Python学习笔记(一篇文章搞定)
Python学习笔记
Python的编程模式
Python的环境搭建很简单。只需要在网页搜索Python官网下载即可,我在这里下载的是当前最新的3.9.6。
下载并安装好之后会有好几个东西,我们需要用到的是IDLE(Python集成开发环境)。
python的编程和C语言不同,python分成两种编程模式:1.交互式编程;2.文件式编程。
进入IDLE之后显示的就是交互式编程。如下图所示。
前三行不需要搭理它。
Python 3.9.5 (default, May 4 2021, 03:36:27)
[Clang 12.0.0 (clang-1200.0.32.29)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> # 执行单行代码
>>> print("Hello")
Hello
>>>
>>> # 在语句结尾输入 \ 符号可以执行换行,从而执行多行代码
>>> if True: \
... print(123)
...
123
>>>
这种方法python会紧跟你的脚步去执行你的语句,可以让你清楚地看到你写的语句的执行结果。
还有一种文件式编程又称为批量式编程。就是在进入IDLE之后,点击左上角的file,New file。打开一个文件,在里面编写你的代码然后保存,保存的时候自己记得是不是.py后缀。这就是文件式编程。
Python中的标识符和关键字
以下标识符被作为语言的保留字或称关键字,不可被用作普通标识符。关键字的拼写必须与这里列出的完全一致,大小写也不能错。
False await else import pass
None break except in raise
True class finally is return
and continue for lambda try
as def from nonlocal while
assert del global not with
async elif if or yield
这些关键字很重要,这些关键字的用法都需要记住!记住!记住!
除了关键字,某些标识符类具有特殊的含义。这些标识符类的命名模式是以下划线字符打头和结尾:1 _* 2 __*__ 3``__*。在这里不再叙说,对编程帮助不大。
Python表达式、缩进和注释
表达式是任何编程语言的基础,简单说一个具有完整功能最小表达即是一个表达式。
示例:最简单的表达式
print("Hello World")
示例:不完整的表达式
for i in [1,2,3]:
# for 循环语句不含循环体
修改完整后
for i in [1,2,3]:
print(i)
多行表达式
在Python表达式默认不支持换行书写,示例:
# 错误书写
ab = "a" +
"b"
我们可以用 \ 符号实现换行,\ 可以理解为告诉解释器表达式还没结束,示例:
# 正确书写
ab = "a" + \
"b"
你说解释器是什么?解释器和编译器有啥不同,都是为了把我们写的代码编译成计算机所熟知的的代码。那解释器和编译器的区别?
答:编译是将源代码转换成目标代码的过程。执行编译的计算机程序称为编译器,如下图:
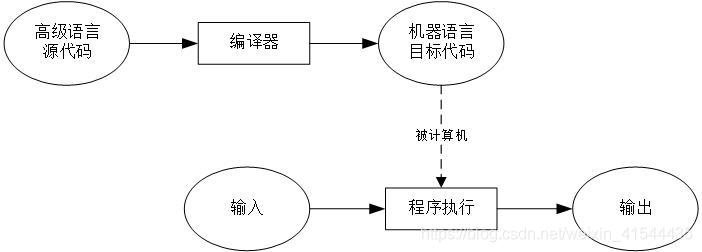
解释是将源代码逐条转换成目标代码同时逐条运行目标代码的过程。如下图:
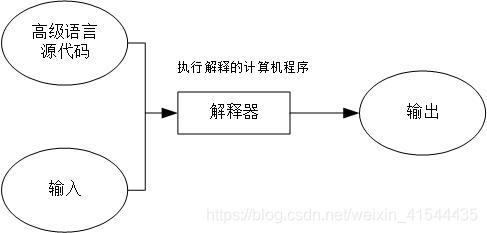
这里就知道了,区别在于编译是一次性翻译,一旦程序被编译,不再需要编译程序或者源代码。解释是每次程序运行时都需要解释器和源代码。类比英语资料的全篇翻译和实时的同声翻译。
除此之外 ()、[]、{} 三个符号(三个符号的区别见下)内的表达式默认支持换行,示例:
# () 表示为一个整体,在数学计算中 () 会提高计算优先级
str = (
"a" +
"b" +
"c"
)
# [] 表示一个列表结构(List)
arr = [
"a",
"b",
"c",
]
# {} 表示一个字典结构
tel = {
'jack': 4098,
'sape': 4139
}
Python 中的 ; 符号默认表达式结尾不需要以分号结尾(这里也是和C语言很大的一个区别),如果需要将两个表达式写在同一行可以用分号隔开示例:
print("Hello"); print("World")
缩进
大多数编程语言使用 {} 符号来定义代码块,示例:
// PHP 语言代码
if (true) {
echo "Hello";
}
// C 语言代码
#include
int main() {
if (1 > 0) {
printf("Hello");
}
return 0;
}
在Python中使用缩进替代 {} 定义代码块(不能再随意的首行缩进了!),实例:
if True:
print("Hello World")
# 空一行写下一个表达式
正确缩进,用4个空格来缩进您的代码块。 Python代码必须严格进行缩进,否则Python解释器会抛除错误:
IndentationError: expected an indented block
注释
注释用于说明一段代码的作用,单行注释以#开头即可。Python中使用 3个双引号""",或者3个单引号 ''' 来进行多行注释。
python文档字符串
先看一个示例:
# 定一个不包含文档字符串的函数
def fn_str():
print("fn_str")
# 使用 __doc__ 打印abc的帮助信息
print(fn_str.__doc__)
# 会输出 "None"
# ====================================================================
# 为函数添加文档字符串
def fn_str():
"""这是一个函数"""
print("fn_str")
print(fn_str.__doc__)
# 此时会输出 "这是一个函数"
文档字符串的作用就是为函数或者类添加文档信息,除了使用 doc 打印之外,还可以是用 help() 函数查看。
Python中的变量和字面值
变量
变量是编程语言最重要的组成元素之一
先看例子:
foo = "a"
# foo 就是一个变量,foo的值是 "a"
# 之所以叫做变量是变量的值可以改变
foo = "b"
print(foo) # 输出 b
变量是数据的载体,Python可以存放各种数据类型。
Python 使用 = 号声明变量
numberVar = 123 # 声明名称为numberVar的变量,变量值是数字
floatVar = 123 # 声明名称为numberVar的变量,变量值是数字
booleVar = True # 声明名称为numberVar的变量,变量值是数字
noneVar = True # 声明名称为numberVar的变量,变量值是数字
listVar = [1,2,3,4,5] # 声明名称为numberVar的变量,变量值是数字
# 还可以把一个函数 "存储" 到变量中 👇
def func():
print("this a function")
funcVar = func
funcVar()
# 输出 "this a function"
字面量
字面值即文字的具体的值,并且不可修改,看起来可能比较拗口:10 的字面值是 10。
示例:
print(10) # 打印10的字面值,输出10
print("abc") # 打印abc的字面值,输出abc
# 如果尝试修改字面值,会收到Python解释的报错
"abc" = 111
#输出:错误:SyntaxError: cannot assign to literal
Python数据类型
内置数据类型
在编程中,数据类型是一个重要的概念。
变量可以存储不同类型的数据,并且不同类型可以执行不同的操作。
在这些类别中,Python 默认拥有以下内置数据类型:
| 文本类型: | str |
|---|---|
| 数值类型: | int, float, complex |
| 序列类型: | list, tuple, range |
| 映射类型: | dict |
| 集合类型: | set, frozenset |
| 布尔类型: | bool |
| 二进制类型: | bytes, bytearray, memoryview |
获取数据类型
您可以使用 type() 函数获取任何对象的数据类型:
Python 数据类型转换
显式的类型转换
顾名思义,开发者主动进行的类型转换称之为 “显式类型转换”
包括上面使用的 int() 函数,Python进行类型转换的内置函数的其他示例:
print(int("10")) # 将 字符串 "10" 转换为整数 10
print(str(10)) # 将 整数 10 转换为 字符串 "10"
print(float(10)) # 将 整数 10 转换为 浮点数 10.0
print(str(True)) # 将 布尔值转换为字符串 得到字符串 "True"
print(int(True)) # 将 布尔值转换为字符串 得到字符串 "True"
print(bool(1)) # 将 整数 1 转换为 True
隐式类型转换
在整数和浮点数混合运算中,Python解释器会自动转换类型,将整数向浮点数转换以保持数值精度(有浮点数参与了就OK)
示例:
print(10 + 1.0) # 输出 11.0
Python中的运算符
和其他编程语言雷同,这里贴一个链接不熟悉的可以传送门学习:https://www.runoob.com/python/python-operators.html
成员检测运算
有两个成员检测符号:
in 如果对象在序列中返回 True
not in 如果对象不在序列中返回 True
成员检测主要作用于 列表 (list)、元祖 (tuple)、映射 (dict)。
示例:
# 列表成员检测
print(2 in [1,2,3]) # 输出 True
print(2 not in [1,3]) # 输出 True
# 元祖成员检测
print((2) in (1,2,3)) # 输出 True
print((2) not in (1,3)) # 输出 True
# 映射成员检测
print("one" in {"one": 1, "two": 2}) # 输出 True
print("three" not in {"one": 1, "two": 2}) # 输出 True
Python结构控制
Python条件控制
单分支结构:if语句
if <条件>:
<语句块>
high = int(input("请输入你的身高:"))
if high >= 160:
print("你是一个帅哥")
二分支结构:if-else语句
if <条件>:
<语句块>
else:
<语句块>
high = int(input("请输入你的身高:"))
if high >= 160:
print("你是一个美女")
else:
print("你是一位帅哥")
#没有任何歧视
多分支结构:if-elif-else语句
if <条件>:
<语句块>
elif <条件>:
<语句块>
else:
<语句块>
high = int(input("请输入你的身高:"))
if high >= 160:
print("你是一个美女")
elif high>=100:
print("你是一位帅哥")
else:
print("不知道说啥了")
#没有任何歧视
上面例子中 else 结构是默认条件,当以上条件全都不成立时,执行 else 结构中代码
Python循环控制
循环语句用于循环执行一个或多个表达式。
for 循环
for循环是一种知道循环次数的循环,又称之为遍历循环。循环次数通过遍历结构中的元素个数来体现
for <循环变量> in <遍历结构>:
<语句块>
这里的遍历结构可以是列表【1,2,3】。
也可以是字符串“abc” 'abc '。
也可以是下文提到的range函数。
示例:
# -*- coding: utf-8 -*-
# 迭代列表,打印字符串长度:
words = ['猫', '田园猫', '中华田园猫']
for w in words:
print(w, len(w))
# 迭代字符串序列:
word = '中华田园猫'
for w in word:
print(w)
range() 函数!!!!!!!!!!一般这个用的多
我们在本章开始时已经使用 range() 函数创建 a-z 的字符列表,函数 range() 常用于遍历数字序列,该函数可以生成算术级数:
print(range(10))
# 输出 range(0, 10)
# 使用内置函数 list() 生成 list
print(list(range(0, 10)))
# 输出 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for n in range(10,20): # 迭代 10 到 20 之间的数字
range() 接受两个参数,第一个参数开始位置(包含),第二参数结束位置(不包含),如果只传一个参数默认从0开始。
while循环
这种循环又称之为非确定次数循环。又称作为无限循环。
while <条件>:
<语句块>
死循环:当逻辑出错时,条件永远是 True,则会造成死循环,尝试使用 Ctrl+C 结束程序。
示例:
cond = True
while cond:
cond = False
print("执行一次,将 cond 条件修改为 False 结束循环")
还有一种while的else拓展形式:
while <条件>:
<语句块1>
else:
<语句块2>
在这里就不举例了,当条件不满足时会接着往下执行else的语句,这个else可以一个while退出的标志。
s,idx = "ABC",0
while idx < len(s):
print("ing:" + s[idx])
idx += 1
else:
s = "end"
print(s)
#输出
#ing:A
#ing:B
#ing:C
#end
循环中的 break、continue、pass 语句
break用于终止循环continue跳过匹配的循环,回到循环起点重新执行pass占位语句, 无任何实际操作
for n in [1, 2, 3, 4, 5, 6, 7, 8]:
if n == 4:
# 当 n 等于 4 时终止循环
break
else:
print(n)
# 输出 1 2 3
for n in [1, 2, 3, 4, 5, 6, 7, 8]:
if n == 4:
# 当 n 等于 4 跳过本次循环
continue
else:
print(n)
# 1 2 3 5 6 7 8
if True:
print("达成条件,执行此流程")
else:
# 占位,无任何作用
pass
Python函数
函数的定义
函数是一个功能模块的封装,函数可以让写好的功能模块可以更容易重复使用。
def <函数名>(参数列表):
<函数体>
return <返回值列表>
示例:
# 使用 def 关键词定义函数
def get_name_and_age():
"""获取姓名和年龄并输出"""
name = input("姓名:")
age = input("年龄:")
print(f"姓名:{name},年龄{age}")
# 调用函数
get_name_and_age()
函数内的第一条语句是字符串时,该字符串就是文档字符串 (docstring),通过*._doc_来调用(忘记了)。print(函数名.doc)可以用。
函数参数
函数定义详解:函数参数
参数是使用者提供给函数的数据值,值可以是多种类型。
示例:
# 定义一个函数计算指定数字自身的乘方
def my_pow(n: int):
calc = 1
for _ in range(n):
calc *= n
return calc
print(my_pow(3)) # 输出27
print(my_pow(5)) # 输出3125
函数的返回值
Python 使用 return关键词返回数据供给调用后的逻辑使用,返回值可以多种类型,甚至是一个函数(function)或者类(class)。
形参和实参数
函数定义时的参数称为 “形参”,调用是传入的实际参数称为 “实参”,
默认值参数
为参数指定默认值是非常有用的方式。调用函数时,可以使用比定义时更少的参数,例如:(有默认值的参数可以不用管,没有的一定要管)
# 声明一个函数,并为性别设置默认值
def input_you_info(name: str, age: int, sex: str = "男"):
return (
f"name: {name}\n"
f"age: {age} 岁\n"
f"sex: {sex} 性"
)
# 省略性别调用函数
# 且另外两个都不能少
print(input_you_info("小明", 18))
"""
输出:
name: 小明
age: 18 岁
sex: 男 性
"""
(警告:默认值只初始化一次,当默认值是列表(这也是下面累积的原因)、字典、Class实例等可变对象时,会产生与预期不同的结果。)
示例,下面定义的的函数会累积每次调用时传递的参数:
append()函数描述:在列表ls最后(末尾)添加一个元素
def f(a, L=[]):
L.append(a)
return L
print(f(1))
# 输出 [1]
print(f(2))
# 输出 [1, 2]
print(f(3))
# 输出 [1, 2, 3]
不想在每次调用之间共享默认值时,应该使用如下方式编写函数
def f(a, L = None):
if L is None:
L = []
L.append(a)
return L
'''
def f(a, L = []):
L = []
L.append(a)
return L
#这种方法就只能输出一个了
'''
r = f(1)
print(r) # 输出 [1]
r = f(2, r)
print(r) # 输出 [1, 2]
r = f(3, r)
print(r) # 输出 [1, 2, 3]
r = f(1)
print(r) # 输出 [1]
Python全局变量和局部变量
函数内部只作引用的 Python 变量隐式视为全局变量。如果在函数内部任何位置为变量赋值,则除非明确声明为全局变量,否则均将其视为局部变量。
(已分配的变量要求加上 global 可以防止意外的副作用发生。另一方面,如果所有全局引用都要加上 global ,那处处都得用上 global 了。那么每次对内置函数或导入模块中的组件进行引用时,都得声明为全局变量。这种杂乱会破坏 global 声明用于警示副作用的有效性。)
示例
(在foo函数中,x只被引用,变量隐式视为全局变量)
x = 10
def foo():
print(x)
foo()
# 输出 10
在函数内部任何位置为变量赋值,则除非明确声明为全局变量,否则均将其视为局部变量。
x = 10
def foo():
x += 1 # 对 x 重新赋值,x 被视为局部变量
print(x)
foo()
# 发生错误: UnboundLocalError: local variable 'x' referenced before assignment
global 关键词
使用 global 关键词,显式的将变量声明为全局变量。
x = 10
def foobar():
global x
# 使用
x += 1
print(x)
foobar()
# 输出 11
局部变量
在函数内 (适用于类的方法) 声明的变量是局部变量,在外部无法使用
def local_foo():
local_variable = 10
print(local_variable)
# 如果使用在外部使用函数内声明的变量,会提示:NameError: name 'local_variable' is not defined
Python数据结构
原文链接:https://blog.csdn.net/weixin_41544435/article/details/119320085
Python模块和包
模块是包含一组函数的文件,希望在应用程序中引用。
创建模块
如需创建模块,只需将所需代码保存在文件扩展名为 .py 的文件中:
示例:
在名为 mymodule.py 的文件中保存代码:
def greeting(name):
print("Hello, " + name)
使用模块
现在,我们就可以用 import 语句来使用我们刚刚创建的模块:
示例:
导入名为 mymodule 的模块,并调用 greeting 函数:
import mymodule
mymodule.greeting("Bill")
注释:如果使用模块中的函数时,请使用以下语法:
module_name.function_name
模块中的变量
模块可以包含已经描述的函数,但也可以包含各种类型的变量(数组、字典、对象等):
示例:
在文件 mymodule.py 中保存代码:
person1 = {
"name": "Bill",
"age": 63,
"country": "USA"
}
示例:
导入名为 mymodule 的模块,并访问 person1 字典:
import mymodule
a = mymodule.person1["age"]
print(a)
为模块命名
您可以随意对模块文件命名,但是文件扩展名必须是 .py。
重命名模块
您可以在导入模块时使用 as 关键字创建别名:
示例:
为 mymodule 创建别名 mx:
import mymodule as mx
a = mx.person1["age"]
print(a)
内建模块
Python 中有几个内建模块,您可以随时导入。
示例:
导入并使用 platform 模块:
import platform
x = platform.system()
print(x)
使用 dir() 函数列出模块中的所有函数名(或变量名)
有一个内置函数可以列出模块中的所有函数名(或变量名)。dir() 函数:
示例:
列出属于 platform 模块的所有已定义名称:
import platform
x = dir(platform)
print(x)
从模块导入
您可以使用 from 关键字选择仅从模块导入部件。
示例:
名为 mymodule 的模块拥有一个函数和一个字典:
def greeting(name):
print("Hello, " + name)
person1 = {
"name": "Bill",
"age": 63,
"country": "USA"
}
示例:
仅从模块导入 person1 字典:
from mymodule import person1
print (person1["age"])
提示:在使用 from 关键字导入时,请勿在引用模块中的元素时使用模块名称。示例:person1["age"],而不是 mymodule.person1["age"]。
Python面向对象
类class和object对象
类定义语法
最简单的类定义看起来像这样:
class ClassName:
类对象
类对象支持两种操作:属性引用和实例化。
属性引用 使用 Python 中所有属性引用所使用的标准语法: obj.name。 有效的属性名称是类对象被创建时存在于类命名空间中的所有名称。 因此,如果类定义是这样的:
class MyClass:
"""A simple example class"""
i = 12345
def f(self):
return 'hello world'
那么 MyClass.i 和 MyClass.f 就是有效的属性引用,将分别返回一个整数和一个函数对象。 类属性也可以被赋值,因此可以通过赋值来更改 MyClass.i 的值。 doc 也是一个有效的属性,将返回所属类的文档字符串: "A simple example class"。
类的实例化使用函数表示法。 可以把类对象视为是返回该类的一个新实例的不带参数的函数。 举例来说(假设使用上述的类):
x = MyClass()
创建类的新实例并将此对象分配给局部变量 x。
实例化操作(“调用”类对象)会创建一个空对象。 许多类喜欢创建带有特定初始状态的自定义实例。 为此类定义可能包含一个名为 __init__() 的特殊方法,就像这样:
def __init__(self):
self.data = []
当一个类定义了 __init__() 方法时,类的实例化操作会自动为新创建的类实例发起调用 __init__() 。 因此在这个示例中,可以通过以下语句获得一个经初始化的新实例:
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i)
# 3.0, -4.5
实例对象
现在我们能用实例对象做什么? 实例对象所能理解的唯一操作是属性引用。 有两种有效的属性名称:数据属性和方法。
数据属性对应于 Smalltalk 中的“实例变量”,以及 C++ 中的“数据成员”。 数据属性不需要声明;像局部变量一样,它们将在第一次被赋值时产生。 例如,如果 x 是上面创建的 MyClass 的实例,则以下代码段将打印数值 16,且不保留任何追踪信息:
x.counter = 1
while x.counter < 10:
x.counter = x.counter * 2
print(x.counter)
del x.counter
另一类实例属性引用称为方法。 方法是“从属于”对象的函数。 (在 Python 中,方法这个术语并不是类实例所特有的:其他对象也可以有方法。 例如,列表对象具有 append, insert, remove, sort 等方法。 然而,在以下讨论中,我们使用方法一词将专指类实例对象的方法,除非另外显式地说明。)
实例对象的有效方法名称依赖于其所属的类。 根据定义,一个类中所有是函数对象的属性都是定义了其实例的相应方法。 因此在我们的示例中,x.f 是有效的方法引用,因为 MyClass.f 是一个函数,而 x.i 不是方法,因为 MyClass.i 不是函数。 但是 x.f 与 MyClass.f 并不是一回事 — 它是一个 方法对象,不是函数对象。
类的继承
当然,如果不支持继承,语言特性就不值得称为“类”。派生类定义的语法如下所示:
class DerivedClassName(BaseClassName):
.
名称 BaseClassName 必须定义于包含派生类定义的作用域中。 也允许用其他任意表达式代替基类名称所在的位置。 这有时也可能会用得上,例如,当基类定义在另一个模块中的时候:
class DerivedClassName(modname.BaseClassName):
派生类定义的执行过程与基类相同。 当构造类对象时,基类会被记住。 此信息将被用来解析属性引用:如果请求的属性在类中找不到,搜索将转往基类中进行查找。 如果基类本身也派生自其他某个类,则此规则将被递归地应用。
派生类的实例化没有任何特殊之处: DerivedClassName() 会创建该类的一个新实例。 方法引用将按以下方式解析:搜索相应的类属性,如有必要将按基类继承链逐步向下查找,如果产生了一个函数对象则方法引用就生效。
派生类可能会重写其基类的方法。 因为方法在调用同一对象的其他方法时没有特殊权限,所以调用同一基类中定义的另一方法的基类方法最终可能会调用覆盖它的派生类的方法。 (对 C++ 程序员的提示:Python 中所有的方法实际上都是 virtual 方法。)
在派生类中的重载方法实际上可能想要扩展而非简单地替换同名的基类方法。 有一种方式可以简单地直接调用基类方法:即调用 BaseClassName.methodname(self, arguments)。 有时这对客户端来说也是有用的。 (请注意仅当此基类可在全局作用域中以 BaseClassName 的名称被访问时方可使用此方式。)
Python有两个内置函数可被用于继承机制:
使用 isinstance() 来检查一个实例的类型: isinstance(obj, int) 仅会在 obj.class 为 int 或某个派生自 int 的类时为 True。
使用 issubclass() 来检查类的继承关系: issubclass(bool, int) 为 True,因为 bool 是 int 的子类。 但是,issubclass(float, int) 为 False,因为 float 不是 int 的子类。
多重继承
Python 也支持一种多重继承。 带有多个基类的类定义语句如下所示:
class DerivedClassName(Base1, Base2, Base3):
对于多数应用来说,在最简单的情况下,你可以认为搜索从父类所继承属性的操作是深度优先、从左至右的,当层次结构中存在重叠时不会在同一个类中搜索两次。 因此,如果某一属性在 DerivedClassName 中未找到,则会到 Base1 中搜索它,然后(递归地)到 Base1 的基类中搜索,如果在那里未找到,再到 Base2 中搜索,依此类推。
真实情况比这个更复杂一些;方法解析顺序会动态改变以支持对 super() 的协同调用。 这种方式在某些其他多重继承型语言中被称为后续方法调用,它比单继承型语言中的 super 调用更强大。
动态改变顺序是有必要的,因为所有多重继承的情况都会显示出一个或更多的菱形关联(即至少有一个父类可通过多条路径被最底层类所访问)。 例如,所有类都是继承自 object ,因此任何多重继承的情况都提供了一条以上的路径可以通向 object 。 为了确保基类不会被访问一次以上,动态算法会用一种特殊方式将搜索顺序线性化, 保留每个类所指定的从左至右的顺序,只调用每个父类一次,并且保持单调(即一个类可以被子类化而不影响其父类的优先顺序)。 总而言之,这些特性使得设计具有多重继承的可靠且可扩展的类成为可能。 要了解更多细节,请参阅 https://www.python.org/download/releases/2.3/mro/。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号