数据库一对多、多对多关系 ,单表操作,数据迁移
⼀对多关系

班级是1端,学⽣是多端,结合⾯向对象的思想,1端是⽗亲,多端是⼉⼦,所以多端具有1端的属性,也就是说多端⾥⾯应该放置1端的主键,那
么学⽣表⾥⾯应该放置班级表⾥⾯的主键
新增一个关系表,用来表示学生与班级的属于关系,该关系表包含字段(学生号,班级号)。通过学生号与班级号的对应关系表示学生属于的班级。
多对多关系
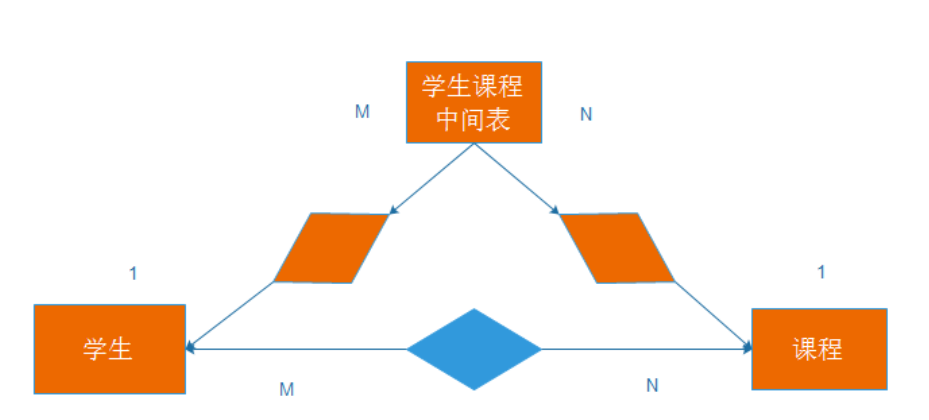
对于多对多关系,需要转换成1对多关系,那么就需要一张中间表来转换,这张中间表里面需要存放学生表里面的主键和课程表里面的主键,此时学生与中间表示1对多关系,课程与中间表是1对多关系,学生与课程是多对多关系
MySql单表
数据库概述:保存数据的仓库 我们可以向数据库里保存、获取、修改、删除数据,在实际的web应用开发过程中,需要通过Java程序来操作数据库。数据库的本质是一个文件系统
MySql的table的操作:
create table 表名称(字段1 字段类型 [约束],字段2 字段类型 [约束],.....字段n 字段类型 [约束]);创建table表格
show tables;列出所有table表格
desc 表名称;查看表结构
rename table 表名称 to 新表名称; 重命名表
alter table 表名称 add 字段名称 字段类型 [约束];添加字段
alter table 表名称 modify 字段名称 字段类型 [约束];修改字段类型
alter table 表名称 change 原字段名 新字段名 字段类型 [约束];修改字段名称
alter table 表名称 drop 字段名;删除字段
drop table 表名称;删除table
(五) 数据库的操作
一丶插入数据
向表里所有字段插入数据
insert into 表名称 values (字段1的值, 字段2的值,… 字段n的值);
注意:表里有几个字段,就必须有几个值;值的顺序必须要和字段的顺序一样;数值要符合字段的精度要求
向表里指定字段插入数据
insert into 表名称 (字段1, 字段2,… 字段n) values (字段1的值, 字段2的值,… 字段n的值);
注意:写了几个字段,就必须有几个值;值和顺序要和字段的顺序一样;数值要符合字段的精度要求
在SQL语句里,可以以字符串的形式插入任何类型字段的数据。
二丶修改数据
update 表名称 set 字段1=值, 字段2=值,… [where 条件]
三丶删除数据
delete from 表名称 [where 条件]
注意!删除数据时必须严格where条件以免误删数据,造成不必要的损失
四丶查询数据
基本查询
select * from 表名称; 查询所有字段
select 字段1, 字段2, … from 表名称; 查询指定字段
select 字段1, 字段2+500, 字段3-300,… from 表名称; 查询并运算
select 字段1, ifnull(字段2, 为null时的取值), 字段3,… from 表名称; 查询并处理null值
select 字段1 as 别名, ifnull(字段2, 为null时的取值)+500 as 别名,… from 表名称; #as可以省略不写
去重查询
select distinct 字段1, 字段2,… from 表名称;
条件查询
基本查询 where 条件
条件的写法:
比较运算符: >, <, >=, <=, =, <>(不等于)
范围运算:字段名 between 最小值 and 最大值
集合查询:字段名 in (值1,值2,值3,…)
模糊查询:字段名 like ‘字段%’ %表示任意个任意字符,_表示一个任意字符
not(条件):舍弃符合这个条件的数据
查询空值:字段名 is null
查询非空值: 字段名 is not null
条件的连接符:
and:条件必须都符合
or:符合任意一个条件即可
多个条件时,最好使用括号分隔开 如:工资大于8000的女性员工 和 年龄小于20的男性员工
例如:select * from employee where (salary > 8000 and gender = '女') or (age < 20 and gender = '男');
排序查询
基本查询: [where 条件] order by 排序字段 排序规则, 排序字段 排序规则, …;
排序规则 :升序排列asc, 降序排列desc
例如:select * from employee order by salary desc, age asc, id desc;
聚合查询
聚合函数:
count(*):统计个数 count(字段)
sum(字段):计算这个字段所有值的和
avg(字段):计算平均值
max(字段):求最大值
min(字段):求最小值
聚合函数会忽略null值
分组查询
select 分组字段, 聚合函数,… from 表 [where 条件] group by 分组字段 [having 分组后的过滤] order by 排序字段 排序规则
例如:select dept, count(), sum(salary), max(age), min(salary), avg(salary) from employee group by dept having count()>5 order by count(*) asc;
分组查询的执行过程:
先对基本表进行where过滤,得到过滤后的数据
对过滤后的数据按照分组字段进行分组,然后分组统计,得到分组后的结果(虚拟表)
对分组后的结果(虚拟表)进行having过滤
对having过滤后的结果进行排序显示出来
where和having的区别:
where是对基本表进行过滤的,having是对分组后的结果(虚拟表)进行过滤的
where条件先执行,分组后才会having的过滤执行
where条件里写基本表字段的一些条件,having里写分组后结果的字段进行过滤,或者 是聚合函数过滤
数据库的备份和恢复
1.使用可视化客户端工具备份和恢复
2.使用cmd命令行备份和恢复:
备份:mysqldump -u用户名 -p密码 [-h服务器ip地址 -P端口号] 数据库名>D:\bak.sql(备份路径及文件名称)
恢复:mysql -u用户名 -p密码 [-h服务器ip地址 -P端口号] 数据库名<D:\bak.sql
MySql乱码问题的处理
临时解决方案:
登录MySql之后,执行一条命令:set names gbk; 之后再执行SQL语句就正常了
但是这个设置,仅在这一次连接里是有效的,下次数据库连接任然会失效
永久解决方案:
找到MySql安装目录下的my.ini文件
搜索[mysql]后边的default-character-set=utf8 把值换成gbk,然后保存文件
注意:修改时可能会有修改权限问题 如果需要权限 则要通过使用管理身份运行记事本,在记事本中打开该文件,修改并保存;
需要重启MySql服务,修改的配置文件才会生效
数据迁移
场景:
1.从旧数据库中将数据迁移到全新的数据库
2.有两个数据库A和B,A中需迁移表的结构和B一样,A和B中都有各自的数据,现在要同步两个数据库
方法:
通过单表查询插入SQL语句
通过写数据库存储过程
通过写程序(这里采用java语言),将数据查询出来后,插入新数据库
注:主要介绍第一种方式,2和3简单介绍下思路,具体实现需后面再研究。1和2不一样的地方是,第二种方式存储过程实现的基本思路,是通过写语句,在迁移一条主表数据的时候,同时迁移其关联子表数据。而第一种方法,是一个表一个表的迁移,在有关联表的存在,所以要先迁移主表,后迁移子表。
实现:
通过单表查询插入SQL语句:
两个语句:
select * into TABLE_A from [192.168.0.110].reliability.dbo.TABLE_B where 条件1 nad 条件2
该语句会将TABLE_B中满足条件的数据拷贝到TABLE_A(TABLE_A在原数据库中不能存在,是脚本自动生成的表),注意此方法只能将数据进行拷贝,表结构不会保留(字段一样,单主键,外键,字段属性设置等都会丢失,可以理解成将查询出来的数据,进行简单保存)
如果要迁移数据库在两个不同服务器上,则要在新数据库上配置链接服务器,将旧数据库配置到新数据库上,新数据库就能通过[IP].数据库名.dbo.表名的形式,访问到旧数据库的数据
对于要同步新旧数据库数据(两个数据库都有各自的数据),会存在一个问题,待迁移主表主键为自增长,旧数据库待迁移数据的主键在新数据库中可能已经被占用。所以不能简单的直接将原本的主键拷贝过去。而且也不能令拷过去的数据主键自增长,因为这样其关联的子表就会不知道其关联的主表主键是多少。解决方式有几种思路:1.在新数据库中新增一个临时字段,记录旧表中的主键数据,子表迁移的时候根据该字段更新外键数据,最后在删除该字段(修改到表结构,有风险,自己评估)。2.通过写程序或存储过程的方式实现(较麻烦)。3.给待迁移的数据主键加上某个指定的值,令其主键大于现有最大值,保证其不会重复,然后子表迁移时,外键也加上该值。(需评估数据主键的范围是否满足)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号