软工homework2:个人项目-论文查重(Python)
| 这个作业属于哪个课程 | 广工计院计科34班软工 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 个人独立完成一次论文查重项目,完成项目后能够了解项目开发工程流程,学会使用PSP表格,完成性能分析以及测试等 |
零、GitHub地址
一、需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
- 原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
二、PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 80 |
| Estimate | 估计这个任务需要多少时间 | 740 | 750 |
| Development | 开发 | 300 | 250 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 25 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 35 |
| Design | 具体设计 | 50 | 40 |
| Coding | 具体编码 | 50 | 70 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 40 |
| Reporting | 报告 | 40 | 20 |
| Test Repor | 测试报告 | 40 | 50 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 740 | 750 |
三、算法与接口设计
1、接口部分
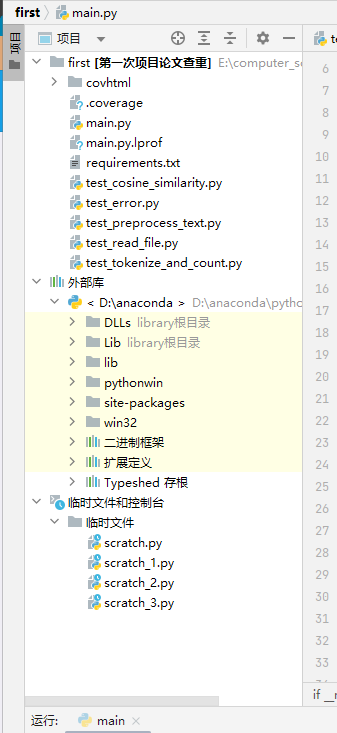
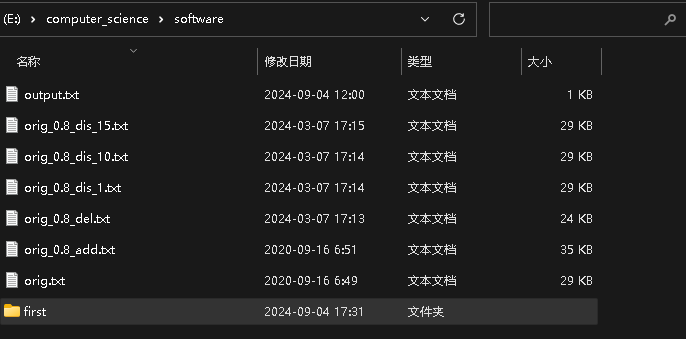
- 项目代码文件main.py与requirement.txt等测试代码文件存放于first文件夹,并且orig.txt原文和orig_add.txt等其他抄袭版论文以及输出文件output.txt与first文件夹一起存放在software文件夹下。
2、算法部分
代码组织
尽管没有直接使用类来组织代码,但函数之间的逻辑关系和职责划分仍然非常清晰。以下是每个函数的具体作用及其在组织中的角色:
1)文件操作
- 函数:read_file(file_path)
-
- 作用:负责从给定的文件路径读取文件内容,并将其作为字符串返回。
-
- 异常处理:如果文件不存在,将抛出FileNotFoundError异常。
-
- 角色:作为数据输入的第一步,为后续的文本处理提供原始数据。
2)文本预处理
- 函数:def preprocess_text(content)
-
- 作用:通过正则表达式去除文本内容中的常见中文标点符号,并返回清理后的文本字符串。
-
- 角色:数据预处理的关键步骤
3)文本处理
- 函数:tokenize_and_count(content)
-
- 作用:接收一段文本内容作为输入,使用jieba库进行分词,并统计每个词的出现次数,返回一个包含词频的字典。
-
- 角色:将原始文本数据转换为一种便于分析和比较的格式(即词频向量)。
4)相似度计算
- 函数:cosine_similarity(vec1, vec2)
-
- 作用:接收两个词频字典作为输入,计算它们之间的余弦相似度,并返回该值。
-
- 算法细节:
-
-
- 首先,计算两个向量的内积,即对应元素乘积的和。
-
-
-
- 然后,分别计算两个向量的模长(即每个元素平方和的平方根)。
-
-
-
- 最后,用内积除以两个模长的乘积,得到余弦相似度。
-
- 角色:提供衡量两个文本相似度的核心算法。
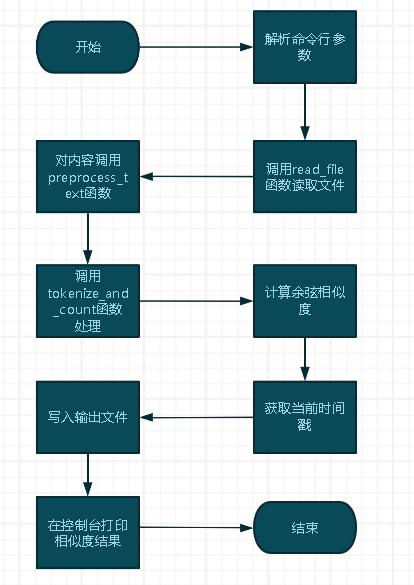
5)主函数
- 函数:main()
-
- 作用:程序的入口点,负责解析命令行参数,调用上述函数,并处理异常。
-
- 流程:
-
-
- 解析命令行参数,获取两个输入文件的路径和一个输出文件的路径。
-
-
-
- 调用read_file函数读取两个输入文件的内容。
-
-
-
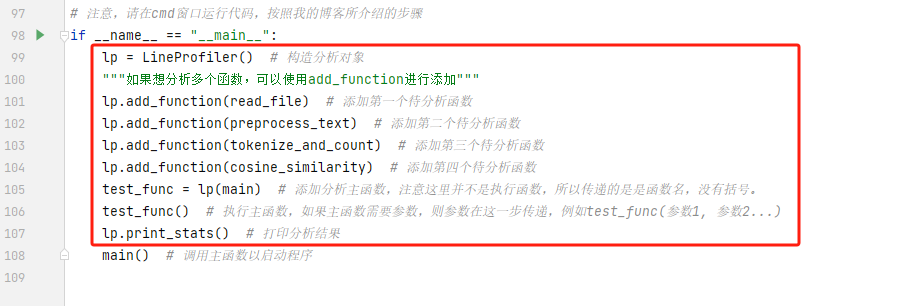
- 调用preprocess_text函数去除标点符号
-
-
-
- 调用tokenize_and_count函数处理读取到的内容,得到两个词频字典。
-
-
-
- 调用cosine_similarity函数计算两个词频字典的余弦相似度。
-
-
-
- 获取当前时间戳,格式化后准备写入输出文件。
-
-
-
- 打开输出文件,以追加模式写入相似度结果和时间戳。
-
-
-
- 在控制台打印相似度结果。
-
-
- 异常处理:捕获并处理FileNotFoundError,确保程序在遇到文件不存在时能够优雅地退出并给出错误信息。
函数之间的关系
- read_file:负责读取文件内容,是数据输入的第一步。
- preprocess_text:对读取到的文本进行预处理,如去除标点符号,是文本处理的前置步骤。
- tokenize_and_count:接收预处理后的文本,进行分词并统计词频,为相似度计算提供数据。
- cosine_similarity:接收两个词频字典,计算它们之间的余弦相似度。
- main:程序的入口点,负责解析命令行参数,调用上述函数,并处理异常。
这些函数之间通过参数传递和返回值进行交互,形成了一个清晰的执行流程。
函数流程图
-
主函数流程图
![]()
-
核心函数cosine_similarity流程图
![]()

算法的关键与独到之处
- 余弦相似度计算:这是算法的核心,通过计算两个词频向量的内积与它们模长的乘积之比来衡量文本之间的相似度。这种方法能够有效地捕捉文本之间的语义相似性,而不仅仅是字面上的相似性。
- 文本预处理:通过去除标点符号等预处理步骤,减少了噪声对相似度计算的影响,提高了算法的准确性和鲁棒性。
- 分词技术:使用jieba库进行中文分词,能够准确地将中文文本切分成有意义的词汇单元,为后续的统计和相似度计算提供了良好的基础。
- 命令行参数解析:通过argparse模块解析命令行参数,使得程序更加灵活和易于使用。用户可以通过命令行指定输入文件和输出文件的路径,而无需修改代码。
四、计算模块接口部分的性能分析
Code Quality Analysis
- PyCharm的Inspect Code提供了代码静态审查功能,可以检测出语法错误。在结果检查后将警告等全部清除。
- 我已经消除了所有的警告


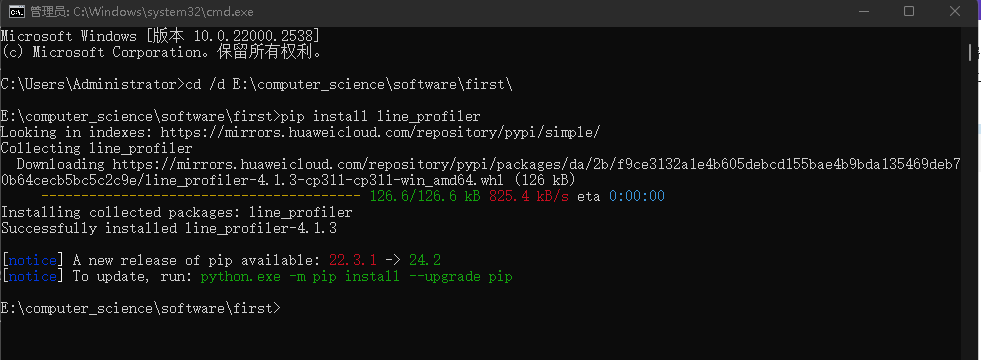
Python代码优化工具——line_profile
- 按照要求安装
![]()
- 这里我们使用python命令进行分析
-
- 引入第三方包LineProfiler
-
- 对代码做如下修改
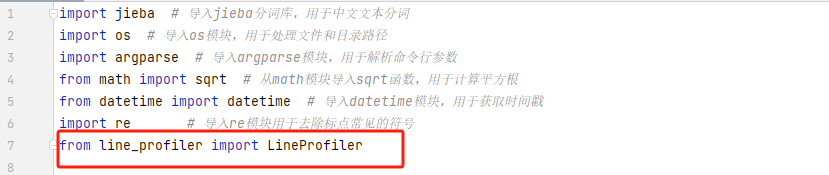
-
- 接着打开命令行窗口
-
- 分别输入下面两行命令(注意:这里是要根据你的项目文件存放地址来修改)
-
- 我们这里是以orig.txt 和 orig_0.8_add.txt为例
-
- cd /d E:\computer_science\software\first\
-
- python main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_add.txt" "E:\computer_science\software\output.txt"
-
- 窗口自动运行代码
-
运行结果

-
- 函数read_file(读取文件)
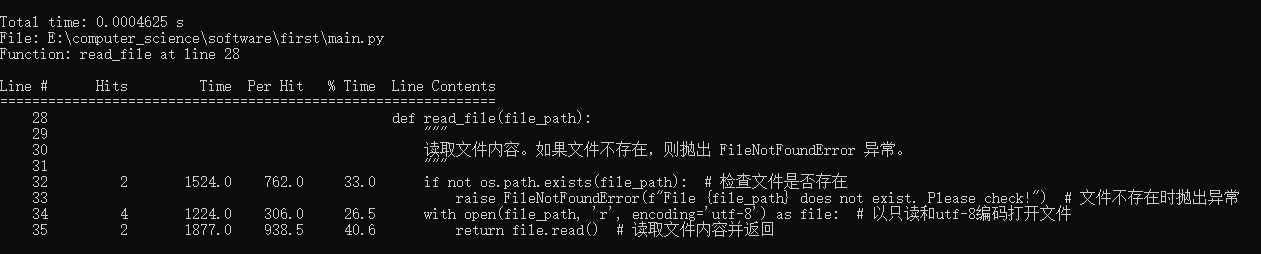
-
- preprocess_text(文本预处理-删除标点符号)
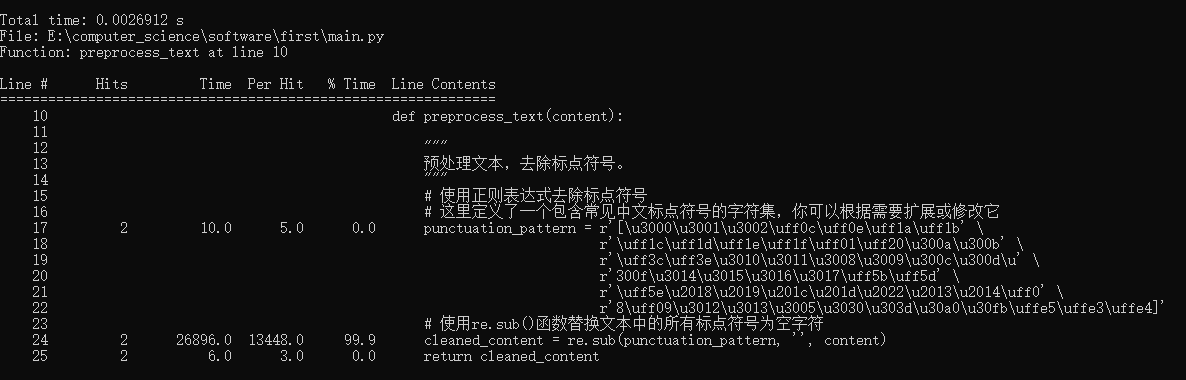
-
- 函数tokenize_and_count(文本处理)
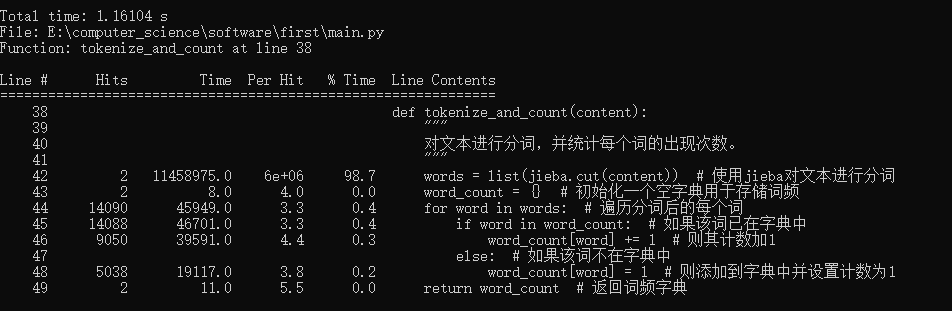
-
- 函数cosine_similarity(计算余弦相似度)
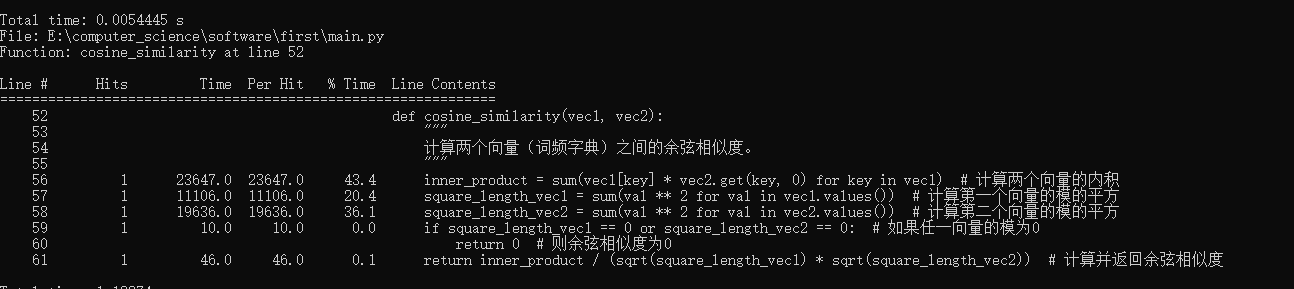
-
- 主函数main
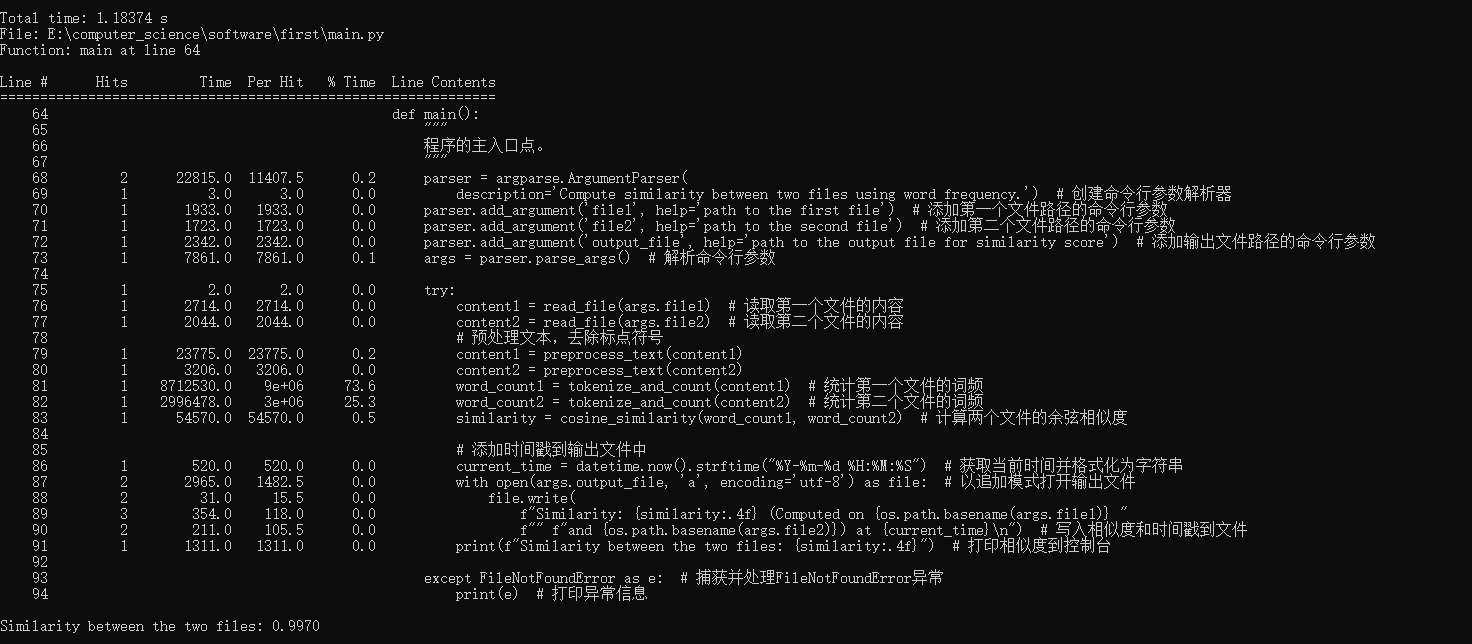
-
- 我们可以得到函数tokenize_and_count的用时最长,并且耗时达到1.16104 s,代码如下
def tokenize_and_count(content):
"""
对文本进行分词,并统计每个词的出现次数。
"""
words = list(jieba.cut(content)) # 使用jieba对文本进行分词
word_count = {} # 初始化一个空字典用于存储词频
for word in words: # 遍历分词后的每个词
if word in word_count: # 如果该词已在字典中
word_count[word] += 1 # 则其计数加1
else: # 如果该词不在字典中
word_count[word] = 1 # 则添加到字典中并设置计数为1
return word_count # 返回词频字典
-
- 此时我尝试去改进该函数tokenize_and_count,改进如下
-
- 从减少内存使用和可能的重复计算上着手。由于jieba分词已经相对高效,主要的优化点可能在于词频统计的效率和内存使用上。
-
- 从collections模块导入Counter类。
-
- 这个改进主要利用了Counter的效率和便捷性。Counter可以直接从可迭代对象(如jieba分词的生成器)中统计元素出现的次数,无需手动遍历和更新字典。

-
- 可惜结果并非如我所愿,用时依旧相差无几
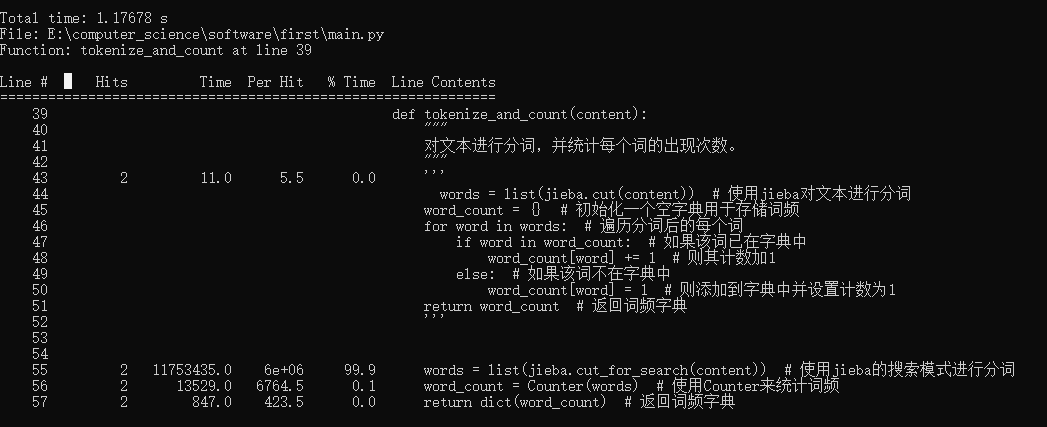
-
- 所以我目前暂时无法再改进性能了。。。。。。。也许其他人会有。。
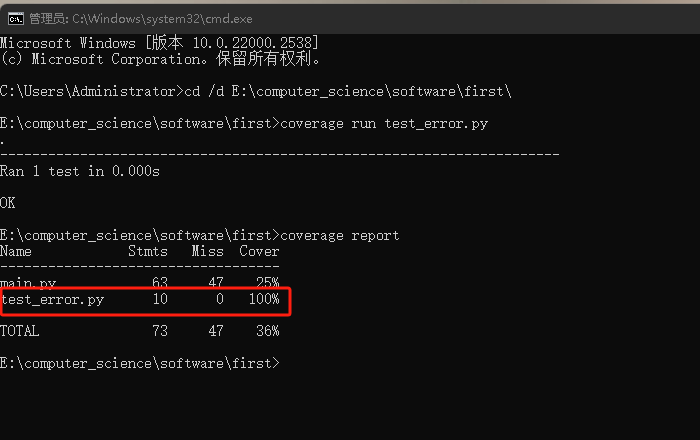
Python代码覆盖率分析工具----Coverage(这个分析是以学习为目的而额外进行的)
- Coverage是一个Python代码覆盖率分析工具,它可以用于衡量Python测试代码的质量。通过给代码执行带来的覆盖率数据,Coverage可以帮助我们找出测试代码中的漏洞,并且指明哪些代码没有被测试到。以下对代码进行覆盖率测试:
- 按要求安装
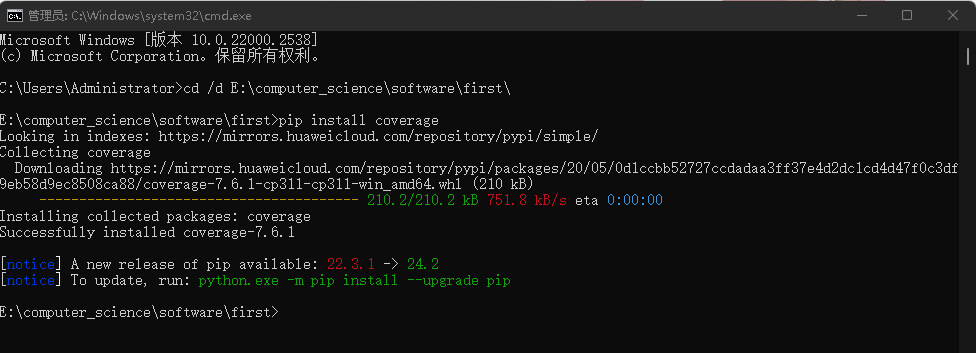
* 引入第三方库unittest (import unittest)并修改以下代码(后续补充:这一步可以不做,但是后面单元测试会用到)
![]()
- 在命令行窗口分别输入如下命令(注意,要改成你自己的)
-
- cd /d E:\computer_science\software\first\
-
- coverage run main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_add.txt" "E:\computer_science\software\output.txt"
-
- coverage report
- 运行结果如下
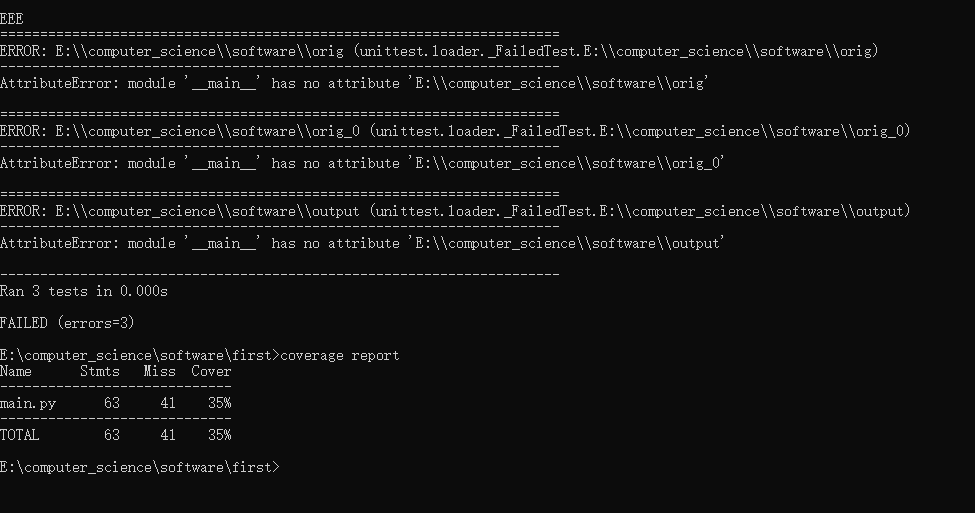
-
- 发现覆盖率不高,我通过coverage html -d covhtml命令自动生成网页版报告,然后去查看代码覆盖情况(打开下图的文件),发现可能是测试的缘故,很多代码被我注释掉了。在这里我仍然有疑问,明明代码能正常跑出结果,但是覆盖报告却显示没有覆盖到核心代码,后续再进行修改测试补充,还请读者见谅。
五、单元测试
- unittest是python自带的一个单元测试框架,不仅适用于单元测试,还可用于Web、Appium、接口自动化测试用例的开发与执行;此框架可以组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否执行通过,并生成测试结果。经过单元测试,覆盖率都是100%!最后的结果与上面的覆盖率分析截然相反,我判断是命令输入不对或者其他小问题,总之代码整体性应该没什么问题才对!
test_read_file.py
- 需要测试的函数代码
def read_file(file_path):
"""
读取文件内容。如果文件不存在,则抛出 FileNotFoundError 异常。
"""
import os # 确保在代码中导入了os模块
if not os.path.exists(file_path):
raise FileNotFoundError(f"File {file_path} does not exist. Please check!")
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
- 构造测试数据的思路
-
- 文件存在且有内容的场景
-
-
- 目标:验证函数能够正确读取并返回文件内容。
-
-
-
- 测试数据:创建一个包含普通文本内容的文件(如test1.txt,内容为Hello, world!)。
-
-
- 文件存在但为空的场景
-
-
- 目标:验证函数能够正确处理并返回空文件的内容(即空字符串)。
-
-
-
- 测试数据:创建一个空文件(如test2.txt)。
-
-
- 文件包含Unicode内容的场景
-
-
- 目标:验证函数能够正确读取并返回包含Unicode字符的文件内容。
-
-
-
- 测试数据:创建一个包含Unicode字符的文件(如test3.txt,内容为こんにちは、世界!)。确保文件以UTF-8编码保存,因为read_file函数以UTF-8编码读取文件。
-
-
- 文件不存在的场景
-
-
- 目标:验证函数在文件不存在时能够正确抛出FileNotFoundError异常。
-
-
-
- 测试数据:构造一个不存在的文件路径(如nonexistent.txt)。无需实际创建该文件,因为测试的是异常处理逻辑。
-
-
- 文件包含特殊字符的场景
-
-
- 目标:验证函数能够正确读取并返回包含特殊字符的文件内容。
-
-
-
- 测试数据:创建一个包含特殊字符的文件(如test_special.txt,内容为!@#$%^&*()_+{}:"<>?)。确保文件内容能够正确表示这些特殊字符。
-
-
- 文件包含换行符的场景
-
-
- 目标:验证函数能够正确读取并返回包含换行符的文件内容。
-
-
-
- 测试数据:创建一个包含换行符的文件(如test_newlines.txt,内容为Hello\nWorld)。确保换行符在文件中正确表示
-
-
- 了解更详细的测试内容,还请读者前往项目文件查看测试代码
- 测试结果
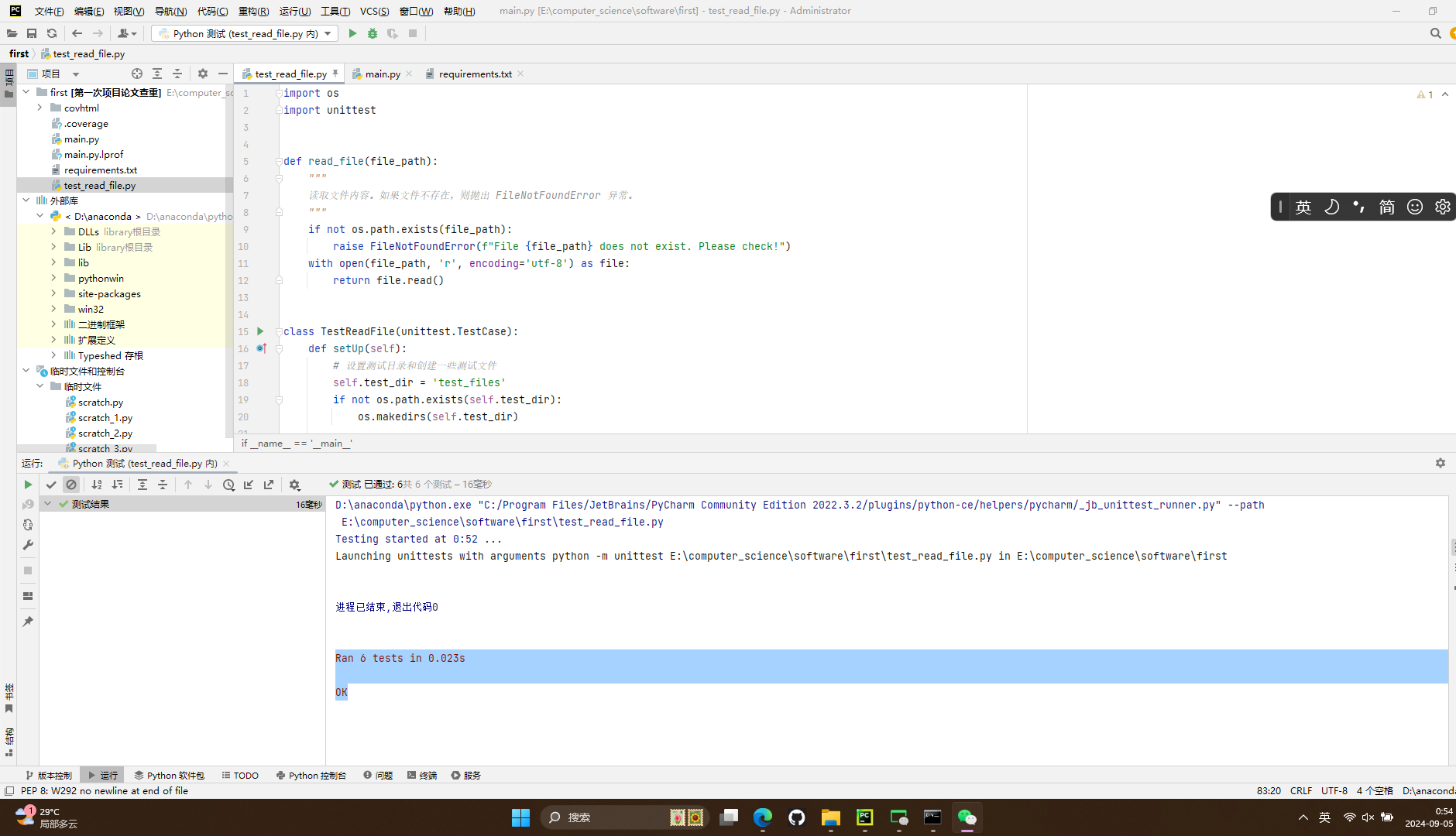
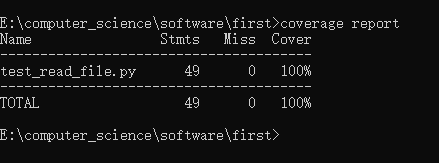
- 此处覆盖率100%
test_preprocess_text.py
- 需要测试的函数代码
def preprocess_text(content):
"""
预处理文本,去除标点符号。
"""
# 使用正则表达式去除标点符号
# 这里定义了一个包含常见中文标点符号的字符集,你可以根据需要扩展或修改它
punctuation_pattern = r'[\u3000\u3001\u3002\uff0c\uff0e\uff1a\uff1b' \
r'\uff1c\uff1d\uff1e\uff1f\uff01\uff20\u300a\u300b' \
r'\uff3c\uff3e\u3010\u3011\u3008\u3009\u300c\u300d\u' \
r'300f\u3014\u3015\u3016\u3017\uff5b\uff5d' \
r'\uff5e\u2018\u2019\u201c\u201d\u2022\u2013\u2014\uff0' \
r'8\uff09\u3012\u3013\u3005\u3030\u303d\u30a0\u30fb\uffe5\uffe3\uffe4]'
# 使用re.sub()函数替换文本中的所有标点符号为空字符
cleaned_content = re.sub(punctuation_pattern, '', content)
return cleaned_content
-
构造测试数据的思路
-
- 包含常见中文标点符号的文本
-
-
- 目标:验证函数能够正确去除文本中的常见中文标点符号。
-
-
-
- 测试数据:示例文本:"你好,世界!这是一个测试文本,包含多个标点符号:,。?!;:【】()《》‘’“”…—"
-
-
-
- 预期结果:"你好世界这是一个测试文本包含多个标点符号"
-
-
- 包含非中文标点符号的文本
-
-
- 目标:虽然函数主要处理中文标点符号,但验证其对非中文标点符号(如英文标点符号)的处理也是有益的,以确保它不会意外地去除这些字符。
-
-
- 空字符串或仅包含空格的文本
-
-
- 目标:验证函数对空字符串或仅包含空格的文本的处理。
-
-
-
- 测试数据:示例文本1:""(空字符串)示例文本2:" "(仅包含空格)
-
-
-
- 预期结果:对于两个示例文本,预期结果都应该是空字符串或仅包含空格的字符串,具体取决于函数是否应该去除空格。
-
-
- 包含特殊字符和Unicode字符的文本
-
-
- 目标:验证函数对包含特殊字符和Unicode字符(非标点符号)的文本的处理。
-
-
-
- 测试数据:示例文本:"这是一个包含特殊字符的文本:!@#$%^&*()_+{}:"<>? 和 Unicode 字符:こんにちは、世界!"
-
-
-
- 预期结果:"这是一个包含特殊字符的文本:!@#$%^&*()_+{}:"<>? 和 Unicode 字符:こんにちは世界"(注意:Unicode字符中的标点符号被去除)
-
-
- 边界情况
-
-
- 目标:验证函数在边界情况下的行为,如文本开头或结尾的标点符号。测试数据:
-
-
-
- 示例文本:",你好,世界!"(文本开头和结尾都是标点符号)
-
-
-
- 预期结果:"你好世界"
-
-
- 了解更详细的测试内容,还请读者前往项目文件查看测试代码
-
测试结果
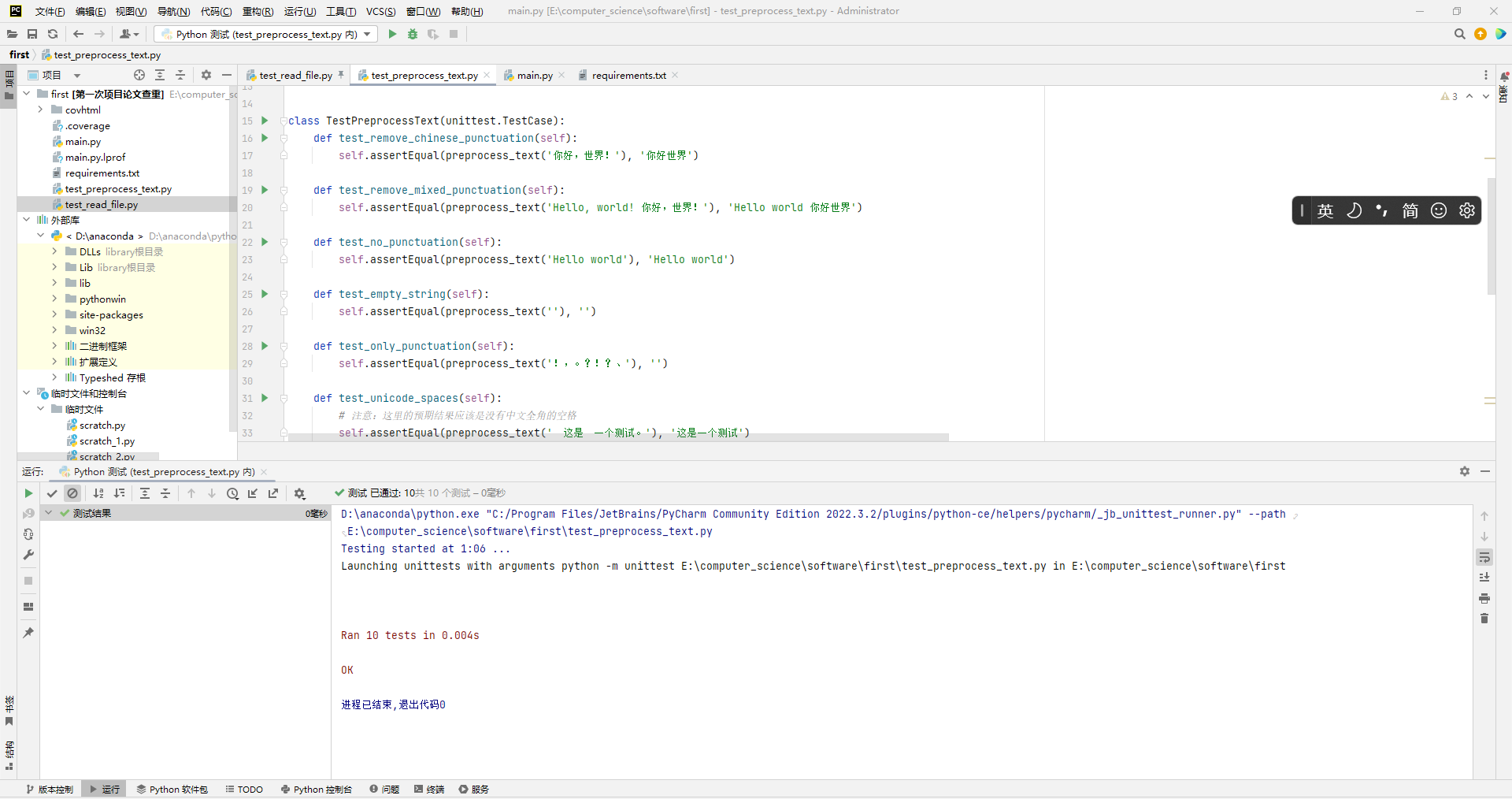
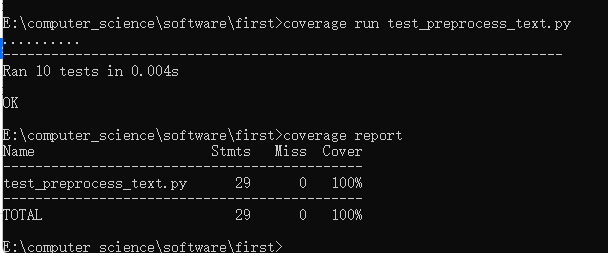
- 此处覆盖率100%
test_tokenize_and_count.py
- 需要测试的函数代码
def tokenize_and_count(content):
"""
对文本进行分词,并统计每个词的出现次数。
"""
words = list(jieba.cut(content)) # 使用jieba对文本进行分词
word_count = {} # 初始化一个空字典用于存储词频
for word in words: # 遍历分词后的每个词
if word in word_count: # 如果该词已在字典中
word_count[word] += 1 # 则其计数加1
else: # 如果该词不在字典中
word_count[word] = 1 # 则添加到字典中并设置计数为1
return word_count # 返回词频字典
-
构造测试数据的思路
-
- 空字符串
-
-
- 目的:验证函数在输入为空字符串时的行为,确保返回的是空字典。
-
-
-
- 测试数据:""
-
-
- 单个单词
-
-
- 目的:验证函数对单个单词的处理能力,确保单词被正确计数。
-
-
-
- 测试数据:"hello"
-
-
- 多个单词
-
-
- 目的:验证函数对多个单词的处理能力,包括单词之间的空格。
-
-
-
- 测试数据:"hello world"
-
-
- 重复单词
-
-
- 目的:验证函数对重复单词的计数能力。
-
-
-
- 测试数据:"hello hello"
-
-
- 混合字符
-
-
- 目的:验证函数对中英文混合文本的处理能力。
-
-
-
- 测试数据:"hello 你好"
-
-
- 标点符号
-
-
- 目的:验证函数对标点符号的处理能力,确保标点符号也被正确计数(如果这是预期的行为)。
-
-
-
- 测试数据:"hello, world!"
-
-
- 多个标点符号
-
-
- 目的:验证函数对连续或分散的多个标点符号的处理能力。
-
-
-
- 测试数据:"hello!! world??"
-
-
- 特殊字符
-
-
- 目的:验证函数对特殊字符(如@、#等)的处理能力,这些字符在默认情况下可能不会与单词合并。
-
-
-
- 测试数据:"@hello #world"
-
-
- 混合内容
-
-
- 目的:验证函数对包含中英文、标点符号、特殊字符的混合文本的处理能力。
-
-
-
- 测试数据:"hello 你好, 世界!"
-
-
- 长文本
-
-
- 目的:验证函数对较长文本的处理能力,确保在大量词汇和可能的标点符号存在时,函数仍然能够正确分词并统计词频。
-
-
-
- 测试数据:一段包含多个单词、标点符号和可能的特殊字符的长文本。
-
-
- 了解更详细的测试内容,还请读者前往项目文件查看测试代码
-
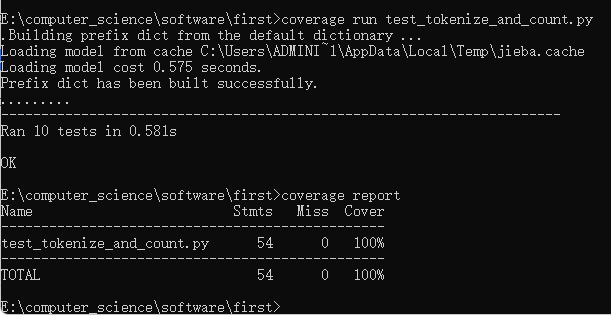
测试结果
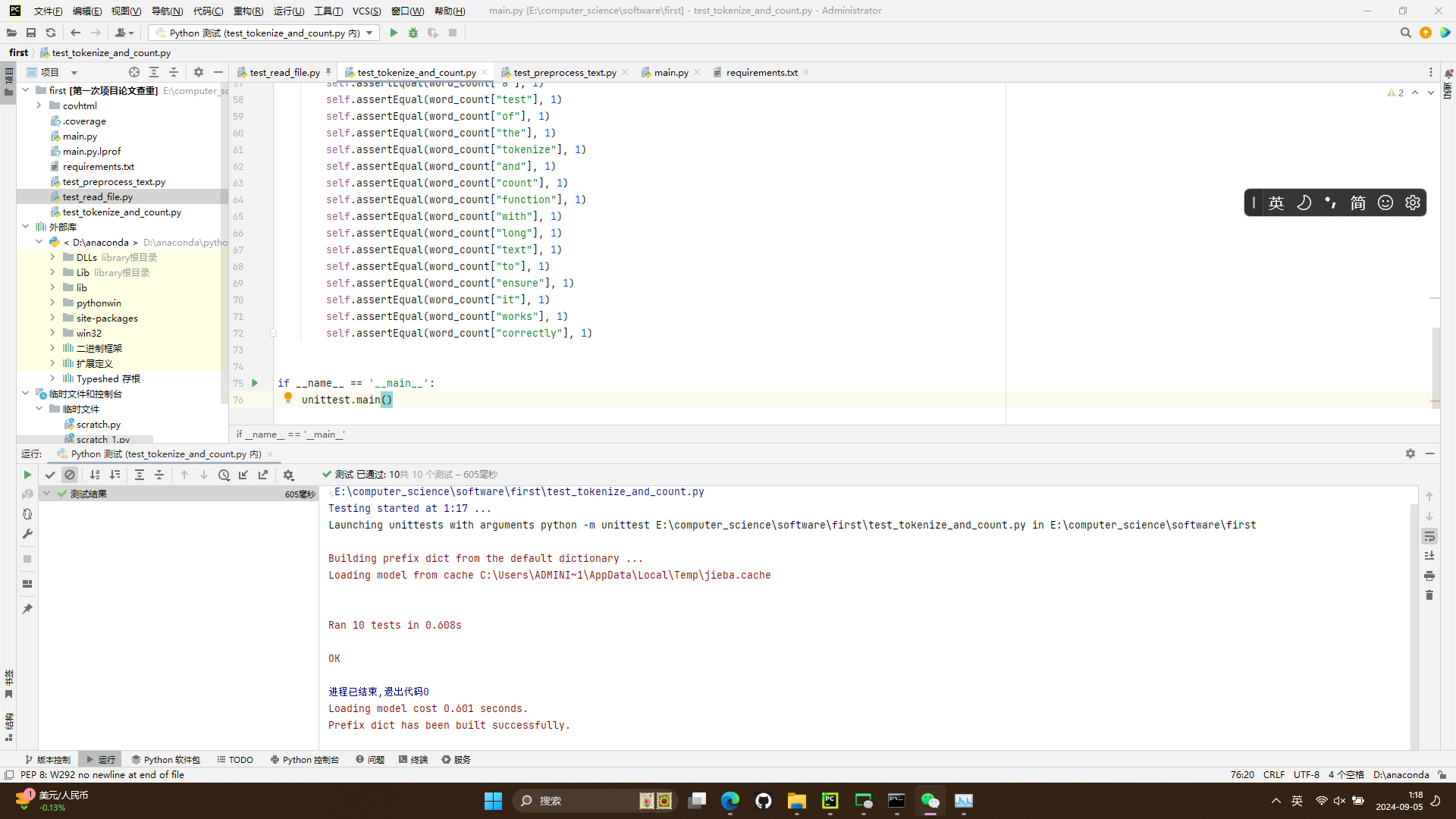
- 此处覆盖率100%
test_cosine_similarity.py
- 需要测试的函数代码
def cosine_similarity(vec1, vec2):
"""
计算两个向量(词频字典)之间的余弦相似度。
"""
inner_product = sum(vec1[key] * vec2.get(key, 0) for key in vec1) # 计算两个向量的内积
square_length_vec1 = sum(val ** 2 for val in vec1.values()) # 计算第一个向量的模的平方
square_length_vec2 = sum(val ** 2 for val in vec2.values()) # 计算第二个向量的模的平方
if square_length_vec1 == 0 or square_length_vec2 == 0: # 如果任一向量的模为0
return 0 # 则余弦相似度为0
return inner_product / (sqrt(square_length_vec1) * sqrt(square_length_vec2)) # 计算并返回余弦相似度
-
构造测试数据的思路
-
- 相同向量
-
-
- 目的:验证当两个向量完全相同时,余弦相似度是否为1。
-
-
-
- 测试数据:vec1 = {'a': 1, 'b': 2}; vec2 =
-
-
- 不同向量但相似
-
-
- 目的:验证当两个向量不同但相似(即方向相同但模不同)时,余弦相似度是否接近1但小于1。
-
-
-
- 测试数据:vec1 = {'a': 1, 'b': 2}; vec2 =
-
-
- 垂直向量
-
-
- 目的:验证当两个向量垂直(即内积为0)时,余弦相似度是否为0。
-
-
-
- 测试数据:vec1 = {'a': 1, 'b': 0}; vec2 =
-
-
- 相反向量
-
-
- 目的:验证当两个向量完全相反时,余弦相似度是否为-1。
-
-
-
- 测试数据:vec1 = {'a': 1, 'b': 2}; vec2 =
-
-
- 零向量
-
-
- 目的:验证当任一向量为零向量(即所有元素都为0)时,余弦相似度的处理是否正确(通常定义为0,但需要注意除以0的情况)。
-
-
-
- 测试数据:vec1 = {'a': 0, 'b': 0}; vec2 = {'a': 1, 'b': 2} vec1 = {'a': 0, 'b': 0}; vec2 =
-
-
- 稀疏向量
-
-
- 目的:验证当向量包含大量零元素(即稀疏)时,函数是否能正确处理。
-
-
-
- 测试数据:vec1 = {'a': 1, 'b': 0, 'c': 0, 'd': 2}; vec2 =
-
-
- 边界情况
-
-
- 目的:验证函数在处理边界情况(如非常小的浮点数、大整数等)时的稳定性。
-
-
-
- 测试数据:vec1 = {'a': 1e-10, 'b': 2}; vec2 =
-
-
- 复杂向量
-
-
- 目的:验证函数在处理包含多种类型元素(如正数、负数、零、小数)的复杂向量时的能力。
-
-
-
- 测试数据:vec1 = {'a': 1.5, 'b': -2, 'c': 0, 'd': 3.14}; vec2 =
-
-
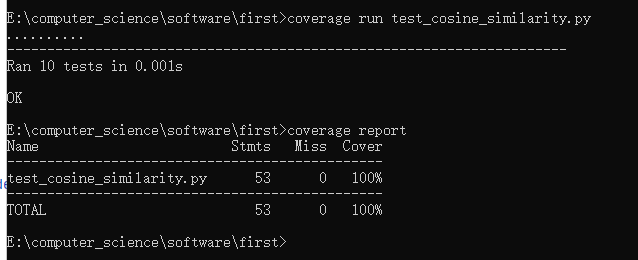
测试结果
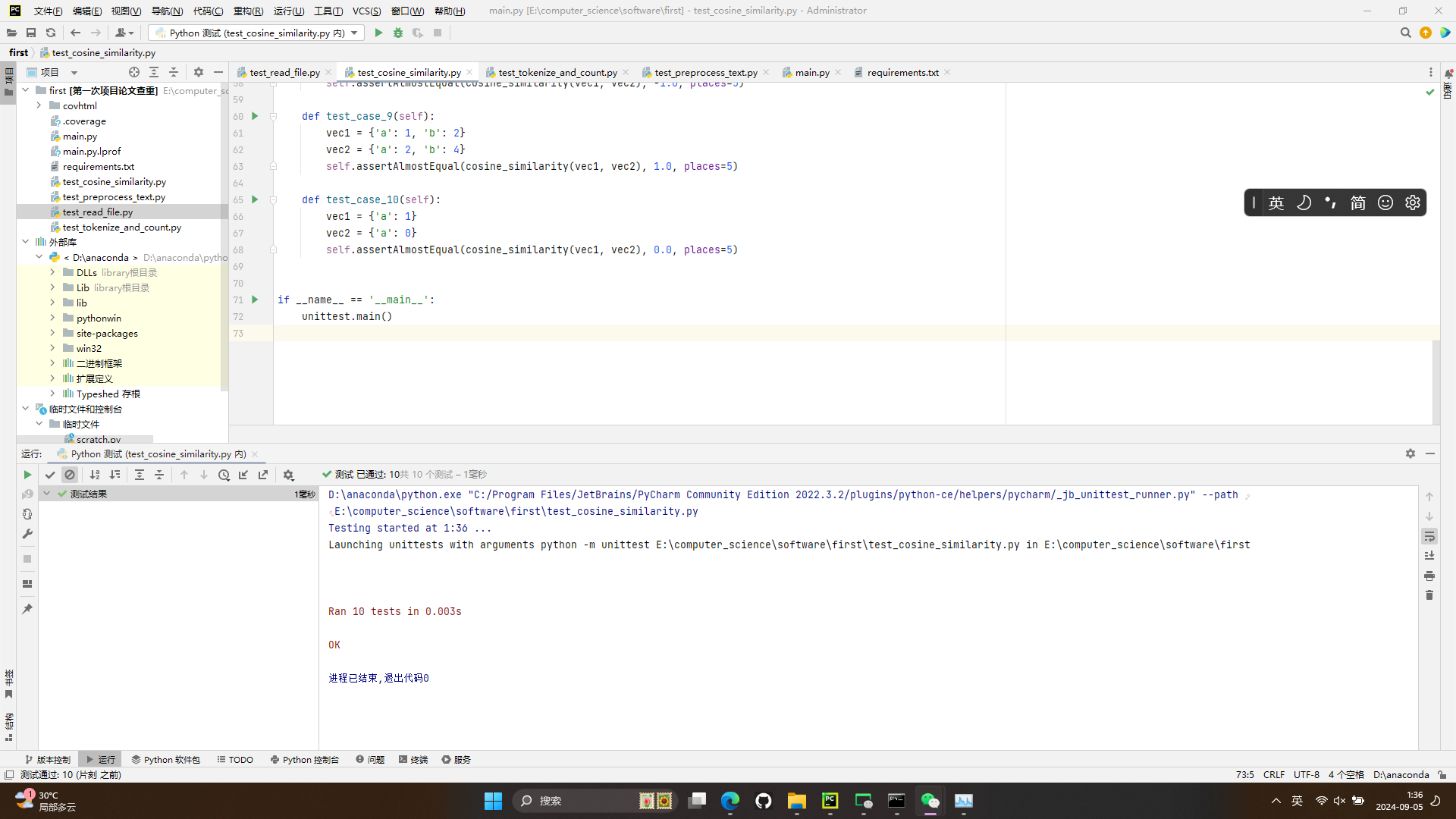
- 此处覆盖率100%
六、异常以及优化处理
- 在read_file函数中设计了FileNotFoundError异常来处理文件不存在的情况。
-
- 异常处理设计目标:当尝试读取的文件不存在时,抛出此异常,这是为了让用户清楚地知道哪个文件缺失,并能够在出现问题时迅速定位并解决问题。
- 原函数代码
def read_file(file_path):
"""
读取文件内容。如果文件不存在,则抛出 FileNotFoundError 异常。
"""
if not os.path.exists(file_path): # 检查文件是否存在
raise FileNotFoundError(f"File {file_path} does not exist. Please check!") # 文件不存在时抛出异常
with open(file_path, 'r', encoding='utf-8') as file: # 以只读和utf-8编码打开文件
return file.read() # 读取文件内容并返回
- 单元测试样例
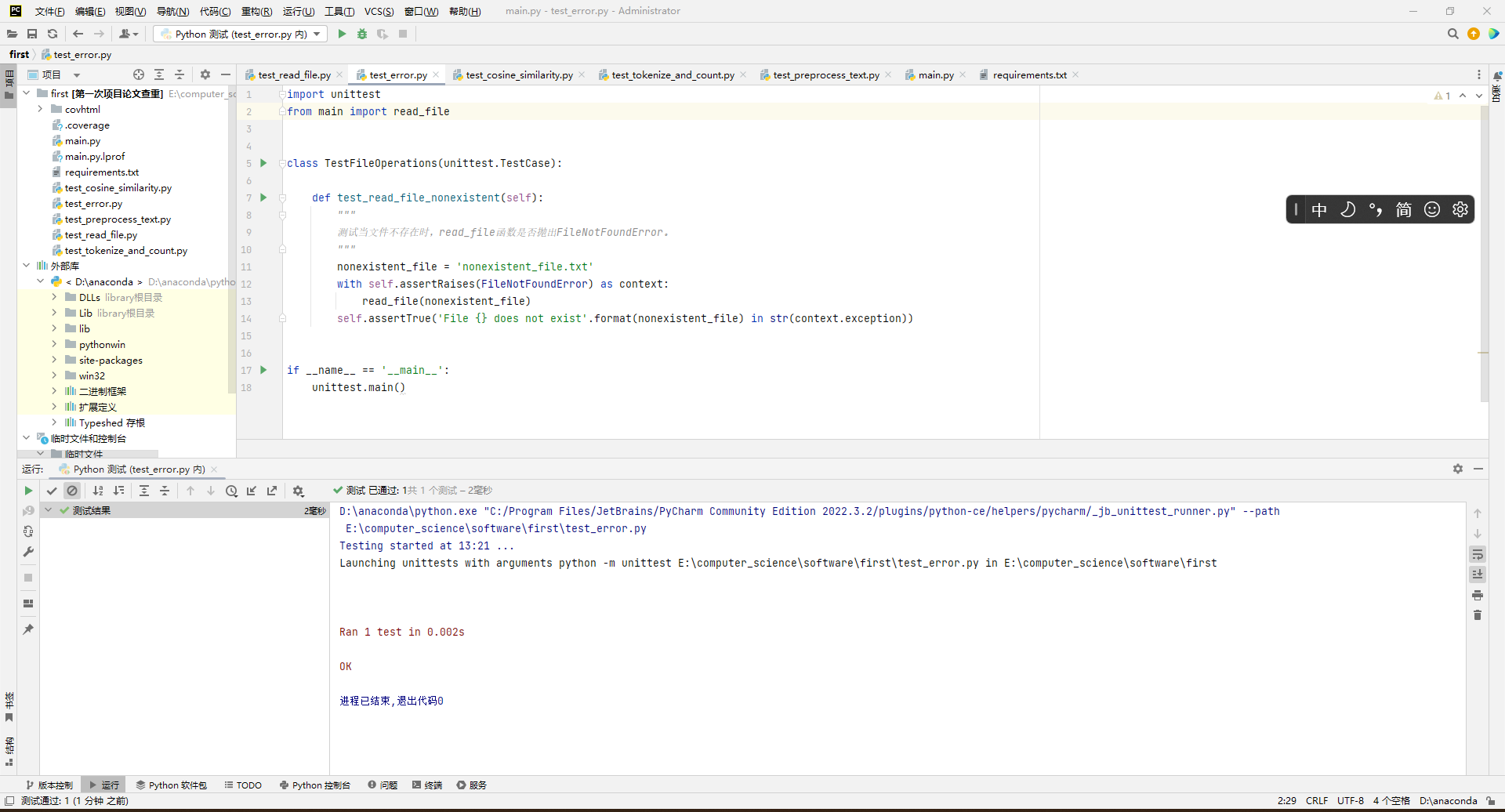
-
- 此处测试文件test_error.py覆盖率为100%
- 错误对应的场景
-
- 文件路径错误:用户可能在命令行中指定了错误的文件路径,导致文件不存在。
-
- 文件未正确放置在指定位置:程序期望在某个目录下找到文件,但文件实际并未被放置在那里。
-
- 文件权限问题:虽然文件存在,但当前用户没有足够的权限去读取它。然而,在这种情况下,程序可能会抛出PermissionError而不是FileNotFoundError,这取决于操作系统的行为。但在大多数情况下,权限问题不直接对应到文件不存在的问题,所以在这里我们主要关注FileNotFoundError。
七、实测结果
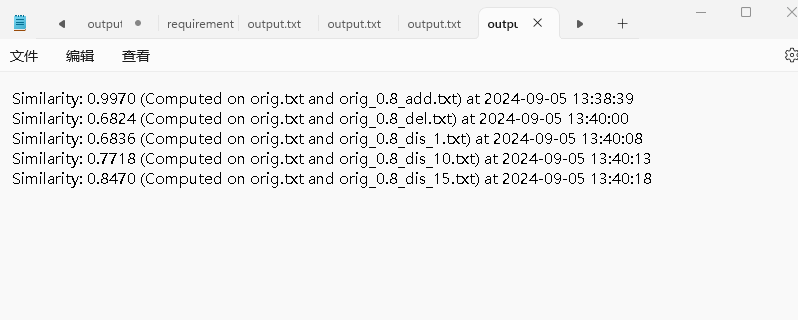
- 从上到下:orig.txt分别与orig_0.8_add.txt、orig_0.8_del.txt、orig_0.8_dis_1.txt、orig_0.8_dis_10.txt、orig_0.8_dis_15.txt进行比较,得到的重复率结果输出到output.txt文件
八、附录
运行代码的步骤
- (此处还请读者根据自己项目文件的存放地址对命令进行修改)
- Win + R 打开运行 > 输入cmd 回车
-
在命令行窗口输入cd /d E:\computer_science\software\first\
-
- 输入前
-
- 输入后
- 在命令行窗依次输入
-
- python main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_add.txt" "E:\computer_science\software\output.txt"
-
- python main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_del.txt" "E:\computer_science\software\output.txt"
-
- python main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_dis_1.txt" "E:\computer_science\software\output.txt"
-
- python main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_dis_10.txt" "E:\computer_science\software\output.txt"
-
- python main.py "E:\computer_science\software\orig.txt" "E:\computer_science\software\orig_0.8_dis_15.txt" "E:\computer_science\software\output.txt"
-
- 按照上述要求进行就可以正常运行程序,我们就能在output.txt文件查看输出结果
测试代码的步骤
-
Win + R 打开运行 > 输入cmd 回车
-
在命令行窗口输入cd /d E:\computer_science\software\first\
-
为了减少篇幅,此处我只对test_read_file.py文件进行测试。
-
在命令行窗口输入coverage run test_read_file.py,此处输入前,请确保窗口已经进入存放测试代码的文件地址
-
然后输入coverage report
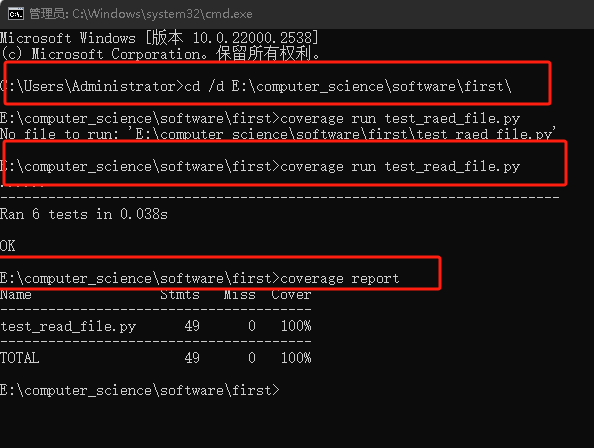
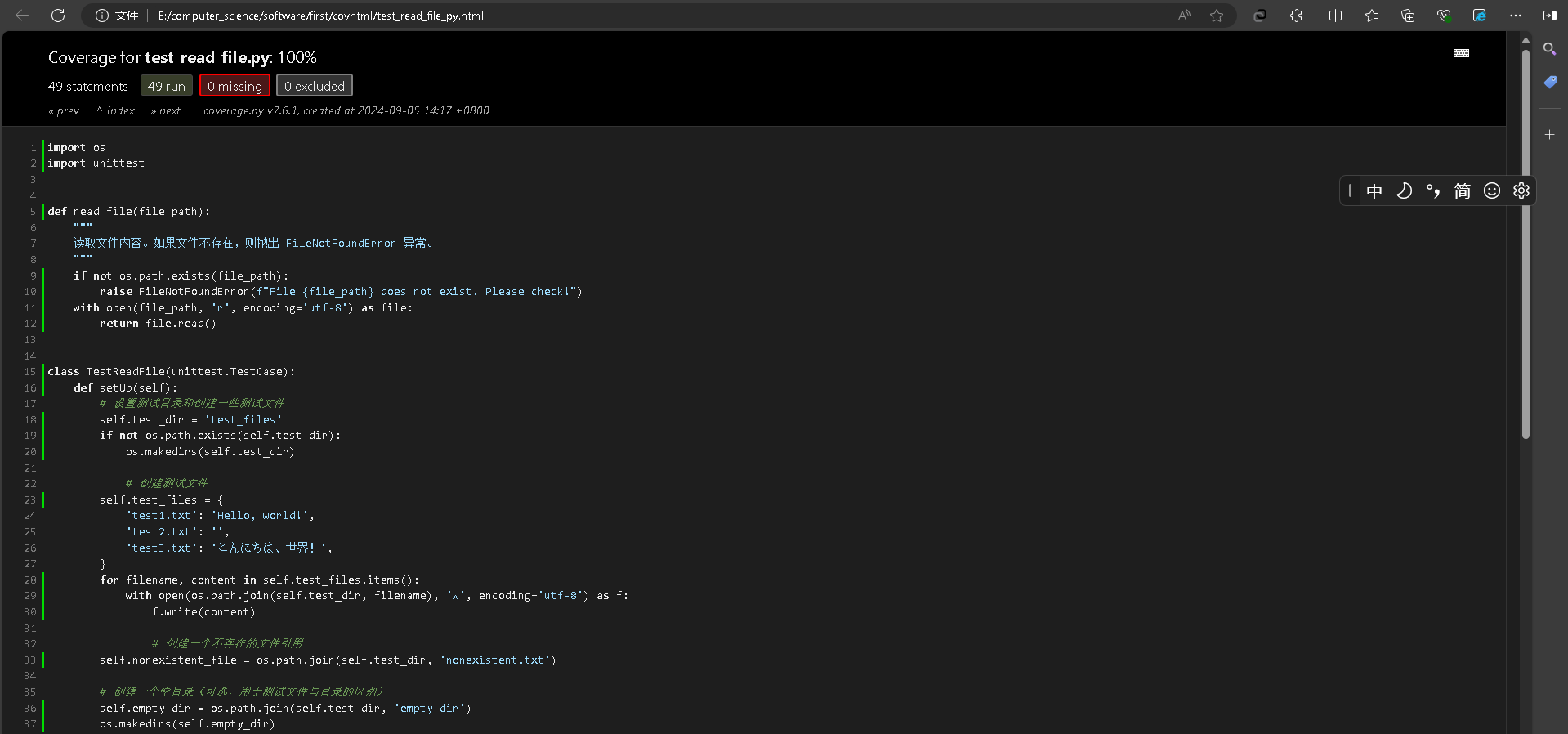
- 我们也可以输入coverage html -d covhtml来生成HTML报告


 浙公网安备 33010602011771号
浙公网安备 33010602011771号