MySQL-day15-增删改查实例实操
文章目录
一、介绍
MySQL数据操作: DML
- 在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括:
- 使用INSERT实现数据的插入
- UPDATE实现数据的更新
- 使用DELETE实现数据的删除
- 使用SELECT查询数据以及
二、插入数据INSERT
1. 插入完整数据(顺序插入)
语法一:
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n);
语法二:
INSERT INTO 表名 VALUES (值1,值2,值3…值n);
2. 指定字段插入数据
语法:
INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…);
3. 插入多条记录
语法:
INSERT INTO 表名 VALUES
(值1,值2,值3…值n),
(值1,值2,值3…值n),
(值1,值2,值3…值n);
4. 插入查询结果
语法:
INSERT INTO 表名(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2
WHERE …;
三、更新数据UPDATE
语法:
UPDATE 表名 SET
字段1=值1,
字段2=值2,
WHERE CONDITION;
示例:
UPDATE mysql.user SET password=password(‘123’)
where user=’root’ and host=’localhost’;
四、删除数据DELETE
语法:
DELETE FROM 表名
WHERE CONITION;
示例:
DELETE FROM mysql.user
WHERE password=’’;
练习:
更新MySQL root用户密码为mysql123
删除除从本地登录的root用户以外的所有用户
五、权限管理
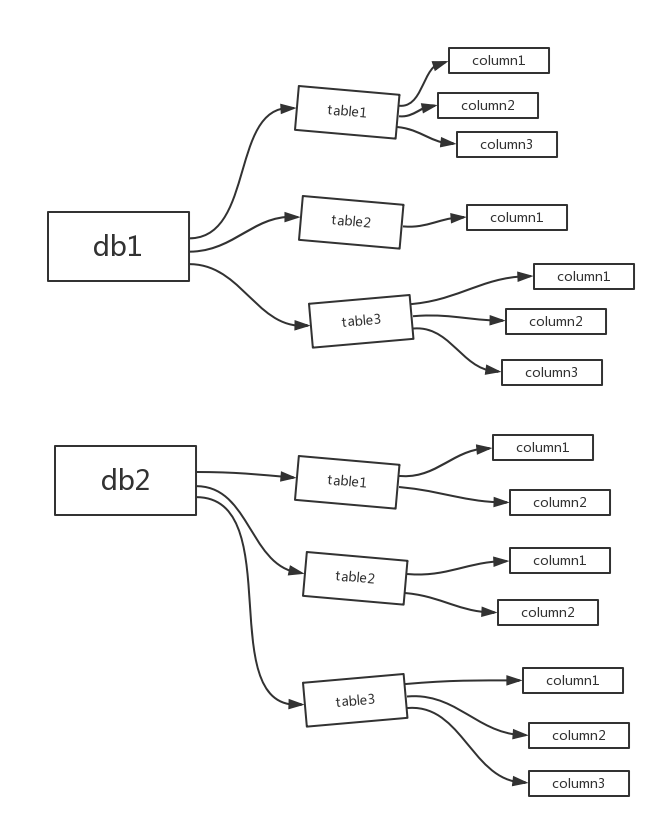
#授权表
user #该表放行的权限,针对:所有数据,所有库下所有表,以及表下的所有字段
db #该表放行的权限,针对:某一数据库,该数据库下的所有表,以及表下的所有字段
tables_priv #该表放行的权限。针对:某一张表,以及该表下的所有字段
columns_priv #该表放行的权限,针对:某一个字段
#按图解释:
user:放行db1,db2及其包含的所有
db:放行db1,及其db1包含的所有
tables_priv:放行db1.table1,及其该表包含的所有
columns_prive:放行db1.table1.column1,只放行该字段
#创建用户
create user 'egon'@'1.1.1.1' identified by '123';
create user 'egon'@'192.168.1.%' identified by '123';
create user 'egon'@'%' identified by '123';
#授权:对文件夹,对文件,对文件某一字段的权限
查看帮助:help grant
常用权限有:select,update,alter,delete
all可以代表除了grant之外的所有权限
#针对所有库的授权:*.*
grant select on *.* to 'egon1'@'localhost' identified by '123'; #只在user表中可以查到egon1用户的select权限被设置为Y
#针对某一数据库:db1.*
grant select on db1.* to 'egon2'@'%' identified by '123'; #只在db表中可以查到egon2用户的select权限被设置为Y
#针对某一个表:db1.t1
grant select on db1.t1 to 'egon3'@'%' identified by '123'; #只在tables_priv表中可以查到egon3用户的select权限
#针对某一个字段:
mysql> select * from t3;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | egon1 | 18 |
| 2 | egon2 | 19 |
| 3 | egon3 | 29 |
+------+-------+------+
grant select (id,name),update (age) on db1.t3 to 'egon4'@'localhost' identified by '123';
#可以在tables_priv和columns_priv中看到相应的权限
mysql> select * from tables_priv where user='egon4'\G
*************************** 1. row ***************************
Host: localhost
Db: db1
User: egon4
Table_name: t3
Grantor: root@localhost
Timestamp: 0000-00-00 00:00:00
Table_priv:
Column_priv: Select,Update
row in set (0.00 sec)
mysql> select * from columns_priv where user='egon4'\G
*************************** 1. row ***************************
Host: localhost
Db: db1
User: egon4
Table_name: t3
Column_name: id
Timestamp: 0000-00-00 00:00:00
Column_priv: Select
*************************** 2. row ***************************
Host: localhost
Db: db1
User: egon4
Table_name: t3
Column_name: name
Timestamp: 0000-00-00 00:00:00
Column_priv: Select
*************************** 3. row ***************************
Host: localhost
Db: db1
User: egon4
Table_name: t3
Column_name: age
Timestamp: 0000-00-00 00:00:00
Column_priv: Update
rows in set (0.00 sec)
#删除权限
revoke select on db1.* from 'egon'@'%';
六、过滤查询 having
- HAVING与WHERE不一样的地方在于:
- 执行优先级从高到低:where > group by > having
- Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
- Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
- 执行优先级从高到低:where > group by > having
1.举例
mysql> select @@sql_mode;
+--------------------+
| @@sql_mode |
+--------------------+
| ONLY_FULL_GROUP_BY |
+--------------------+
1 row in set (0.00 sec)
mysql> select * from emp where salary > 100000;
+----+------+------+-----+------------+---------+--------------+------------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------+------+-----+------------+---------+--------------+------------+--------+-----------+
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
+----+------+------+-----+------------+---------+--------------+------------+--------+-----------+
1 row in set (0.00 sec)
mysql> select * from emp having salary > 100000;
ERROR 1463 (42000): Non-grouping field 'salary' is used in HAVING clause
mysql> select post,group_concat(name) from emp group by post having salary > 10000;#错误,分组后无法直接取到salary字段
ERROR 1054 (42S22): Unknown column 'salary' in 'having clause'
mysql> select post,group_concat(name) from emp group by post having avg(salary) > 10000;
+-----------+-------------------------------------------------------+
| post | group_concat(name) |
+-----------+-------------------------------------------------------+
| operation | 程咬铁,程咬铜,程咬银,程咬金,张野 |
| teacher | 成龙,jinxin,jingliyang,liwenzhou,yuanhao,wupeiqi,alex |
+-----------+-------------------------------------------------------+
2 rows in set (0.00 sec)
2.小练习
1. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
3. 查询各岗位平均薪资大于10000的岗位名、平均工资
4. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
#题1:
mysql> select post,group_concat(name),count(id) from employee group by post having count(id) < 2;
+-----------------------------------------+--------------------+-----------+
| post | group_concat(name) | count(id) |
+-----------------------------------------+--------------------+-----------+
| 老男孩驻沙河办事处外交大使 | egon | 1 |
+-----------------------------------------+--------------------+-----------+
#题目2:
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| operation | 16800.026000 |
| teacher | 151842.901429 |
+-----------+---------------+
#题目3:
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000;
+-----------+--------------+
| post | avg(salary) |
+-----------+--------------+
| operation | 16800.026000 |
+-----------+--------------+
七、查询排序 order by
1.示例
按单列排序
SELECT * FROM employee ORDER BY salary;
SELECT * FROM employee ORDER BY salary ASC;
SELECT * FROM employee ORDER BY salary DESC;
按多列排序:先按照age排序,如果年纪相同,则按照薪资排序
SELECT * from employee
ORDER BY age,
salary DESC;
2.小练习
1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列
#题目1
mysql> select * from employee ORDER BY age asc,hire_date desc;
#题目2
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| operation | 16800.026000 |
| teacher | 151842.901429 |
+-----------+---------------+
#题目3
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| teacher | 151842.901429 |
| operation | 16800.026000 |
+-----------+---------------+
八、限制查询 limit
- 限制查询:限制查询的记录数
1.示例
SELECT * FROM employee ORDER BY salary DESC
LIMIT 3; #默认初始位置为0
SELECT * FROM employee ORDER BY salary DESC
LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
SELECT * FROM employee ORDER BY salary DESC
LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
2.小练习
- 分页显示,每页5条
mysql> select * from employee limit 0,5;
+----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
| 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 |
| 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
| 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 |
+----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
5 rows in set (0.00 sec)
mysql> select * from employee limit 5,5;
+----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+
| 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 |
| 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 |
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 |
+----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+
5 rows in set (0.00 sec)
mysql> select * from employee limit 10,5;
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 |
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 |
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
5 rows in set (0.00 sec)
九、使用正则表达式查询
1.示例
SELECT * FROM employee WHERE name REGEXP '^ale';
SELECT * FROM employee WHERE name REGEXP 'on$';
SELECT * FROM employee WHERE name REGEXP 'm{2}';
小结:对字符串匹配的方式
WHERE name = 'egon';
WHERE name LIKE 'yua%';
WHERE name REGEXP 'on$';
2.小练习
查看所有员工中名字是jin开头,n或者g结果的员工信息
select * from employee where name regexp '^jin.*[gn]$';
十、查询数据select(单表)
1.单表查询示例
SELECT 字段1,字段2... FROM 表名
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
2.关键字的执行优先级(重点)
- 重点中的重点:关键字的执行优先级
由上而下,从高到低:
from
where
group by
having
select
distinct
order by
limit
PS:详见:http://www.cnblogs.com/linhaifeng/articles/7372774.html
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.将分组的结果进行having过滤
5.执行select
6.去重
7.将结果按条件排序:order by
8.限制结果的显示条数
3.简单查询
1)建表、插入值
1.表所需信息
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
2.查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
3.插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
2)查询语法
#简单查询
SELECT id,name,sex,age,hire_date,post,post_comment,salary,office,depart_id
FROM employee;
SELECT * FROM employee;
SELECT name,salary FROM employee;
#避免重复DISTINCT
SELECT DISTINCT post FROM employee;
#通过四则运算查询
SELECT name, salary*12 FROM employee;
SELECT name, salary*12 AS Annual_salary FROM employee;
SELECT name, salary*12 Annual_salary FROM employee;
#定义显示格式
CONCAT() 函数用于连接字符串
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary
FROM employee;
CONCAT_WS() 第一个参数为分隔符
SELECT CONCAT_WS(':',name,salary*12) AS Annual_salary
FROM employee;
结合CASE语句:
SELECT
(
CASE
WHEN NAME = 'egon' THEN
NAME
WHEN NAME = 'alex' THEN
CONCAT(name,'_BIGSB')
ELSE
concat(NAME, 'SB')
END
) as new_name
FROM
employee;
3)小练习
1 查出所有员工的名字,薪资,格式为:<名字:egon> <薪资:3000>
2 查出所有的岗位(去掉重复)
3 查出所有员工名字,以及他们的年薪,年薪的字段名为annual_year
select concat('<名字:',name,'> ','<薪资:',salary,'>') from employee;
<名字:egon> <薪资:7300.33>
<名字:alex> <薪资:1000000.31>
<名字:wupeiqi> <薪资:8300.00>
<名字:yuanhao> <薪资:3500.00>
<名字:liwenzhou> <薪资:2100.00>
<名字:jingliyang> <薪资:9000.00>
<名字:jinxin> <薪资:30000.00>
<名字:成龙> <薪资:10000.00>
<名字:歪歪> <薪资:3000.13>
<名字:丫丫> <薪资:2000.35>
<名字:丁丁> <薪资:1000.37>
<名字:星星> <薪资:3000.29>
<名字:格格> <薪资:4000.33>
<名字:张野> <薪资:10000.13>
<名字:程咬金> <薪资:20000.00>
<名字:程咬银> <薪资:19000.00>
<名字:程咬铜> <薪资:18000.00>
<名字:程咬铁> <薪资:17000.00>
select distinct post from employee;
老男孩驻沙河办事处外交大使
teacher
sale
operation
select name,salary*12 annual_salary from employee;
egon 87603.96
alex 12000003.72
wupeiqi 99600.00
yuanhao 42000.00
liwenzhou 25200.00
jingliyang 108000.00
jinxin 360000.00
成龙 120000.00
歪歪 36001.56
丫丫 24004.20
丁丁 12004.44
星星 36003.48
格格 48003.96
张野 120001.56
程咬金 240000.00
程咬银 228000.00
程咬铜 216000.00
程咬铁 204000.00
4.where约束
- where字句中可以使用:
- 比较运算符:> < >= <= <> !=
- between 80 and 100 值在10到20之间
- in(80,90,100) 值是10或20或30
- like ‘egon%’
- pattern可以是%或_,
- %表示任意多字符
- _表示一个字符
- 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
1)单多条件、关键字查询
#1:单条件查询
# 查询岗位为sale(销售)的名字
SELECT name FROM employee WHERE post='sale';
歪歪
丫丫
丁丁
星星
格格
#2:多条件查询
# 查询岗位为老师且薪资为10000的名字
SELECT name,salary FROM employee
WHERE post='teacher' AND salary>10000;
alex 1000000.31
wupeiqi 8300.00
yuanhao 3500.00
liwenzhou 2100.00
jingliyang 9000.00
jinxin 30000.00
成龙 10000.00
#3:关键字BETWEEN AND
# 查询名字、薪资,薪资为1000和2000
SELECT name,salary FROM employee
WHERE salary BETWEEN 10000 AND 20000;
SELECT name,salary FROM employee
WHERE salary NOT BETWEEN 10000 AND 20000;
#4:关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS)
# 查询名字、岗位注释,岗位注释为null的
SELECT name,post_comment FROM employee
WHERE post_comment IS NULL;
# 查询名字、岗位注释,岗位注释不为null的
SELECT name,post_comment FROM employee
WHERE post_comment IS NOT NULL;
# 查询名字、岗位注释,岗位注释为空的
SELECT name,post_comment FROM employee
WHERE post_comment=''; # 注意''是空字符串,不是null
ps:
执行
update employee set post_comment='' where id=2;
再用上条查看,就会有结果了
#5:关键字IN集合查询,推荐用IN
# 查询名字、薪资,且薪资为3000/3500/4000/9000
# 方式1:where
SELECT name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ;
# 方式2:in
SELECT name,salary FROM employee
WHERE salary IN (3000,3500,4000,9000) ;
# 查询名字、薪资,且薪不资为3000/3500/4000/9000
# 方式1:where
SELECT name,salary FROM employee WHERE salary!=3000 OR salary!=3500 OR salary!=4000 OR salary!=9000;
# 方式2:in
SELECT name,salary FROM employee
WHERE salary NOT IN (3000,3500,4000,9000) ;
#6:关键字LIKE模糊查询
通配符 %
SELECT * FROM employee
WHERE name LIKE 'eg%';
+----+------+------+-----+------------+-----------------------------------------+--------------+---------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------+------+-----+------------+-----------------------------------------+--------------+---------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
+----+------+------+-----+------------+-----------------------------------------+--------------+---------+--------+-----------+
通配符 _
# 一个下划线代表一个字符,若用eg匹配egon,则需要两个下划线,以此类推
SELECT * FROM employee
WHERE name LIKE 'eg__';
+----+------+------+-----+------------+-----------------------------------------+--------------+---------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------+------+-----+------------+-----------------------------------------+--------------+---------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
+----+------+------+-----+------------+-----------------------------------------+--------------+---------+--------+-----------+
2)小练习
1. 查看岗位是teacher的员工姓名、年龄
2. 查看岗位是teacher且年龄大于30岁的员工姓名、年龄
3. 查看岗位是teacher且薪资在9000-1000范围内的员工姓名、年龄、薪资
4. 查看岗位描述不为NULL的员工信息
5. 查看岗位是teacher且薪资是10000或9000或30000的员工姓名、年龄、薪资
6. 查看岗位是teacher且薪资不是10000或9000或30000的员工姓名、年龄、薪资
7. 查看岗位是teacher且名字是jin开头的员工姓名、年薪
select name,age from employee where post = 'teacher';
select name,age from employee where post='teacher' and age > 30;
select name,age,salary from employee where post='teacher' and salary between 9000 and 10000;
select * from employee where post_comment is not null;
select name,age,salary from employee where post='teacher' and salary in (10000,9000,30000);
select name,age,salary from employee where post='teacher' and salary not in (10000,9000,30000);
select name,salary*12 from employee where post='teacher' and name like 'jin%';
5、分组查询 group by
- 一 什么是分组?为什么要分组?
1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
3、为何要分组呢?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
- 小窍门:‘每’这个字后面的字段,就是我们分组的依据
4、大前提:
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
1)only_full_group_by
#查看MySQL 5.7默认的sql_mode如下:
mysql> select @@global.sql_mode;
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#!!!注意
ONLY_FULL_GROUP_BY的语义就是确定select target list中的所有列的值都是明确语义,简单的说来,在ONLY_FULL_GROUP_BY模式下,target list中的值要么是来自于聚集函数的结果,要么是来自于group by list中的表达式的值。
#设置sql_mole如下操作(我们可以去掉ONLY_FULL_GROUP_BY模式):
mysql> set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
mysql> select @@global.sql_mode;
+-------------------+
| @@global.sql_mode |
+-------------------+
| |
+-------------------+
1 row in set (0.00 sec)
mysql> select * from emp group by post;
+----+------+--------+-----+------------+----------------------------+--------------+------------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------+--------+-----+------------+----------------------------+--------------+------------+--------+-----------+
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
+----+------+--------+-----+------------+----------------------------+--------------+------------+--------+-----------+
4 rows in set (0.00 sec)
#由于没有设置ONLY_FULL_GROUP_BY,于是也可以有结果,默认都是组内的第一条记录,但其实这是没有意义的
mysql> set global sql_mode='ONLY_FULL_GROUP_BY';
Query OK, 0 rows affected (0.00 sec)
mysql> quit #设置成功后,一定要退出,然后重新登录方可生效
Bye
mysql> use db1;
Database changed
mysql> select * from emp group by post; #报错
ERROR 1055 (42000): 'db1.emp.id' isn't in GROUP BY
mysql> select post,count(id) from emp group by post; #只能查看分组依据和使用聚合函数
+----------------------------+-----------+
| post | count(id) |
+----------------------------+-----------+
| operation | 5 |
| sale | 5 |
| teacher | 7 |
| 老男孩驻沙河办事处外交大使 | 1 |
+----------------------------+-----------+
4 rows in set (0.00 sec)
2)group by
单独使用GROUP BY关键字分组
SELECT post FROM employee GROUP BY post;
# 注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数
+-----------------------------------------+
| post |
+-----------------------------------------+
| operation |
| sale |
| teacher |
| 老男孩驻沙河办事处外交大使 |
+-----------------------------------------+
GROUP BY关键字和GROUP_CONCAT()函数一起使用
#按照岗位分组,并查看组内成员名
SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post;
+-----------------------------------------+---------------------------------------------------------+
| post | GROUP_CONCAT(name) |
+-----------------------------------------+---------------------------------------------------------+
| operation | 张野,程咬金,程咬银,程咬铜,程咬铁 |
| sale | 歪歪,丫丫,丁丁,星星,格格 |
| teacher | alex,wupeiqi,yuanhao,liwenzhou,jingliyang,jinxin,成龙 |
| 老男孩驻沙河办事处外交大使 | egon |
+-----------------------------------------+---------------------------------------------------------+
SELECT post,GROUP_CONCAT(name) as emp_members FROM employee GROUP BY post;
GROUP BY与聚合函数一起使用
#按照岗位分组,并查看每个组有多少人
select post,count(id) as count from employee group by post;
+-----------------------------------------+-------+
| post | count |
+-----------------------------------------+-------+
| operation | 5 |
| sale | 5 |
| teacher | 7 |
| 老男孩驻沙河办事处外交大使 | 1 |
+-----------------------------------------+-------+
# 按性别分组,查看每组有多少人
select sex,count(id) from employee group by sex;
+--------+-----------+
| sex | count(id) |
+--------+-----------+
| male | 10 |
| female | 8 |
+--------+-----------+
- 强调:
- 如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义
多条记录之间的某个字段值相同,该字段通常用来作为分组的依据
- 如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义
5、聚合函数
- 强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组
示例:
SELECT COUNT(*) FROM employee;
SELECT COUNT(*) FROM employee WHERE depart_id=1;
SELECT MAX(salary) FROM employee;
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;
小练习
1. 查询岗位名以及岗位包含的所有员工名字
2. 查询岗位名以及各岗位内包含的员工个数
3. 查询公司内男员工和女员工的个数
4. 查询岗位名以及各岗位的平均薪资
5. 查询岗位名以及各岗位的最高薪资
6. 查询岗位名以及各岗位的最低薪资
7. 查询男员工的平均薪资,女员工的平均薪资
#题1:分组
mysql> select post,group_concat(name) from employee group by post;
+-----------------------------------------+---------------------------------------------------------+
| post | group_concat(name) |
+-----------------------------------------+---------------------------------------------------------+
| operation | 张野,程咬金,程咬银,程咬铜,程咬铁 |
| sale | 歪歪,丫丫,丁丁,星星,格格 |
| teacher | alex,wupeiqi,yuanhao,liwenzhou,jingliyang,jinxin,成龙 |
| 老男孩驻沙河办事处外交大使 | egon |
+-----------------------------------------+---------------------------------------------------------+
#题目2:
mysql> select post,count(id) from employee group by post;
+-----------------------------------------+-----------+
| post | count(id) |
+-----------------------------------------+-----------+
| operation | 5 |
| sale | 5 |
| teacher | 7 |
| 老男孩驻沙河办事处外交大使 | 1 |
+-----------------------------------------+-----------+
#题目3:
mysql> select sex,count(id) from employee group by sex;
+--------+-----------+
| sex | count(id) |
+--------+-----------+
| male | 10 |
| female | 8 |
+--------+-----------+
#题目4:
mysql> select post,avg(salary) from employee group by post;
+-----------------------------------------+---------------+
| post | avg(salary) |
+-----------------------------------------+---------------+
| operation | 16800.026000 |
| sale | 2600.294000 |
| teacher | 151842.901429 |
| 老男孩驻沙河办事处外交大使 | 7300.330000 |
+-----------------------------------------+---------------+
#题目5
mysql> select post,max(salary) from employee group by post;
+-----------------------------------------+-------------+
| post | max(salary) |
+-----------------------------------------+-------------+
| operation | 20000.00 |
| sale | 4000.33 |
| teacher | 1000000.31 |
| 老男孩驻沙河办事处外交大使 | 7300.33 |
+-----------------------------------------+-------------+
#题目6
mysql> select post,min(salary) from employee group by post;
+-----------------------------------------+-------------+
| post | min(salary) |
+-----------------------------------------+-------------+
| operation | 10000.13 |
| sale | 1000.37 |
| teacher | 2100.00 |
| 老男孩驻沙河办事处外交大使 | 7300.33 |
+-----------------------------------------+-------------+
#题目七
mysql> select sex,avg(salary) from employee group by sex;
+--------+---------------+
| sex | avg(salary) |
+--------+---------------+
| male | 110920.077000 |
| female | 7250.183750 |
+--------+---------------+
十一、查询数据select(连表)
- 多表连接查询
- 复合条件连接查询
- 子查询
1.准备表
#建表
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
#查看表结构和数据
mysql> desc department;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> desc employee;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
mysql> select * from department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
mysql> select * from employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
2.多表连接查询
- 重点:外链接语法
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
1)交叉连接:不适用任何匹配条件。生成笛卡尔积
mysql> select * from employee,department;
+----+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 1 | egon | male | 18 | 200 | 201 | 人力资源 |
| 1 | egon | male | 18 | 200 | 202 | 销售 |
| 1 | egon | male | 18 | 200 | 203 | 运营 |
| 2 | alex | female | 48 | 201 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 2 | alex | female | 48 | 201 | 202 | 销售 |
| 2 | alex | female | 48 | 201 | 203 | 运营 |
| 3 | wupeiqi | male | 38 | 201 | 200 | 技术 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 202 | 销售 |
| 3 | wupeiqi | male | 38 | 201 | 203 | 运营 |
| 4 | yuanhao | female | 28 | 202 | 200 | 技术 |
| 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 4 | yuanhao | female | 28 | 202 | 203 | 运营 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 201 | 人力资源 |
| 5 | liwenzhou | male | 18 | 200 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 203 | 运营 |
| 6 | jingliyang | female | 18 | 204 | 200 | 技术 |
| 6 | jingliyang | female | 18 | 204 | 201 | 人力资源 |
| 6 | jingliyang | female | 18 | 204 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | 203 | 运营 |
+----+------------+--------+------+--------+------+--------------+
2)内连接:只连接匹配的行
#找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了正确的结果
#department没有204这个部门,因而employee表中关于204这条员工信息没有匹配出来
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id;
+----+-----------+------+--------+--------------+
| id | name | age | sex | name |
+----+-----------+------+--------+--------------+
| 1 | egon | 18 | male | 技术 |
| 2 | alex | 48 | female | 人力资源 |
| 3 | wupeiqi | 38 | male | 人力资源 |
| 4 | yuanhao | 28 | female | 销售 |
| 5 | liwenzhou | 18 | male | 技术 |
+----+-----------+------+--------+--------------+
#上述sql等同于
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
3)外链接之左连接:优先显示左表全部记录
#以左表为准,即找出所有员工信息,当然包括没有部门的员工
#本质就是:在内连接的基础上增加左边有右边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;
+----+------------+--------------+
| id | name | depart_name |
+----+------------+--------------+
| 1 | egon | 技术 |
| 5 | liwenzhou | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 6 | jingliyang | NULL |
+----+------------+--------------+
4)外链接之右连接:优先显示右表全部记录
#以右表为准,即找出所有部门信息,包括没有员工的部门
#本质就是:在内连接的基础上增加右边有左边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id;
+------+-----------+--------------+
| id | name | depart_name |
+------+-----------+--------------+
| 1 | egon | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 5 | liwenzhou | 技术 |
| NULL | NULL | 运营 |
+------+-----------+--------------+
5)全外连接:显示左右两个表全部记录
全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
#注意:mysql不支持全外连接 full JOIN
#强调:mysql可以使用此种方式间接实现全外连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
#查看结果
+------+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 203 | 运营 |
+------+------------+--------+------+--------+------+--------------+
#注意 union与union all的区别:union会去掉相同的纪录
3.符合条件连接查询
#示例1:以内连接的方式查询employee和department表,并且employee表中的age字段值必须大于25,即找出年龄大于25岁的员工以及员工所在的部门
select employee.name,department.name from employee inner join department
on employee.dep_id = department.id
where age > 25;
#示例2:以内连接的方式查询employee和department表,并且以age字段的升序方式显示
select employee.id,employee.name,employee.age,department.name from employee,department
where employee.dep_id = department.id
and age > 25
order by age asc;
4.子查询
- 子查询是将一个查询语句嵌套在另一个查询语句中。
- 内层查询语句的查询结果,可以为外层查询语句提供查询条件。
- 子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
- 还可以包含比较运算符:= 、 !=、> 、< 等
1)带 in 关键字的子查询
not in 无法处理null的值,即子查询中如果存在null的值,not in将无法处理,如下
mysql> select * from emp;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
| 7 | xxx | male | 19 | NULL |
+----+------------+--------+------+--------+
7 rows in set (0.00 sec)
mysql> select * from dep;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
4 rows in set (0.00 sec)
# 子查询中存在null
mysql> select * from dep where id not in (select distinct dep_id from emp);
Empty set (0.00 sec)
# 解决方案如下
mysql> select * from dep where id not in (select distinct dep_id from emp where dep_id is not null);
+------+--------+
| id | name |
+------+--------+
| 203 | 运营 |
+------+--------+
1 row in set (0.00 sec)
mysql>
2)带ANY关键字的子查询
#在 SQL 中 ANY 和 SOME 是同义词,SOME 的用法和功能和 ANY 一模一样。
# ANY 和 IN 运算符不同之处1
ANY 必须和其他的比较运算符共同使用,而且ANY必须将比较运算符放在 ANY 关键字之前,所比较的值需要匹配子查询中的任意一个值,这也就是 ANY 在英文中所表示的意义
例如:使用 IN 和使用 ANY运算符得到的结果是一致的
select * from employee where salary = any (
select max(salary) from employee group by depart_id);
select * from employee where salary in (
select max(salary) from employee group by depart_id);
结论:也就是说“=ANY”等价于 IN 运算符,而“<>ANY”则等价于 NOT IN 运算符
# ANY和 IN 运算符不同之处2
ANY 运算符不能与固定的集合相匹配,比如下面的 SQL 语句是错误的
SELECT
*
FROM
T_Book
WHERE
FYearPublished < ANY (2001, 2003, 2005)
3)带ALL关键字的子查询
# all同any类似,只不过all表示的是所有,any表示任一查询出那些薪资比所有部门的平均薪资都高的员工=》薪资在所有部门平均线以上的狗币资本家
select * from employee where salary > all (
select avg(salary) from employee group by depart_id);
查询出那些薪资比所有部门的平均薪资都低的员工=》薪资在所有部门平均线以下的无产阶级劳苦大众
select * from employee where salary < all (
select avg(salary) from employee group by depart_id);
查询出那些薪资比任意一个部门的平均薪资低的员工=》薪资在任一部门平均线以下的员工select * from employee where salary < any ( select avg(salary) from employee group by depart_id);
查询出那些薪资比任意一个部门的平均薪资高的员工=》薪资在任一部门平均线以上的员工
select * from employee where salary > any (
select avg(salary) from employee group by depart_id);
4)带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from emp where age > (select avg(age) from emp);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
2 rows in set (0.00 sec)
#查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
5)带EXISTS关键字的子查询
- EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录,而是返回一个真假值:True或False
- 当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
#department表中存在dept_id=203,Ture
mysql> select * from employee where exists (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee where exists (select id from department where id=204);
Empty set (0.00 sec)
1> in 与 exists
!!!!!!当in和exists在查询效率上比较时,in查询的效率快于exists的查询效率!!!!!!
==============================exists==============================
# exists
exists后面一般都是子查询,后面的子查询被称做相关子查询(即与主语句相关),当子查询返回行数时,exists条件返回true,
否则返回false,exists是不返回列表的值的,exists只在乎括号里的数据能不能查找出来,是否存在这样的记录。
# 例
查询出那些班级里有学生的班级
select * from class where exists (select * from stu where stu.cid=class.id)
# exists的执行原理为:
1、依次执行外部查询:即select * from class
2、然后为外部查询返回的每一行分别执行一次子查询:即(select * from stu where stu.cid=class.cid)
3、子查询如果返回行,则exists条件成立,条件成立则输出外部查询取出的那条记录
==============================in==============================
# in
in后跟的都是子查询,in()后面的子查询 是返回结果集的
# 例
查询和所有女生年龄相同的男生
select * from stu where sex='男' and age in(select age from stu where sex='女')
# in的执行原理为:
in()的执行次序和exists()不一样,in()的子查询会先产生结果集,
然后主查询再去结果集里去找符合要求的字段列表去.符合要求的输出,反之则不输出.
2> not in 与 not exists
!!!!!!not exists查询的效率远远高与not in查询的效率。!!!!!!
==============================not in==============================
not in()子查询的执行顺序是:
为了证明not in成立,即找不到,需要一条一条地查询表,符合要求才返回子查询的结果集,不符合的就继续查询下一条记录,直到把表中的记录查询完,只能查询全部记录才能证明,并没有用到索引。
==============================not exists==============================
not exists:
如果主查询表中记录少,子查询表中记录多,并有索引。
例如:查询那些班级中没有学生的班级
select * from class
where not exists
(select * from student where student.cid = class.cid)
not exists的执行顺序是:
在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询。
3> 应用
create database db13;
use db13
create table student(
id int primary key auto_increment,
name varchar(16)
);
create table course(
id int primary key auto_increment,
name varchar(16),
comment varchar(20)
);
create table student2course(
id int primary key auto_increment,
sid int,
cid int,
foreign key(sid) references student(id),
foreign key(cid) references course(id)
);
insert into student(name) values
("egon"),
("lili"),
("jack"),
("tom");
insert into course(name,comment) values
("数据库","数据仓库"),
("数学","根本学不会"),
("英语","鸟语花香");
insert into student2course(sid,cid) values
(1,1),
(1,2),
(1,3),
(2,1),
(2,2),
(3,2);
4> 示例
# 1、查询选修了所有课程的学生id、name:(即该学生根本就不存在一门他没有选的课程。)
select * from student s where not exists
(select * from course c where not exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
select s.name from student as s
inner join student2course as sc
on s.id=sc.sid
group by s.name
having count(sc.id) = (select count(id) from course);
# 2、查询没有选择所有课程的学生,即没有全选的学生。(存在这样的一个学生,他至少有一门课没有选)
select * from student s where exists
(select * from course c where not exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
# 3、查询一门课也没有选的学生。(不存这样的一个学生,他至少选修一门课程)
select * from student s where not exists
(select * from course c where exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
# 4、查询至少选修了一门课程的学生。
select * from student s where exists
(select * from course c where exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
6> 练习:查询每个部门最新入职的那位员工
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
#插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
SELECT
*
FROM
employee AS t1
INNER JOIN (
SELECT
post,
max(hire_date) max_date
FROM
employee
GROUP BY
post
) AS t2 ON t1.post = t2.post
WHERE
t1.hire_date = t2.max_date;
mysql> select t3.name,t3.post,t3.hire_date from emp as t3 where id in (select (select id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post);
+--------+-----------------------------------------+------------+
| name | post | hire_date |
+--------+-----------------------------------------+------------+
| egon | 老男孩驻沙河办事处外交大使 | 2017-03-01 |
| alex | teacher | 2015-03-02 |
| 格格 | sale | 2017-01-27 |
| 张野 | operation | 2016-03-11 |
+--------+-----------------------------------------+------------+
rows in set (0.00 sec)
5.综合练习
1> init.sql文件内容
数据导入:
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50624
Source Host : localhost
Source Database : sqlexam
Target Server Type : MySQL
Target Server Version : 50624
File Encoding : utf-8
Date: 10/21/2016 06:46:46 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `class`
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `class`
-- ----------------------------
BEGIN;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
COMMIT;
-- ----------------------------
-- Table structure for `course`
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `course`
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
COMMIT;
-- ----------------------------
-- Table structure for `score`
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `score`
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
COMMIT;
-- ----------------------------
-- Table structure for `student`
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `student`
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
COMMIT;
-- ----------------------------
-- Table structure for `teacher`
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `teacher`
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
2> 从init.sql文件中导入数据
#准备表、记录
mysql> create database db1;
mysql> use db1;
mysql> source /root/init.sql
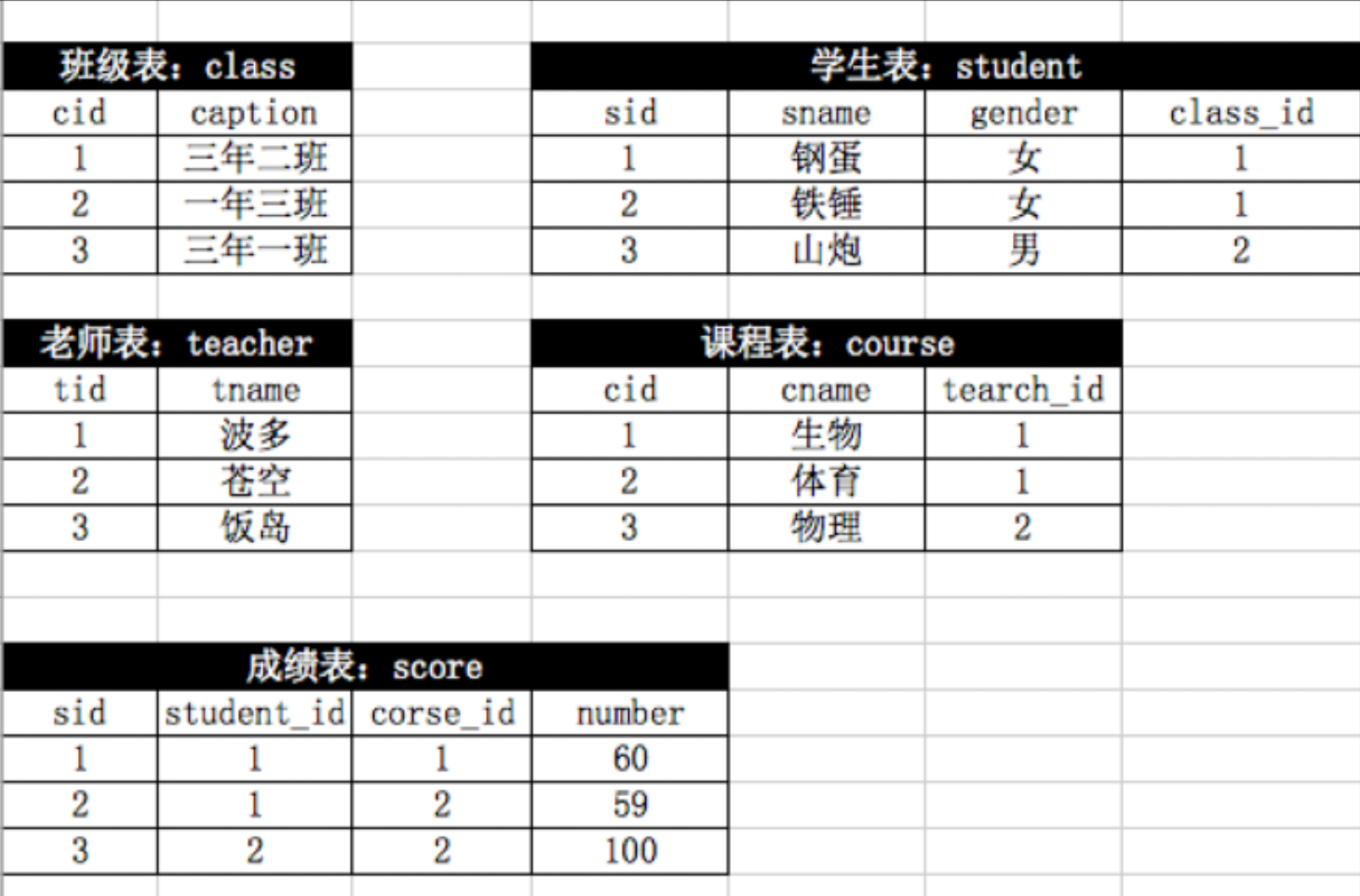
3> 表结构为
6.常用语法
1)查询锁表
where条件后匹配库名
SELECT concat('KILL ',id,';')
FROM information_schema.processlist p
INNER JOIN information_schema.INNODB_TRX x
ON p.id=x.trx_mysql_thread_id
WHERE db='DATABASE_NAME';
十二、高级查询
高级查询在数据库中用得是最频繁的,也是应用最广泛的
--Ø 基本常用查询
--select
select * from student;
--all 查询所有
select all sex from student;
--distinct 过滤重复
select distinct sex from student;
--count 统计
select count(*) from student;
select count(sex) from student;
select count(distinct sex) from student;
--top 取前N条记录
select top 3 * from student;
--alias column name 列重命名
select id as 编号, name '名称', sex 性别 from student;
--alias table name 表重命名
select id, name, s.id, s.name from student s;
--column 列运算
select (age + id) col from student;
select s.name + '-' + c.name from classes c, student s where s.cid = c.id;
--where 条件
select * from student where id = 2;
select * from student where id > 7;
select * from student where id < 3;
select * from student where id <> 3;
select * from student where id >= 3;
select * from student where id <= 5;
select * from student where id !> 3;
select * from student where id !< 5;
--and 并且
select * from student where id > 2 and sex = 1;
--or 或者
select * from student where id = 2 or sex = 1;
--between ... and ... 相当于并且
select * from student where id between 2 and 5;
select * from student where id not between 2 and 5;
--like 模糊查询
select * from student where name like '%a%';
select * from student where name like '%[a][o]%';
select * from student where name not like '%a%';
select * from student where name like 'ja%';
select * from student where name not like '%[j,n]%';
select * from student where name like '%[j,n,a]%';
select * from student where name like '%[^ja,as,on]%';
select * from student where name like '%[ja_on]%';
--in 子查询
select * from student where id in (1, 2);
--not in 不在其中
select * from student where id not in (1, 2);
--is null 是空
select * from student where age is null;
--is not null 不为空
select * from student where age is not null;
--order by 排序
select * from student order by name;
select * from student order by name desc;
select * from student order by name asc;
--group by 分组
--按照年龄进行分组统计
select count(age), age from student group by age;
--按照性别进行分组统计
select count(*), sex from student group by sex;
--按照年龄和性别组合分组统计,并排序
select count(*), sex from student group by sex, age order by age;
--按照性别分组,并且是id大于2的记录最后按照性别排序
select count(*), sex from student where id > 2 group by sex order by sex;
--查询id大于2的数据,并完成运算后的结果进行分组和排序
select count(*), (sex * id) new from student where id > 2 group by sex * id order by sex * id;
--group by all 所有分组
--按照年龄分组,是所有的年龄
select count(*), age from student group by all age;
--having 分组过滤条件
-- 按照年龄分组,过滤年龄为空的数据,并且统计分组的条数和现实年龄信息
select count(*), age from student group by age having age is not null;
-- 按照年龄和cid组合分组,过滤条件是cid大于1的记录
select count(*), cid, sex from student group by cid, sex having cid > 1;
-- 按照年龄分组,过滤条件是分组后的记录条数大于等于2
select count(*), age from student group by age having count(age) >= 2;
-- 按照cid和性别组合分组,过滤条件是cid大于1,cid的最大值大于2
select count(*), cid, sex from student group by cid, sex having cid > 1 and max(cid) > 2;
--Ø 嵌套子查询
-- 子查询是一个嵌套在select、insert、update或delete语句或其他子查询中的查询。任何允许使用表达式的地方都可以使用子查询。子查询也称为内部查询或内部选择,而包含子查询的语句也成为外部查询或外部选择。
--# from (select … table)示例
--将一个table的查询结果当做一个新表进行查询
select * from (
select id, name from student where sex = 1
) t where t.id > 2;
--上面括号中的语句,就是子查询语句(内部查询)。在外面的是外部查询,其中外部查询可以包含以下语句:
-- 1、 包含常规选择列表组件的常规select查询
-- 2、 包含一个或多个表或视图名称的常规from语句
-- 3、 可选的where子句
-- 4、 可选的group by子句
-- 5、 可选的having子句
--# 示例
--查询班级信息,统计班级学生人生
select *, (select count(*) from student where cid = classes.id) as num
from classes order by num;
--# in, not in子句查询示例
--查询班级id大于小于的这些班级的学生信息
select * from student where cid in (
select id from classes where id > 2 and id < 4
);
--查询不是班的学生信息
select * from student where cid not in (
select id from classes where name = '2班'
)
--in、not in 后面的子句返回的结果必须是一列,这一列的结果将会作为查询条件对应前面的条件。如cid对应子句的id;
--# exists和not exists子句查询示例
--查询存在班级id为的学生信息
select * from student where exists (
select * from classes where id = student.cid and id = 3
);
--查询没有分配班级的学生信息
select * from student where not exists (
select * from classes where id = student.cid
);
--exists和not exists查询需要内部查询和外部查询进行一个关联的条件,如果没有这个条件将是查询到的所有信息。如:id等于student.id;
--# some、any、all子句查询示例
--查询班级的学生年龄大于班级的学生的年龄的信息
select * from student where cid = 5 and age > all (
select age from student where cid = 3
);
select * from student where cid = 5 and age > any (
select age from student where cid = 3
);
select * from student where cid = 5 and age > some (
select age from student where cid = 3
);
--Ø 聚合查询
--1、 distinct去掉重复数据
select distinct sex from student;
select count(sex), count(distinct sex) from student;
--2、 compute和compute by汇总查询
--对年龄大于的进行汇总
select age from student
where age > 20 order by age compute sum(age) by age;
--对年龄大于的按照性别进行分组汇总年龄信息
select id, sex, age from student
where age > 20 order by sex, age compute sum(age) by sex;
--按照年龄分组汇总
select age from student
where age > 20 order by age, id compute sum(age);
--按照年龄分组,年龄汇总,id找最大值
select id, age from student
where age > 20 order by age compute sum(age), max(id);
--compute进行汇总前面是查询的结果,后面一条结果集就是汇总的信息。compute子句中可以添加多个汇总表达式,可以添加的信息如下:
-- a、 可选by关键字。它是每一列计算指定的行聚合
-- b、 行聚合函数名称。包括sum、avg、min、max、count等
-- c、 要对其执行聚合函数的列 compute by适合做先分组后汇总的业务。compute by后面的列一定要是order by中出现的列。 COMPUTE 和 GROUP BY 之间的区别汇总如下:GROUP BY 生成单个结果集。每个组都有一个只包含分组依据列和显示该组子聚合的聚合函数的行。选择列表只能包含分组依据列和聚合函数。COMPUTE 生成多个结果集。一类结果集包含每个组的明细行,其中包含选择列表中的表达式。另一类结果集包含组的子聚合,或 SELECT语句的总聚合。选择列表可包含除分组依据列或聚合函数之外的其它表达式。聚合函数在 COMPUTE 子句中指定,而不是在选择列表中。--下列查询使用 GROUP BY 和聚合函数;该查询将返回一个结果集,其中每个组有一行,该行中包含该组的聚合小计:
USE pubsSELECT type, SUM(price), SUM(advance)FROM titlesGROUP BY type--说明 在 COMPUTE 或 COMPUTE
--BY 子句中,不能包含 ntext、text 或 image 数据类型。
--3、 cube汇总
--cube汇总和compute效果类似,但语法较简洁,而且返回的是一个结果集。
select count(*), sex from student group by sex with cube;
select count(*), age, sum(age) from student where age is not null group by age with cube;
--cube要结合group by语句完成分组汇总
--Ø 排序函数
-- 排序在很多地方需要用到,需要对查询结果进行排序并且给出序号。比如:
-- 1、 对某张表进行排序,序号需要递增不重复的
-- 2、 对学生的成绩进行排序,得出名次,名次可以并列,但名次的序号是连续递增的
-- 3、 在某些排序的情况下,需要跳空序号,虽然是并列
--基本语法
--排序函数 over([分组语句] 排序子句[desc][asc])
--排序子句 order by 列名, 列名
--分组子句 partition by 分组列, 分组列
--# row_number函数
--根据排序子句给出递增连续序号
--按照名称排序的顺序递增
select s.id, s.name, cid, c.name, row_number() over(order by c.name) as number
from student s, classes c where cid = c.id;
--# rank函数函数
--根据排序子句给出递增的序号,但是存在并列并且跳空
--顺序递增
select id, name, rank() over(order by cid) as rank from student;
--跳过相同递增
select s.id, s.name, cid, c.name, rank() over(order by c.name) as rank
from student s, classes c where cid = c.id;
--# dense_rank函数
--根据排序子句给出递增的序号,但是存在并列不跳空
--不跳过,直接递增
select s.id, s.name, cid, c.name, dense_rank() over(order by c.name) as dense
from student s, classes c where cid = c.id;
--# partition by分组子句
--可以完成对分组的数据进行增加排序,partition by可以与以上三个函数联合使用。
--利用partition by按照班级名称分组,学生id排序
select s.id, s.name, cid, c.name, row_number() over(partition by c.name order by s.id) as rank
from student s, classes c where cid = c.id;
select s.id, s.name, cid, c.name, rank() over(partition by c.name order by s.id) as rank
from student s, classes c where cid = c.id;
select s.id, s.name, cid, c.name, dense_rank() over(partition by c.name order by s.id) as rank
from student s, classes c where cid = c.id;
--# ntile平均排序函数
--将要排序的数据进行平分,然后按照等分排序。ntile中的参数代表分成多少等分。
select s.id, s.name, cid, c.name,
ntile(5) over(order by c.name) as ntile
from student s, classes c where cid = c.id;
--Ø 集合运算
--操作两组查询结果,进行交集、并集、减集运算
--1、 union和union all进行并集运算
--union 并集、不重复
select id, name from student where name like 'ja%'
union
select id, name from student where id = 4;
--并集、重复
select * from student where name like 'ja%'
union all
select * from student;
--2、 intersect进行交集运算
--交集(相同部分)
select * from student where name like 'ja%'
intersect
select * from student;
--3、 except进行减集运算
--减集(除相同部分)
select * from student where name like 'ja%'
except
select * from student where name like 'jas%';
--Ø 公式表表达式
--查询表的时候,有时候中间表需要重复使用,这些子查询被重复查询调用,不但效率低,而且可读性低,不利于理解。那么公式表表达式可以解决这个问题。
--我们可以将公式表表达式(CET)视为临时结果集,在select、insert、update、delete或是create view语句的执行范围内进行定义。
--表达式
with statNum(id, num) as
(
select cid, count(*)
from student
where id > 0
group by cid
)
select id, num from statNum order by id;
with statNum(id, num) as
(
select cid, count(*)
from student
where id > 0
group by cid
)
select max(id), avg(num) from statNum;
--Ø连接查询
--1、 简化连接查询
--简化联接查询
select s.id, s.name, c.id, c.name from student s, classes c where s.cid = c.id;
--2、 left join左连接
--左连接
select s.id, s.name, c.id, c.name from student s left join classes c on s.cid = c.id;
--3、 right join右连接
--右连接
select s.id, s.name, c.id, c.name from student s right join classes c on s.cid = c.id;
--4、 inner join内连接
--内连接
select s.id, s.name, c.id, c.name from student s inner join classes c on s.cid = c.id;
--inner可以省略
select s.id, s.name, c.id, c.name from student s join classes c on s.cid = c.id;
--5、 cross join交叉连接
--交叉联接查询,结果是一个笛卡儿乘积
select s.id, s.name, c.id, c.name from student s cross join classes c
--where s.cid = c.id;
--6、 自连接(同一张表进行连接查询)
--自连接
select distinct s.* from student s, student s1 where s.id <> s1.id and s.sex = s1.sex;
--Ø 函数
--1、 聚合函数
max最大值、min最小值、count统计、avg平均值、sum求和、var求方差
select
max(age) max_age,
min(age) min_age,
count(age) count_age,
avg(age) avg_age,
sum(age) sum_age,
var(age) var_age
from student;
--2、 日期时间函数
select dateAdd(day, 3, getDate());--加天
select dateAdd(year, 3, getDate());--加年
select dateAdd(hour, 3, getDate());--加小时
--返回跨两个指定日期的日期边界数和时间边界数
select dateDiff(day, '2011-06-20', getDate());
--相差秒数
select dateDiff(second, '2011-06-22 11:00:00', getDate());
--相差小时数
select dateDiff(hour, '2011-06-22 10:00:00', getDate());
select dateName(month, getDate());--当前月份
select dateName(minute, getDate());--当前分钟
select dateName(weekday, getDate());--当前星期
select datePart(month, getDate());--当前月份
select datePart(weekday, getDate());--当前星期
select datePart(second, getDate());--当前秒数
select day(getDate());--返回当前日期天数
select day('2011-06-30');--返回当前日期天数
select month(getDate());--返回当前日期月份
select month('2011-11-10');
select year(getDate());--返回当前日期年份
select year('2010-11-10');
select getDate();--当前系统日期
select getUTCDate();--utc日期
--3、 数学函数
select pi();--PI函数
select rand(100), rand(50), rand(), rand();--随机数
select round(rand(), 3), round(rand(100), 5);--精确小数位
--精确位数,负数表示小数点前
select round(123.456, 2), round(254.124, -2);
select round(123.4567, 1, 2);
--4、 元数据
select col_name(object_id('student'), 1);--返回列名
select col_name(object_id('student'), 2);
--该列数据类型长度
select col_length('student', col_name(object_id('student'), 2));
--该列数据类型长度
select col_length('student', col_name(object_id('student'), 1));
--返回类型名称、类型id
select type_name(type_id('varchar')), type_id('varchar');
--返回列类型长度
select columnProperty(object_id('student'), 'name', 'PRECISION');
--返回列所在索引位置
select columnProperty(object_id('student'), 'sex', 'ColumnId');
--5、 字符串函数
select ascii('a');--字符转换ascii值
select ascii('A');
select char(97);--ascii值转换字符
select char(65);
select nchar(65);
select nchar(45231);
select nchar(32993);--unicode转换字符
select unicode('A'), unicode('中');--返回unicode编码值
select soundex('hello'), soundex('world'), soundex('word');
select patindex('%a', 'ta'), patindex('%ac%', 'jack'), patindex('dex%', 'dexjack');--匹配字符索引
select 'a' + space(2) + 'b', 'c' + space(5) + 'd';--输出空格
select charIndex('o', 'hello world');--查找索引
select charIndex('o', 'hello world', 6);--查找索引
select quoteName('abc[]def'), quoteName('123]45');
--精确数字
select str(123.456, 2), str(123.456, 3), str(123.456, 4);
select str(123.456, 9, 2), str(123.456, 9, 3), str(123.456, 6, 1), str(123.456, 9, 6);
select difference('hello', 'helloWorld');--比较字符串相同
select difference('hello', 'world');
select difference('hello', 'llo');
select difference('hello', 'hel');
select difference('hello', 'hello');
select replace('abcedef', 'e', 'E');--替换字符串
select stuff('hello world', 3, 4, 'ABC');--指定位置替换字符串
select replicate('abc#', 3);--重复字符串
select subString('abc', 1, 1), subString('abc', 1, 2), subString('hello Wrold', 7, 5);--截取字符串
select len('abc');--返回长度
select reverse('sqlServer');--反转字符串
select left('leftString', 4);--取左边字符串
select left('leftString', 7);
select right('leftString', 6);--取右边字符串
select right('leftString', 3);
select lower('aBc'), lower('ABC');--小写
select upper('aBc'), upper('abc');--大写
--去掉左边空格
select ltrim(' abc'), ltrim('# abc#'), ltrim(' abc');
--去掉右边空格
select rtrim(' abc '), rtrim('# abc# '), rtrim('abc');
--6、 安全函数
select current_user;
select user;
select user_id(), user_id('dbo'), user_id('public'), user_id('guest');
select user_name(), user_name(1), user_name(0), user_name(2);
select session_user;
select suser_id('sa');
select suser_sid(), suser_sid('sa'), suser_sid('sysadmin'), suser_sid('serveradmin');
select is_member('dbo'), is_member('public');
select suser_name(), suser_name(1), suser_name(2), suser_name(3);
select suser_sname(), suser_sname(0x01), suser_sname(0x02), suser_sname(0x03);
select is_srvRoleMember('sysadmin'), is_srvRoleMember('serveradmin');
select permissions(object_id('student'));
select system_user;
select schema_id(), schema_id('dbo'), schema_id('guest');
select schema_name(), schema_name(1), schema_name(2), schema_name(3);
--7、 系统函数
select app_name();--当前会话的应用程序名称
select cast(2011 as datetime), cast('10' as money), cast('0' as varbinary);--类型转换
select convert(datetime, '2011');--类型转换
select coalesce(null, 'a'), coalesce('123', 'a');--返回其参数中第一个非空表达式
select collationProperty('Traditional_Spanish_CS_AS_KS_WS', 'CodePage');
select current_timestamp;--当前时间戳
select current_user;
select isDate(getDate()), isDate('abc'), isNumeric(1), isNumeric('a');
select dataLength('abc');
select host_id();
select host_name();
select db_name();
select ident_current('student'), ident_current('classes');--返回主键id的最大值
select ident_incr('student'), ident_incr('classes');--id的增量值
select ident_seed('student'), ident_seed('classes');
select @@identity;--最后一次自增的值
select identity(int, 1, 1) as id into tab from student;--将studeng表的烈属,以/1自增形式创建一个tab
select * from tab;
select @@rowcount;--影响行数
select @@cursor_rows;--返回连接上打开的游标的当前限定行的数目
select @@error;--T-SQL的错误号
select @@procid;
--8、 配置函数
set datefirst 7;--设置每周的第一天,表示周日
select @@datefirst as '星期的第一天', datepart(dw, getDate()) AS '今天是星期';
select @@dbts;--返回当前数据库唯一时间戳
set language 'Italian';
select @@langId as 'Language ID';--返回语言id
select @@language as 'Language Name';--返回当前语言名称
select @@lock_timeout;--返回当前会话的当前锁定超时设置(毫秒)
select @@max_connections;--返回SQL Server 实例允许同时进行的最大用户连接数
select @@MAX_PRECISION AS 'Max Precision';--返回decimal 和numeric 数据类型所用的精度级别
select @@SERVERNAME;--SQL Server 的本地服务器的名称
select @@SERVICENAME;--服务名
select @@SPID;--当前会话进程id
select @@textSize;
select @@version;--当前数据库版本信息
--9、 系统统计函数
select @@CONNECTIONS;--连接数
select @@PACK_RECEIVED;
select @@CPU_BUSY;
select @@PACK_SENT;
select @@TIMETICKS;
select @@IDLE;
select @@TOTAL_ERRORS;
select @@IO_BUSY;
select @@TOTAL_READ;--读取磁盘次数
select @@PACKET_ERRORS;--发生的网络数据包错误数
select @@TOTAL_WRITE;--sqlserver执行的磁盘写入次数
select patIndex('%soft%', 'microsoft SqlServer');
select patIndex('soft%', 'software SqlServer');
select patIndex('%soft', 'SqlServer microsoft');
select patIndex('%so_gr%', 'Jsonisprogram');
--10、 用户自定义函数
--查看当前数据库所有函数
--查询所有已创建函数
select definition,* from sys.sql_modules m join sys.objects o on m.object_id = o.object_id
and type in('fn', 'if', 'tf');
--创建函数
if (object_id('fun_add', 'fn') is not null)
drop function fun_add
go
create function fun_add(@num1 int, @num2 int)
returns int
with execute as caller
as
begin
declare @result int;
if (@num1 is null)
set @num1 = 0;
if (@num2 is null)
set @num2 = 0;
set @result = @num1 + @num2;
return @result;
end
go
--调用函数
select dbo.fun_add(id, age) from student;
--自定义函数,字符串连接
if (object_id('fun_append', 'fn') is not null)
drop function fun_append
go
create function fun_append(@args nvarchar(1024), @args2 nvarchar(1024))
returns nvarchar(2048)
as
begin
return @args + @args2;
end
go
select dbo.fun_append(name, 'abc') from student;
--修改函数
alter function fun_append(@args nvarchar(1024), @args2 nvarchar(1024))
returns nvarchar(1024)
as
begin
declare @result varchar(1024);
--coalesce返回第一个不为null的值
set @args = coalesce(@args, '');
set @args2 = coalesce(@args2, '');
set @result = @args + @args2;
return @result;
end
go
select dbo.fun_append(name, '#abc') from student;
--返回table对象函数
select name, object_id, type from sys.objects where type in ('fn', 'if', 'tf') or type like '%f%';
if (exists (select * from sys.objects where type in ('fn', 'if', 'tf') and name = 'fun_find_stuRecord'))
drop function fun_find_stuRecord
go
create function fun_find_stuRecord(@id int)
returns table
as
return (select * from student where id = @id);
go
select * from dbo.fun_find_stuRecord(2);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号