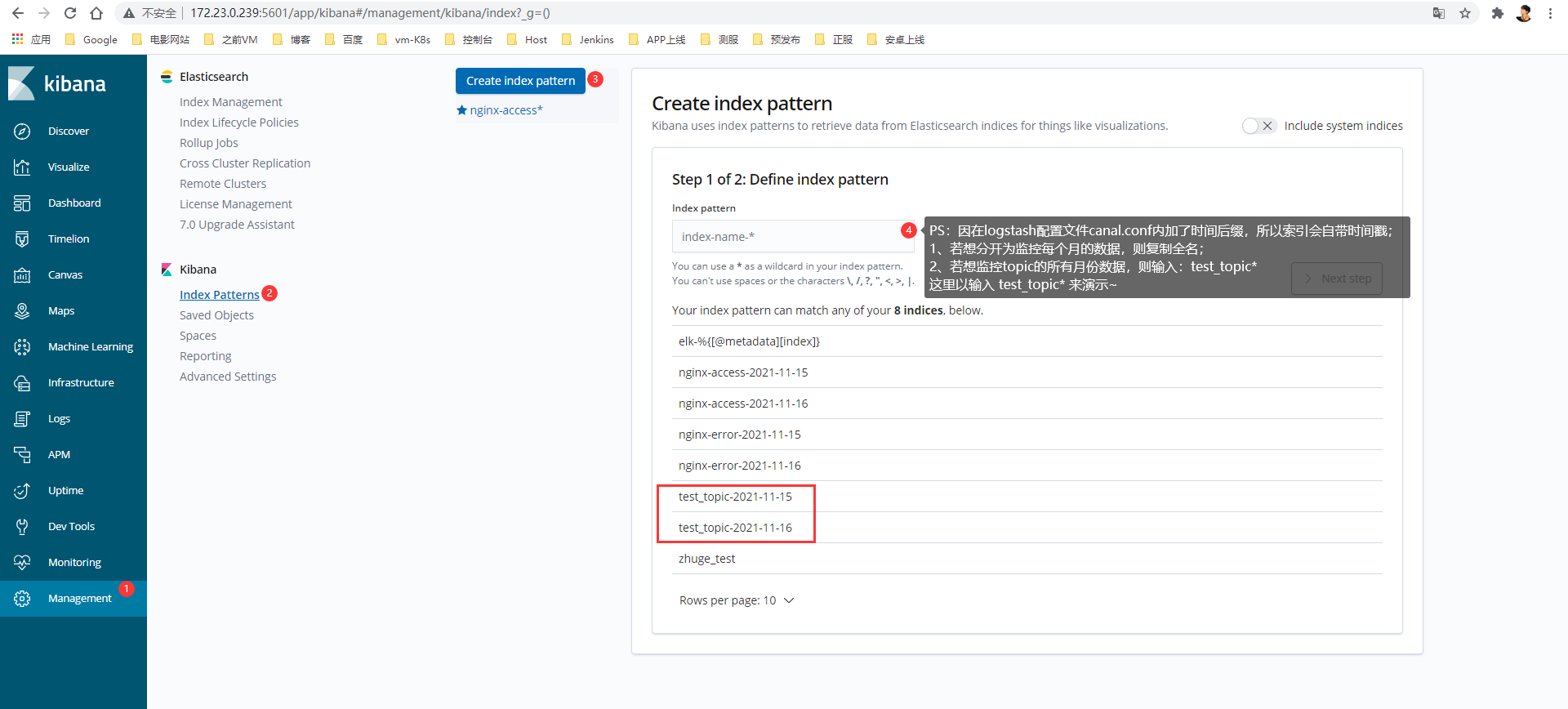
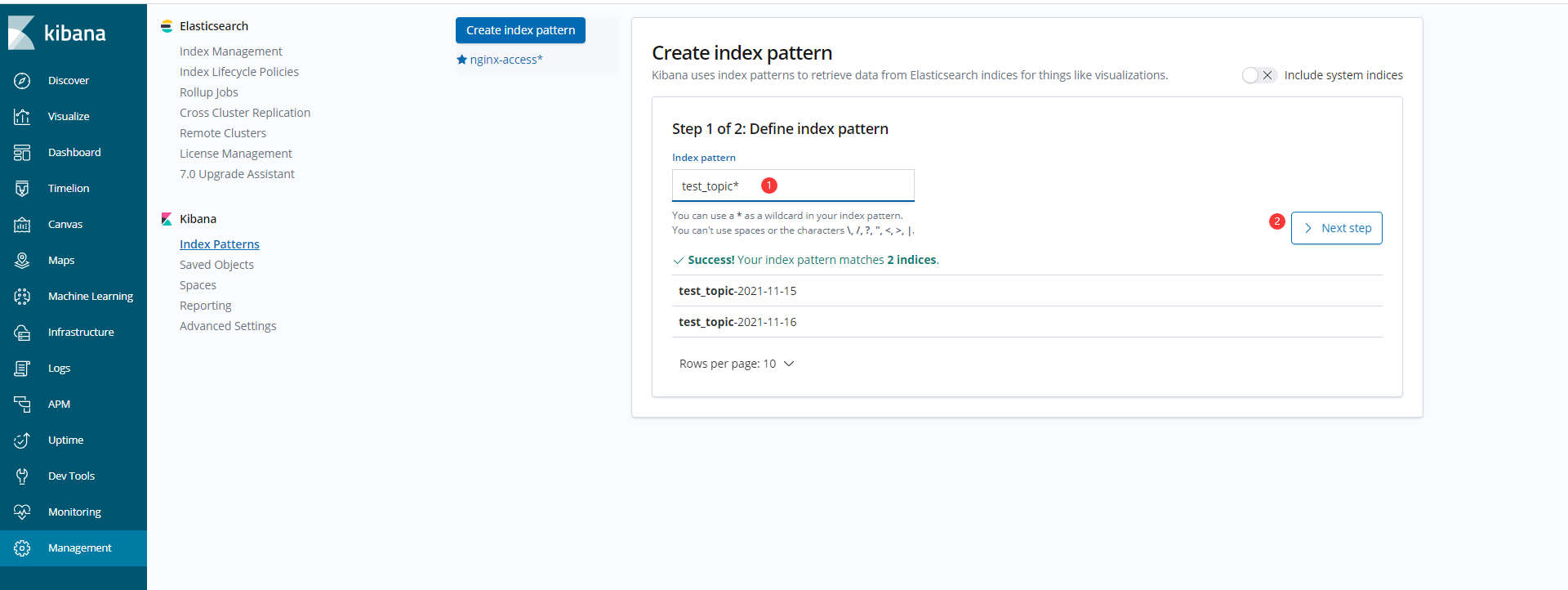
进入Kibana:172.23.0.239:5601
1> 创建索引
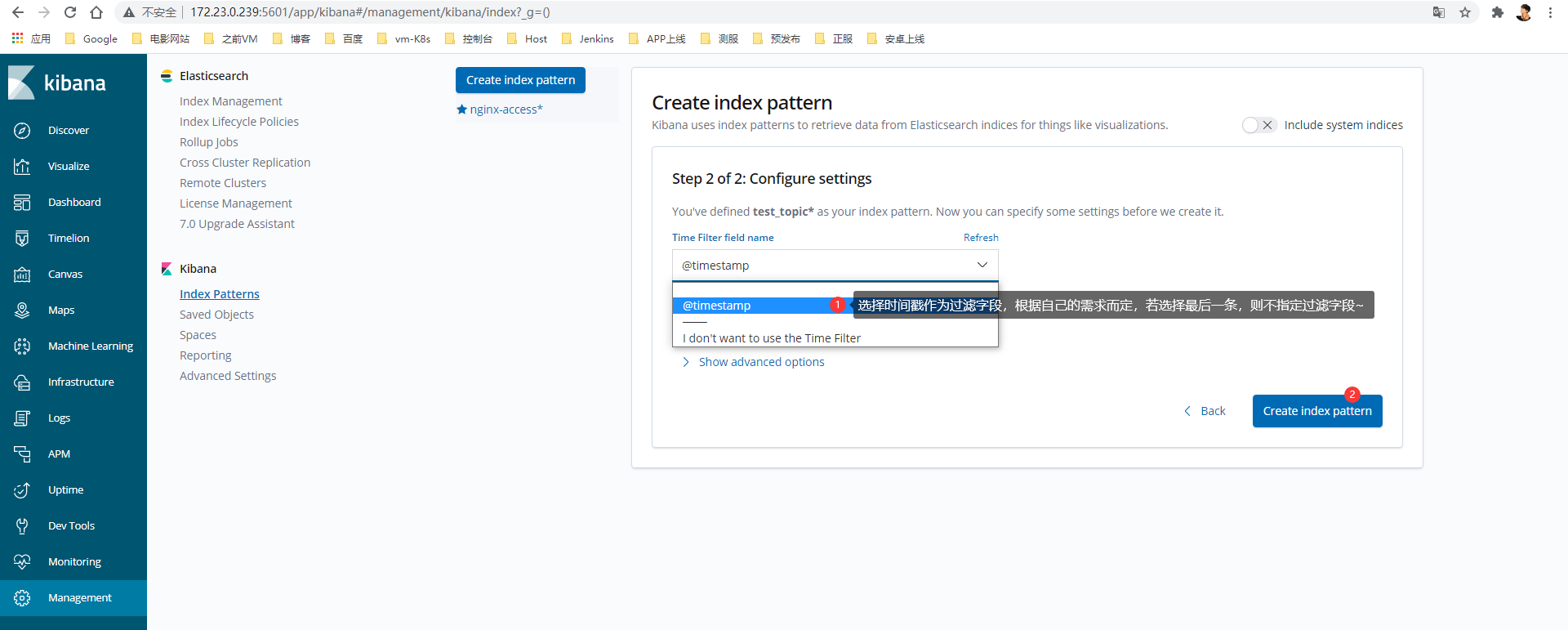
2> 获取数据
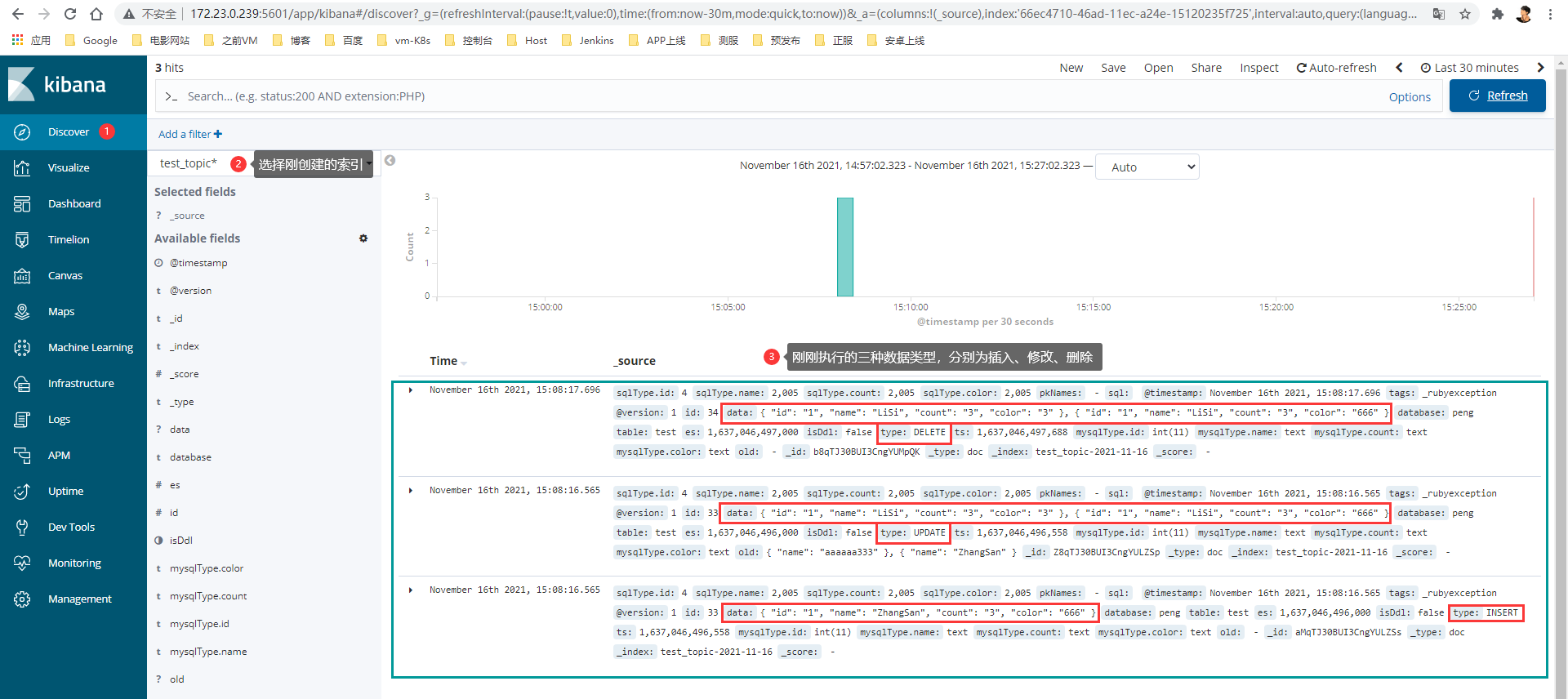
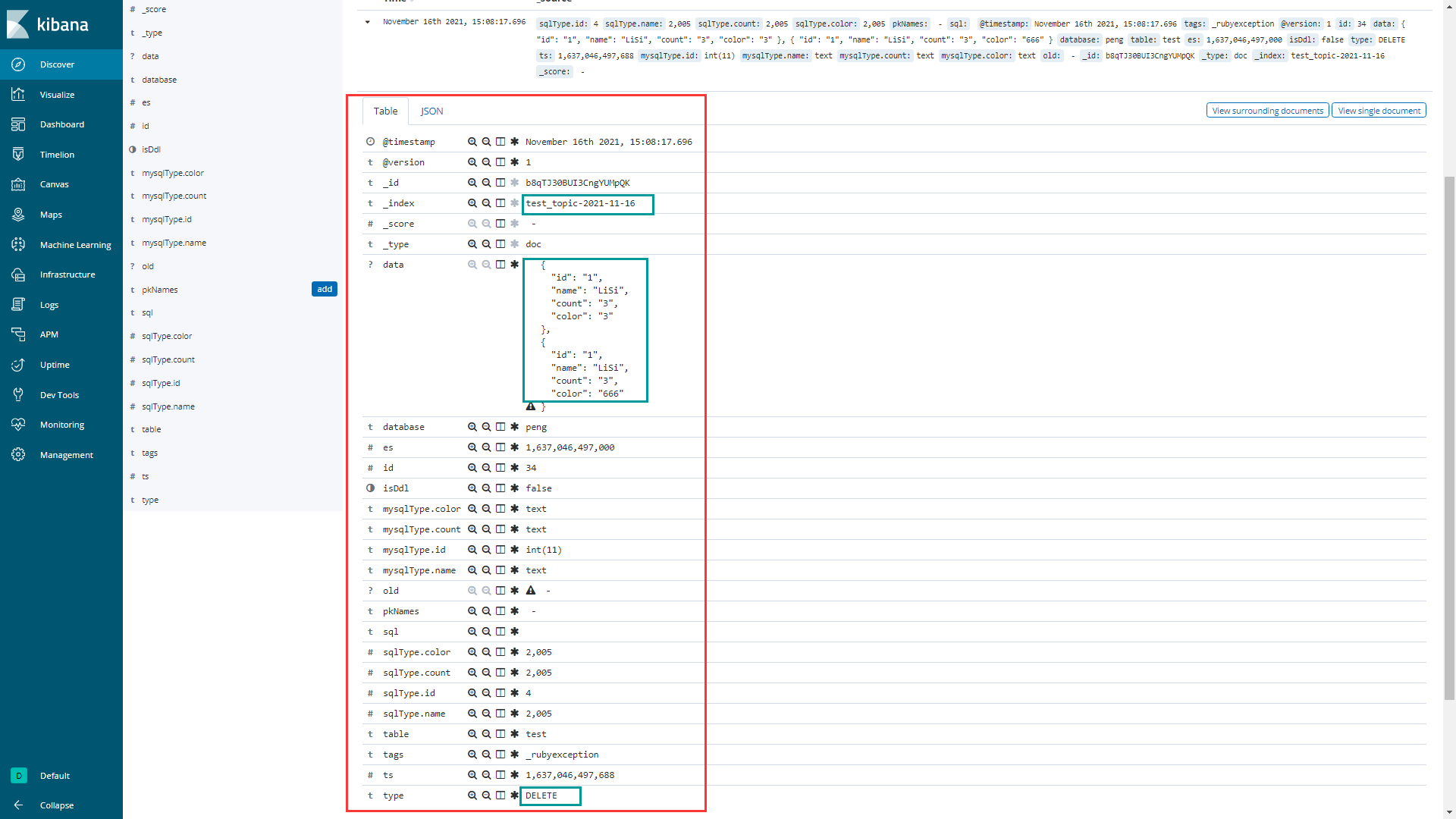
3> 展开查看
展开后查看更加人性化
4> 开发工具get数据
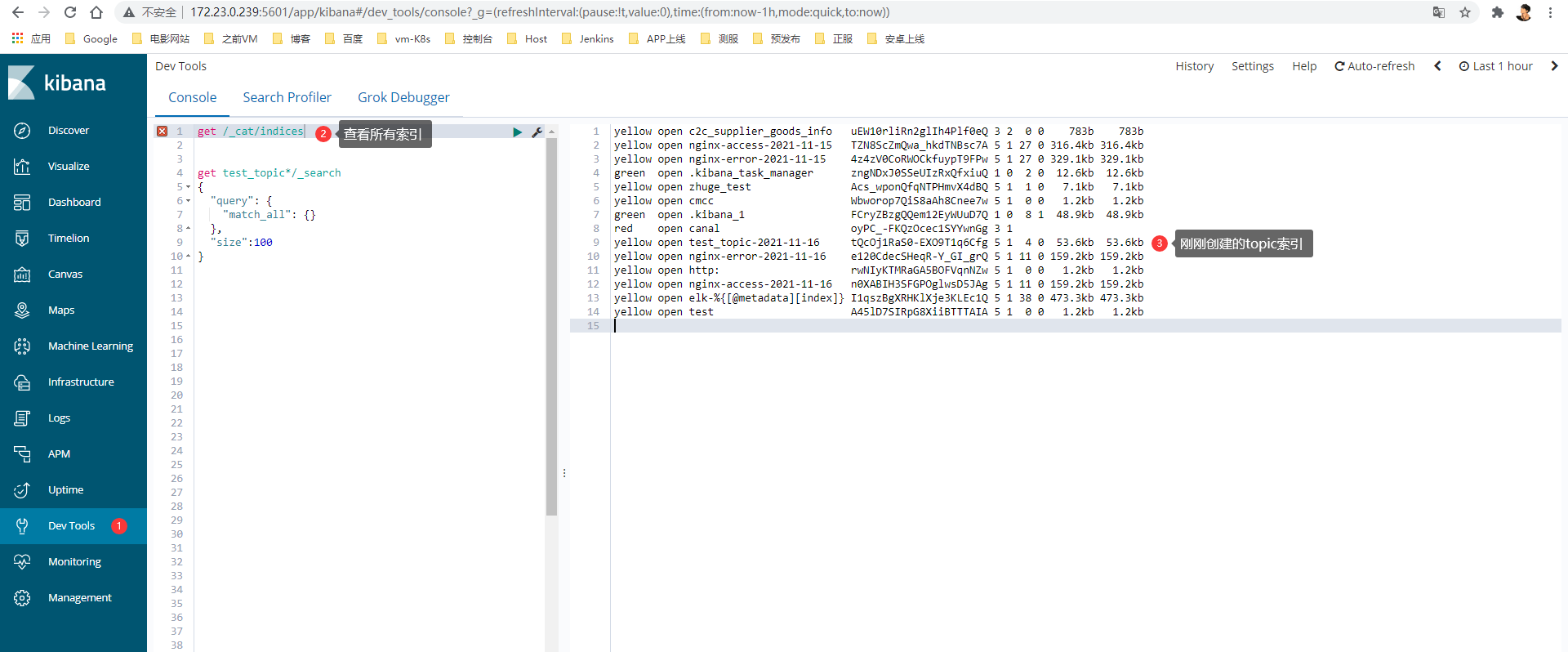

 浙公网安备 33010602011771号
浙公网安备 33010602011771号