十四、字符处理命令、打包压缩与解压、inode与软硬链接
今日内容:
1、字符处理命令:sort、uniq、cut、tr、wc;
2、打包压缩与解压:tar、zip;
3、文件系统:inode、软硬链接一、字符处理命令
1>sort命令
sort 将文件内容排序
sort file.txt #不加选项默认以字母排列
选项
-n #按数值大小排序
-r #反向排序
-k #以某列排序
-t #指定分隔符,默认为空格空格符准备文件,写入一段无序的内容
cat >> file.txt <<EOF
b:3
c:2
a:4
e:5
d:1
f:11
EOF#执行结果如下:
[root@peng ~]# sort file.txt
a:4 #不加选型默认以字母排列
b:3
c:2
d:1
e:5
f:11
[root@peng ~]# sort -t ':' -nk2 file.txt
d:1 #-t指定分隔符为冒号,-n指定数值,k为指定第二列
c:2
b:3
a:4
e:5
f:11
[root@peng ~]# sort -t ':' -nrk2 file.txt
f:11 #t指定分隔符为冒号,-n指定数值,k为指定第二列,r为倒序
e:5
a:4
b:3
c:2
d:12、uniq命令
uniq #用于检查、删除文本文件中重复的行列,一般与sort命令结合使用
默认不加选项,所有内容只显示一行文本
选项
-c #显示重复行的次数,1代表无重复
-d #显示重复的行
-u #显示不重复的行
准备文件,写入一段无序的内容:
cat > file.txt <<EOF
hello
123
hello
123
func
EOF#执行结果如下:
[root@peng ~]# sort file.txt
123
123
func
hello
hello
[root@peng ~]# sort file.txt | uniq
123
func
hello
[root@peng ~]# sort file.txt | uniq -c
2 123
1 func
2 hello
[root@peng ~]# sort file.txt | uniq -d
123
hello3>cut命令
cut 用来显示行中的指定部分,删除文件中的指定字段
选项
-d #指定字段的分隔符,默认的字段分隔符为“TAB”
-f #显示指定字段的内容
, #几和几
- #几到几
执行结果:
[root@localhost ~]# head -1 /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# head -1 /etc/passwd | cut -d ":" -f1,3,4,6
root:0:0:/root4>tr命令
tr 替换或删除
选项
-d #删除字符
#两种情况的执行结如下:
情况一:root替换为大写;删除‘root’相关单词字符
[root@peng ~]# head -1 /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@peng ~]# head -1 /etc/passwd |tr 'root' 'ROOT'
ROOT:x:0:0:ROOT:/ROOT:/bin/bash
[root@peng ~]# head -1 /etc/passwd |tr -d 'root'
:x:0:0::/:/bin/bash
情况二:将所有包含egon的字母都会替换
[root@peng ~]# echo 'hello egon qq:378533872' >1.txt
[root@peng ~]# tr 'egon' 'EGON' <1.txt
hEllO EGON qq:378533872
[root@peng ~]# 5>wc命令
wc 统计,计数数字
选项
-c 统计Bytes数
-l 统计行数
-w 统计单词数,默认以空白字符作为分隔符
#执行效果如下:
[root@peng ~]# ps aux |wc -l
105 #运行的进程数
[root@peng ~]# cat file.txt
b:3
c:2
a:4
e:5
f:11 hello world
[root@peng ~]# wc -c file.txt
33 file.txt
[root@peng ~]# wc -l file.txt
5 file.txt
[root@peng ~]# wc -w file.txt
7 file.txt
[root@peng ~]# wc file.txt
5 7 33 file.txt二、打包压缩**
1、打包压缩
打包:把多个东西放入袋子里;
压缩:把袋子的空间挤压一下;
Linux下常见的压缩包类型
.zip #zip压缩工具
.gz #gzip压缩工具,只能压缩文件,会删除源文件(通常配合tar使用)
.bz2 #bzip2压缩工具,只能压缩文件,会删除源文件(通常配合tar使用)
.tar.gz #先用tar命令归档打包,在使用gzip压缩
.tar.bz2 #先用tar命令归档打包,在使用gzip压缩选项
#常用打包选项为cvf
#常用压缩选项为czvf
c #创建新的
v #详细过程
f #打包后文件路径
z #用gzip压缩算法
j #用bzip2压缩算法
1>打包
tar cvf etc_bak.tar /etc/ #创建,详细,打包文件路径
2>压缩
gzip etc_bak.tar #文件体积变小,并且加上后缀.gz
3>上述两步可合二为一:打包并压缩
tar czvf etc_bak.tar.gz /etc/ #用gzip压缩算法压缩
tar czvf etc_bak.tar.bz2 /etc/#用bzip2压缩算法压缩
tar cjvf etc_bak.tar.bz2 /etc/#用bzip2压缩算法压缩
4>zip压缩
zip 压缩后路径或文件名 压缩文件或路径
zip /test/bak.zip a.txt b.txt c.txt
#zip的第一个参数为压缩包路径,其余为被压缩的文件2、解压缩
1>针对.tar.gz 或tar.bz2
统一使用:tar xvf 压缩包 -C 解压路径 #无需指定解压算法,tar会自动判断
#格式如下:
tar xvf 1.tar.gz -C /root
或
tar xvf 1.tar.bz2 -C /root
2>针对zip:使用unzip
选项
-d #指定解压路径
#格式如下:
unzip 1.zip3、拓展选项
tar zcvf `date "+%Y_%m_%d_%H-%M-%S"`_etc.gz /etc
2020_10_27_15-55-24_etc.gz #备份文件
拓展选项 #打包压缩通常用语备份文件,文件名需见名知意且该带上时间、主机名之类
-d #根据时间的描述显示日期
-s #修改日期
%F #显示日期(%Y-%m-%d)
%H #小时,24小时制(00~23)
%M #分钟(00~59)
%s #从1970年1月1日0时0分0秒到目前经历的秒数
%S #显示秒(00~59)
%T #显示时间,24小时制(hh:mm:ss)
%d #一个月的第几天(01~31)
%% #一年的第几天(001~336)
%m #月份(01~12)
%w #一周的第几天(0为周日)
%W #一年的第几周(00~53,周一为第一天)
%y #年的最后两个数字(1999则为99)
%Y #年,实际示例:
[root@localhost ~]# date
2020年 08月 12日 星期三 20:55:48 CST
[root@localhost ~]# date +%F
2020-08-12
[root@localhost ~]# date +%Y-%m-%d
2020-08-12
[root@localhost ~]#
[root@localhost ~]# date +%y-%m-%d
20-08-12
[root@localhost ~]# date +%T
00:01:03
[root@localhost ~]# date +%H:%M:%S
00:01:11
[root@localhost ~]#
[root@localhost ~]# date +%w
3
[root@localhost ~]# date +%s
1597236988
[root@localhost ~]# date +%d
12
[root@localhost ~]# date +%W
32
[root@localhost ~]# date +%j
225
[root@localhost ~]# date -d "-1 day" +%F
2020-08-11
[root@localhost ~]# date -d "1 day" +%F
2020-08-13
[root@localhost ~]# date -d "+1 day" +%F
2020-08-13
[root@localhost ~]# date -d "3 years" +%F
2023-08-12
[root@localhost ~]# date -d "+3 years" +%F
2023-08-12
[root@localhost ~]# date -d "+3 hours" +%F_%H:%M:%S
2020-08-12_23:58:06
[root@localhost ~]# date -s 20201111
2020年 11月 11日 星期三 00:00:00 CST
[root@localhost ~]# date -s 11:11:11
2020年 11月 11日 星期三 11:11:11 CST
[root@localhost ~]# date -s "20201111 11:11:11"
2020年 11月 11日 星期三 11:11:11 CST
[root@localhost ~]# date +%F
2020-11-11
[root@localhost ~]# date +%T
11:11:29备份效果为: [root@localhost ~]# tar czvf `date +%F`_bak.tar.gz /etc三、文件系统
文件系统是操作系统中负责操作硬盘的一段程序,文件系统提供了文件的概念。
df #显示磁盘分区的已用/可用空间,默认为KB单位
-h #KB以上的单位来显示
-T #显示文件类型
-a #显示全部文件系统
superblock #总block块
inode #存放文件的属性
block #真实的数据
stst 1.txt #查看文件最近的访问、更改、改动时间
#最近访问:第一次打开文件时间保持,加载到内存后时间不变
#最近更改:只有改内容才会变
#最近改动:只要改就变,指最近修改INode时间,例如文件类型(常规、目录、符号链接等),权限,文件大小,创建/修改/访问时间等都是保存INode中。
echo 3 > /proc/sys/vm/drop_caches #可释放部分缓存

1>了解inode
Linux系统一切皆文件,大部分的Linux文件系统(如ext2、ext3)规定:任意文件都有三部分组成:
1>目录项:文件名与其对应的inode号
2>inode:又称文件“索引节点”,包含文件的基础信息及数据块的指针
3>数据块:是记录文件真实内容的地方,又称block
#从根本上讲,inode中存放的是除了文件的名字、真实内容之外,所有有关文件的信息/元数据(metadata)如下:
inode编号
用来识别文件类型、以及用于stat C函数的模式信息
链接数,即有多少文件名指向这个inode
属主的ID(UID)
属主的组ID(GID)
文件的字节数
文件所使用的的磁盘块的实际数目
指向数据块的指针
文件的三个时间戳:
1>ctime指inode上一次变动的时间
2>mtime指文件内容上一次变动的时间
3>atime指文件上一次打开时间
#总之,除了文件名以外的所有文件信息,都存在inode之中。
可用stat命令查看某个文件的inode信息:stat 1.txt
2>iode的大小☆★
★ inode也会消耗硬盘空间,即在硬盘格式化时,操作系统自动将硬盘分为两个区域:存放文件的数据区、inode区;
★ 每个inode节点的大小,一般是128字节或256字节,inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode:
★ #假定在一块1GB的硬盘中,每个inode的节点大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%;
df -i #查看每个硬盘分区的inode总数和已经使用的数量
sudo dumpe2fs -h /devhda |grep 'Inode size' #查看每个inode节点的大小
PS:由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但硬盘还未存满的情况,这时就无法在硬盘上创建新文件;3>inode号码
★ 每个inode都有一个号码,操作系统就用inode号来识别不同的件;
Linux内部不使用文件名,而使用inode号来识别文件,对系统来说,文件名只是inode号便于识别的别称,表面上,用户通过文件名打开文件,实际上系统内部这个过程分为三步:
1>系统找到此文件名对应的inode号
2>通过inode号,获取inode信息
3>根据inode信息,找到文件数据所在的block,读取数据
ls -i 1.txt #查看文件对应的indoe号4>目录项
Linux系统中,目录(directory)也是一种文件,打开目录就是打开目录文件;
#目录文件的结构很简单,就是一系列目录项(dirent)的列表,每个目录项由两部分组成:文件的文件名、文件名对应的inode号;
ls /etc #只能列出目录中所有的文件名
ls -i /etc #则列出文件名与inode号
PS:要查看文件的详细信息,必须根据inode号,访问inode节点,读取信息:ls -li5>硬链接、软连接
硬链接
概念:文件名即文件的硬链接,就是给文件起了个别名,对应的inode号与源文件一样。
#详解:文件名和inode号是‘一一对应’关系,每个inode号对应一个文件名,可linux系统允许多个文件名指向同一个inode号,这意味着可用不同文件名访问同样的内容,对文件内容进行修改,就会影响到所有文件名;但删除一个文件名,却不影响另一个文件名的访问,这种情况即成为硬链接。
ln 1.txt file1 #创建硬链接为file1
硬链接的限制:
1. 不允许普通用户给目录创建硬链接 (可能把目录树变成环形图,从而无法定位一个文件)
2. 不能跨文件系统创建硬链接
总结:
1.具有相同inode的不同文件名
2.删除硬链接或者原文件之一,文件实体不会被删除
3.删除所有硬链接,数据会在被磁盘检查或者新数据写入时候删除回收。
4.可以给文件设置硬链接防止误删
5.通过ln [原文件] [目标文件]设置硬链接
6.通过rm -f删除硬链接
7.文件目录不可创建硬链接,因为硬链接无法跨区软连接
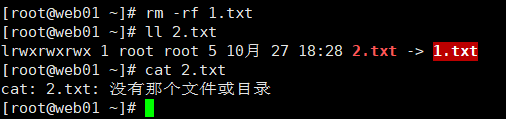
概念:类似快捷方式,它有单独的inode,指向了被连接的源文件,与路径关联;若删除源文件,打开软连接则报错;
总结:
1>软连接类似快捷方式,存放原文件路径,执行原文件
2>删除源文件,软连接依然存在,但失效
3>执行ln -s [源文件] [目标文件] 完成创建
4>软连接和源文件是不同类型文件,inode不同
5>rm -f 删除软连接
6>可以创建目录和文件的软链接,即可跨区


企业面试题:请描述Linux中软链接和硬链接的区别?
1.从定义,linux系统中,链接有两种:
#一种是软链接,类似于快捷方式,存放指向原文件inode的信息,与原文件inode不同;
#一种是硬链接,与原文件有相同的inode,可以指向数据block;
2.从创建方式:
#硬链接命令:ln [原文件] [目标文件]
#软链接命令:ln -s [原文件] [目标文件]
3.从创建对象: ln命令不能对目录创建硬链接,但是可以对目录创建软链接。因为软链接可以跨越文件系统,硬链接则不能。对目录和为客户创建的文件软链接经常用到。
4.删除软链接文件,对硬链接和原文件无影响。
5.删除文件硬链接,对原文件及软链接文件无影响
6.删除原文件,对硬链接读取数据无影响,软链接则失效。会出现红底白字状。
7.同时删除原文件和硬链接,原文件才会被真正删除
8.很多硬件设备中的快照原理,类似于硬链接原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号