C learn note
C和指针
1. 宏函数与自定义函数
宏函数与自定义函数是对立的,宏函数的优点就是自定义函数的缺点,自定义函数的缺点就是宏函数的优点。
宏函数的优点:1·执行效率高 2·节省空间
宏函数的缺点:1编译时间长 2·不安全,没有语法检查
因为宏函数在编译时直接展开,所以不像自定义函数一样需要进行函数调用,因此宏函数运行时没有通过函数名找到函数的入口地址,保存返回地址,为形参分配空间,实参分配给形参,形参入栈等操作。因此步骤少,并且不需要在栈上分配额外空间。但因此宏函数需要在编译时替换,因此编译时间长。另外,宏函数也没有语法检查,不安全。
2. 关键字
2.1 extern,static
#include <stdio.h>
//static int num = 100; // 1.static修饰全局变量,改变变量的作用域,只能在本文件中被调用,采用这种声明,编译1.c和2.c就会报错。
int num = 100; // 声明并初始化一个变量,会分配内存
void f(); // 声明一个函数
int main()
{
f();
return 0;
}
#include <stdio.h>
// 仅声明变量num,但不初始化,否则就会为其分配内存
// extern表示该变量在别处定义并初始化
extern int num;
//static void f() // 2.static修饰函数,改变函数的作用域,只能在本文件中被调用
void f()
{
printf("num = %d\n", num);
}
gcc 1.c 2.c -o main
./main
# 编译多个文件时,要保证只有一个main函数
#include <stdio.h>
void Add()
{
static int x = 0; // 3.static修饰局部变量,叫静态变量(存放在静态数据区),改变变量的生命周期,直到程序结束释放
//int x = 0;
x ++ ;
printf("%d\n", x);
}
int main()
{
int i;
for(i = 0; i < 3; i ++ )
Add();
return 0;
}
2.2 const
1.const 修饰普通变量即const修饰只读变量,不能通过变量本身修改变量的值,但可以通过其他方式(指针)修改
#include <stdio.h>
int main()
{
const int a = 100;
int *p = (int *)&a;
*p ++ ;
printf("%d\n", a);
return 0;
}
运行上面的程序之后可以发现a的值仍然被修改了,所以说这也就说明了一个常见的误解,认为const修饰的就是常量,实际上并不是
2.const修饰指针 (就近原则)
int a = 1;
// 指向常量的指针
// 由于const和int的位置可以互换,所以可以忽略int,原式就成了 const *q,const距离*最近,因此const修饰的是*q
const int *q = &a;
int const *q = &a;
// 指针常量
// const距离q最近,因此const修饰的是q
int *const q = &a;
3.const修饰函数形参
#include <stdio.h>
#include <stdlib.h>
void new_strcpy(char *dest, const char *src)
{
while((*dest ++ = *src++) != '\0') ;
}
int main()
{
char d[20] = "hello,world";
char s[20] = "newstr";
new_strcpy(d, s);
puts(d);
return 0;
}
4.const修饰函数的返回值
若函数的返回值是指针,且用const修饰,则函数返回值指向的内容是常数,不可被修改,此返回值仅能赋值给const修饰的相同类型的指针。如:
#include <stdio.h>
#include <stdlib.h>
const int * f1()
{
int * p;
p = new int;
*p = 1;
return p;
}
int main()
{
const int *p; // 改为int *p1;则编译时报错:“[8] error: invalid conversion from 'const int*' to 'int*'” (编译器code::block);
p = f1();
return 0;
}
若主函数改为:
int main()
{
const int * p1;
p1 = f1();
*p1 = 2; //则编译时报错:"[10] error: assignment of read-only location '* p1'" (编译器code::block);
}
如果函数返回值是数值(by value),因C++中,返回值会被复制到外部临时的存储单元中,故const 修饰是没有任何价值的。例:不要把函数int fun1() 写成const int func1()。
同理不要把函数A GetA(void) 写成const A GetA(void),其中A 为用户自定义的数据类型。
如果返回值是对象,将函数A fun2() 改写为const A & fun2()的确能提高效率。但此要注意,要确定函数究竟是想返回一个对象的“copy”,还是仅返回对象的“别名”即可,否则程序会出错。
3. 危险的指针
警告⚠️:没有将一个free掉的指针置NULL
一个指针被free之后,它仍然指向原来指向的内存区域。但是该空间的内容已经不再是之前的值了,已经释放掉了。
这时候的指针我们称为野指针。将它置为NULL后,可以防止被误用,同时也可以后续作为判断该指针是否已经释放的标记
3.1 悬挂(悬空)指针
悬挂指针:当指针所指向的对象被释放,但是该指针没有任何改变,以至于其仍然指向已经被回收的内存地址,这种情况下该指针被称为悬挂指针;
3.2 野指针
野指针:未初始化的指针被称为野指针。
4. gcc编译器
4.1 编译过程
4.1.1 预处理
命令 gcc -E x.c -o x.i ,生成一个 .i 文件(预处理文件)
预处理就是处理所有# 开头的行,即展开头文件和宏定义和条件编译。
其中 #include <stdio.h> 中的 <> 表示在系统里面找 stdio.h 文件。在 /usr/include 目录下有很多头文件。
4.1.2 编译
命令 gcc -S x.i -o x.s ,生成一个.s 文件(汇编文件)
4.1.3 汇编
命令 gcc -c x.s -o x.o ,生成一个.o 文件(二进制文件)
4.1.4 链接
生成一个可执行二进制文件。默认链接方式是动态链接。
对于一条语句 printf("xxx") ,动态链接会链接 printf 的位置信息,静态链接会链接 printf 的具体实现。因此,静态链接的文件大小比静态链接的文件大得多。但是静态链接对环境的依赖比动态链接要小,加入系统中不存在 printf 的实现,那么动态链接就无法执行。
4.2 其它常用参数
- -g:在可执行程序中包含标准调试信息。
- -v:打印出编译器内部个过程的命令行信息和编译器的版本
- -I dir:在头文件的搜索路径列表中添加 dir 目录
- -L dir:在库文件的搜索路径列表中添加 dir 目录
- -static:链接静态库
- -l library:链接名为 library 的库文件
4.3 静态库
静态库文件格式:.a 结尾,lib 开头。
创建静态库文件步骤:
- 写源文件,通过
gcc -c xxx.c生成目标文件。 - 用
ar归档目标文件,生成静态库。具体位为:ar -crv libname.a lib1.o lib2.o,执行该命令即可创建名为name的静态库。
上述命令中 crv 是 ar的命令选项:
- c 如果需要生成新的库文件,不要警告
- r 代替库中现有的文件或者插入新的文件
- v 输出详细信息
创建静态库举例:
f1.c
#include <stdio.h>
void f1()
{
printf("this is f1...\n");
}
f2.c
#include <stdio.h>
void f2()
{
printf("this is f1...\n");
}
main.c
#include <stdio.h>
// 声明函数
void f1();
void f2();
int main()
{
f1();
f2();
return 0;
}
以 f1.c, f2.c为源文件创建静态库:
gcc -c f1.c f2.c #生成目标文件f1.o f2.o
ar -crv libmylib.a f1.o f2.o
链接静态库:
gcc main.c -o main -staic -l mylib -L .
# 虽然静态库文件为:libmylib.a,但是该静态库的名字是 mylib
# -l mylib 表示链接名为 mylib 的静态库
# -L . 表示将当前目录添加到搜索静态库文件的目录
4.4 动态库
动态库文件格式:.so 结尾
创建并链接动态库:
gcc -fPIC -shared -o libxxx.so xx1.c xx2.cgcc main.c -o main -L . -l xxx
fPIC 作用于编译阶段,告诉编译器产生与位置无关代码(Position-Independent Code),则产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载器加载到内存的任意位置,都可以正确的执行。这正是共享库所要求的,共享库被加载时,在内存的位置不是固定的。
PIC就是position independent code
PIC使.so文件的代码段变为真正意义上的共享
如果不加 -fPIC,则加载 .so文件的代码段时,代码段引用的数据对象需要重定位, 重定位会修改代码段的内容,这就造成每个使用这个 .so文件代码段的进程在内核里都会生成这个 .so文件代码段的copy.每个 copy都不一样,取决于这个 .so文件代码段和数据段内存映射的位置.
不加 fPIC编译出来的 so,是要再加载时根据加载到的位置再次重定位的.(因为它里面的代码并不是位置无关代码)
如果被多个应用程序共同使用,那么它们必须每个程序维护一份so的代码副本了.(因为so被每个程序加载的位置都不同,显然这些重定位后的代码也不同,当然不能共享)
我们总是用fPIC来生成so,也从来不用fPIC来生成a.
fPIC与动态链接可以说基本没有关系,libc.so一样可以不用fPIC编译,只是这样的so必须要在加载到用户程序的地址空间时重定向所有表目.因此,不用fPIC编译so并不总是不好.
如果你满足以下4个需求/条件:
1.该库可能需要经常更新
2.该库需要非常高的效率(尤其是有很多全局量的使用时)
3.该库并不很大.
4.该库基本不需要被多个应用程序共享如果用没有加这个参数的编译后的共享库,也可以使用的话,可能是两个原因:
1:gcc默认开启-fPIC选项
2:loader使你的代码位置无关从GCC来看,shared应该是包含fPIC选项的,但似乎不是所以系统都支持,所以最好显式加上fPIC选项。
还是上面的三个文件。执行完上述两个操作之后,执行 ./main ,报错:./main: error while loading shared libraries: libmylib.so: cannot open shared object file: No such file or directory
这是因为链接动态库虽然是在当前目录下链接的,但是在程序执行的时候并不在当前目录下找,我们可以用命令 ldd main 查看 main 程序在哪里寻找动态库。
ldd命令用于查看二进制文件所有用到的动态库在哪
linux-vdso.so.1 (0x00007ffc4edf3000)
libmylib.so => not found
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f23af86c000)
/lib64/ld-linux-x86-64.so.2 (0x00007f23afa6e000)
可以看到,我们的动态库 libmylib.so 显示 not found,而系统自带的动态库 libc.so.6 在目录 /lib/x86_64-linux-gnu/ 下。
因此我们只需要把 libmylib.so 复制到该目录下即可:sudo cp libmylib.so /lib/x86_64-linux-gnu/,然后 main 程序就可以正常执行了。
5. sizeof 产生的问题
5.1 仍然需要加括号的情况
首先,sizeof是一个关键字而不是一个函数。其次,当我们用sizeof求字节长度时,最好加上括号,例如:
sizeof struct node;
// 上面的代码编译起就会报错,因为他被解释为:sizeof struct
sizeof a + 1
// 会被解释为: sizeof(a) + 1;
// 而不是 sizeof(a + 1)
所以说为了避免由于优先级问题导致的二义性,还是加上括号吧!
另外,看下面的例子:
#include <stdio.h>
int main()
{
int a = 1;
printf("%ld\n", sizeof(0 == 1));
printf("%ld\n", sizeof(a = 4));
printf("%d\n", a);
return 0;
}
/* output
4
4
1
*/
5.2 sizeof到底是什么
网上有人说sizeof是一个操作符,但我觉得它更像一个特殊的宏,因为它是在编译阶段求值的。
在上面的例子中,
printf("%ld\n", sizeof(0 == 1));
printf("%ld\n", sizeof(a = 4));
在编译阶段会被翻译为:
printf("%ld\n", 4);
printf("%ld\n", 4;
因为C语言中没有bool类型,而是以int类型表示,所以
sizeof(0 == 1) 就相当于 sizeof(int)
并且我们在第二条语句中令a=4,但输出的仍然是1,这说明a的值没有被改变,并且sizeof(a=4)被解释为sizeof(int)
其原因就在于sizeof在编译阶段处理的特性。由于sizeof不能被编译成机器码,所以sizeof作用范围内,也就是()里面的内容也不能被编译,而是被替换成类型。=操作符返回左操作数的类型,所以a=3相当于int.
5.3 总结
所以,sizeof是不可能支持链式表达式的,这也是和一元操作符不一样的地方。
结论:不要把sizeof当成函数,也不要看作一元操作符,把他当成一个特殊的编译预处理。
6. 内存管理
6.1 内存结构
在实际的程序当中,我们操作的都是虚拟内存,而不是实际的物理内存(因为操作者不一定能正确操纵内存,如果直接操作物理内存,可能会导致操作系统死掉等问题)。
虚拟内存与物理内存之间是映射关系,虚拟内存映射一小部分物理内存。在linux中,虚拟内存一般是4g,默认按照1:3分配(可以调整)。1个g是内核态、另外3个g是用户态。
其中3个g一般又分为5块。
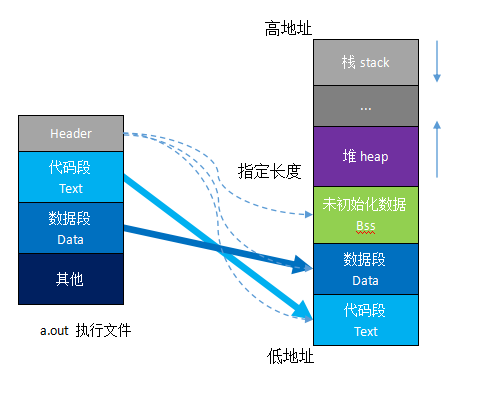
相关段总结如下。
| 段名 | 存储属性 | 内存分配 |
|---|---|---|
| 代码段 .text | 存放可执行程序的指令,存储态和运行态都有 | 静态 |
| 数据段 .data | 存放已初始化(非零初始化的全局变量和静态局部变量)的数据,存储态和运行态都有 | 静态 |
| bss段 .bss | 存放未初始化(未初始化或者0初始化的全局变量和静态局部变量)的数据,存储态和运行态都有 | 静态 |
| 堆 heap | 动态分配内存,需要通过malloc手动申请,free手动释放,适合大块内存。容易造成内存泄漏和内存碎片。运行态才有。由程序员手动申请。 | 动态 |
| 栈 stack | 存放函数局部变量和参数以及返回值,函数返回后,由操作系统立即回收。栈空间不大,使用不当容易栈溢出。运行态才有。系统自动分配。 | 静态 |
看下面的代码
#include <stdio.h>
#include <stdlib.h>
int main()
{
char s1[size] = "hello,world!";
char *s2 = "hello,world!";
char *s3 = malloc(128);
return 0;
}
上述代码中,s1,s2,s3都是局部变量,s1是一个数组,s2,s3是一个指针,其本身被分配在栈中。
但是s2中的“hello,world!”是一个字符串常量,其也占用内存,并且分配在数据段,s2指向这个字符串常量的地址。
s3中malloc分配的大小为128字节的内存在堆中,s3指向堆中分配的这块内存。
可以看出,同样是局部变量,s1只占用了一块内存,而s2,s3占用了两块内存。
6.2 堆和栈的区别
- 管理方式不同:堆由程序员管理,栈由系统管理。
- 空间大小不同:栈的空间比较小,堆的空间比较大。
- 是否产生碎片:堆由于malloc/new,从而产生大量的碎片,使程序效率降低(虽然程序结束后操作系统会对内存进行回收管理),对于栈来讲,内存连续分配,则不存在这个问题。
- 增长方向不同:栈向下(低地址)增长,堆向上(高地址)增长。
- 分配效率不同:栈是极其系统提供的数据结构,计算机会在底层对栈提供支持,分配专门的寄存器存放栈的地址,压栈出zhan都有专门的指令执行。堆则是C函数库提供的,它的机制很复杂,例如为了分配一块内存,库函数会按照一定的算法,在堆内存中搜索可用的,足够大的空间,如果没有(可能是由于内存碎片太多),就有需要操作系统来重新整理内存空间,这样就有机会分到足够大的内存,然后返回。显然,堆的效率比栈要低得多。
- 分配方式不同:堆都是程序中由malloc()函数动态申请分配并由free()函数释放的,栈的分配和释放是由编译器完成的,栈的动态分配由alloca()函数完成,但是栈的动态分配是和堆不同的,它的动态分配是由编译器完成申请和释放的,无需手工实现。
6. 3 常见内存错误及对策
- 指针没有指向一块合法的内存(野指针):例如声明了一个指针但没有初始化就使用这个指针。
- 为指针分配的内存太小:例如为字符串str,malloc内存时,大小为strlen(str)+1,如果没有+1,malloc的大小就不够。
- 内存分配成功但未初始化:对于未初始化的指针,其值是未定义的。可以使用memset初始化。
- 内存越界:段错误。
- 内存泄露:没有释放掉分配的内存。
- 内存释放之后:虽然内存释放了,但是指针仍然指向该内存,所以要将指针置为空吗,否则就会变为野指针。free(p)释放的是p指向的内存,而不是p本身。
- 内存已经释放,但是继续通过指针来使用:分为堆释放(使用已经free掉内存的指针),栈释放(返回一个局部变量的地址)。
7. 可变参数
7.1 带可变参数的函数由来
当函数中的参数个数不确定时,这时候就需要带可变参数的函数!
如我们经常使用的C库函数printf()实际就是一个可变参数的函数,
其原型为:
int printf( const char* format, ...);
它除了有一个参数format固定以外,后面跟的参数的个数和类型是可变的。例如我们可以有以下不同的调用方法:
printf( "%d ",i); printf( "%s ",s); printf( "the number is %d ,string is:%s ", i, s);
7.2 带可变参数函数的实现
7.2.1 原理
- 使用了指针参数来解决参数的可变问题,指针参数随着其移动指向不同的参数;
- C语言的函数形参是从右向左压入堆栈的,以保证栈顶是第一个参数。
C语言标准库中头文件stdarg.h索引的接口包含了一组能够遍历变长参数列表的宏。
头文件
#include <stdarg.h>
7.2.2 几个宏
(1). va_list 定义一个指针
用来定义一个表示参数表中各个参数的变量,即定义了一个指向参数的指针, 用于指示可选的参数.
如:va_list ap;
(2). va_start(ap,v) 初始化指针
使参数列表指针ap指向函数参数列表中的第一个可选参数,v是位于第一个可选参数之前的固定参数, 或者说最后一个固定参数.通常用于指定可变参数列表中参数的个数!
如有一va函数的声明是void va_test(char a, char b, char c, ...), 则它的固定参数依次是a,b,c, 最后一个固定参数v为c, 因此就是va_start(ap, c).
(3). va_arg(ap, type) 返回参数列表中指针ap所指的参数, 返回类型为type. 并使指针ap指向参数列表中下一个参数.返回的是可选参数, 不包括固定参数.
(4). va_end(ap) 清空参数列表, 并置参数指针arg_ptr无效.
#include <stdarg.h>
void simple_va_fun(int i,...)
{
va_list arg_ptr; //定义可变参数指针
va_start(arg_ptr,i); // i为最后一个固定参数
int j = va_arg(arg_ptr,int); //返回第一个可变参数,类型为int
char c = va_arg(arg_ptr,char); //返回第二个可变参数,类型为char
va_end(arg_ptr); // 清空参数指针
printf( "%d %d %c\n",i,j,c);
return;
}
int main(int argc,char *argv[])
{
simple_va_fun(100);
simple_va_fun(100,200);
simple_va_fun(100,200,'a');
return 0;
}
/*
输出为
100 4193388 ?100 200 ?100 200 a
*/
7.2.3 思路
(1)首先在函数里定义一个va_list型的变量,这里是arg_ptr,这个变量是指向参数的指针.
(2)然后用va_start宏初始化变量arg_ptr,这个宏的第二个参数是第一个可变参数的前一个参数,是一个固定的参数.
(3)然后用va_arg返回第一个可变的参数,并赋值给整数j。va_arg的第二个参数是你要返回的参数的类型,这里是int型. 返回第一个可变参数后arg_ptr指向第二个可变参数,用同样的方法返回并赋值给c,类型为char类型。
(4)最后用va_end宏结束可变参数的获取。
小结:
可变参数的函数原理其实很简单,而va系列是以宏定义来定义的,实现跟堆栈相关.我们写一个可变函数的C函数时,有利也有弊,所以在不必要的场合,我们无需用到可变参数.如果在C++里,我们应该利用C++的多态性来实现可变参数的功能,尽量避免用C语言的方式来实现。
指针专题
1. 指针简介
1.1 指针的声明
指针的标准写法:type* p;
常见的不标准的写法:type *p = &a;
在不标准的写法中,我们常常会把 解引用符号(*)与变量名联系在一起,这就导致了一些直观上的不舒服?。
例如代码:
int *p = &a;我们会自觉的把等号左边分成两个部分,类型和变量名,如果把*和变量名连在一起,那么看上去就好像是把a的地址放到了*p里面,而类型也变成了int而不是int*。但如果我们写成:
int* p = &a;这样看起来就很舒服了,a的地址存放在了指针变量p中,p它就是一个变量,它存储的是a的地址,而*p表示解引用指针变量p里面的地址,得到该地址存放的值。
所以说,推荐写成标准的形式,看起来更舒服!
1.2 指针的常识
- 指针是不占用内存空间的,其本身是地址,地址怎么会占内存空间。指针变量才占用内存空间。
- 当我们仅使用数组名时,返回的是数组首元素的地址。
- 函数用来指向或引用内存中的数据(变量或常量)。
- 指针是由地址的,指针的地址不等同于指针变量的地址。
1.3 指针的算术运算
指针变量+/-1:这里的1是指针类型的长度,而不是数字 1
Code:
int a = 1;
int* p = &a;
cout << p << endl; // -> x
cout << (p + 1) << endl; // -> x + sizeof(int)
2. 输出char类型的地址
在C++中,如果cout一个字符数组的话,那么它会沿着这个地址,一直输出这个字符串,直到遇到'\0',例如:
char*c = "hello";
cout << c << endl;
输出的结果是:hello
如果我们自作聪明的想输出第一个字符的地址,例如这样输出:
cout << &c[0] << endl;
不幸的是,这样输出的结果依旧不是我们需要的地址。实际上输出结果仍然是整个字符串。
但是,如果我们回归到C语言的话,例如用printf的话,如下:
printf("%x\n", &c[0]);
幸福的事情发生了,输出的结果是:
46f020
的确是字符串的首地址,但是,如果我们要输出字符串的地址,难道就这一种方法吗?难道我们就不可以用我们C++上的cout达到我们的效果吗?
原因:*c是靠%s, %x, %p来区分指针表达式&a[0]的输出形式的;c++没有这个格式控制,只能按一种形式输出,对char*类型的指针值就理解为串输出,所以必须对这个指针表达式做类型转换处理。
例如:
char c='a';
cout << "&c:" << &c << endl;
输出的仍然不是字符变量c的地址,而是乱码。
在C++中,字符串是以空终止符('/0')结尾的字符数组,通过字符串中第一个字符的指针访问字符串。也就是说,字符串的值是字符串中第一个字符的(常量)地址。如下的面3种形式表示:
char *str1 = "string1";
char str2[] = "string2";
char str3[] = {'s','t','r','i','n','g','3','\0'};
cout << "line 1:str1=" << str1 << endl;
cout << "line 2:str2=" << str2 << endl;
cout << "line 3:str3=" << str3 << endl;
Output:
line 1:str = string1
line 2:str2 = string2
line 3:str3 = string3
运行可知,这3行的输出就是保存的字符串的值,而并非我们认为的地址。那么,我们可以联系到前面&c,其实这就是一个char *的变量,所以,输出的自然就应该是字符串的值。可是,&c保存的字符串是没有终止符的,因此输出的也就是乱码了。
最近,在读到《C++程序设计教程》(第4版)第12章的时候,我才解决了这个疑惑。实际上,C++标准库中I/O类对输出操作符<<重载,在遇到字符型指针时会将其当做字符串名来处理,输出指针所指的字符串。既然这样,我们就别让他知道那是字符型指针,所以得进行类型转换,即:希望任何字符型的指针变量输出为地址的话,都要作一个转换,即强制char *转换成void *,如下所示:
cout<<"static_cast<void *>(&c)="<<static_cast<void*>(&c)<<endl;
cout<<"static_cast<void *>(str)="<<static_cast<void*>(str)<<endl;
此时,可以看到输出的结果就是char类型变量和字符串变量的地址了。
3. 为什么指针要使用强类型
3.1 强类型语言和弱类型语言
强类型语言是一种强制类型定义的语言,即一旦某一个变量被定义类型,如果不经强制转换,那么它永远就是该数据类型。而弱类型语言是一种弱类型定义的语言,某一个变量被定义类型,该变量可以根据环境变化自动进行转换,不需要经过现行强制转换。
其中
强类型语言包括:Java、.net、Python、C++等语言。其中Python是动态语言,是强类型定义语言,是类型安全的语言,Java是静态语言,是强类型定义语言,也是;类型安全的语言;
弱类型语言包括:VB,PHP,JavaScript等语言。其中VBScript是动态语言,是一种类型不安全的原因。
举个栗子吧:
var A=5;
var B="5"
sumA=A+B;
sumB=A-B;
sumA=55,系统默认+字符连接符,将A转化为字符串类型;而sumB=0;系统认为-是算数运算符,从而将B转化为int类型,所以sum为5-5=0;
上面就是一个弱类型语言的例子;
那么强类型语言与弱类型语言有什么优缺点呢?
强类型语言和弱类型原因其判断的根本是是否会隐形进行语言类型转变。强类型原因在速度上可能略逊于弱类型语言,但是强类型定义语带来的严谨性又避免了不必要的错误。
上面提到了动态语言与静态语言,那就讲讲动态语言静态语言的区别:
动态类型语言:动态性语言是指在运行期间才去做数据类型检查的语言,也就是说动态类型语言编程时,永远不用给任何变量指定数据类型,该语言会在第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
静态类型语言:静态类型语言与动态类则刚好相反,它的数据类型在编译期间检查,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他静态语言还有C#、Java等。
对于动态语言与静态语言的区分,其根本在于判断是在运行期间去做数据类型还是在编译期间检查。
3.2 指针为什么要使用强类型
Q:指针保存的地址的类型都是一样的,为什么还要为指针指定类型呢?
A:我们使用指针不仅仅只是用到地址,还需要经常解引用(*)来获得指针所指向地址的值或者写数据,因此我们就需要知道两个信息:①我们需要获得多少字节的内容;②采用何种方式解析数据。例如:char占用1字节,int占用4字节,他们占用字节大小是不一样的,float也占用 4字节,但是float和int的解析方式是不一样的。
Eg:指针变量保存的地址是首地址
4. 通用指针类型(void *)
5. 指向指针的指针
理解多重指针的最好方法是画图。
如果我们让一个指针指向一片内存,那么就在指针和内存之间加上一个箭头,表示指针指向内存。假设有指针p指向内存s,那么*p就可以在图中表示为由p沿着指向s的指针到s,这样多重指针不过就是多走几次罢了。
Code:
int x = 10;
int* p= &x;
int** q = &p;
int*** r = &q;
对面上面的代码,表现在图形中就是:

6. 传值调用
Code:
void Increamet(int x)
{
x = x + 1;
}
int main()
{
int a = 10;
Increment(a);
}
在上面的代码中,main中的a是实参,Increment中的x是形参,传值调用的过程就是实参映射到实参,也就是将实参的值拷贝到形参中。
7. 数组与指针
Code:
int a[3] = {1, 2, 3};
cout << &a[i] << endl; // <==> cout << (a + i) << endl;
cout << a[i] << endl; // <==> cout << *(a + i) << endl;
int *p = a;
*p ++ ; // valid
a ++ ; // invalid
指针就是数组,数组就是指针
数组的基地址就是数组首元素的地址,直接使用数组名就可以得到数组的基地址
8. 数组作为函数参数
8.1 例1
Code:
#include <iostream>
using namespace std;
int getSum(int t[]) // <==> int getSum(int *t)
{
int sum = 0;
int Size = sizeof(t) / sizeof(t[0]);
cout << "size-t : " << sizeof(t) << endl;
cout << "getSum-size: " << Size << endl;
for(int i = 0; i < Size; i ++ ) sum += t[i];
return sum;
}
int main()
{
int a[] = {1, 2, 3, 4, 5};
int Size = sizeof(a) / sizeof(a[0]);
cout << "size-a: " << sizeof(a) << endl;
cout << "main-size: " << Size << endl;
int sum = getSum(a);
cout << "sum: " << sum << endl;
return 0;
}
Output:
size-a: 20
main-size: 5
size-t : 8
getSum-size: 2
sum: 3
Explaion:
在上面的程序中,我们希望将数组 a 传递给函数 getSum 来求得数组 a 中所有元素的和(15)。
我们通过一个巧妙的方法得到数组 a 中元素的个数:sizeof(a) / sizeof(a[0]);
sizeof(a) 是数组 a 所占用的字节数,同理如果有一个 int 类型变量 i,那么 sizeof(i) = 4;sizeof(a[0]) 是数组 a 中一个元素占用的字节数。
在 main 函数中我们正确求得了 数组 a 的元素个数(5),数组 a 占用的字节数(20),然而当我们把数组 a 传递给函数 getSum 时,我们在函数内求得数组 a 的元素个数为 2,并且数组 a 占用的字节大小为 8,而不是 20 (5*sizeof(int))。
这是为什么呢?
8.2 例2
Code:
#include <iostream>
using namespace std;
void change(int t[], int n)
{
for(int i = 0; i < n; i ++ )
t[i] = t[i] * 2;
}
int main()
{
int a[5] = {1, 2, 3, 4, 5};
cout << "before change: ";
for(int i = 0; i < 5; i ++ ) cout << a[i] << ' ';
cout << endl;
change(a, 5);
cout << "after change: ";
for(int i = 0; i < 5; i ++ ) cout << a[i] << ' ';
cout << endl;
return 0;
}
Output:
before change: 1 2 3 4 5
after change: 2 4 6 8 10
Explain:
我们发现,将数组 a 传递给函数 change 之后,在 change 中执行的操作返回到了实参中。
这说明数组的传递是传引用而不是传值。
8.3 例3
Code:
#include <iostream>
using namespace std;
void out(int t[])
{
cout << "&t: " << &t << endl;
cout << "t: " << t << endl;
cout << "*t: " << *t << endl;
}
int main()
{
int a[5] = {1, 2, 3, 4, 5};
cout << "&a: " << &a << endl;
cout << "a: " << a << endl;
cout << "*a: " << *a << endl;
out(a);
return 0;
}
Output:
&a: 0x7fff33a6e2d0
a: 0x7fff33a6e2d0
*a: 1
&t: 0x7fff33a6e2b8
t: 0x7fff33a6e2d0
*t: 1
Explain:
我们发现,将数组 a 传递给函数 out 之后,数组 t 的首地址和数组 a 的首地址是一样的,但是在数组中,理应来说 &t 和 t 的结果应该是一样的,例如在 main中 &a 和 a 的结果就是一致的,但实际上打印出来的结果是不同的,这又是为什么呢?
8.4 例4
Code:
#include <iostream>
using namespace std;
void out(int *t)
{
cout << "&t: " << &t << endl;
cout << "t: " << t << endl;
cout << "*t: " << *t << endl;
for(int i = 0; i < 5; i ++ )
printf("&(t + %d)[%p] = %d\n", i, t + i, *(t + i));
}
int main()
{
int a[5] = {1, 2, 3, 4, 5};
cout << "&a: " << &a << endl;
cout << "a: " << a << endl;
cout << "*a: " << *a << endl;
out(a);
return 0;
}
Output:
&a: 0x7fff9a681e00
a: 0x7fff9a681e00
*a: 1
&t: 0x7fff9a681dd8
t: 0x7fff9a681e00
*t: 1
&(t + 0)[0x7fff9a681e00] = 1
&(t + 1)[0x7fff9a681e04] = 2
&(t + 2)[0x7fff9a681e08] = 3
&(t + 3)[0x7fff9a681e0c] = 4
&(t + 4)[0x7fff9a681e10] = 5
Explain:
我们发现,将数组 a 传递给函数 out,out 的形参是一个 int 型指针,依然可以遍历数组。
8.5 总结
- 由例4和例2可得出: type function(int a[]) <==> type function(int *a),当我们把一个数组作为参数传递给函数时,并不会传递整个数组的内容,而是仅仅传递数组的首地址。同时这也印证了那句话:数组就是指针,指针就是数组
- 由结论1,对于数组来说,不使用传值方式,总是传引用。因为有时候数组可能很大,拷贝整个数组没有太大意义,它会耗费大量内存。
- 由结论2,我们便可以知道为什么例3中,在函数 out 中打印 &t 和 t是不一样结果了,因为编译器把 int t[] 转换成了 int *t,因此 t 本质上不是一个数组,而是一个指向数组的指针。所以在栈中,只会申请 8 字节(64位机器一个指针占用的内存空间)空间,用来存放这个指针 t,所以说&t 实际上打印的是在栈中 t 的地址,而 t 则打印的是指针变量 t 的内容,也就是它指向的地址(即数组 a 的地址)。
- 由2和3,也就解释了例1 中为什么在函数 getSum中,sizeof(t) = 8,因为我们传递过去的不是一个完整的数组,而是指向这个数组的指针。
9. 指针和字符数组
——当我们在 C 语言中谈论字符数组时,基本上就是在讨论字符串
9.1如何把字符串存入字符数组
——首要的需求就是字符数组必须足够大,大到能够容纳字符串
一个足够大的字符数组是指它的大小>=字符的数量 +1,因为在字符串中必须指明结束标志(\0),但整型和浮点型数组没有结束符, 完全要自己严格控制元素的数量。
9.2 字符数组的声明
Code:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char s[] = "john"; // 用双引号给字符数组复制,编译器会自动给字符串添加结束标志'\0',因为字符数组的长度就是字符串长度+1(\0)
cout << sizeof(s) << endl; // 5, 包含'\0'
cout << strlen(s) << endl; // 4,不包含 '\0'
char a[] = {'1', '2', '3', '4'}; // 需要手动添加结束标志,这里因为没有添加 '\0',strlen(a)出错
cout << sizeof(a) << endl; // 4
cout << strlen(a) << endl; // 8,出错
char b[] = {'1', '2', '\0'}; // 手动添加'\0'
cout << sizeof(b) << endl; // 3
cout << strlen(b) << endl; // 2
return 0;
}
Tips:
char s[] = "john";
// 不可以写为下面的形式:
char s[107];
s = "john";
// 用双引号初始化必须在同一行
// 其次,下面的声明方式是不严谨的,因为我们不知道字符串的结束在那
// 因此,可能发生奇怪的问题
char a[] = {'1', '2', '3', '4'};
// 例如下面:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char a[] = {'1', '2', '3', '4'};
char *s = a;
cout << a << endl;
cout << s << endl;
return 0;
}
// 输出:
1234t��M�
1234t��M�
// 可以发现出现了乱码
9.3 char *
Code:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char *s = "Hello";
s[0] = 'A';
return 0;
}
Explain:
上面的代码会报错,因此把 "Hello" 的值----也就是字符串常量字面值,也就是 "Hello" 的地址,准确来说是起始地址----赋给字符指针 str,Linux下 "Hello"字符串常量是存放于只读数据区(常量区)的,不可以修改。
因此如果我们要把 char* 传递到函数中,那么形参的类型最好是 const char*
对于
char s[] = "Hello";s[] 是一个字符数组,编译器首先在栈中分配一定的连续空间用于存放 “Hello” 中的字符以及结尾符,然后把字符串常量的内容,也就是
"Hello" 中的各个字符和结尾符复制到这个栈中的连续空间中。str是数组名,用来表示这个连续栈空间的起始地址,所以str中存放的是栈地址,这个地址的数据是可写的。在 Linux 中,堆,全局数据,常量等都是存放于从 0x8048000 开始的内存地址,向上增长。一般来说,32位机器上,在Linux中,栈地址空间从3G(0xbfffffff)开始向下增长。
Tips:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char ch[] = "Hello";
char *s = ch;
s ++ ;
cout << s << endl; //ello
s[0] = 'X';
cout << s << endl; // Xllo
return 0;
}
由于 char*s = ch;中的 ch 不是字符串常量,因此 s 可以修改。
10. 指针和二维数组
多维数组本质上是数组的数组,由于一个指针可以表示一个数组,因此可以把二维数组看做一维指针数组。
数组可以看做是同类事物的集合,多维数组基本上可以理解为数组的集合。
例如二维数组A[3][2],如下图所示:

对 A 解引用就可以得到 A[0], A[1], A[2]
对 A[i] 解引用就可以得到 A[i][0], A[i][1]
对 A[i][j] 解引用就可以得到具体的值
注意别把指针数组和二维指针搞混了,根本不是一回事!
10.1 二维数组在内存中的存放方式
假设我们生成了一个数组 A[3][2]

此时如果我们定义一个指针 int *p = &A; 会编译错误,因为这里的 int 类型指针 p 指向了一个一维数组,这与指针的类型不匹配。
10.2 二维数组的运算
Code:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int b[2][3] = {
{2, 3, 6},
{4, 5, 8}
};
cout << "二维数组b的首地址: " << &b << endl;
int (*p)[3] = b; // 一维指针数组
// b是二维数组b[][]的数组名,它的地址就是首地址b[0]
cout << b << ' ' << b[0] << endl;
cout << b + 1 << ' ' << b[1] << endl;
// b <==> &b,b[i] <==> &b[i]
// 对b直接解引用得到的是b[0],b[0]是一维数组b[0]的数组名,因此b[0]的地址就是首地址b[0][0]
cout << *b << ' ' << b[0] << ' ' << &b[0][0] << endl; // *b = *(b + 0)
cout << *(b + 1) << ' ' << b[1] << ' ' << &b[1][0] << endl;
//
cout << *(b + 1) + 2 << ' ' << b[1] + 2 << ' ' << &b[1][2] << endl;
//
cout << *(*b + 1) << endl;
return 0;
}
Output:
二维数组b的首地址: 0x7fff0e673980
0x7fff0e673980 0x7fff0e673980
0x7fff0e67398c 0x7fff0e67398c
0x7fff0e673980 0x7fff0e673980 0x7fff0e673980
0x7fff0e67398c 0x7fff0e67398c 0x7fff0e67398c
0x7fff0e673994 0x7fff0e673994 0x7fff0e673994
3
Tips:
在二维数组中,有以下两条等式
取地址:
&b[i][j] <=> b[i] + j <=> *(b + i) + j取值:
b[i][j] <==> *(b[i] + j ) <==> *(*(b + i) + j)
11. 指针和多维数组
11.1 指针和三维数组
Code:
要注意解引用运算符(*)的优先级
#include <iostream>
using namespace std;
int main()
{
int c[2][2][2] = {1,2,3,4,5,6,7,8};
int (*p)[2][2] = c;
//int *p[2][2] = c; // Wrong!
return 0;
}
Tips:
c[i][j][k]
= *(c[i][j] + k)
= *(*(c[i] + j) + k)
= *(*(*(c + i) + j) + k)
对于上面的转换,只需要牢记指针和数组之间的转换就可以了:
c[i] = *(c + i);
&c[i] = c + i;
11.2 多维数组作为参数传递给函数
我们在第 8 章中已经知道,将数组作为参数传递给函数时,实际上不会拷贝整个数组,只会以指针的形式传它的引用。例如:
Code:
void func(int a[]) {
}
// 等价于
void fundc(int *a) {
}
上面的例子是一维数组的情况,那么如果传递的是多维数组呢?
Code:
int c[2][3];
int d[10][10];
void func1(int a[][]) { // test 1
}
void func2(int *a) { // test 2
}
void func3(int a[][3]) { // test 3
}
void func4(int *a[3]) { // test 4
}
void func5(int **a) { // test 5
}
Explain:
在第一种形式中,编译器会报错,因为我们执行了一个二维数组作为形参,形式上虽然是
a[][],但编译器会将其转化为(*a)[], 也就是说,我们指定了一个指针数组作为参数,但我们没有指定这个指针数组的大小,因此编译器报错。在第二种形式中,编译时不会报错,但如果我们将数组
c作为参数执行func()函数,编译器会报错,因为c[][]的类型为(int *)[],而参数的类型为int *,显然类型不匹配。第三种形式和第四种形式都是正确的,因为我们指定了指针数组的大小。
将数组
c传递给func3()和func4()是正确的,但如果传入数组d就会报错,因为数组的第二维不匹配。
Tips:
也就是说,在我们将数组作为参数传递给函数时,数组的第一维是可以省略的,但是剩下的维必须指定大小。
另外,一个常见的误区是:对于二维数组,我们传入一个指针的指针,对于三维数组,传递一个指针的指针的指针,这是不对的。
12. 指针和内存管理
12.1 内存架构
在一个典型的架构中,分配给应用程序的内存可以分为四个区段:
- Test(Code):用来存放需要执行的指令
- Static/Global:用来存放静态变量或全局变量,也就是不在函数中声明的变量,它们的声明周期贯穿整个程序周期
- Stack:用来存放函数调用的所有信息和所有局部变量,局部变量在函数内部声明
- Heap:用来存放动态分配的变量
Tips:
- 代码段,静态/全局数据段,栈区在运行期间的大小是不会增长的。
- 一个函数的帧栈大小,是在编译期间就决定了的。
- 程序在任何时间,都是栈顶的函数在执行。
12.2 堆的引入
内存在栈上的分配和销毁有一定的规则,当一个函数被调用的时候,它被压入堆栈,结束时,弹出堆栈。如果变量是在栈上分配的,那你就不能操纵变量的范围。
另外一个限制,如果我们需要声明一个很大的数据类型,或者一个很大的数组作为局部变量,我们需要在编译期间知道数组的大小。如果我们有这样一个场景:需要在运行期间根据参数决定数组的大小,那么使用栈就会有问题了。
针对这些问题,比如分配很大的内存,或者把变量预留在内存中直到我们想用的时候为止,我们就有了堆。
12.3 堆简介和引应用
不像栈,应用程序的堆的大小是不固定的,它的大小在应用程序的整个声明周期是可变的,也没有特定的规则来分配和销毁特定的内存,程序员可以完全控制在堆上分配多少存在,数据保留到什么时候,你几乎可以任意使用堆上的内存,只要不超出系统自身的内存限制,但有时候随意使用堆也是危险的(内存泄露)
有时候我们把堆称为内存的空闲池,或者内存空闲存取区,我们可以在堆中获得我们想要的内存,尽管不同的操作系统对分配堆的方式不同,但可以把堆抽象看做一块很大的自由使用的内存空间
注意不要把这里的堆和数据结构中的堆混淆了,它们是完全不同的概念,这里的堆表示的只是空闲的内存池。另外栈区是栈的一种实现,而堆不是的。
使用堆内存意味着动态内存分配,在 C 或者 C++ 中使用堆的方法:
C:
malloc();
calloc();
realloc();
free();
C ++ :
new;
delete();
C ++ 也可以使用 C 的四个函数,因为 C ++ 向后兼容 C
malloc会返回一个指向这块内存起始地址的(void *)指针,因此需要做类型转换,但是在 C ++ 里面则不需要,因此new 和 delete 操作符是类型安全的,这意味着,他们是带着类型的,返回指向特定类型的指针。
事实上使用堆的唯一方式就是通过引用。malloc函数所做的事情仅仅是,从堆上找到空闲的内存,为你预留空间然后通过指针返回给你,你去访问这块内存的方式就是自己维护一个指针。
分配在堆上的内存在函数调用结束之后并不会像栈上那样自动释放,因此,对于分配的内存,要注意回收(free) ,否则可能导致内存泄露
Code:C
#include <stdio.h>
#include <stdlib.h>
int main()
{
int a; // goes on stack
int *p;
p = (int *)malloc(sizeof(int));
*p = 10;
free(p);
p = (int *)malloc(20 * sizeof(int));
return 0;
}
Code:C++
#include <iostream>
#include <stdlib.h>
using namespace std;
int main()
{
int a; // 分配在栈上
int *p;
p = new int;
*p = 10;
delete p; // 释放空间
p = new int[20]; // 分配一个数组
delete[] p; // 释放空间
return 0;
}
12.4 库函数
介绍 C 语言支持中支持动态内存分配的各种库函数。
12.4.1 malloc()
malloc 的全称是 memory allocation,中文叫动态内存分配,用于申请一块连续的指定大小的内存块区域以 void* 类型返回分配的内存区域地址,当无法知道内存具体位置的时候,想要绑定真正的内存空间,就需要用到动态的分配内存,且分配的大小就是程序要求的大小。
如果分配成功则返回指向被分配内存的指针(此空间中的初始值不确定),否则返回空指针 NULL。当内存不再使用时,应使用 free() 函数将内存块释放。
原型为:void* malloc(size_t size);
可以把 size_t看做 unsigned_int(>=0),显然我们不能指定一个负数。
malloc 返回一个 void* 指针,这个指针指向分配给我们的内存块的第一个地址。
size = 单元的数量 * 每个单元的字节数
例如:如果我们希望分配一个单元的 int 类型的空间
void *p = malloc(4);不是一种好的写法,因为变量的大小是由编译器决定的,尽管有时候 int 类型占四个字节是显然的。但也有可能有些编译器的 int 并不是 4 个字节。我们最好写成这样的形式:
void *p = malloc(sizeof(int));
我们不可以解引用一个 void 指针,因此为了能够使用这块内存,我们需要把 malloc 返回的指针转成一个特定类型的指针。
malloc 之所以返回一个 void 指针是因为可以确保它的通用性,它做的仅仅只是分配内存,而不关心这块内存你是拿来存整形还是字符还是浮点数。
Code:
#include <iostream>
#include <stdlib.h>
using namespace std;
int main()
{
int *p = (int *)malloc(3 * sizeof(int));
// 通过指针操纵
*p = 1;
*(p + 1) = 2;
*(p + 2) = 3;
// 因为我们分配的是一个int数组,因此我们可以直接通过数组的方式操纵
p[0] = 4;
p[1] = 5;
p[2] = 6;
return 0;
}
12.4.2 calloc()
使用 malloc 初始化时不会进行初始化,因此如果没有填入值得话,会得到一些随机值。但是使用 calloc 的话,会对其进行初始化为 0,如果分配成功则返回指向被分配内存的指针(**此空间中的初始值为 0 **),否则返回空指针 NULL,
calloc 的全称是 clear allocation,中文名为动态内存分配并清零
函数原型为:*void calloc(unsigned int num,unsigned int size);
num 表示分配的单元数量,size表示单元大小
12.4.3 realloc()
如果你有一块内存,动态分配的内存,然后你想修改内存块的大小,就可以使用 realloc,realloc 的全称是 reset allocation,中文名为动态内存调整。
函数原型为:extern void * realloc(void* mem_address, unsigned int newsize);
mem_address 指向已分配内存的起始地址的指针,如果 mem_address = NULL , 那么此时就相当于 malloc
newsize 为新内存块的大小
先判断当前的指针是否有足够的连续空间,如果有,扩大 mem_address 指向的地址,并且将 mem_address 返回,如果空间不够,先按照 newsize 指定的大小分配空间,将原有数据从头到尾拷贝到新分配的内存区域,而后释放原来 mem_address 所指内存区域(原来的指针会自动释放,不需要再使用 free),同时返回新分配的内存区域的首地址。重新分配成功返回指向被分配内存的指针,否则返回空指针 NULL。
注意:调整后的大小可大可小(如果新的大小大于原内存大小,新分配部分不会被初始化;如果新的大小小于原内存大小,可能会导致数据丢失)。
12.4.4 free()
函数原型为:*void free(void ptr);
一般使用 malloc, calloc, realloc 函数进行内存分配后要使用 free(起始地址的指针) 对内存进行释放,不然内存申请过多会影响计算机的性能,以至于重启电脑。但是若使用动态内存分配函数后未使用 free 函数进行释放,还可以使用指针对该块内存进行访问,如果释放则不能再访问。
注意:使用后该指针变量一定要重新指向 NULL,防止野指针出现,有效规避错误操作。
12.4.5 示例
上面函数的使用需要引入头文件 #include <stdlib.h>
Code:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
int n;
cout << "请输入数组的大小: " << endl;
cin >> n;
// 编译错误,不能在运行时定义数组
//int A[n];
//正确方法
int* A = (int*)malloc(n * sizeof(int));
cout << "mallo分配的数组: " << endl;
for(int i = 0; i < n; i ++ ) cout << A[i] << ' ';
cout << endl;
int *B = (int*)calloc(n, sizeof(int));
cout << "callo分配的数组: " << endl;
for(int i = 0; i < n; i ++ ) cout << B[i] << ' ';
cout << endl;
return 0;
}
Input && Output:
请输入数组的大小:
25
mallo分配的数组:
39855248 0 7365248 0 0 0 0 0 0 0 -1694498661 43847 39855248 0 7340368 0 0 -1 -1728053095 43846 39855248 0 7340368 0 0
callo分配的数组:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Explain:
在上面的代码中,我们实现了在程序运行过程当中分配一个数组,并且可以验证,malloc 不会进行初始化,因此我们得到一堆随机数,而 calloc 会进行0初始化,因此数组元素全为 0
Code:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
int n;
cout << "请输入数组的大小: " << endl;
cin >> n;
int* A = (int*)malloc(n * sizeof(int));
for(int i = 0; i < n; i ++ ) A[i] = i + 1;
for(int i = 0; i < n; i ++ ) cout << A[i] << ' ';
cout << endl;
// 释放内存
free(A);
for(int i = 0; i < n; i ++ ) cout << A[i] << ' ';
cout << endl;
// free之后再次修改内存中的值
for(int i = 0; i < n; i ++ ) A[i] = i + 1;
for(int i = 0; i < n; i ++ ) cout << A[i] << ' ';
cout << endl;
return 0;
}
Input && Output:
请输入数组的大小:
5
1 2 3 4 5
16279024 0 16253264 0 5
1 2 3 4 5
Expalin:
可以发现,在释放掉动态分配的内存之后,仍然可以访问该内存,并打印出一些随机值(完全取决于编译器和机器),甚至可以再次修改内存中的值并正常执行,但在其他的机器上这个程序可能会崩溃(可能另一个指针指向这块内存,而你修改了它)。
所以说 free 并不是真的 “销毁” 了一块内存,它只是说实现这个内存不属于你这个指针了。
这是使用指针的时候一个危险的地方。
Code:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
int n;
cout << "请输入数组的大小: " << endl;
cin >> n;
int* A = (int*)malloc(n * sizeof(int));
cout << "请输入数组改编后的大小:" << endl;
cin >> n;
int *B = (int *)realloc(A, n * sizeof(int)); // 包含 free(A)
for(int i = 0; i < n; i ++ ) B[i] = i + 1;
for(int i = 0; i < n; i ++ ) cout << B[i] << ' ';
cout << endl;
free(B);
return 0;
}
Input && Output:
请输入数组的大小:
5
请输入数组改编后的大小:
10
1 2 3 4 5 6 7 8 9 10
12.5 内存泄露
所谓内存泄露,是指不当地使用动态内存或者内存的堆区,也就是在堆长增加"垃圾"。其他语言诸如 Java 和 C# ,堆上的垃圾会被自动回收(垃圾回收机制)。
内存泄漏总是因为堆中未使用和未引用的内存块才发生的。
栈上的内存是自动回收的,栈的大小是固定的,会多就是会发生栈溢出。
常见的错误:在函数内部 malloc 一块内存,但是在函数结束时没有释放,如果这个函数执行非常多次,就造成内存泄漏。不要误以为在函数中 malloc 的内存会在函数结束时自动释放,函数结束时只会自动释放栈中的内存,而 malloc 是在堆上分配的内存,所以函数结束时不会释放。
13. 函数返回指针
重点:什么时候可以从函数返回一个指针
如果我们在堆上有一个内存地址或者在全局区有一个变量,那么我们就可以安全的返回他们的地址
Code:
#include <iostream>
#include <stdlib.h>
using namespace std;
// int* Add1(int *a, int *b)
// {
// int c = (*a) + (*b);
// return &c;
// }
int* Add(int *a, int *b)
{
int *c = (int *)malloc(sizeof(int));
*c = *a + *b;
return c;
}
int main()
{
int a = 2, b = 4;
int* c = Add(&a, &b);
//int *c = Add1(&a, &b); 报错
cout << (*c) << endl;
return 0;
}
Explain:
在上面的代码中,Add1函数并不是一个正确的函数返回指针的例子,因为它返回的是一个 《被调用的函数的中的局部变量的地址》,我们知道,一个函数的栈帧会随着函数的结束而被释放,所以当 Add1 函数结束的时候,局部变量 c 的地址就被释放了,所以说返回 c 的地址是错误的。
因此,从函数返回地址时,我们需要小心它们的作用范围
从栈底向上传一个局部变量或者局部变量的地址是可以的。
但是,从栈顶想下传一个局部变量或者局部变量的地址是不可以的。因为被调函数的地址在主调函数的上面,当被调函数执行时,主调函数一定还没结束,而主调函数在执行时,被调函数分配的内存空间也一定被释放掉了。
正确的做法是返回全局变量取的地址或者堆区的地址,因为那里的地址不会被自动释放。
14. 函数指针
14.1 简介
根据定义可以知道,函数指针是用来保存函数的地址的指针。
那么问题来了,函数的地址是什么?
在内存中,一个函数就是一块连续的内存(里面是指令)
函数的地址,我们也把它称为函数的入口点,它是函数的第一条指令的地址(最低地址)
通过直接使用函数名或者取地址可以得到函数的地址。
function = &function
14.2 函数指针的使用
对于下面这个函数:
int add(int a, int b) {
return a + b;
}
函数指针的声明和初始化:
声明一个函数指针的步骤:
- 首先输入的是,指向这个函数的返回类型,add 函数的返回类型是 int;
- 然后跟一个括号,括号里面是 *name,name就是函数指针的名字;
- 然后再跟一个括号,括号里面是所指向这个函数的所有参数的类型,要和所指向的这个函数的类型是一致的。
即:function_type (*pointer_name)(arguments_type);
声明一个指向 add 函数的指针 p:
--> int (*p)(int, int); // 声明了一个函数指针
--> p = &add; // 将函数指针 p 指向函数 add通过上面两条语句我们就实现了声明一个函数指针并让其指向一个函数,当然也可以写为一条语句。
调用函数指针:
--> int c = (*p)(2, 3); // 调用函数add
(*p)表示解引用,来获得这个函数,然后把两个参数传递给这个函数。
作为代替,我们也可以直接使用函数指针名(就像在使用函数名一样):
-->int c = p(2, 3); // 等价于上面的语句
Code:
#include <iostream>
using namespace std;
int add(int a, int b) {
return a + b;
}
void printStr() {
printf("Hello,World!\n");
}
int main()
{
int c;
int (*p)(int, int) = &add;
c = (*p)(2, 3);
cout << c << endl; // 5
c = p(4, 5);
cout << c << endl; // 9
void (*p1)();
p1 = printStr;
p1(); // Hello,World!
return 0;
}
14.3 使用案例(回调函数)
回调函数:一个函数引用传递给另一个函数时,那个函数被称作回调函数。
函数指针可以被用来做函数参数,接受函数指针的那个函数可以回调函数指针所指向的那个函数,举个例子:
Code:
#include <stdio.h>
void A() {
printf("Hello\n");
}
void B(void (*ptr)()) {
(*ptr)(); // <==> ptr();
}
int main()
{
void (*ptr)() = A;
B(ptr);
// <==>
B(A);
}
Explain:
在上面的函数中,我们声明了两个函数
A和B
A没有参数,返回值类型为void;
B有一个参数,参数类型为一个返回值类型为void,没有参数的函数指针,返回值类型为void;在
main中,我们声明了一个返回值类型为void,没有参数的指针ptr,并让其指向函数A(类型匹配),返回将这个指针作为参数传递给函数B,函数B又通过函数指针ptr调用函数A。函数
B可以通过函数指针回调函数A另外也可以写成
B(A)的形式,因为函数的名字返回的就是指针。
更清晰的例子:
Code:
void bubbleSort(int *a, int n) {
for(int i = 0; i < n - 1; i ++ ) {
for(int j = 0; j < n - 1 - i; j ++ ) {
if(a[i] > a[i + 1]) {
swap(a[i], a[i + 1])
}
}
}
}
Explain:
通过上面的冒泡排序,我们可以实现对一个数组升序排序。现在有这样一种情况,我们有时候需要升序排序,有时候又需要降序排序。
最简单的方式就是写两份冒泡排序,然后修改判断条件,但是这样代码的冗余度太高。
另一种冗余度低且比较简单的方法是在函数中额外传递一个参数
flag,用来标记这是升序排序还是降序排序。但这样的话如果flag很大的话,那么函数内部的if比较函数就会很多(我们需要判断依据何种判断条件)。还有一种方式就是在函数中额外传递一个比较函数,这样就不要额外添加判断语句。
Code:
#include <iostream>
#include <algorithm>
using namespace std;
int cmp(int a, int b)
{
if(a > b) return -1;
else return 1;
}
void bubbleSort(int *a, int n, int (*compare)(int, int)) {
for(int i = 0; i < n - 1; i ++ ) {
for(int j = 0; j < n - 1 - i; j ++ ) {
if(compare(a[j], a[j + 1]) > 0) {
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = {3, 5, 1, 15, 9, 74, 5};
int n = (int)sizeof(arr) / sizeof(arr[0]);
bubbleSort(arr, n, cmp);
for(int i = 0; i < n; i ++ ) cout << arr[i] << ' ';
cout << endl;
return 0;
}
Explain:
在
bubbleSort函数中回调cmp函数实现自定义的排序方案。
15. 第15章 C文件操作
15.0 简介和参考
在ANSI C中,对文件的操作分为两种方式,即:
-
流式文件操作
-
I/O文件操作
15.1 英文名词
perror:错误
flow:流
reind:倒带,back to the begining
15.2 流式文件操作
15.2.0 FIle结构
这种方式的文件操作有一个重要的结构FILE,FILE在stdio.h中定义如下:
以下是引用片段:
typedef struct {
int level;
unsigned flags;
char fd;
unsigned char hold;
int bsize;
unsigned char _FAR *buffer;
unsigned char _FAR *curp;
unsigned istemp;
short token;
} FILE;
FILE这个结构包含了文件操作的基本属性,对文件的操作都要通过这个结构的指针来进行,此种文件操作常用的函数如下,下面是这些函数的功能使用说明:
15.2.1 perror()
void perror(const char *message);
在发生错误时,该函数会简化向用户报告这些指定错误的过程。
打印格式为 message: [“wrong message”],message后面跟一个冒号和空格,然后就是错误信息。
15.2.2 fopen()
FILE *fopen(path, mode); // 打开一个流
FILE *freopen(path, mode); //重新打开一个流
Mode:
r 打开只读文件,该文件必须存在。
r+ 打开可读写的文件,该文件必须存在。
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。不过在POSIX系统,包含Linux都会忽略该字符。
15.2.3 fclose()
int fclose (FILE *f*);
关闭fopen()打开的文件。
对于输出流,fclose函数在文件关闭之前刷新缓冲区。如果它执行成功,返回零值,否则返回EOEF(-1)
在程序结束时一定要记得关闭打开的文件,不然可能会造成数据的丢失。
15.2.4 fputc(), fgetc()
int fputc(int c, FILE *Stream);
int fgetc(FILE *Stream);
成功时都返回put/get的字符,失败时都返回EOF
15.2.5 fgets(), fputs()
int fputs(const char *s, FILE *Stream);
写入一个字符串到流中
char *fgets(char *s, int n, FILE *Strem)
从流中读取一行或指定个字符,注意是读取n-1个字符(还有一个默认的‘\0’),除非读完一行。参数s是用来接收字符串,如果成功则返回s的指针,否则返回NULL。
注意fgets会读取回车, fputs不换行。
15.2.6 fseek()
fseek() 在流中定位到指定的字符
此函数一般用于二进制模式打开的文件中,功能是定位到流中指定的位置,原型是:
int fseek(FILE *stream, long offset, int whence);
如果成功返回0,参数offset是移动的字符数,whence是移动的基准,取值是:
符号常量 值 基准位置
-
SEEK_SET 0 文件开头
-
SEEK_CUR 1 当前读写的位置
-
SEEK_END 2 文件尾部
例:fseek(fp,1234L,SEEK_CUR);//把读写位置从当前位置向后移动1234字节(L后缀表示长整数)
fseek(fp,0L,2);//把读写位置移动到文件尾
15.2.7 fprintf(), fscanf()
fprintf按格式输入到流,其原型是:
```int fprintf(FILE *stream, const char *format[, argument, …]);``
其用法和printf()相同,不过不是写到控制台,而是写到流罢了。
例:fprintf(fp,"%d-%s",4,"Hahaha");
fscanf从流中按格式读取,其原型是
int fscanf(FILE *stream, const char *format[, address, …]);
其用法和scanf()相同,不过不是从控制台读取,而是从流读取罢了。
例:fscanf(fp,"%d%d" ,&x,&y);
如果想用scanf实现逐行读取,需要在fscanf中读取一个换行,否则第一次fscanf是正常读如,但第二次会读入一个换行,之后就全错了。
15.2.8 rewind()
把当前的读写位置回到文件开始,原型是:
void rewind(FILE *stream);
其实本函数相当于fseek(fp,0L,SEEK_SET);
15.2.9 remove()
删除文件,原型是
int remove(const char *filename);
参数就是要删除的文件名,成功返回0。
15.2.10 ferror()
int ferror(FILE *stream);
返回流最近的错误代码,可用clearerr()来清除它,clearerr()的原型是:
void clearerr(FILE *stream);
15.2.11 tmpname()
char *tmpname(char *s);
生成一个唯一的文件名,其实tmpfile()就调用了此函数,参数s用来保存得到的文件名,并返回这个指针,如果失败,返回NULL。
15.2.12 tmpfile()
FILE *tmpfile(void);
生成一个临时文件,以"w+b"的模式打开,并返回这个临时流的指针,如果失败返回NULL。在程序结束时,这个文件会被自动删除。
15.2.13 fread(), fwrite()
fread()从流中读指定个数的字符,原型是
size_t fread(void *ptr, size_t size, size_t n, FILE *stream);
参数ptr是保存读取的数据,void*的指针可用任何类型的指针来替换,如char*、int *等等来替换;size是每块的字节数;n是读取的块数,如果成功,返回实际读取的块数(不是字节数),本函数一般用于二进制模式打开的文件中。
例:
以下是引用片段:
char x[4230];
FILE *file1=fopen("file","r");
fread(x, 200, 12, file1);
//共读取200*12=2400个字节
与fread对应,fwrite()向流中写指定的数据,原型是:
size_t fwrite(const void *ptr, size_t size, size_t n, FILE *stream);
参数ptr是要写入的数据指针,void的指针可用任何类型的指针来替换,如char、int *等等来替换;size是每块的字节数;n是要写的块数,如果成功,返回实际写入的块数(不是字节数),本函数一般用于二进制模式打开的文件中。
例:
以下是引用片段:
char x[]="I Love You";
fwire(x, 6, 12, fp);//写入6*12=72字节
// 将把"I Love"写到流fp中12次,共72字节
15.2 I/O 文件操作
参考博客吧!
暂时用不到!
C陷阱与缺陷
第一章 词法陷阱
1.0 引子
符号 指的是程序的一个基本组成单元,其作用相当于一个句子中的单词,但是同一个单词在不同的句子中意思是基本一样的,而符号可能完全不同。
编译器中负责将程序分解为一个一个符号的部分,一般称为“词法分析器”。
例如 if (x > big)big = x;经过词法分析之后,可以写为:
if
(
>
big
)
big
=
x
;
1.1 =不同于==
在C语言中,之所以使用=作为赋值运算符,==作为比较运算符,主要是因为赋值运算出现的更为频繁,因而字符较少的=就被赋予了更常用的含义—赋值运算。
某些编译器在发现条件判断的条件判断表达式中出现类似于e1 = e2 的赋值语句时会给出警告。但当我们确实需要使用赋值语句时,不应该关闭警告选项,而是显示的进行比较。
例如表达式if (x = y)
可以写为:if ((x = y) != 0)
1.2 &和 | 不同于 &&和 ||
1.3 词法分析中的贪心法
C语言划分符号的规则:每一个符号应该包含尽可能多的字符。
例如 a---b;
将会被划分为(a--) - b;,而不是a - (--b);
1.4 整形常量
八进制(octonary system)
如果一个整形常量第一个字符是数字0,或者以字符Q结尾,那么该常量将被视作八进制。
所以有时用O结尾,有时用Q结尾,原因:为避免把字母O误认作零,改由Q代替
十六进制(hexadecimal system)
0x开头,或者以字符H结尾。
二进制(binary system)
以字符B结尾。
十进制(decimal system)
开头不能是0,以 字符D结尾。
1.5 字符和字符串
C语言中的单引号和双引号的含义迥异。
用单引号引起的一个字符实际上代表一个整数,整数值对应于该字符在编译器采用的字符集中的序列值。因此,对于采用 ASCLL 字符集的编译器而言,'a' 的含义与 97(十进制)严格一致。
用双引号引起的字符串,代表的却是一个指向无名数组起始字符的指针,该指针被双引号之间的字符以及一个额外的二进制为零的字符 '\0' 初始化。
例如,下面的语句是等价的:
printf ("Hello");
/* 等价于 */
char str[] = {'h', 'e', 'l', 'l', 'o', 0};
printf (str);
第二章 语法陷阱
2.1 理解函数声明
任何 C 变量的声明都由两部分组成:类型以及一组类似表达式的声明符。
一旦我们知道了如何声明一个给定类型的变量,那么该类型的类型转换符就很容易得到了:只需要把声明中的变量名和声明末尾的分号去掉,再将剩余的部分用一个括号整个“封装”起来即可。
2.2 优先级问题
C 语言运算符优先级表

单目运算符,赋值运算符,三目运算符自右向左结合。
任何一个逻辑运算符的优先级比任何一个关系运算符的优先级要低。
移位运算符的优先级比算术运算符要低,但是比关系运算符要高。
六个关系运算符的优先级并不相同。因此,如果我们要比较 a 和 b 的大小顺序是否和 c 和 d 的大小顺序一样,可以这样写:
a < b == c < d任意两个逻辑运算符的具有不同的优先级,所有的按位运算符优先级(& , | , ^)要比顺序运算符(&&, ||)的优先级高;每个与运算的优先级比或运算的优先级高,异或运算的优先级介于两者之间。
三目运算符的优先级最低,这样我们就可以在三目运算符的条件表达式中包含关系运算符的逻辑组合。例如:
tax_rate = income > 4000 && residency < 5 ? 3.5 : 2.0;本例其实还说明赋值运算符的优先级低于条件运算符的优先级是有意义的。
C++ 运算符优先级和结合性
| 优先级 | 运算符 | 说明 | 结合性 |
|---|---|---|---|
| 1 | :: | 范围解析 | 自左向右 |
| 2 | ++ -- | 后缀自增/后缀自减 | |
| () | 括号 | ||
| [] | 数组下标 | ||
| . | 成员选择(对象) | ||
| −> | 成员选择(指针) | ||
| 3 | ++ -- | 前缀自增/前缀自减 | 自右向左 |
| + − | 正/负号 | ||
| ! ~ | 逻辑非/按位取反 | ||
| (type) | 强制类型转换 | ||
| * | 取指针指向的值 | ||
| & | 某某的地址 | ||
| sizeof | 某某的大小 | ||
| new, new[] | 动态内存分配/动态数组内存分配 | ||
| delete, delete[] | 动态内存释放/动态数组内存释放 | ||
| 4 | .* ->* | 成员对象选择/成员指针选择 | 自左向右 |
| 5 | * / % | 乘法/除法/取余 | |
| 6 | + − | 加号/减号 | |
| 7 | << >> | 位左移/位右移 | |
| 8 | < <= | 小于/小于等于 | |
| > >= | 大于/大于等于 | ||
| 9 | == != | 等于/不等于 | |
| 10 | & | 按位与 | |
| 11 | ^ | 按位异或 | |
| 12 | | | 按位或 | |
| 13 | && | 与运算 | |
| 14 | || | 或运算 | |
| 15 | ?: | 三目运算符 | 自右向左 |
| 16 | = | 赋值 | |
| += −= | 相加后赋值/相减后赋值 | ||
| *= /= %= | 相乘后赋值/相除后赋值/取余后赋值 | ||
| <<= >>= | 位左移赋值/位右移赋值 | ||
| &= ^= |= | 位与运算后赋值/位异或运算后赋值/位或运算后赋值 | ||
| 17 | throw | 抛出异常 | |
| 18 | , | 逗号 | 自左向右 |
2.3 注意作为语句结束标志的分号
例子1:
if (x > 10);
x = 0;
在 if 的后面,我们多加了一个分号,上述语句就相当于:
x = 0;
例子2:
if (x > 10)
return
a = 1;
b = 2;
c = 3
在 return 的后面,我们遗漏了分号,但是不会报错,上述语句就相当于:
if (x > 10)
return a = 1;
b = 2;
c = 3;
2.4 switch 语句
由 switch 控制的流程在执行第一个 case 之后,会自然而然的顺序执行下去,C 语言的这种特性,既是它的优势所在,也是它的劣势。
因为程序员可能会遗漏 break 语句,而有时候,我们或许需要故意省略 break 语句来实现某种效果。
2.5 函数调用
与其他程序设计语言不同,C 语言要求:在函数调用时,即使函数不带参数,也应该包括参数列表。
因此,如果 f 是一个函数,那么f();是一个函数调用语句,而f却是一个什么也不做的语句。更准确的说,它计算函数 f 的地址,却并不调用这个函数。
2.6 悬挂 else 引发的额问题
C 语言有这样的规则:else 始终与同一括号内最近的未匹配的 if 结合。
例如下面的例子:
if (x == 0)
if (y == 0) error();
else z = x + y;
// 上面代码,看起来像是:
if (x == 0)
{
if(y == 0) error();
}
else
{
z = x + y;
}
// 实际上是:
if(x == 0)
{
if(y == 0) error();
else z = x + y;
}
第三章 语义陷阱
3.1 指针与数组
C 语言中的数组值得注意的地方有以下两点:
- C 语言中只有一维数组,并且数组的大小必须在编译器就作为一个常数确定下来。所谓多维数组其实就是数组的元素可以是任意类型的对象,包括数组。
- 对于一个数组,我们能做的只有两件事:确定该数组的大小以及获得指向该数组下标为 0 的指针。有关数组的其他操作,哪怕他们乍看上去是以数组下标进行运算的,实际上都是通过指针进行的。换言之,任何一个数组下标运算都等同于一个对应的指针运算,因此我们完全可以根据指针行为定义数组下标的行为。
int a[3] = {1, 2, 3};
int *p = &a;
这种写法在 ANSI C 中是非法的,以为 &a 是一个指向数组的指针,而 p 是一个指向整型变量的对象,它们的类型不匹配。
正确的写法应该是:
int a[3] = {1, 2, 3};
int *p = a;
这里的 a 就是 a[0] 的地址。
除了 a 被用作运算符 sizeof 的参数这一情形,在其他所有情形中使用数组名 a 都代表指向数组 a 中下标为 0 的元素的指针。
另外,在上文中我们说过“有关数组的其他操作,哪怕他们乍看上去是以数组下标进行运算的,实际上都是通过指针进行的。”
例如 a[i] 表示取数组 a 下标为 i 的元素的值,它实际表示的是: *(a + i),只不过这种写法非常常用,因此被简记为 a[i]。实际上,由于 a + i 和 i + a 一样,因此 a[i] 和 i[a] 具有相同的含义。(也许某些汇编程序员会觉得很熟悉--偏移量)
#include <iostream>
using namespace std;
int main()
{
int a[3][3] = {
{1, 2, 3}, {4, 5, 6}, {7, 8, 9},
};
int (*p)[3];
for(p = a; p < &a[3]; p ++ ) {
int *j;
for(j = *p; j < &(*p)[3]; j ++ )
cout << *j << ' ';
cout << endl;
}
return 0;
}
*对指针的 (解引用) 可以理解为让指针指向某个地方。
3.2 非数组的指针
在 C 语言中,字符串常量代表了一块包括字符串中所有字符以及一个空字符 '\0' 的内存区域的地址。
如果我们想要拼接两个字符串 s 和 t,正确的写法为:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char *s = "Hello,";
char *t = "World!";
char *r;
r = malloc(strlen(s) + strlen(t) + 1);
if(!r) {
puts("分配失败");
exit(1);
}
strcpy(r, s);
puts(r);
strcat(r, t);
puts(r);
return 0;
}
3.3 作为参数的数组声明
在 C 语言中,我们无法将一个数组作为函数参数直接传递。如果我们将数组名作为参数,那么数组会立即被转换为指向该数组第一个元素的指针。
例如:
#include <stdio.h>
#include <string.h>
int main()
{
char *s = "Hello!";
puts(s);
puts(&s[0]);
// 传递一个数组名和传递数组第一个元素的地址是等价的
return 0;
}
因此,将数组作为函数参数毫无意义。所以,C 语言会自动将作为参数的数组声明转换为对应的指针声明。
例如:
int strlen(char s[]) {
/* do something */
}
与下面的写法完全相同:
int strlen(char *s) {
/* do something */
}
3.4 避免“举隅法”
举隅(yu2)法:举一端为例。意在使人由此一端而推知其他。意在以更宽泛的词语来代替含义相对较窄的词语,或者相反:例如,以整体代表部分,或者以部分代表整体。
C 语言中一个常见的陷阱:混淆指针与指针所指向的数据。
例如:
char *p, *q;
p = "xyz";
尽管有时候我们不妨认为,上面的赋值语句使得 p 的值就是字符串 "xyz" ,然而实际情况并不是这样。实际上, p 的值是一个指向由 'x', 'y', 'z', '\0' 四个字符组成的数组的起始元素的指针。
因此,如果我们执行下面语句:
p = q;
p 和 q 现在是指向内存中同一个地址的指针。这个赋值语句并没有复制内存中的字符。需要记住的是,复制指针并不同时复制指针所指向的数据。
3.5 空指针并非空字符串
在 C 语言中,编译器保证由 0 转换而来的指针并不等同与任何有效的指针。出于代码文档化的考虑,常数 0 这一个值常用一个符号来代替:
#define NULL 0
当常数 0 被转换为指针使用时,这个指针绝对不能被解除引用。换句话说,我们绝对不能企图用该指针所指向的内存中存储的内容。
3.6 边界计算与不对称边界
在所有常见的程序设计错误中,最难于察觉的一类是“栏杆错误”,也常被称为“差一错误”。典型的例子是:100 米长的围栏每隔 10 米 需要提跟支撑用的围栏,则总共需要多少根围栏?如果不假思索,最“显而易见”的答案是将 100 除以 10,得到的答案是 10,即需要 10 根栏杆。当然这个答案是错误的,正确答案是 11。
也即,得出正确答案的最容易方式是这样考虑:要支撑 10 米长的围栏实际需要两根栏杆,两段各一根。这个问题的另一种考虑方式是:除了最右侧的一段围栏,其他每一段 10 米长的围栏都只在左侧有一根围栏;而例外的最右侧不仅左侧有一根围栏,右侧也有一根围栏。
前面一段讨论了解决问题的两种方法,实际上提示了我们避免“栏杆错误”的两个通用原则:
- 首先考虑最简单情况下的特例,然后将得到的结果外推,这是原则一。
- 仔细计算边界,绝不掉以轻心,这是原则二。
将上面总结的两个原则牢记于心之后,来看一个典型的例子:计算整数范围的边界。例如,假设整数 x 的边界条件为 x>=16 且 x<=27,那么此范围内 x 的可能取值个数有多少?
根据原则一,我们考虑最简单情况下的特例:x>=16 且 x<=16,此时显然只有一个元素,也即上边界和下边界重合时,此范围内满足条件的整数只有一个。因此答案就是 27-16+1=12。
然而有时稍不留意,我们会想当然的认为答案为:27-16=11个整数 ,那么是否存在一些编程技巧,可以降低这类错误发生的可能性呢?
这个编程技巧不但存在,而且可以一言以蔽之:用第一个入界点和第一个出界点来表示一个数值范围。具体而言,对于上面的例子我们不应该说整数 x 的边界条件为 x>=16 且 x<=27,而应该说整数 x 的边界条件为 x>=16 且 x<28。注意,这里下界 16 是“入界点”,包含在取值范围之中;而上界是“出界点”,即不包含在取值范围之中,这种不对称或许从数学上而言并不优美,但是它对于程序设计的简化效果却令人吃惊。
- 取值范围的大小就是上界与下界之差。28-16的值恰好是12。
- 如果取值范围为空,那么上界等于下界。
- 即是取值范围为空,上界也永远不可能小于下界。
对于像 C 语言这样数组下标从 0 开始的语言,不对称的边界给程序设计带来的便利要更加明显:这种数组的上界(即第一个“出界点”)恰好是数组元素的个数。
另一种考虑不对称边界的方式是,把上界视作某序列中第一个被占用的元素,而把下界视作序列中第一个被释放的元素。当处理各种不同类型的缓冲区时,这种看待问题的方式特别有用。
3.7 求值顺序
C 语言中只有 4 个运算符(&&、||、 ?: 和 ,)存在规定的求值顺序。运算符 && 和 || 先对左侧操作数求值,只在需要的时候才对右侧操作数求值。运算符 ?: 有三个操作数:在 a?b:c 中,操作数 a 首先被求值,根据 a 的值再去求操作数 b 或 c 的值。逗号运算符首先对左侧操作数求值,然后“丢弃”该值,再对右侧操作数求值。
注:分隔函数参数的逗号并非逗号运算符,例如,x 和 y 在函数 f(x, y) 中的求值顺序是未定义的,而在函数 g((x, y)) 中却是确定的先 x 后 y的顺序。
在后一个例子中,函数 g 只有一个参数。这个参数的值是这样求得的:先对 x 求值,然后“丢弃” x 的值,接下来求 y 的值。因此最后的值永远是 y。
C 语言中其它所有运算符对齐操作数求值的顺序是未定义的,特别是,赋值运算符并不保证任何求值顺序。另外,运算符 && 和 || 对于保证检查操作按照正确的顺序执行至关重要,在语句if(y != 0 && x / y > tolerate) 中,就必须保证 y 非 0 时才能执行 x/y 的操作。
下面这种从数组 x 中复制前 n 个元素到数组 y 中的做法是不正确的,它对求值顺序做了太多假设:
i = 0;
while(i < n) {
y[i] = x[i ++ ];
}
我们假设 y[i] = x[i ++ ]; 执行的是:
y[i] = x[i];
i ++ ;
但也有可能是:
y[i + 1] = x[i];
i ++ ;
之所以会出现后面的情况是因为 y[i] 的地址将有可能在 i 自增之后被求值。而我们假设 y[i] 的地址在 i 自增之前被求值。
3.8 操作符 &&、|| 和 !
不要把 && 和 & 混淆,以及 || 和 | 混淆。它们一类是逻辑运算符,一类是按位运算符。尽管有时候用错了可能也会得到理想的结果。
3.9 整数溢出
C 语言中有两倍整数算术运算:有符号运算和无符号运算。在无符号算术运算中,没有所谓“溢出”一说:所有无符号数运算都以 2 的 n 次方为模,这里 n 是结果中的位数。
溢出的结果是未定义的,有时候会简单的利用符号来判断是否溢出,例如两个正数相加结果如果是负数那么肯定溢出,但是溢出不一定就是负数。
3.10 为 main 函数提供返回值
对于一个函数而言,如果没有显式声明返回类型,那么函数返回类型就默认为整形。但是这个程序并没有给出任何返回值。
第四章 链接
4.1 什么是链接器
C 语言的一个重要思想就是分别编译,即若干个源程序可以在不同的时候单独进行编译,然后在恰当的时候整合到一起。
