
用 eBPF/bcc 分析系统性能的一个简单案例
bcc是eBPF的一种前端,当然这个前端特别地简单好用。可以直接在python里面嵌入通过C语言写的BPF程序,并帮忙产生BPF bytecode和load进入kernel挂载kprobe、tracepoints等上面执行。之后,还可以从python取出来C函数里面导出的maps数据以及per-event数据并进行打印。
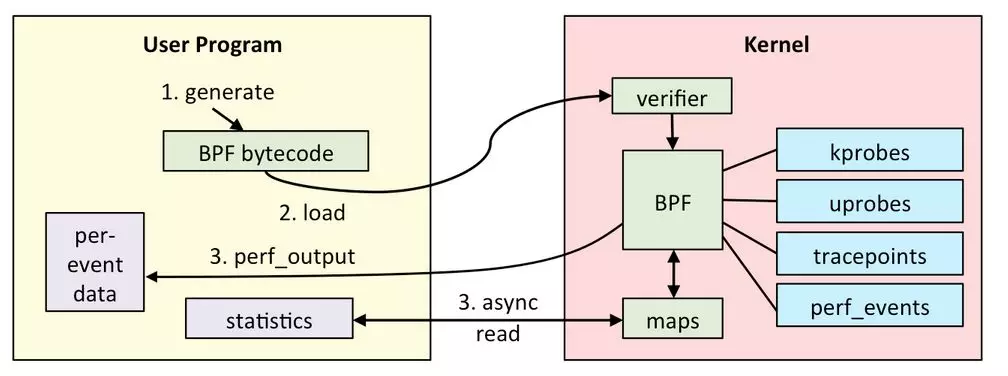
我们特别看一下其中的bitehist.py例子:

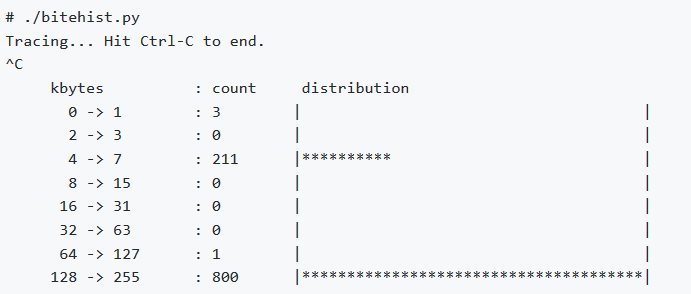
上述程序通过kprobe截获了内核的blk_account_io_completion()函数,并将每个request的data_len转换为单位KBytes后,进行取对数,加入一个HISTOGRAM(属于maps中的一种),之后python会调用
b[“dist”].print_log2_hist(“kbytes”)
打印出这个hist图,从而可以给用户呈现出request磁盘请求的size分布情况:
另外一个经典的例子是通过kprobe截获函数的入口和返回点,得到函数的调用延迟:

上面的这个BPF C程序把在函数进入(kprobe)的时候,把当前时间加入一个start HASH(key是进程的pid,value是函数的开始时间),在函数出口的地方(kretprobe)通过start.loopup(&pid)取得函数入口时间,然后在函数出口的时候,把出口时间减去入口时间的结果求对数后放入一个HISTOGRAM。之后python可以获取这个HIST并打印:

这样可以呈现出延迟的热点分布。
anyway,了解了BPF c和python的语法后,这样的程序并不难写。但是,很多时候,其实我们并没有必要自己写代码,因为牛人们已经给我们写了很多现成的工具了。
比如,分析bio的延迟:
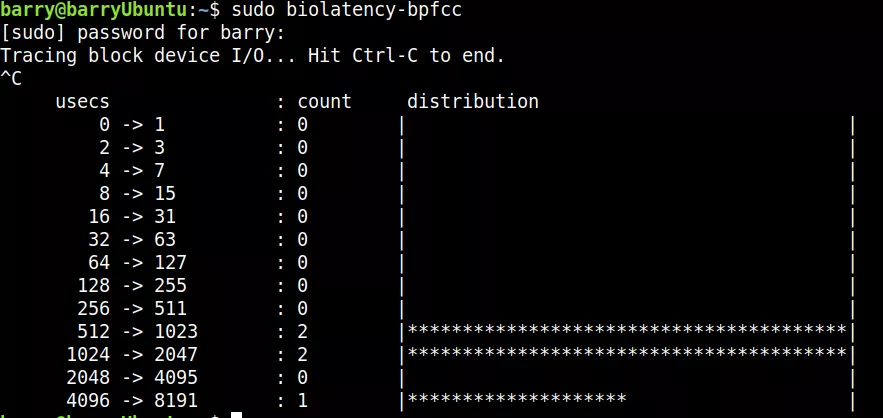
大量的延迟集中在512-1023和1024-2047之间。另外4096-8191也是这个multimodal延迟的另外一个热点。
这个东西就要比iostat命令更加细致靠谱一些,因为iostat命令只是简单地显示平均延迟啥的,并不显示延迟的分布情况,比如man iostat可以获知:
await - The average time (in milliseconds) for I/O requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them.
但是,很多时候延迟呈现为一个multimodal的特点,会有多个峰值区域:
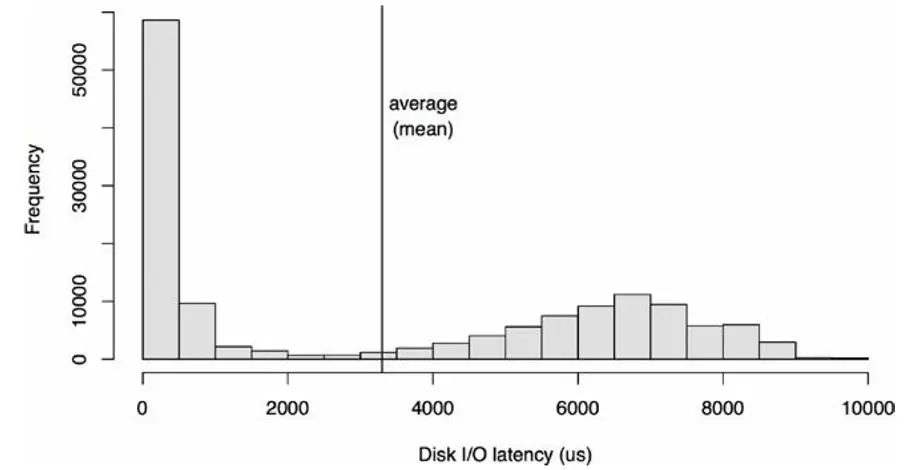
平均值,看起来,有时候没有那么accurate。比如一个班上的学生,平均分70分,但是无法呈现这个班的童鞋的如下特点:
-
有一堆差生都是30分左右
-
有一堆中等生都是60分左右
-
有一堆优等生都是90分左右
如果是HIST图的话,它的分布会类似:

看起来更加精确一些。
下面我们尝试用funclatency这个现成的工具来分析代码里面的usleep(100)究竟真正延迟多少,写一个最简单的应用程序,编译为a.out:
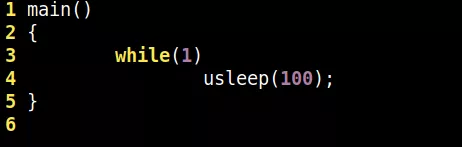
运行后,我们来得到usleep(100)调用内核do_nanosleep的真实延迟:
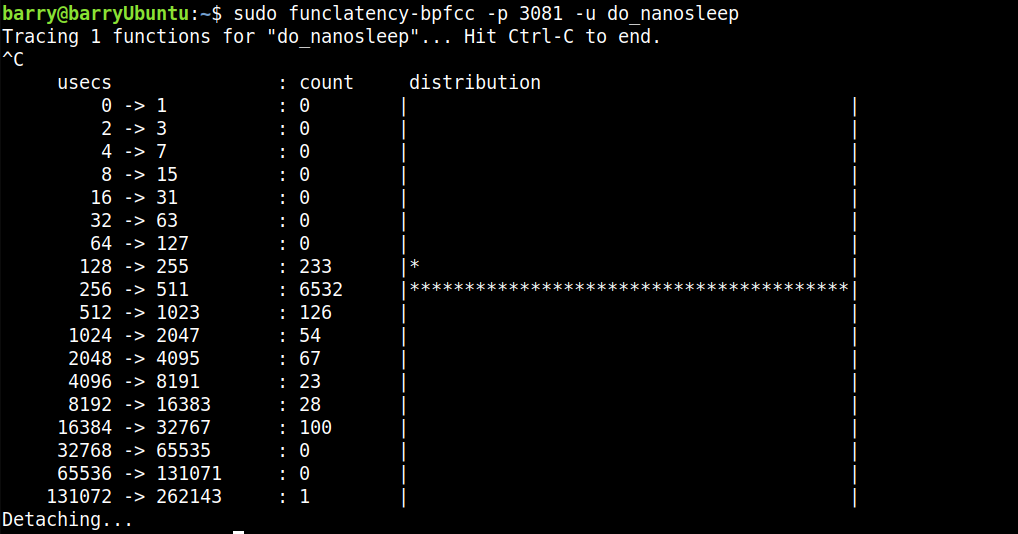
其实usleep(100)大面积集中在256-511us。所以,这个usleep(100)究竟有多准,天知道。
看完三件事❤️
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
-
点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
-
关注公众号 『 java烂猪皮 』,不定期分享原创知识。
-
同时可以期待后续文章ing🚀

本文来自:Linux阅码场,作者:宋宝华

