
使用Go语言开发一个短链接服务:六、链接跳转
章节
Gitee https://gitee.com/alxps/short_link
Github https://github.com/1911860538/short_link
上一篇说了添加和获取短链接逻辑,这一篇将服务的核心,链接跳转。
代码
咱先上代码,再说思路。
app/server/handler/redirect.go
package handler
import (
"log/slog"
"github.com/gin-gonic/gin"
"github.com/1911860538/short_link/app/component"
"github.com/1911860538/short_link/app/server/service"
)
var redirectSvc = service.RedirectSvc{
Cache: component.Cache,
Database: component.Database,
}
func RedirectHandler(c *gin.Context) {
code := c.Param("code")
res, err := redirectSvc.Do(c.Request.Context(), code)
if err != nil {
slog.Error("GetLinkHandler错误", "err", err)
c.AbortWithStatusJSON(res.StatusCode, gin.H{
"detail": "服务内部错误",
})
return
}
if !res.Redirect {
c.AbortWithStatusJSON(res.StatusCode, gin.H{
"detail": res.Msg,
})
return
}
c.Redirect(res.StatusCode, res.LongUrl)
}app/server/service/redirect.go
package service
import (
"context"
"fmt"
"net/http"
"time"
"golang.org/x/sync/singleflight"
"github.com/1911860538/short_link/app/component"
"github.com/1911860538/short_link/config"
)
type RedirectSvc struct {
Cache component.CacheItf
Database component.DatabaseItf
}
type RedirectRes struct {
StatusCode int
Msg string
Redirect bool
LongUrl string
}
var (
confRedirectStatusCode = config.Conf.Core.RedirectStatusCode
confCodeTtl = config.Conf.Core.CodeTtl
confCodeLen = config.Conf.Core.CodeLen
confCacheNotFoundValue = config.Conf.Core.CacheNotFoundValue
sfGroup singleflight.Group
)
func (s *RedirectSvc) Do(ctx context.Context, code string) (RedirectRes, error) {
// 去除code非法的无用请求
if !s.codeValid(code) {
return s.notFound(code)
}
longUrl, err := s.Cache.Get(ctx, code)
if err != nil {
return s.internalErr(err)
}
// confCacheNotFoundValue,用来在缓存标识某个code不存在,防止缓存穿透
// 防止当某个code在数据库和缓存都不存在,大量无用请求反复读取缓存和数据库
if longUrl == confCacheNotFoundValue {
return s.notFound(code)
}
if longUrl != "" {
return s.redirect(longUrl)
}
// 使用singleflight防止缓存击穿
// 防止某个code缓存过期,大量该code请求过来,造成全部请求去数据读值
result, err, _ := sfGroup.Do(code, func() (any, error) {
link, err := s.getLinkSetCache(ctx, code)
if err != nil {
return nil, err
}
return link, nil
})
if err != nil {
return s.internalErr(err)
}
if result == nil {
return s.notFound(code)
}
link, ok := result.(*component.Link)
if !ok {
err := fmt.Errorf("singleflight group.Do返回值%v,类型错误,非*component.Link", result)
return s.internalErr(err)
}
if link == nil {
return s.notFound(code)
}
return s.redirect(link.LongUrl)
}
func (s *RedirectSvc) codeValid(code string) bool {
if len(code) != confCodeLen {
return false
}
for _, char := range code {
if (char < 'a' || char > 'z') && (char < 'A' || char > 'Z') && (char < '0' || char > '9') {
return false
}
}
return true
}
func (s *RedirectSvc) getLinkSetCache(ctx context.Context, code string) (*component.Link, error) {
filter := map[string]any{
"code": code,
}
link, err := s.Database.Get(ctx, filter)
if err != nil {
return nil, err
}
if link == nil || link.LongUrl == "" || link.Expired() {
if err := s.Cache.Set(ctx, code, confCacheNotFoundValue, confCodeTtl); err != nil {
return nil, err
}
return nil, nil
}
var ttl int
if link.Deadline.IsZero() {
ttl = confCodeTtl
} else {
if remainSeconds := int(link.Deadline.Sub(time.Now().UTC()).Seconds()); remainSeconds < confCodeTtl {
ttl = remainSeconds
} else {
ttl = confCodeTtl
}
}
if err := s.Cache.Set(ctx, code, link.LongUrl, ttl); err != nil {
return nil, err
}
return link, nil
}
func (s *RedirectSvc) notFound(code string) (RedirectRes, error) {
return RedirectRes{
StatusCode: http.StatusNotFound,
Msg: fmt.Sprintf("短链接(%s)无对应的长链接地址", code),
}, nil
}
func (s *RedirectSvc) redirect(longUrl string) (RedirectRes, error) {
return RedirectRes{
StatusCode: confRedirectStatusCode,
Redirect: true,
LongUrl: longUrl,
}, nil
}
func (s *RedirectSvc) internalErr(err error) (RedirectRes, error) {
return RedirectRes{
StatusCode: http.StatusInternalServerError,
}, err
}handler主要逻辑为:从url path获取code,假如我们一个短链接url为https://a.b.c/L0YdcA, code即为"L0YdcA",code作为参数调用跳转service,根据service返回结果响应错误信息,或者跳转到目标长链接。
service主要逻辑为:先从缓存获取code对应的长链接url,如果缓存中存在,则跳转。否则读取数据库获取长链接,如果数据库存在,将code和长链接数据写入缓存并跳转;否则返回404。
当然,通过上面的代码发现,除了前面service主要逻辑,加了两点料,如何应对缓存穿透和缓存击穿(什么是缓存雪崩、缓存击穿、缓存穿透?)。
缓存穿透
概念:我们使用缓存大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在缓存中的,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
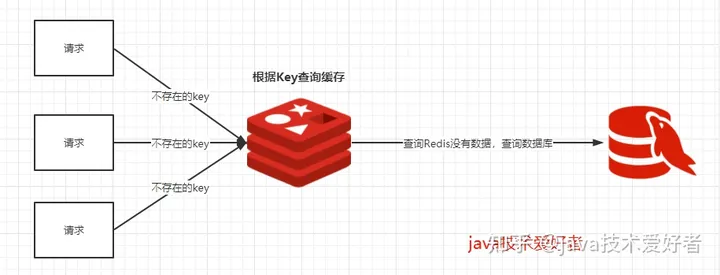
在我们短链接业务中,某个客户申请了一个短链接,并设置有效期到72小时后。该客户将连接嵌入到微博内容中,假如72小时后,该微博突然火了。那么大量这个短链接请求进来,按照常规逻辑,这个短链接已过期,缓存中没有这个key,自然就都去请求数据库。我们就遇到缓存击穿。
两种应对之道:1、设置请求过来的不存在的code在缓存中一个标志为不存在的零值;2、使用布隆过滤器
说一下布隆过滤器,详细原理等可以看这篇,5 分钟搞懂布隆过滤器,亿级数据过滤算法你值得拥有。本文不展开细说,总之布隆过滤器作用相当于一个数据容器,它可以使用很小的内存,保存大量的数据,用来判断某个数据是否存在。Redis 4.0 的时候官方提供了插件机制,集成了布隆过滤器。Golang也有相应的布隆过滤器库(https://github.com/bits-and-blooms/bloom)。然而我们不使用布隆过滤器应对缓存穿透。理由如下:
1、初始化时要将所有数据加载到布隆过滤器。想象一下,我们的服务非常火,数据库有上亿数据,要全表扫描。
2、如果使用redis集成的布隆过滤器,我们要先查询对应的key,如果key不存在,再查询布隆过滤器,布隆过滤器也不存在,则无需请求数据库。而redis布隆过滤器只支持添加和查询操作,不支持删除操作。假如某个链接code已过期,数据库已删除这个数据,那么这个也应该从布隆过滤器删除,没法搞。
3、假如我们使用Golang第三方库,也就是在程序内存中构建布隆过滤器。我们先查询布隆过滤器,布隆过滤器中不存在,则不需要请求缓存和数据库。首先,全量数据全部加载到内存布隆过滤器,程序启动时间无法估量。另一致命问题是,多个节点服务实例运行,内存的数据同步问题。假如有3个短链接服务实例运行A/B/C,实例B接收到添加短链接请求,添加这个短链接到自己内存的布隆过滤器,要怎么实时通知并更新另外两个服务实例的布隆过滤器呢,难搞。
综上,我们使用应对缓存穿透策略为,设置请求过来的不存在的code在缓存中存一个标志为不存在的零值(代码中提到的confCacheNotFoundValue)。
缓存击穿
概念:突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
我们短链接服务中,所有短链接在缓存全部设置了有效期,即使这个短链接永不过期。一个短链接code在缓存中失效,这个code非常热点,请求并发很高,则大量请求读数据库然后写缓存。
两种应对之道:1、如果业务允许的话,对于热点的key可以设置永不过期的key。2、使用互斥锁。如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库打死。
设置不过期的key不用考虑,有过期时间的code一定要设置过期时间,不过期的code,可能短链接创建前期会被频繁访问,到后期就很可能成为僵尸数据,一直占据缓存。
使用互斥锁,golang有个非常适合解决这个问题的库,单飞:golang.org/x/sync/singleflight。不了解singleflight,可以先瞄一眼这里(golang防缓存击穿神器【singleflight】)。singleflight ,大量同一个code请求数据库(耗时io操作),那么在内存维护一个全局变量,它有一个互斥锁的map保存code,后续并发请求过来,发现code在map存在,说明已经有请求在获取这个code,那么只需等前面请求拿到结果,后面的请求都用这个结果就行。如此多个并发请求数据库,就合并为一个请求到数据库了,妙妙妙!
singleflight源码就两个文件,其中一个为单元测试。看看代码singleflight.go
// call is an in-flight or completed singleflight.Do call
type call struct {
wg sync.WaitGroup
// These fields are written once before the WaitGroup is done
// and are only read after the WaitGroup is done.
val interface{}
err error
// These fields are read and written with the singleflight
// mutex held before the WaitGroup is done, and are read but
// not written after the WaitGroup is done.
dups int
chans []chan<- Result
}
// Group represents a class of work and forms a namespace in
// which units of work can be executed with duplicate suppression.
type Group struct {
mu sync.Mutex // protects m
m map[string]*call // lazily initialized
}
// Result holds the results of Do, so they can be passed
// on a channel.
type Result struct {
Val interface{}
Err error
Shared bool
}
// Do executes and returns the results of the given function, making
// sure that only one execution is in-flight for a given key at a
// time. If a duplicate comes in, the duplicate caller waits for the
// original to complete and receives the same results.
// The return value shared indicates whether v was given to multiple callers.
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
c.dups++
g.mu.Unlock()
c.wg.Wait()
if e, ok := c.err.(*panicError); ok {
panic(e)
} else if c.err == errGoexit {
runtime.Goexit()
}
return c.val, c.err, true
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
g.doCall(c, key, fn)
return c.val, c.err, c.dups > 0
}细心的大佬可能注意到,我们使用singleflight是在读取数据库这里,为什么不在读缓存时使用singleflight。如果缓存这里使用singleflight,可以有效减少对缓存的读取io啊,多好啊。
我来反驳一下这个天真的想法:
1、读取缓存很快
2、singleflight要通过互斥锁sync.Mutex读写一个全局变量的map。假如不管有没有过期的所有code都来,都经过singleflight,互斥读写这个全局map,数据竞争大。而针对数据库singleflight,仅仅会是缓存过期的code互斥读写map,数据竞争小。
总结
写完了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号