K8s-K8s部署Zookeeper+Kafka+ELFK+持久化数据
文章目录
引
K8s环境下容器化部署Zookeeper+Kafka+ELFK日志收集系统整篇文章工作流程:
1、搭建
Zookeeper+Kafka、ELFK 2、制作日志数据
3、展示日志数据
NFS-Client动态存储可参考:K8s-nfs-client动态存储部署
各服务介绍可参考:企业级ELFK日志架构介绍
方案采取可参考:应用场景与方案
创建清单目录
[root@k8s-master01 ~]# imkdir log-cluster/{{kafka,zookeeper},elfk/{es,logstash,kibana,fluentd}} -p
[root@k8s-master01 ~]# tree log-cluster/
log-cluster/
├── elfk
│ ├── es
│ ├── fluentd
│ ├── kibana
│ └── logstash
├── kafka
└── zookeeper
Zookeeper & Kafka
Zookeeper
目录清单结构
[root@k8s-master01 zookeeper]# tree
.
├── 1.storage.yaml
├── 2.svc.yaml
├── 3.configmap.yaml
├── 4.pdb.yaml
└── 5.statefulset.yaml
配置清单
1.storage.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: zk-data-db
provisioner: cluster.local/nfs-client-nfs-client-provisioner
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
2.svc.yaml
apiVersion: v1
kind: Service
metadata:
name: zk-svc
namespace: kube-ops
labels:
app: zk-svc
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
3.configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: zk-cm
namespace: kube-ops
data:
jvm.heap: "1G"
tick: "2000"
init: "10"
sync: "5"
client.cnxns: "60"
snap.retain: "3"
purge.interval: "0"
4.pdb.yaml
PS:PodDisruptionBudget的作用就是为了保证业务不中断或者业务SLA不降级。通过PodDisruptionBudget控制器可以设置应用POD集群处于运行状态最低个数,也可以设置应用POD集群处于运行状态的最低百分比,这样可以保证在主动销毁应用POD的时候,不会一次性销毁太多的应用POD,从而保证业务不中断或业务SLA不降级。
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
namespace: kube-ops
spec:
selector:
matchLabels:
app: zk
minAvailable: 2
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
namespace: kube-ops
spec:
serviceName: zk-svc
replicas: 3
selector:
matchLabels:
app: zk
template:
metadata:
labels:
app: zk
spec:
containers:
- name: k8szk
imagePullPolicy: Always
image: registry.cn-hangzhou.aliyuncs.com/rookieops/zookeeper:3.4.10
resources:
requests:
memory: "2Gi"
cpu: "500m"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
env:
- name : ZK_REPLICAS
value: "3"
- name : ZK_HEAP_SIZE
valueFrom:
configMapKeyRef:
name: zk-cm
key: jvm.heap
- name : ZK_TICK_TIME
valueFrom:
configMapKeyRef:
name: zk-cm
key: tick
- name : ZK_INIT_LIMIT
valueFrom:
configMapKeyRef:
name: zk-cm
key: init
- name : ZK_SYNC_LIMIT
valueFrom:
configMapKeyRef:
name: zk-cm
key: tick
- name : ZK_MAX_CLIENT_CNXNS
valueFrom:
configMapKeyRef:
name: zk-cm
key: client.cnxns
- name: ZK_SNAP_RETAIN_COUNT
valueFrom:
configMapKeyRef:
name: zk-cm
key: snap.retain
- name: ZK_PURGE_INTERVAL
valueFrom:
configMapKeyRef:
name: zk-cm
key: purge.interval
- name: ZK_CLIENT_PORT
value: "2181"
- name: ZK_SERVER_PORT
value: "2888"
- name: ZK_ELECTION_PORT
value: "3888"
command:
- sh
- -c
- zkGenConfig.sh && zkServer.sh start-foreground
readinessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: zk-data-db
resources:
requests:
storage: 1Gi
5.statefulset.yaml
部署
[root@k8s-master01 zookeeper]# kubectl apply -f ./
storageclass.storage.k8s.io/zk-data-db created
service/zk-svc created
configmap/zk-cm created
poddisruptionbudget.policy/zk-pdb created
statefulset.apps/zk created
[root@k8s-master01 es]# kubectl get all -n kube-ops | grep zk
pod/zk-0 1/1 Running 0 22m
pod/zk-1 1/1 Running 0 21m
pod/zk-2 1/1 Running 0 20m
service/zk-svc ClusterIP None <none> 2888/TCP,3888/TCP 22m
statefulset.apps/zk 3/3 22m
[root@k8s-master01 es]# kubectl get pvc -n kube-ops
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
datadir-zk-0 Bound pvc-cd6f407e-d782-4944-8d79-ade8c386b9ad 1Gi RWO zk-data-db 22m
datadir-zk-1 Bound pvc-c4932edb-ff48-4e60-ad16-d8141e1daa98 1Gi RWO zk-data-db 22m
datadir-zk-2 Bound pvc-4a48cc44-ad9f-41f1-a499-9be1cf69b111 1Gi RWO zk-data-db 21m
检测状态
由此可见,一个
leader,两个follower,即一主两从
[root@k8s-master01 es]# for i in 0 1 2;do kubectl exec -it -n kube-ops zk-$i -- bash -c "zkServer.sh status";done
ZooKeeper JMX enabled by default
Using config: /usr/bin/../etc/zookeeper/zoo.cfg
Mode: follower
ZooKeeper JMX enabled by default
Using config: /usr/bin/../etc/zookeeper/zoo.cfg
Mode: leader
ZooKeeper JMX enabled by default
Using config: /usr/bin/../etc/zookeeper/zoo.cfg
Mode: follower
Kafka
目录清单结构
[root@k8s-master01 kafka]# tree
.
├── 1.storage.yaml
├── 2.svc.yaml
├── 3.configmap.yaml
├── 4.statefulset.yaml
└── dockerfile
├── Dockerfile
├── jdk-8u192-linux-x64.tar.gz
└── kafka_2.11-2.3.1.tgz
制作镜像
准备目录文件
cd kafka
mkdir dockerfile
cd dockerfile
# 下载kafka、jdk包构建到镜像内
wget https://archive.apache.org/dist/kafka/2.3.1/kafka_2.11-2.3.1.tgz
wget http://download.oracle.com/otn/java/jdk/8u192-b12/750e1c8617c5452694857ad95c3ee230/jdk-8u192-linux-x64.tar.gz
Dockerfile
# Java包下载:
# https://www.oracle.com/cn/java/technologies/javase/javase8-archive-downloads.html#license-lightbox
# PS: 搜索【jdk-8u131-linux-x64.tar.gz】,下载后可能名不相同,自改即可
# Kafka包下载:https://archive.apache.org/dist/kafka/2.3.1/kafka_2.11-2.3.1.tgz
FROM centos:centos7
LABEL "auth"="rookieops" \
"mail"="https://blog.csdn.net/qq_23995091?spm=1011.2124.3001.5343"
ENV TIME_ZONE Asia/Shanghai
# install JAVA
ADD jdk-8u192-linux-x64.tar.gz /opt/
ENV JAVA_HOME /opt/jdk1.8.0_192
ENV PATH ${JAVA_HOME}/bin:${PATH}
# install kafka
ADD kafka_2.11-2.3.1.tgz /opt/
RUN mv /opt/kafka_2.11-2.3.1 /opt/kafka
WORKDIR /opt/kafka
EXPOSE 9092
CMD ["./bin/kafka-server-start.sh", "config/server.properties"]
构建镜像
docker build -t 18954354671/kafka:v1 .
docker tag 18954354671/kafka:v1 harbor.peng.cn/base/kafka:v1
docker push 18954354671/kafka:v1
docker push harbor.peng.cn/base/k8s-kafka:v1
[root@k8s-master01 dockerfile]# docker images|grep kafka
18954354671/kafka v1 eca552ee1d54 38 seconds ago 740MB
harbor.peng.cn/base/k8s-kafka latest 2bbd922598ed 3 days ago 452MB
bitnami/kafka 3.1.0-debian-10-r14 b8072ef9f366 10 days ago 618MB
配置清单
1.storage.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: kafka-data-db
provisioner: cluster.local/nfs-client-nfs-client-provisioner
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
2.svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
namespace: kube-ops
labels:
app: kafka
spec:
selector:
app: kafka
clusterIP: None
ports:
- name: server
port: 9092
3.configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: kafka-config
namespace: kube-ops
data:
server.properties: |
broker.id=${HOSTNAME##*-}
listeners=PLAINTEXT://:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=zk-0.zk-svc.kube-ops.svc.cluster.local:2181,zk-1.zk-svc.kube-ops.svc.cluster.local:2181,zk-2.zk-svc.kube-ops.svc.cluster.local:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
4.statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
namespace: kube-ops
spec:
serviceName: kafka-svc
replicas: 3
selector:
matchLabels:
app: kafka
template:
metadata:
labels:
app: kafka
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
terminationGracePeriodSeconds: 300
containers:
- name: kafka
image: harbor.peng.cn/base/kafka:v1 #registry.cn-hangzhou.aliyuncs.com/rookieops/kafka:2.3.1-beta
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 500m
memory: 1Gi
command:
- "/bin/sh"
- "-c"
- "./bin/kafka-server-start.sh config/server.properties --override broker.id=${HOSTNAME##*-}"
ports:
- name: server
containerPort: 9092
volumeMounts:
- name: config
mountPath: /opt/kafka/config/server.properties
subPath: server.properties
- name: data
mountPath: /data/kafka/logs
volumes:
- name: config
configMap:
name: kafka-config
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: kafka-data-db
resources:
requests:
storage: 10Gi
部署
[root@k8s-master01 kafka]# kubectl apply -f ./
storageclass.storage.k8s.io/kafka-data-db created
service/kafka-svc created
configmap/kafka-config created
statefulset.apps/kafka created
[root@k8s-master01 kafka]# kubectl get all -n kube-ops
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 0 22h
pod/es-cluster-1 1/1 Running 0 22h
pod/es-cluster-2 1/1 Running 0 21h
pod/kafka-0 1/1 Running 0 97s
pod/kafka-1 1/1 Running 0 95s
pod/kafka-2 1/1 Running 0 91s
pod/kibana-685bd77cb8-lpr7b 1/1 Running 0 22h
pod/zk-0 1/1 Running 0 22h
pod/zk-1 1/1 Running 0 22h
pod/zk-2 1/1 Running 0 22h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 22h
service/kafka-svc ClusterIP None <none> 9092/TCP 16m
service/kibana NodePort 192.168.53.88 <none> 5601:31782/TCP 22h
service/zk-svc ClusterIP None <none> 2888/TCP,3888/TCP 22h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kibana 1/1 1 1 22h
NAME DESIRED CURRENT READY AGE
replicaset.apps/kibana-685bd77cb8 1 1 1 22h
NAME READY AGE
statefulset.apps/es-cluster 3/3 22h
statefulset.apps/kafka 3/3 101s
statefulset.apps/zk 3/3 22h
[root@k8s-master01 kafka]# kubectl get pvc -n kube-ops
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-es-cluster-0 Bound pvc-d2f4c2e8-6f08-4155-ba51-8cbd82e9817a 2Gi RWO es-data-db 23h
data-es-cluster-1 Bound pvc-28a9ca78-eef1-4192-8f76-8cfc6c2d46cd 2Gi RWO es-data-db 23h
data-es-cluster-2 Bound pvc-10e69f7c-1233-4c1e-9cd0-8b453d934786 2Gi RWO es-data-db 23h
data-kafka-0 Bound pvc-dd35b192-7fdf-44f0-a9d3-b91f098ef541 10Gi RWO kafka-data-db 99m
data-kafka-1 Bound pvc-58b1f508-45ef-4730-8686-d24e9a25fc99 10Gi RWO kafka-data-db 83m
data-kafka-2 Bound pvc-c2a96eae-a1dc-462a-a069-d3af1f1bebdf 10Gi RWO kafka-data-db 83m
datadir-zk-0 Bound pvc-cd6f407e-d782-4944-8d79-ade8c386b9ad 1Gi RWO zk-data-db 23h
datadir-zk-1 Bound pvc-c4932edb-ff48-4e60-ad16-d8141e1daa98 1Gi RWO zk-data-db 23h
datadir-zk-2 Bound pvc-4a48cc44-ad9f-41f1-a499-9be1cf69b111 1Gi RWO zk-data-db 23h
检测状态
相关命令参数使用请参考:
附:强制删除
Topic,可参考:Kafka强制删除Topic
PS:以下操作打开2个终端窗口,进入两个不同Kafka的Pod:【kafka-0、kafka-1】,进行测试集群连通性
创建Topic
kafka-0:负责创建topic并写入内容
[root@k8s-master01 kafka]# kubectl exec -it -n kube-ops kafka-0 -- bash
[root@kafka-0 kafka]# cd /opt/kafka/bin/
[root@kafka-0 bin]# ./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic Peng
接收Topic消息
kafka-1:接收kafka-0写入的消息
# kafka-1等待接收消息
[root@k8s-master01 es]# kubectl exec -it -n kube-ops kafka-1 -- bash
[root@kafka-1 kafka]# cd /opt/kafka/bin/
[root@kafka-1 bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Peng
# kafka-0写入内容
[root@kafka-0 bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic Peng
>Hello!
>How Are You?
# kafka-1已收到消息
[root@kafka-1 bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Peng
Hello!
How Are You?
检测集群连通性
Kafka
相关命令参数使用请参考:
附:强制删除
Topic,可参考:Kafka强制删除Topic
PS:以下操作打开2个终端窗口,进入两个不同Kafka的Pod,进行测试集群连通性
创建Topic
终端
1:负责创建Topic,并写入内容
# 创建topic
[root@k8s-master01 zookeeper-kafka]# kubectl exec -it -n zookeeper-kafka kafka-0 -- bash
I have no name!@kafka-0:/$ /opt/kafka/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic Peng
Created topic Peng.
# 查看已创建topic列表
I have no name!@kafka-0:/$ /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
Peng
__consumer_offsets
heima
mytopic
testtopic
接收Topic消息
终端
2:接收终端1输入的消息内容(直接进入kafka-1或kafka-2来测试)
# 终端2:进入kafka-1,打开topic等待接收消息
[root@k8s-master01 tmp]# kubectl exec -it -n zookeeper-kafka kafka-1 -- bash
I have no name!@kafka-1:/$ /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Peng
# 终端1:进入kafka-0发送消息到topic
[root@k8s-master01 zookeeper-kafka]# kubectl exec -it -n zookeeper-kafka kafka-0 -- bash
I have no name!@kafka-0:/$ /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Peng
> Hello, I'm Peng!
>Buy!
>
# 终端2:此时,已接收到来自Kafka-0的消息输入!
[root@k8s-master01 tmp]# kubectl exec -it -n zookeeper-kafka kafka-1 -- bash
I have no name!@kafka-1:/$ /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Peng
Hello, I'm Peng!
Buy!
Zookeeper
查看刚创建的
Topic:Peng是否存在,若存在,则证明Zookeeper集群正常,反之亦然~
# zookeeper-0
[root@k8s-master02 ~]# kubectl exec -it -n zookeeper-kafka zookeeper-0 -- bash
I have no name!@zookeeper-0:/$ zkCli.sh -server localhost
[zk: localhost(CONNECTED) 0] ls /brokers/topics
[Peng, __consumer_offsets, heima, mytopic, testtopic]
# zookeeper-1
[root@k8s-master02 ~]# kubectl exec -it -n zookeeper-kafka zookeeper-1 -- bash
I have no name!@zookeeper-1:/$ zkCli.sh -server localhost
[zk: localhost(CONNECTED) 0] ls /brokers/topics
[Peng, __consumer_offsets, heima, mytopic, testtopic]
# zookeeper-2
[root@k8s-master02 ~]# kubectl exec -it -n zookeeper-kafka zookeeper-2 -- bash
I have no name!@zookeeper-2:/$ zkCli.sh -server localhost
[zk: localhost(CONNECTED) 1] ls /brokers/topics
[Peng, __consumer_offsets, heima, mytopic, testtopic]
ELFK
本文采用配置清单方式部署
ELFK以下是配置清单,分别为
es和logstash做了动态持久化,修改为你的命名空间后可复制部署~
Elasticsearch
目录清单结构
[root@k8s-master01 es]# tree
├── 1.es-svc.yaml
├── 2.es-pvc.yaml
└── 3.es-statefulset.yaml
配置清单
1.es-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: kube-ops
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- name: rest
port: 9200
- name: inter-node
port: 9300
2.es-pvc.yaml
需部署
NFS动态存储后,才可创建此配置清单,可参考:K8s-nfs-client动态存储部署部署后会启动
3个Pod,陆续创建并自动绑定3个PVC
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: es-data-db
provisioner: cluster.local/nfs-client-nfs-client-provisioner
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
3.es-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-ops
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 1000m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
annotations:
volume.beta.kubernetes.io/storage-class: es-data-db
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: es-data-db
resources:
requests:
storage: 2Gi
部署
[root@k8s-master01 es]# kubectl apply -f ./
service/elasticsearch created
storageclass.storage.k8s.io/es-data-db created
statefulset.apps/es-cluster created
[root@k8s-master01 es]# kubectl get all -n kube-ops
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 0 11m
pod/es-cluster-1 1/1 Running 0 11m
pod/es-cluster-2 1/1 Running 0 10m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 113m
NAME READY AGE
statefulset.apps/es-cluster 3/3 11m
[root@k8s-master01 es]# kubectl get pvc -n kube-ops
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-es-cluster-0 Bound pvc-d2f4c2e8-6f08-4155-ba51-8cbd82e9817a 2Gi RWO es-data-db 23m
data-es-cluster-1 Bound pvc-28a9ca78-eef1-4192-8f76-8cfc6c2d46cd 2Gi RWO es-data-db 22m
data-es-cluster-2 Bound pvc-10e69f7c-1233-4c1e-9cd0-8b453d934786 2Gi RWO es-data-db 21m
检查状态
# 检查连接,如下为正常
[root@k8s-master01 es]# kubectl port-forward es-cluster-0 9200:9200 -n kube-ops
Forwarding from 127.0.0.1:9200 -> 9200
Forwarding from [::1]:9200 -> 9200
^C
# 检查集群连接状态,如下正常
[root@k8s-master01 es]# kubectl exec -it -n kube-ops es-cluster-0 -- bash
[root@es-cluster-0 elasticsearch]# curl http://localhost:9200/_cluster/health?pretty=true
{
"cluster_name" : "k8s-logs",
"status" : "green", # 状态为green
"timed_out" : false,
"number_of_nodes" : 3, # 节点为3
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# 检查连接地址,如下正常
[root@es-cluster-0 elasticsearch]# curl http://localhost:9200/_cluster/state?pretty | grep transport_address
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1395 100 1395 0 0 143k 0 --:--:-- --:--:-- --:--:-- 151k
"transport_address" : "172.25.244.245:9300",
"transport_address" : "172.25.92.116:9300",
"transport_address" : "172.27.14.219:9300",
Kiban
kibana就是一个展示工具,故用Deployment部署即可
目录清单结构
[root@k8s-master01 kibana]# tree
.
├── 1.kibana-svc.yaml
└── 2.kibana-dep.yaml
配置清单
1.kibana-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-ops
labels:
app: kibana
spec:
ports:
- port: 5601
tatargetPort: 30561
type: NodePort
selector:
app: kibana
2.kibana-dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-ops
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana-oss:6.4.3 # 7.12.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
部署
访问地址:
172.23.0.244:30561
[root@k8s-master01 kibana]# kubectl apply -f ./
service/kibana created
deployment.apps/kibana created
[root@k8s-master01 kibana]# kubectl get all -n kube-ops
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 0 26m
pod/es-cluster-1 1/1 Running 0 25m
pod/es-cluster-2 1/1 Running 0 25m
pod/kibana-685bd77cb8-lpr7b 1/1 Running 0 53s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 127m
service/kibana NodePort 192.168.53.88 <none> 5601:30561/TCP 53s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kibana 1/1 1 1 53s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kibana-685bd77cb8 1 1 1 53s
NAME READY AGE
statefulset.apps/es-cluster 3/3 26m
Kibana添加索引
172.23.0.244:30561进入
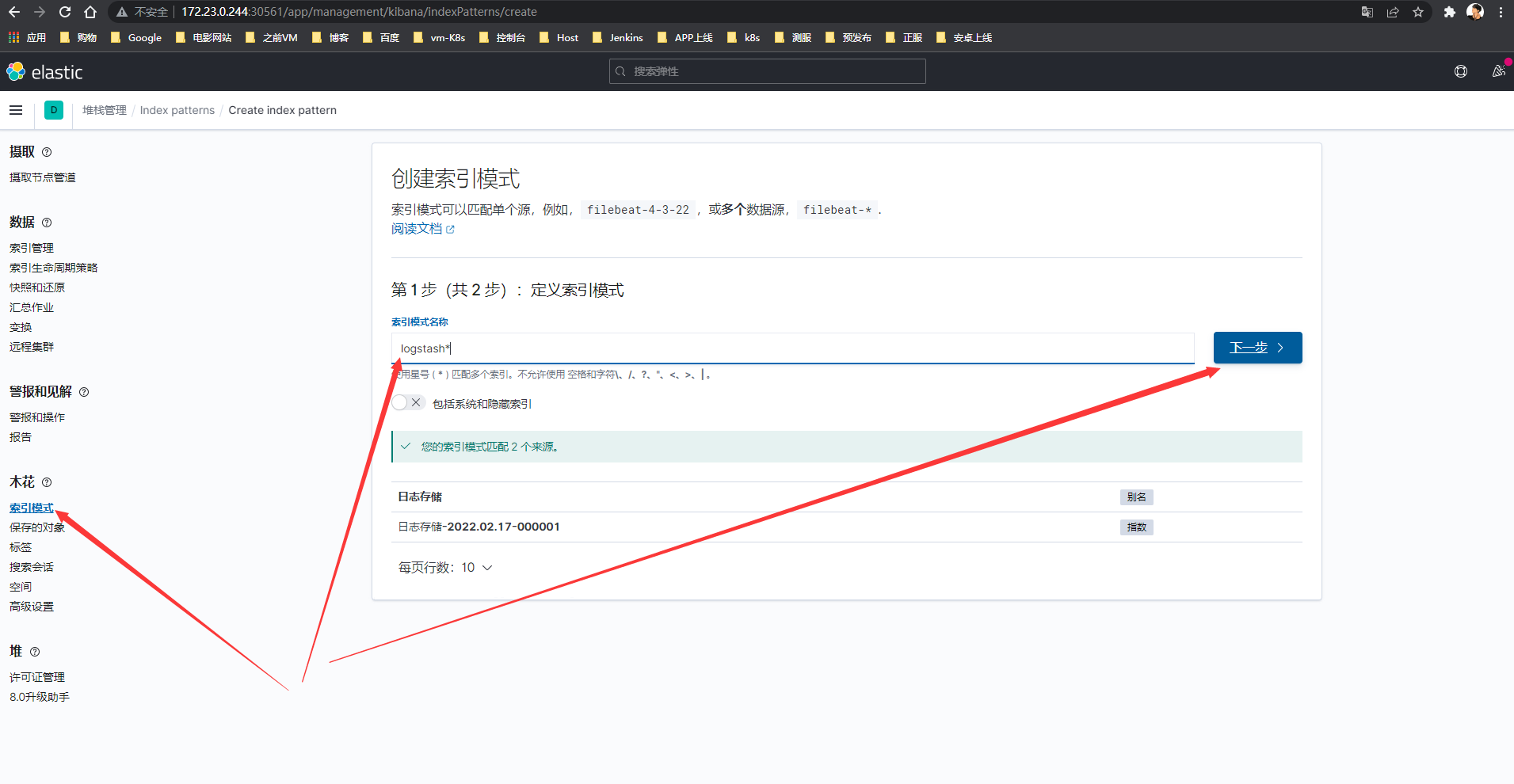
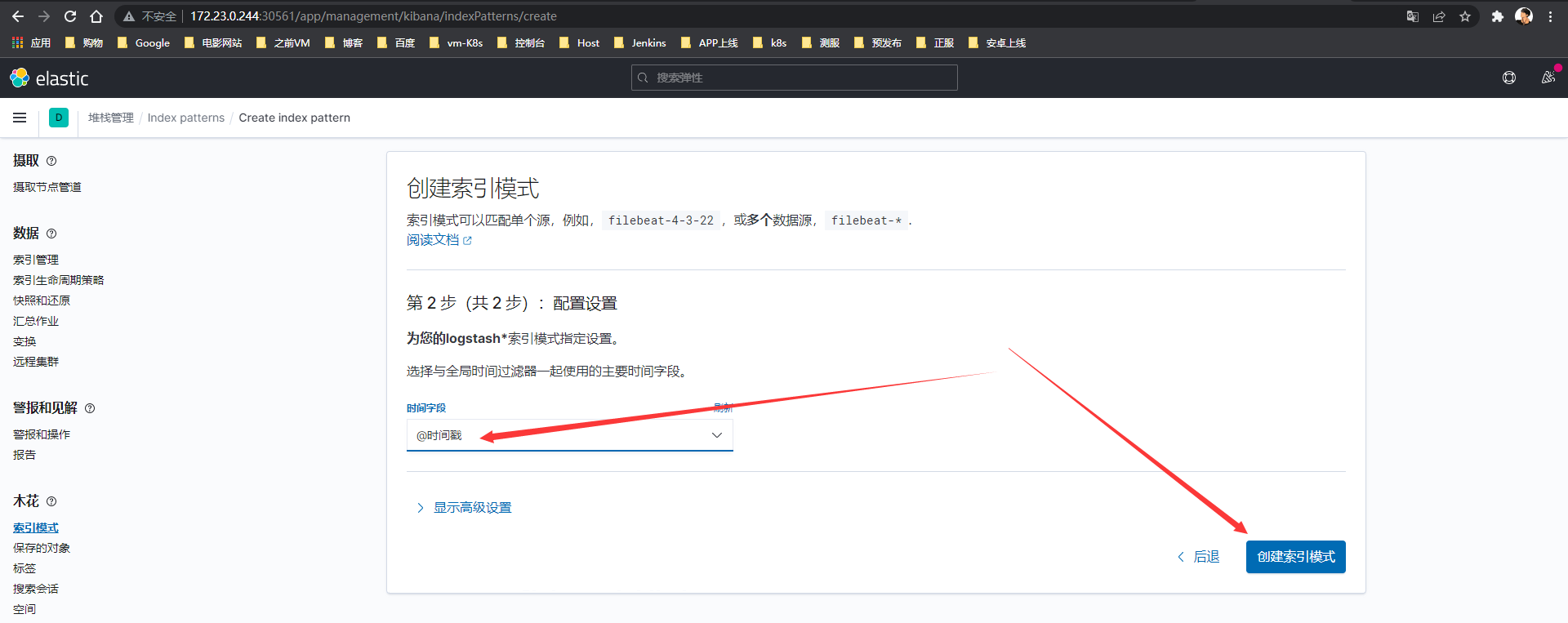
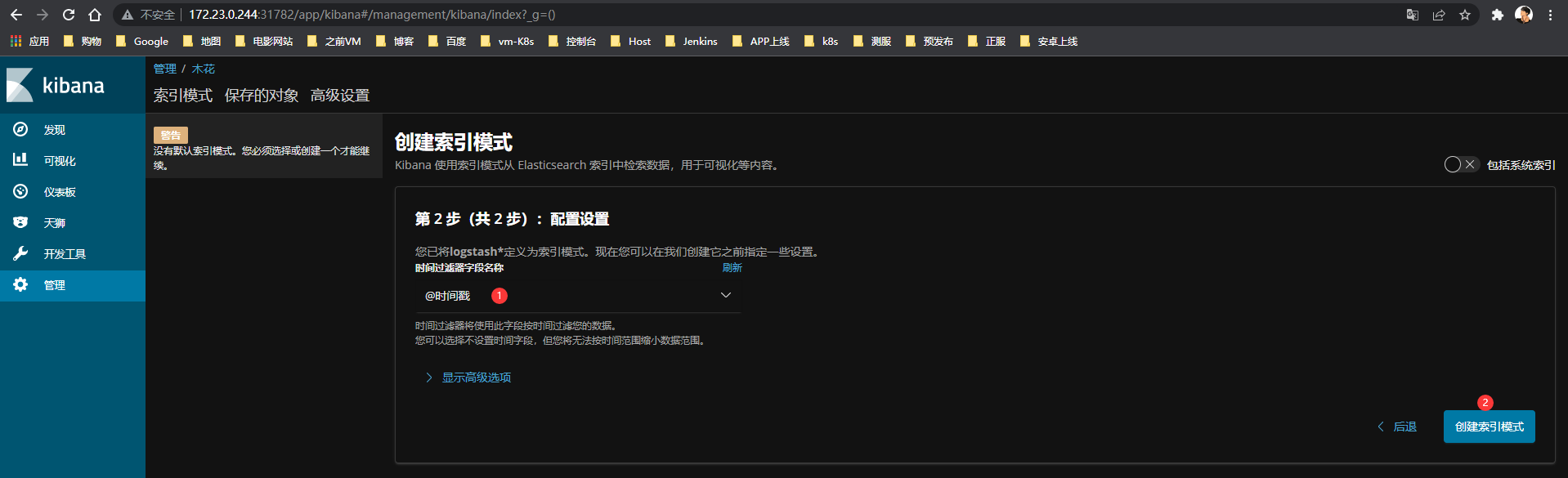
Kibana控制台-左上角菜单-发现-创建索引模式(输入logstash*)-下一步-选择时间戳-创建索引模式
-
创建系统和隐藏索引
勾选:
包括系统和隐藏索引
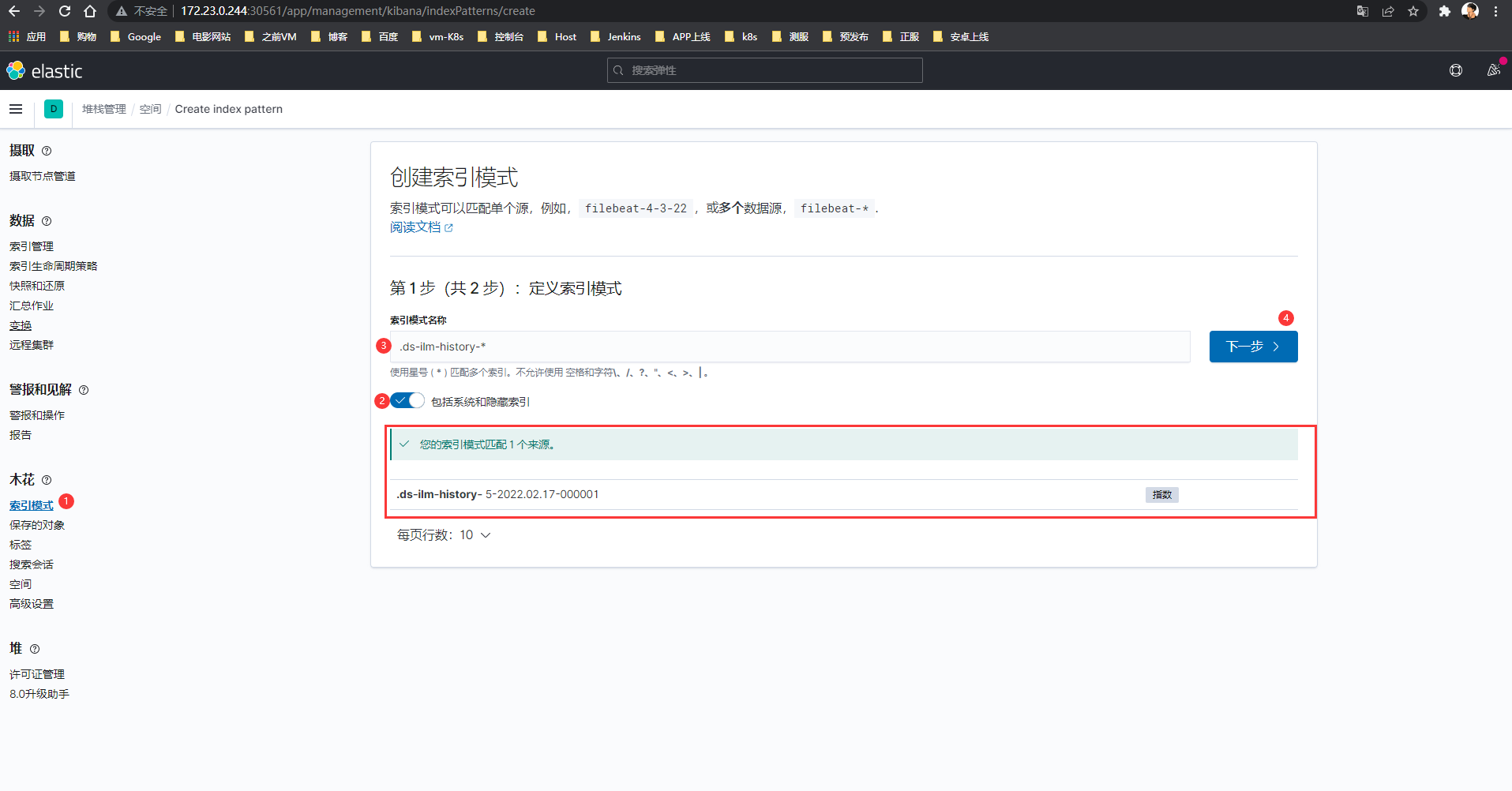
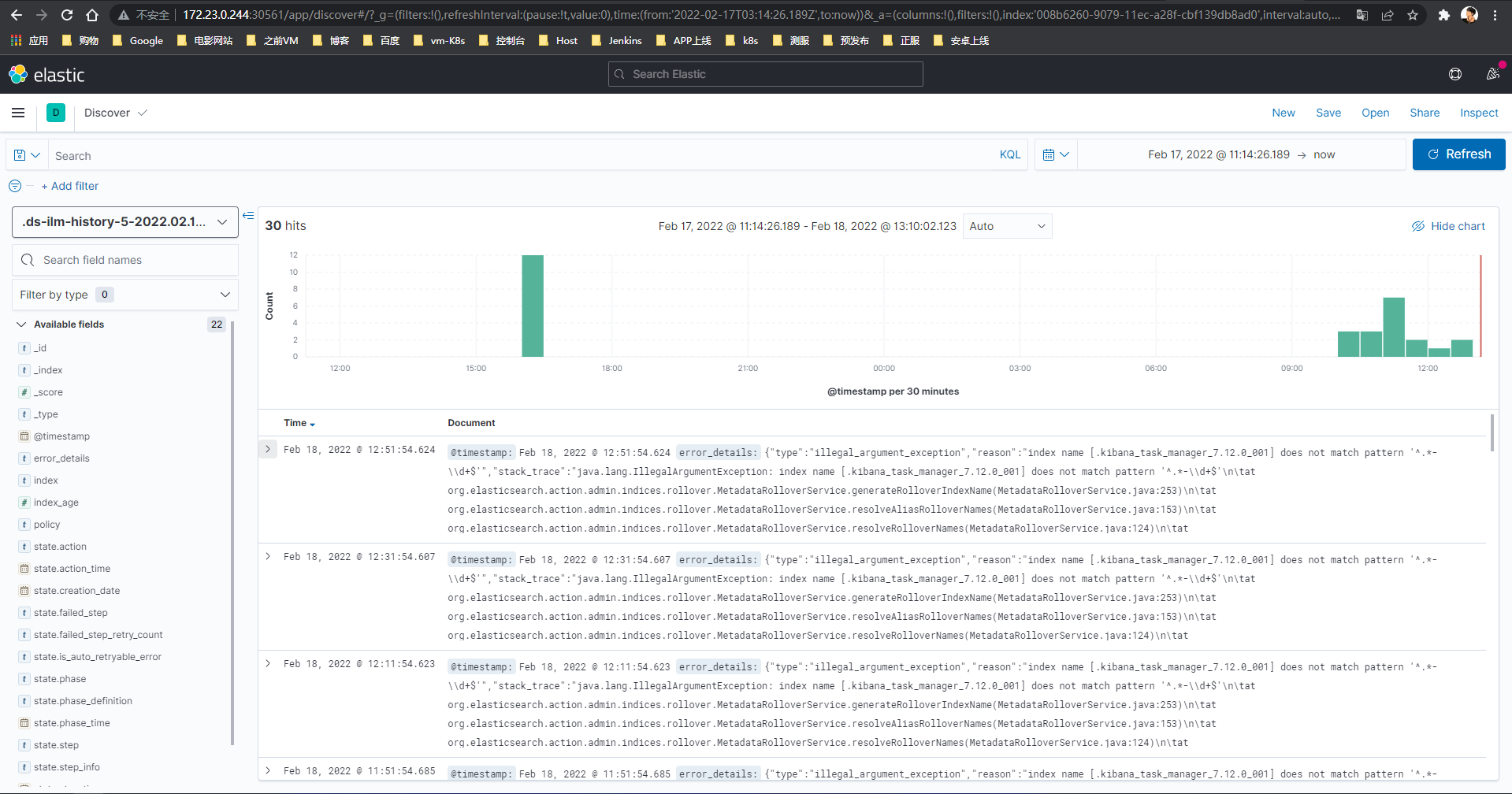
支持
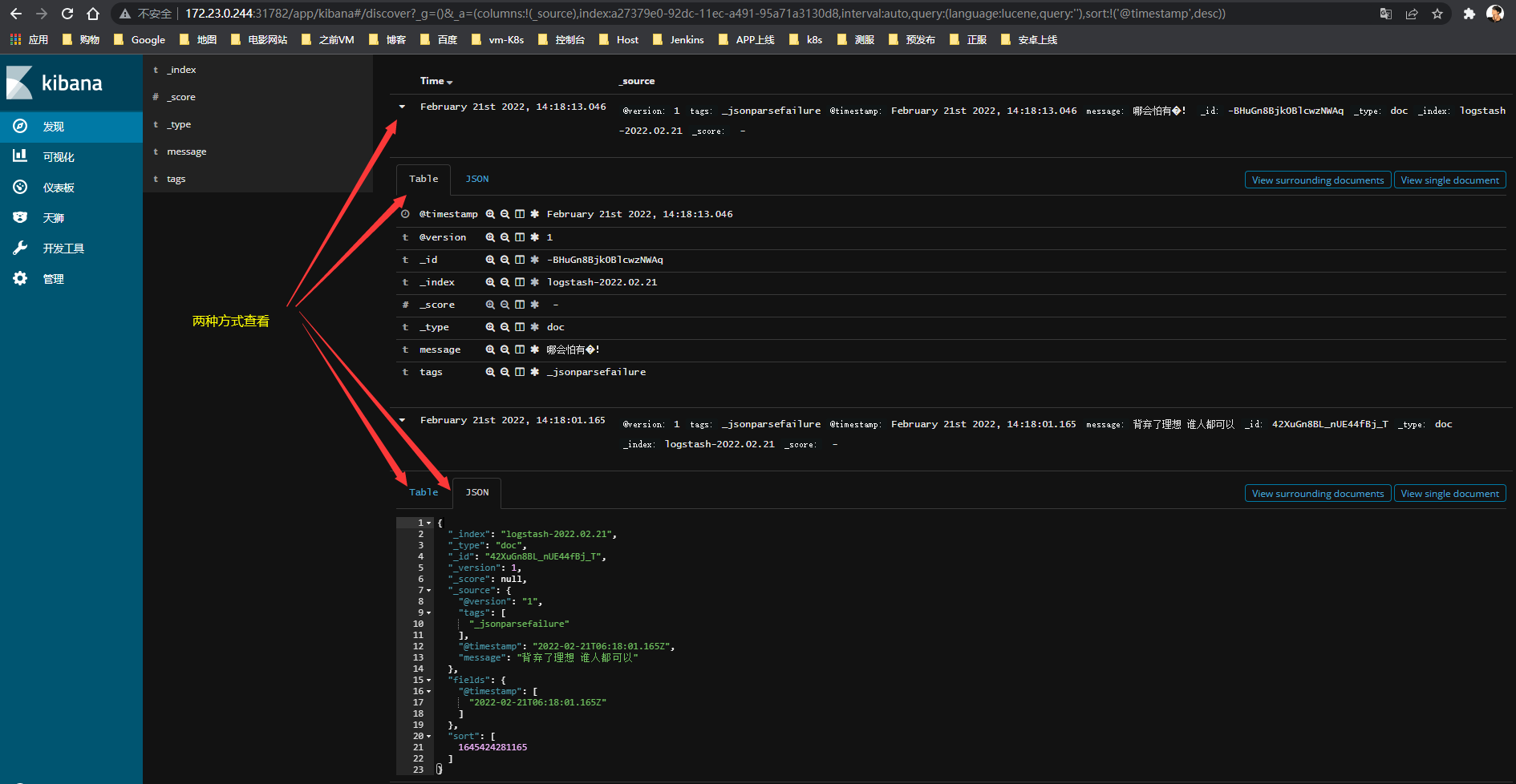
Table|Json两种查看模式
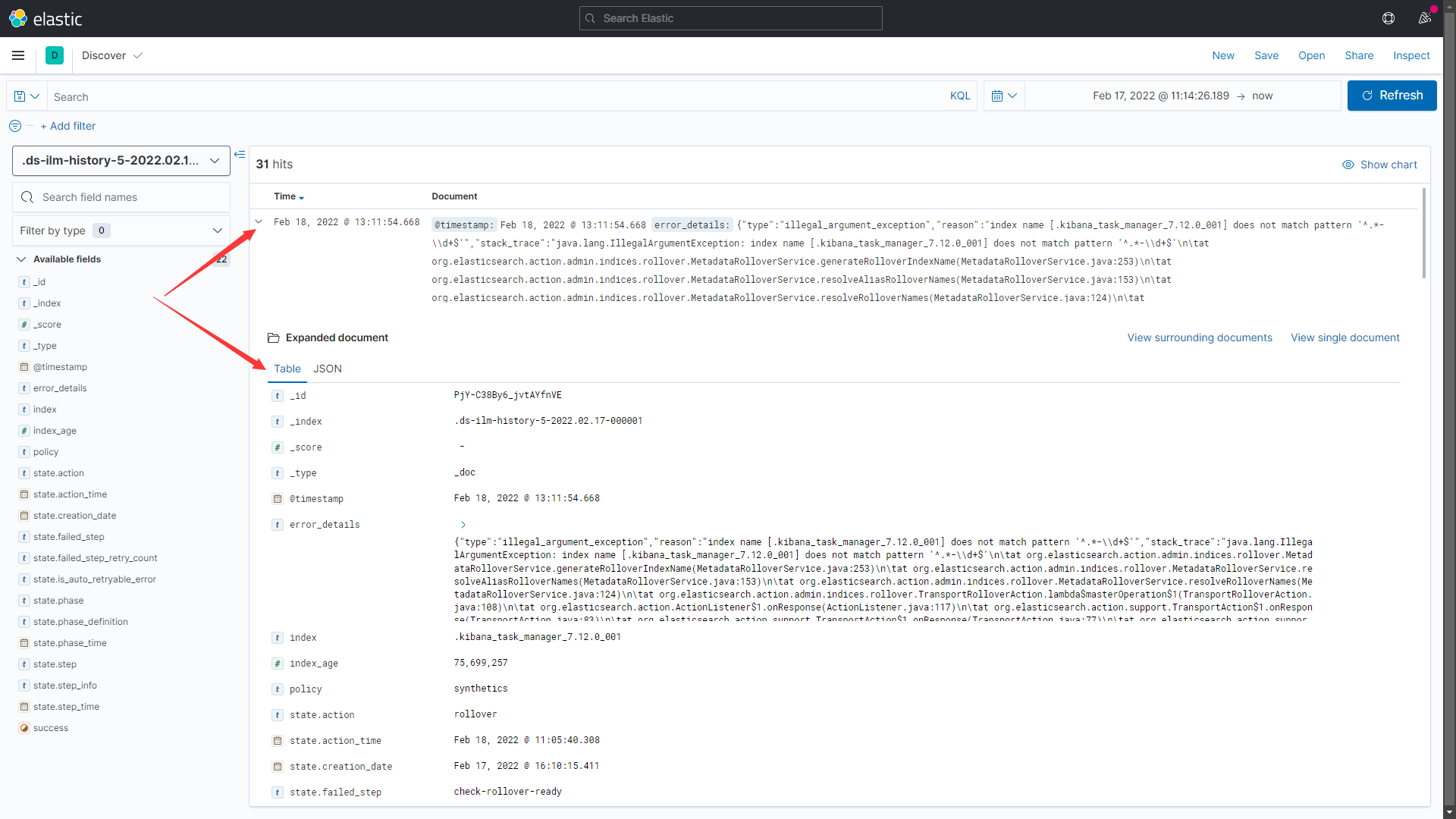
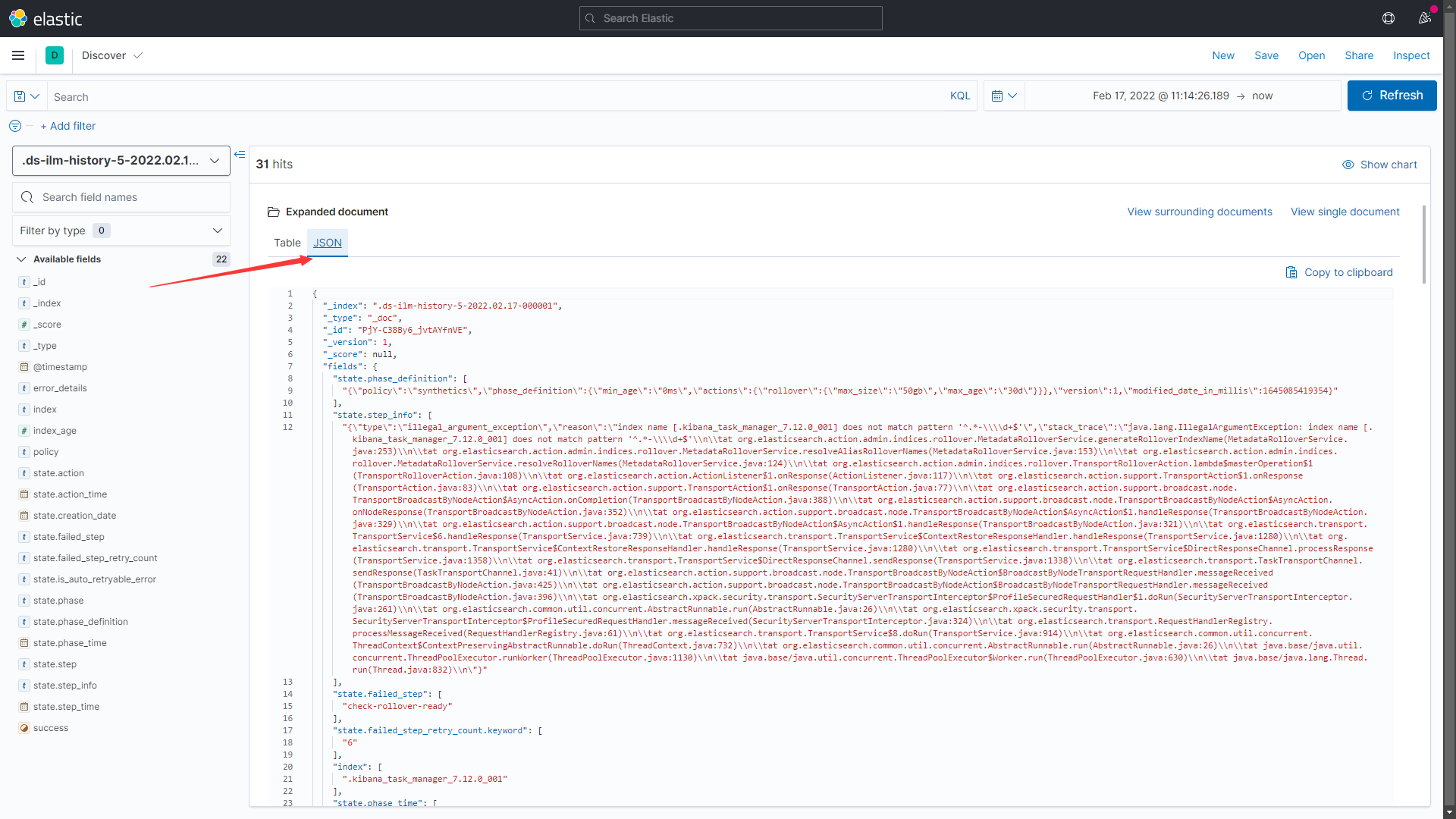
- 创建
Logstash索引
Logstash
从
Kafka中读取数据,传递给Elasticsearch
目录清单结构
[root@k8s-master01 logstash]# tree
.
├── 1.configmap.yaml
├── 2.deploy.yaml
└── dockerfile
├── Dockerfile
├── jdk-8u192-linux-x64.tar.gz
└── logstash-7.1.1.tar.gz
制作镜像
准备目录文件
cd logstash
mkdir dockerfile
cd dockerfile
cp ../../../kafka/dockerfile/jdk-8u192-linux-x64.tar.gz .
# 下载logstash、jdk包构建到镜像内,也可用kafka的Java包,Java包用kafka的即可
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.1.1.tar.gz
wget http://download.oracle.com/otn/java/jdk/8u192-b12/750e1c8617c5452694857ad95c3ee230/jdk-8u192-linux-x64.tar.gz
Dockerfile
FROM centos:centos7
LABEL "auth"="rookieops" \
"mail"="rookieops@163.com"
ENV TIME_ZONE Asia/Shanghai
# install JAVA
ADD jdk-8u131-linux-x64.tar.gz /opt/
ENV JAVA_HOME /opt/jdk1.8.0_131
ENV PATH ${JAVA_HOME}/bin:${PATH}
# install logstash
ADD logstash-7.1.1.tar.gz /opt/
RUN mv /opt/logstash-7.1.1 /opt/logstash
构建镜像
docker build -t 18954354671/logstash-7.1.1:v1 .
docker tag 18954354671/logstash-7.1.1:v1 harbor.peng.cn/base/logstash-7.1.1:latest
docker push 18954354671/logstash-7.1.1:v1
docker push harbor.peng.cn/base/logstash-7.1.1:latest
配置清单
1.configmap.yaml
输出配置格式可参考:数据采集层 并搜索:【
bootstrap_servers =>】修改项:
topics => ["Peng"]监控主题,多个则【topics => ["Peng","test"]】
index => "logstash-%{+YYYY.MM.dd}"索引名称,可定义为有标示性名称:【logstash-peng%{+YYYY.MM.dd}】
PS:topics名称可用大小写,index索引必须为小写,否则不识别,创建不了索引
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-k8s-config
namespace: kube-ops
data:
containers.conf: |
input {
kafka {
codec => "json"
topics => ["Peng"]
bootstrap_servers => ["kafka-0.kafka-svc.kube-ops:9092, kafka-1.kafka-svc.kube-ops:9092, kafka-2.kafka-svc.kube-ops:9092"]
group_id => "logstash-g1"
}
}
output {
elasticsearch {
hosts => ["es-cluster-0.elasticsearch.kube-ops:9200", "es-cluster-1.elasticsearch.kube-ops:9200", "es-cluster-2.elasticsearch.kube-ops:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
2.deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash
namespace: kube-ops
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
nodeName: k8s-node01
containers:
- name: logstash
image: 18954354671/logstash-7.1.1:v1
volumeMounts:
- name: config
mountPath: /opt/logstash/config/containers.conf
subPath: containers.conf
command:
- "/bin/sh"
- "-c"
- "/opt/logstash/bin/logstash -f /opt/logstash/config/containers.conf"
volumes:
- name: config
configMap:
name: logstash-k8s-config
部署
[root@k8s-master01 logstash]# kubectl apply -f ./
configmap/logstash-k8s-config created
deployment.apps/logstash created
[root@k8s-master01 logstash]# kubectl get configmap,pod -n kube-ops | grep logstash
configmap/logstash-k8s-config 1 18m
pod/logstash-696f7fbff6-gcrkn 1/1 Running 0 79s
Fluentd
Fluentd是一个高效的日志聚合器,是用Ruby编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对Fluentd来说不够丰富,所以整体来说,Fluentd更加成熟,使用更加广泛,所以我们这里也同样使用Fluentd来作为日志收集工具。
目录清单结构
[root@k8s-master01 fluentd]# tree
.
├── 1.configmap.yaml
└── 2.daemonset.yaml
制作镜像
先起一个
fluentd容器,然后安装插件,然后docker commit一下,再推送到自己的镜像仓库,最后部署清单
docker run -it registry.cn-hangzhou.aliyuncs.com/rookieops/fluentd-elasticsearch:v2.0.4 bash
gem install fluent-plugin-kafka --no-document
docker commit 53cac7f8fdb0 harbor.peng.cn/fluentd-elasticsearch:v2.0.4
docker tag harbor.peng.cn/fluentd-elasticsearch:v2.0.4 harbor.peng.cn/base/fluentd-elasticsearch:v2.0.4
docker push 18954354671/fluentd-elasticsearc:v2.0.4
docker push harbor.peng.cn/base/fluentd-elasticsearch:v2.0.4
配置清单
1.configmap.yaml
修改项:
default_topic默认主题
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: kube-ops
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id kafka
@type kafka2
@log_level info
include_tag_key true
brokers kafka-0.kafka-svc.kube-ops:9092,kafka-1.kafka-svc.kube-ops:9092,kafka-2.kafka-svc.kube-ops:9092
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
default_topic Peng
# producer settings
required_acks -1
compression_codec gzip
</match>
2.daemonset.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: kube-ops
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: kube-ops
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: kube-ops
labels:
k8s-app: fluentd-es
version: v2.0.4
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.4
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.4
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: 18954354671/fluentd-elasticsearc:v2.0.4
#image: registry.cn-hangzhou.aliyuncs.com/rookieops/fluentd-elasticsearch:v2.0.4
command:
- "/bin/sh"
- "-c"
- "/run.sh $FLUENTD_ARGS"
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-config
部署
[root@k8s-master01 fluentd]# kubectl apply -f ./
configmap/fluentd-config created
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
daemonset.apps/fluentd-es created
# 查看部署
[root@k8s-master01 fluentd]# kubectl get -f 1.configmap.yaml
NAME DATA AGE
fluentd-config 5 3h10m
[root@k8s-master01 fluentd]# kubectl get -f 2.daemonset.yaml
NAME SECRETS AGE
serviceaccount/fluentd-es 1 3h10m
NAME CREATED AT
clusterrole.rbac.authorization.k8s.io/fluentd-es 2022-02-21T02:43:58Z
NAME ROLE AGE
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es ClusterRole/fluentd-es 3h10m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/fluentd-es 0 0 0 0 0 beta.kubernetes.io/fluentd-ds-ready=true 3h10m
查看所有部署
至此,服务都已搭建完毕,查看所有部署内容
[root@k8s-master01 fluentd]# kubectl get all -n kube-ops
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 1 46h
pod/es-cluster-1 1/1 Running 1 46h
pod/es-cluster-2 1/1 Running 1 46h
pod/kafka-0 1/1 Running 4 45h
pod/kafka-1 1/1 Running 4 45h
pod/kafka-2 1/1 Running 4 45h
pod/kibana-6b869f56c5-7b52v 1/1 Running 1 45h
pod/logstash-696f7fbff6-hm74j 1/1 Running 0 11m
pod/zk-0 1/1 Running 3 46h
pod/zk-1 1/1 Running 2 46h
pod/zk-2 1/1 Running 1 46h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 2d21h
service/kafka-svc ClusterIP None <none> 9092/TCP 47h
service/kibana NodePort 192.168.53.88 <none> 5601:31782/TCP 2d21h
service/zk-svc ClusterIP None <none> 2888/TCP,3888/TCP 2d21h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/fluentd-es 0 0 0 0 0 beta.kubernetes.io/fluentd-ds-ready=true 3h15m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kibana 1/1 1 1 46h
deployment.apps/logstash 1/1 1 1 44h
NAME DESIRED CURRENT READY AGE
replicaset.apps/kibana-6b869f56c5 1 1 1 46h
replicaset.apps/logstash-696f7fbff6 1 1 1 44h
NAME READY AGE
statefulset.apps/es-cluster 3/3 46h
statefulset.apps/kafka 3/3 45h
statefulset.apps/zk 3/3 46h
[root@k8s-master01 fluentd]# kubectl get pvc -n kube-ops
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-es-cluster-0 Bound pvc-d2f4c2e8-6f08-4155-ba51-8cbd82e9817a 2Gi RWO es-data-db 2d21h
data-es-cluster-1 Bound pvc-28a9ca78-eef1-4192-8f76-8cfc6c2d46cd 2Gi RWO es-data-db 2d21h
data-es-cluster-2 Bound pvc-10e69f7c-1233-4c1e-9cd0-8b453d934786 2Gi RWO es-data-db 2d21h
data-kafka-0 Bound pvc-dd35b192-7fdf-44f0-a9d3-b91f098ef541 10Gi RWO kafka-data-db 47h
data-kafka-1 Bound pvc-58b1f508-45ef-4730-8686-d24e9a25fc99 10Gi RWO kafka-data-db 46h
data-kafka-2 Bound pvc-c2a96eae-a1dc-462a-a069-d3af1f1bebdf 10Gi RWO kafka-data-db 46h
datadir-zk-0 Bound pvc-cd6f407e-d782-4944-8d79-ade8c386b9ad 1Gi RWO zk-data-db 2d21h
datadir-zk-1 Bound pvc-c4932edb-ff48-4e60-ad16-d8141e1daa98 1Gi RWO zk-data-db 2d21h
datadir-zk-2 Bound pvc-4a48cc44-ad9f-41f1-a499-9be1cf69b111 1Gi RWO zk-data-db 2d21h
制作并展示数据
打开
Kibana的Web页面创建索引模式,并打开3个终端窗口,进行以下操作:
Kibana:创建Logstash索引模式进行数据监听
TTY1:实时监控Logstash容器日志
TTY2:实时接收Kafka容器内Peng的Topic消息
TTY3:进行数据插入
准备监听数据
Kibana监听
创建索引模式并监听数据
Kibana准备实时监听插入的数据日志
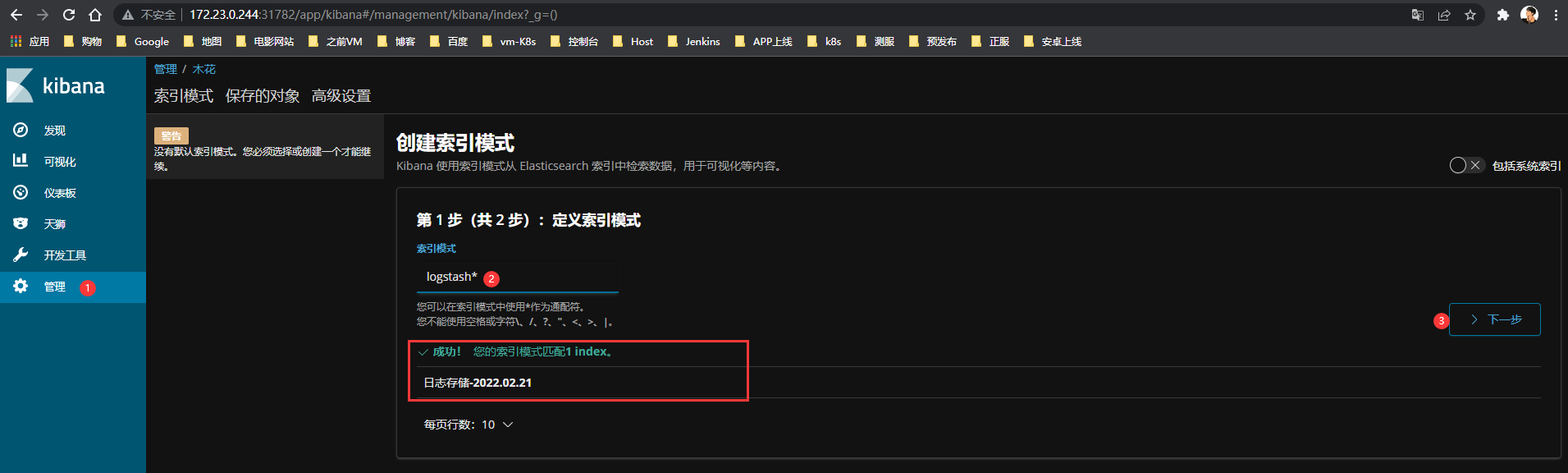
Logstash监听
TTY1
Logstash准备实时监听插入的日志数据
[root@k8s-master01 fluentd]# kubectl logs -f -n kube-ops logstash-696f7fbff6-hm74j
[2022-02-21T05:49:16,810][INFO ][logstash.javapipeline ] Pipeline started {"pipeline.id"=>"main"}
[2022-02-21T05:49:17,083][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2022-02-21T05:49:17,147][INFO ][org.apache.kafka.clients.consumer.ConsumerConfig] ConsumerConfig values:
···
Kafka监听
TTY2
Kafka准备实时监听插入的数据日志
[root@k8s-master02 ~]# kubectl exec -it -n kube-ops kafka-0 -- bash
[root@kafka-0 kafka]# /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Peng
插入数据
TTY3进行数据插入
[root@k8s-master03 ~]# kubectl exec -it -n kube-ops kafka-1 -- bash
[root@kafka-1 kafka]# /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Peng
>《海阔天空》 原唱:beyond 发行日期:2008-03-11
今天我 寒夜里看雪飘过
怀着冷却了的心窝漂远方
风雨里追赶 雾里分不清影踪
天空海阔你与我
可会变(谁没在变)
多少次 迎着冷眼与嘲笑
从没有放弃过心中的理想
一刹那恍惚 若有所失的感觉
不知不觉已变淡
心里爱(谁明白我)
原谅我这一生不羁放纵爱自由
也会怕有一天会跌倒
背弃了理想 谁人都可以
哪会怕有一天只你共我!
展示查看数据
日志流向:
Kafka写入>Topic>Fluentd>Logstash>Elasticsearch>Kibana
Kafka展示
已获取到数据
[root@k8s-master02 ~]# kubectl exec -it -n kube-ops kafka-0 -- bash
[root@kafka-0 kafka]# /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Peng
《海阔天空》 原唱:beyond 发行日期:2008-03-11
今天我 寒夜里看雪飘过
怀着冷却了的心窝漂远方
风雨里追赶 雾里分不清影踪
天空海阔你与我
可会变(谁没在变)
多少次 迎着冷眼与嘲笑
从没有放弃过心中的理想
一刹那恍惚 若有所失的感觉
不知不觉已变淡
心里爱(谁明白我)
原谅我这一生不羁放纵爱自由
也会怕有一天会跌倒
背弃了理想 谁人都可以
哪会怕有�!
Logstash展示
已获取到数据
[root@k8s-master01 fluentd]# kubectl logs -f -n kube-ops logstash-696f7fbff6-hm74j
[2022-02-21T06:18:01,123][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unexpected character ('ã' (code 12298 / 0x300a)): expected a valid value (number, String, array, object, 'true', 'false' or 'null')
at [Source: (String)"ãæµ·é天空ã åå±:beyond åè¡æ¥æ:2008-03-11"; line: 1, column: 2]>, :data=>"《海阔天空》 原唱:beyond 发行日期:2008-03-11"}
[2022-02-21T06:18:01,142][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'ä»å¤©æ': was expecting ('true', 'false' or 'null')
at [Source: (String)"ä»å¤©æ å¯å¤éçéªé£è¿"; line: 1, column: 4]>, :data=>"今天我 寒夜里看雪飘过"}
[2022-02-21T06:18:01,145][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'æçå·å´äºçå¿çªæ¼è¿æ¹': was expecting ('true', 'false' or 'null')
at [Source: (String)"æçå·å´äºçå¿çªæ¼è¿æ¹"; line: 1, column: 23]>, :data=>"怀着冷却了的心窝漂远方"}
[2022-02-21T06:18:01,146][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'é£é¨é追赶': was expecting ('true', 'false' or 'null')
at [Source: (String)"é£é¨é追赶 é¾éåä¸æ¸å½±è¸ª"; line: 1, column: 6]>, :data=>"风雨里追赶 雾里分不清影踪"}
[2022-02-21T06:18:01,148][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token '天空海éä½ ä¸æ': was expecting ('true', 'false' or 'null')
at [Source: (String)"天空海éä½ ä¸æ"; line: 1, column: 15]>, :data=>"天空海阔你与我"}
[2022-02-21T06:18:01,149][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'å¯ä¼å': was expecting ('true', 'false' or 'null')
at [Source: (String)"å¯ä¼åï¼è°æ²¡å¨åï¼"; line: 1, column: 4]>, :data=>"可会变(谁没在变)"}
[2022-02-21T06:18:01,156][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'å¤å°æ¬¡': was expecting ('true', 'false' or 'null')
at [Source: (String)"å¤å°æ¬¡ è¿çå·ç¼ä¸å²ç¬"; line: 1, column: 4]>, :data=>"多少次 迎着冷眼与嘲笑"}
[2022-02-21T06:18:01,158][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'ä»æ²¡ææ¾å¼è¿å¿ä¸ççæ³': was expecting ('true', 'false' or 'null')
at [Source: (String)"ä»æ²¡ææ¾å¼è¿å¿ä¸ççæ³"; line: 1, column: 23]>, :data=>"从没有放弃过心中的理想"}
[2022-02-21T06:18:01,160][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'ä¸å¹é£ææ': was expecting ('true', 'false' or 'null')
at [Source: (String)"ä¸å¹é£ææ è¥ææ失çæè§"; line: 1, column: 6]>, :data=>"一刹那恍惚 若有所失的感觉"}
[2022-02-21T06:18:01,160][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'ä¸ç¥ä¸è§å·²åæ·¡': was expecting ('true', 'false' or 'null')
at [Source: (String)"ä¸ç¥ä¸è§å·²åæ·¡"; line: 1, column: 15]>, :data=>"不知不觉已变淡"}
[2022-02-21T06:18:01,162][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'å¿éç±': was expecting ('true', 'false' or 'null')
at [Source: (String)"å¿éç±ï¼è°æç½æï¼"; line: 1, column: 4]>, :data=>"心里爱(谁明白我)"}
[2022-02-21T06:18:01,163][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'åè°æè¿ä¸çä¸ç¾æ¾çºµç±èªç±': was expecting ('true', 'false' or 'null')
at [Source: (String)"åè°æè¿ä¸çä¸ç¾æ¾çºµç±èªç±"; line: 1, column: 27]>, :data=>"原谅我这一生不羁放纵爱自由"}
[2022-02-21T06:18:01,164][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'ä¹ä¼ææä¸å¤©ä¼è·å': was expecting ('true', 'false' or 'null')
at [Source: (String)"ä¹ä¼ææä¸å¤©ä¼è·å"; line: 1, column: 19]>, :data=>"也会怕有一天会跌倒"}
[2022-02-21T06:18:01,165][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'èå¼äºçæ³': was expecting ('true', 'false' or 'null')
at [Source: (String)"èå¼äºçæ³ è°äººé½å¯ä»¥"; line: 1, column: 6]>, :data=>"背弃了理想 谁人都可以"}
[2022-02-21T06:18:13,045][ERROR][logstash.codecs.json ] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token 'åªä¼ææ': was expecting ('true', 'false' or 'null')
at [Source: (String)"åªä¼ææ�ï¼"; line: 1, column: 5]>, :data=>"哪会怕有�!"}
Kibana展示
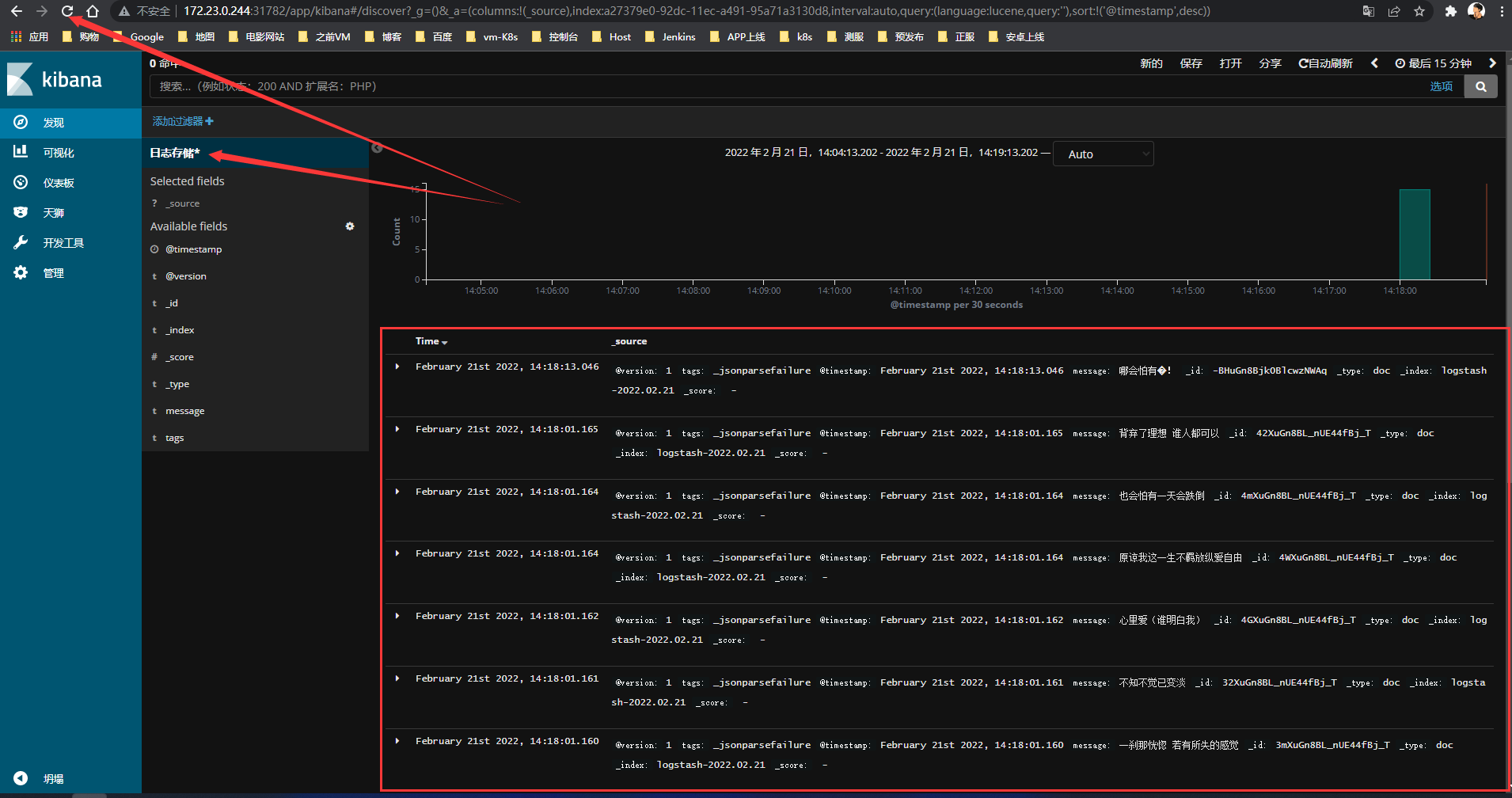
点击刚刚创建的索引,刷新浏览器页面,可以看到刚刚写入的日志数据
日志发现
开发工具
可通过开发工具对相关数据进行匹配
获取索引

查看所有数据
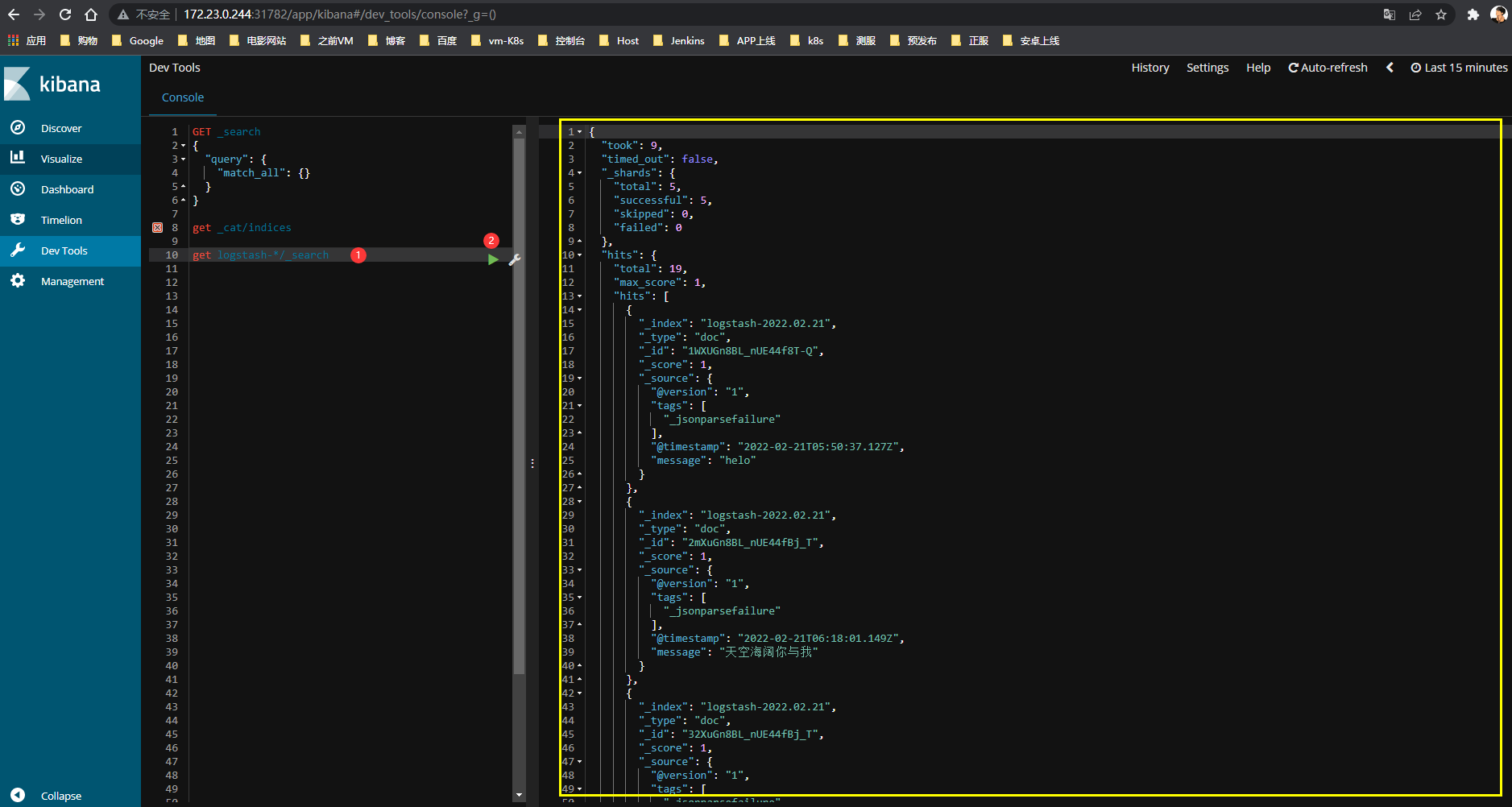
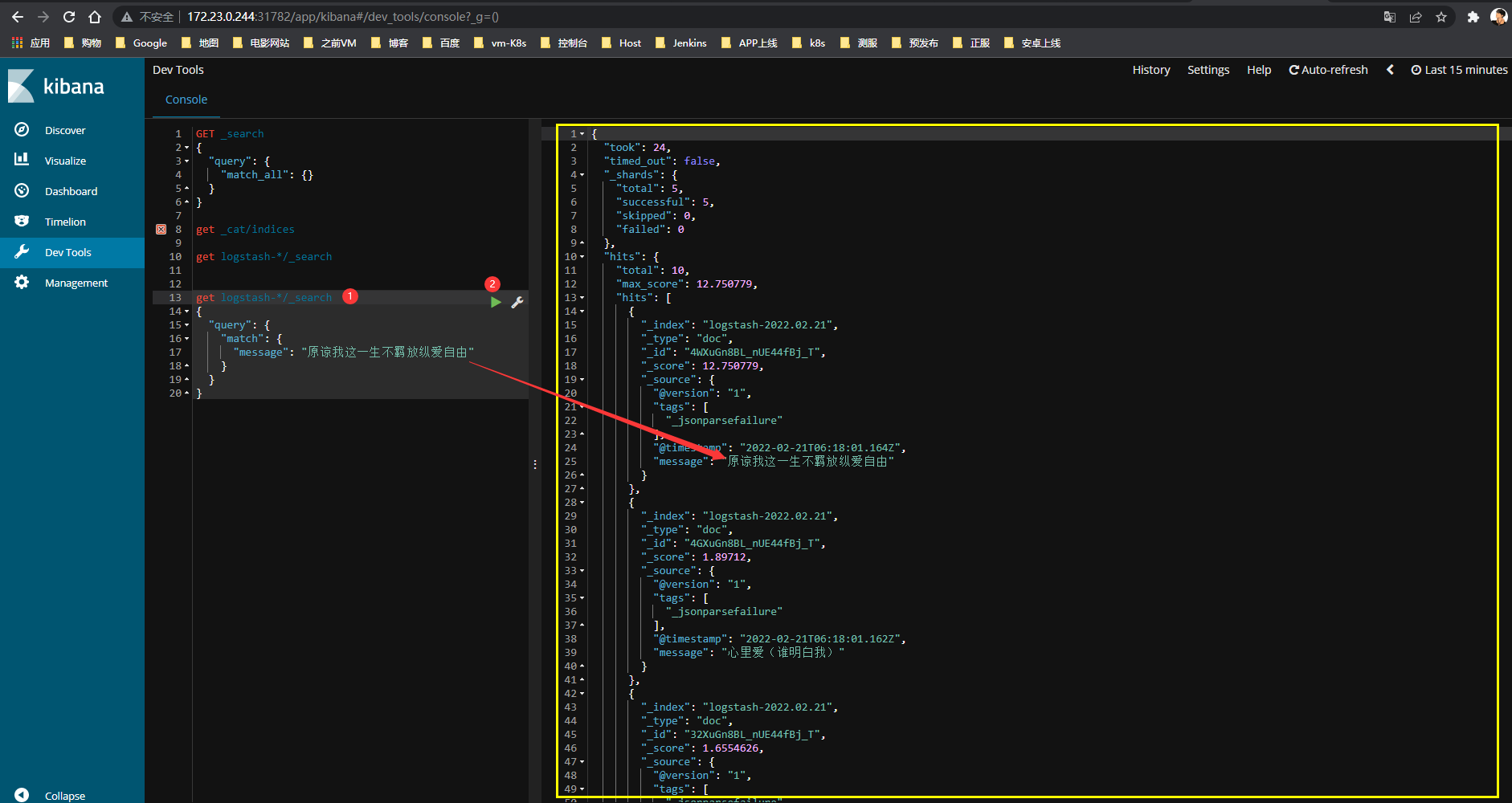
指定匹配数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号