
踩了一个 java 命令行参数顺序的坑
tream
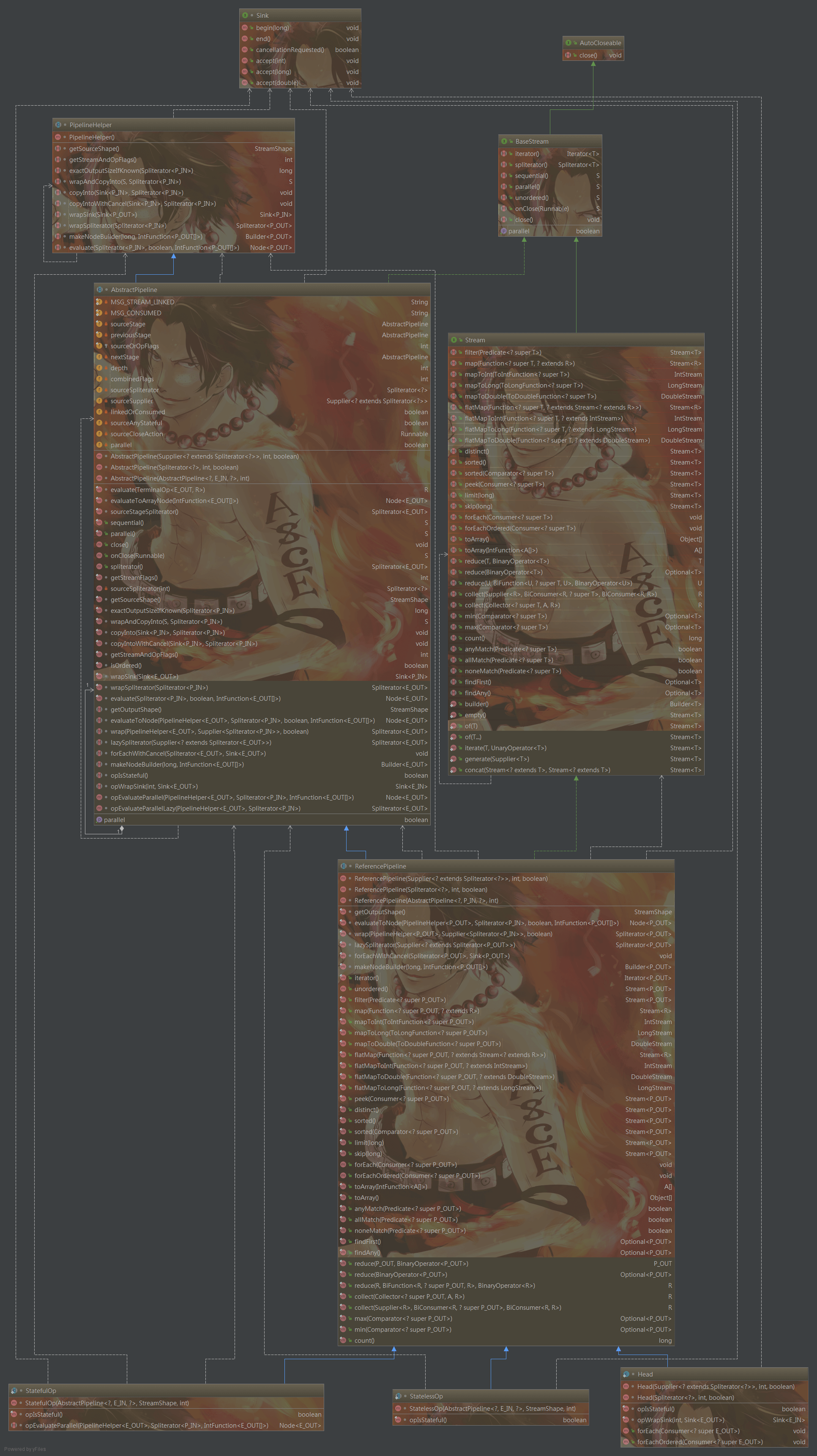
Stream是在Java SE 8 API添加的用于增强集合的操作接口,可以让你以一种声明的方式处理集合数据。将要处理的集合看作一种流的创建者,将集合内部的元素转换为流并且在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选,排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。Stream的继承关系图如下,且容我慢慢抽丝剥茧细细道来。
过滤,转换,聚合,归约
在没有Stream之前,我们对集合数据的处理到多是外部遍历,然后做数据的聚合用算,排序,merge等等。这属于OO思想,在引入Java SE 8引入FP之后,FP的操作可以提高Java程序员的生产力,,基于类型推断的lambda表达式可以 让程序员写出高效率、干净、简洁的代码。可以避免冗余的代码。根据给定的集合操作通过stream()方法创建初始流,配合map(),flatMap(),filter()对集合数据进行过滤,转换。api调用我这里就不多说了。直接从源码入手,看上图最核心的就是类为AbstractPipeline,ReferencePipeline和Sink接口.AbstractPipeline抽象类是整个Stream中流水线的高度抽象了源头sourceStage,上游previousStage,下游nextStage,定义evaluate结束方法,而ReferencePipeline则是抽象了过滤,转换,聚合,归约等功能,每一个功能的添加实际上可以理解为卷心菜,菜心就是源头,每一次加入一个功能就相当于重新长出一片叶子包住了菜心,最后一个功能集成完毕之后整颗卷心菜就长大了。而Sink接口呢负责把整个流水线串起来,然后在执行聚合,归约时候调AbstractPipeline抽象类的evaluate结束方法,根据是否是并行执行,调用不同的结束逻辑,如果不是并行方法则执行terminalOp.evaluateSequential否则就执行terminalOp.evaluateParallel,非并行执行模式下则是执行的是AbstractPipeline抽象类的wrapAndCopyInto方法去调用copyInto,调用前会先执行一下wrapSink,用于剥开这个我们在流水线上产生的卷心菜。从下游向上游去遍历AbstractPipeline,然后包装到Sink,然后在copyInto方法内部迭代执行对应的方法。最后完成调用,
并行执行实际上是构建一个ForkJoinTask并执行invoke去提交到ForkJoinPool线程池。
BaseStream
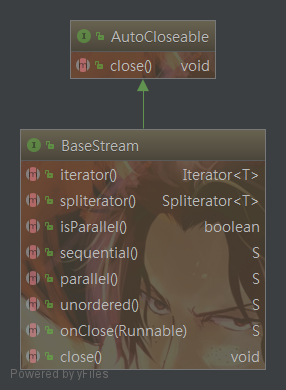
流的基本接口,该接口制定流可以支持无序,顺序,并行的,Stream实现了BaseStream接口。
-
Iterator<T> iterator();外部迭代器
-
Spliterator<T> spliterator();用于创建一个内部迭代器
-
isParallel用于判断该stream是否是并行的
-
S sequential();标识该stream创建是顺序执行的
-
S parallel();标识该stream创建是并行的,需要使用
ForkJoinPool -
S unordered();标识该stream创建是无序的
-
S onClose(Runnable closeHandler);当stream关闭的时候执行一个方法回调去关闭流。
PipelineHelper
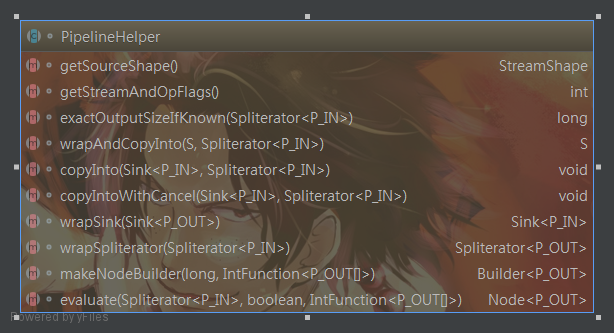
该抽象类主要定义了操作管道的核心方法,并且能收集到流管道内的所有信息。如通过
TerminalOp#evaluateParallel用于执行并行流操作,通过TerminalOp#evaluateSequential执行顺序流的操作。
-
abstract StreamShape getSourceShape();
-
abstract int getStreamAndOpFlags();
-
abstract<P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
将此时间的管道内的元素应用到提供的
Spliterator,并将结果发送到提供的接收器sink里
-
abstract<P_IN, S extends Sink<P_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator);
用于输出返回值的大小。
-
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
用于将从
Spliterator获得的元素推入提供的接收器中Sink。如果已知流管道中有短路阶段(包含StreamOpflag#SHORT_CURRENT),则在每个元素之后执行一下Sink#cancellationRequested(),如果返回请求true,则执行终止。这个方法被实现之后需要遵守Sink的协议即:Sink#begin->Sink#accept->Sink->end
-
abstract <P_IN> void copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
用于将从
Spliterator获得的元素推入提供的接收器中Sink。在每个元素之后执行一下Sink#cancellationRequested(),如果返回请求true,则执行终止。这个方法被实现之后需要遵守Sink的协议即:Sink#begin->Sink#accept->Sink->end
-
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
该方法主要用于包装sink,从下游向上游去遍历
AbstractPipeline,然后包装到一个Sink内,用于然后在copyInto方法内部迭代执行对应的方法。
-
abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown,IntFunction<P_OUT[]> generator);
用于构造一个节点Builder,转换为数组去处理数组类型和PipelineHelper定义的输出类型一样。
-
abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator,boolean flatten,IntFunction<P_OUT[]> generator);
该方法将源拆分器应用到管道内的所有元素。针对数组处理。如果管道没有中间(
filter,map)操作,并且源由一个节点支持(源头),则该节点将被返回(内部遍历然后返回)。这减少了由有状态操作和返回数组的终端操作组成的管道的复制.例如:stream.sorted().toArray();该方法对应到AbstractPipeline内部,代码如下:
AbstractPipeline
“管道”类的抽象基类,是流接口及其原始专门化的核心实现。用来表示流管道的初始部分,封装流源和零个或多个中间操作。对于顺序流和没有状态中间操作的并行流、并行流,管道中数据的处理是在一次“阻塞”所有操作的过程中完成的也就是最后才去处理。对于具有状态操作的并行流,执行被分成多个段,其中每个状态操作标记一个段的结束,每个段被单独评估,结果被用作下一个段的输入。上述所有情况,都是达到终端操作才开始处理源数据。
AbstractPipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel)
创建源Source stage 第一个参数指定一个Supplier接口(工厂模式,只能生成Spliterator<?>的对象,根据传入的lambda实现,
<? extends Spliterator<?泛型的PECS原则了解一下。)
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel)
创建源Source stage 第一个参数制定这个拆分器,和上面的构造方式一样,直接分析一下这个方法:
创建Stream 源阶段的时候
previousStage为null,this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;用于设置当前阶段的标识位。this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;添加源阶段的对流的操作标识,这个combinedFlags是流在整个管道内部所有操作的合集,在最后的规约操作的时候去解析出来。
-
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags)
根据上游创建下游
Pipeline。
this.sourceStage = previousStage.sourceStage;,用于上游和下游关联,this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);将上游的操作标识位添加到本阶段的操作标识位中。depth记录整个管道的中间操作数。
-
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp)
进行终端汇聚计算。执行最终的计算,得到结果,根据是否是并行执行,调用不同的结束逻辑,如果不是并行方法则执行
terminalOp.evaluateSequential否则就执行terminalOp.evaluateParallel。
-
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator)
处理流转换数组。
转换数组的时候,如果是并行流并且不是源阶段,而且调用过
sorted||limit||skip||distinct这些有状态的操作之后,这里是个模版方法调用。实际上是通过调用DistinctOps||SortedOps||SliceOps这些实现的opEvaluateParallel方法,提交到ForkJoin线程池来转换数组。串行执行的时候直接执行evaluate(sourceSpliterator(0), true, generator);
-
evaluate(sourceSpliterator(0), true, generator);
具体的执行方法,用于吧管道内部的输出结果放到Node中。
如果是源是并行流的情况,以ReferencePipeline引用管道来看主要执行的是 return Nodes.collect(helper, spliterator, flattenTree, generator);,该collect方法内部根据切割器有无Spliterator.SUBSIZED确定了生成的Node的长度,主要工作是创建一个Task提交到线程池。然后调用invoke拿到结果。示例代码Arrays.asList("2","22","222").parallelStream().skip(2).toArray(); 整个流程如下:
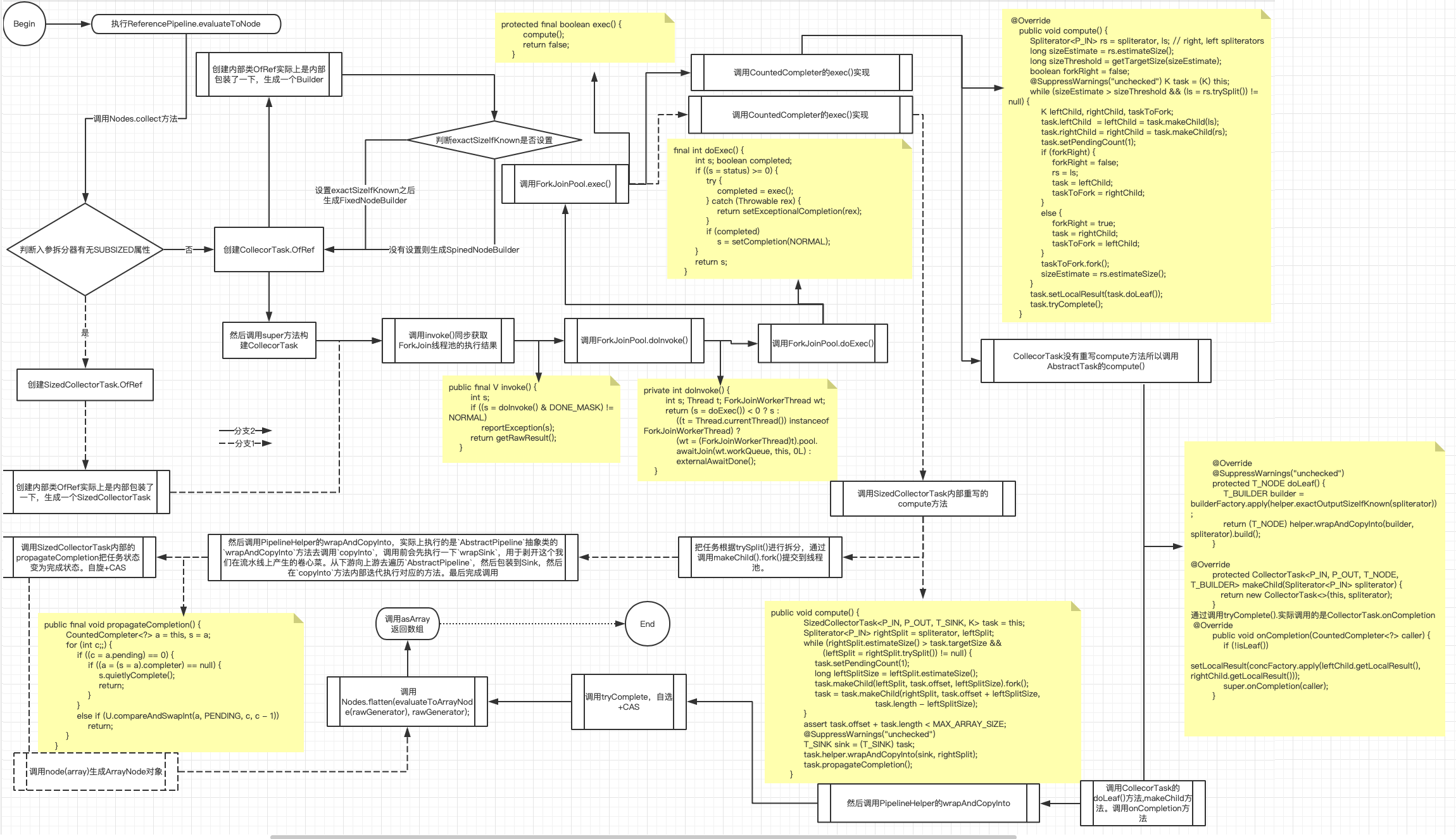
串行执行示例代码Arrays.asList("2","22","222").stream().skip(2).toArray(); 整个流程如下:
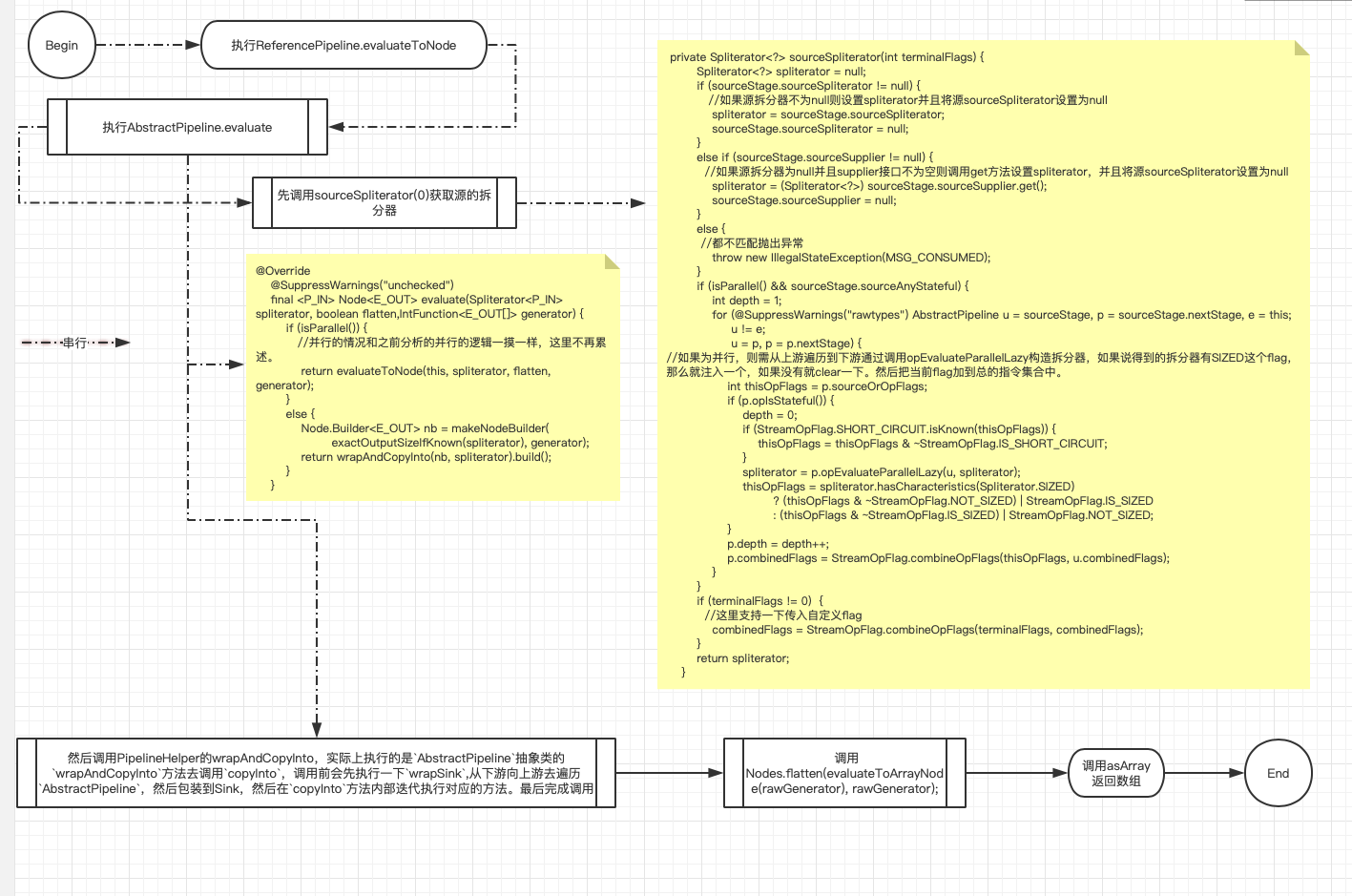
-
final Spliterator<E_OUT> sourceStageSpliterator()
获取Stream源头设置的拆分器,如果设置有则返回并且把源拆分器置空,如果有Supplier则调用get方法返回拆分器并且把源拆分器置空。
-
public final S sequential()
设置为串行流 ,设置源的paraller属性为false。终态方法不允许重写
-
public final S sequential()
设置为并行流 ,设置源的paraller属性为true。终态方法不允许重写
-
public void close()
关闭管道的方法,在关闭的时候会把管道使用标志设置为false,拆分器设置为null,如果源的回调关闭Job存在不为null时则invoker这个回调Job。
-
public S onClose(Runnable closeHandler)
用于注册关闭的回调job,在调用close的时候用于去执行这个回调job。
-
public Spliterator<E_OUT> spliterator()
和
sourceStageSpliterator方法一样的功能,只不过不是终态方法,可以重写用于自定义的拓展。
-
public final boolean isParallel()
用于盘带你当前管道是否是并行流。
-
final int getStreamFlags()
获取流的标志和Stream的包含的所有操作。
-
private Spliterator<?> sourceSpliterator(int terminalFlags) {
获取源拆分器,和
sourceStageSpliterator方法一样的功能,针对是并行流时候,并且是创建Stream阶段的话有中间状态,会组合流标志和操作构建拆分器。如果传入的操作码不等于0,那么则添加到拆分器的操作码中。
-
final StreamShape getSourceShape()
输出Stream源的类型。(引用 OR int OR Double OR Long)
-
final <P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator)
获取期望的size,如果拆分器如果有SIZE标志,调用拆分器的getExactSizeIfKnown方法,否则返回-1。
-
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator)
封装整个管道的阶段,包装在Sink中。把每一个阶段串联起来。包装在Sink内部的
downstream.
wrapAndCopyInto代码执行流程如下:
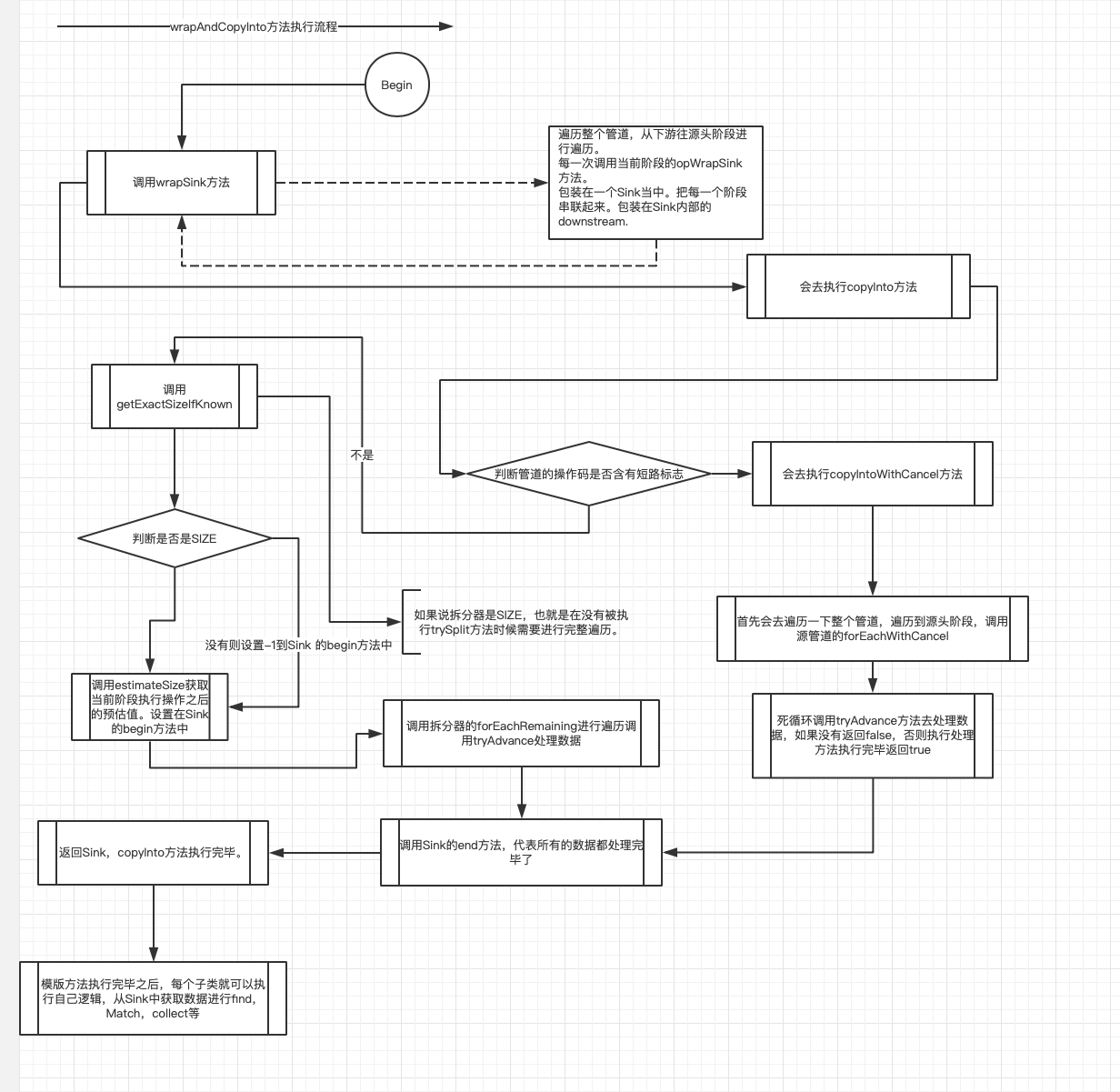
看完三件事❤️
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
-
点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
-
关注公众号 『 java烂猪皮 』,不定期分享原创知识。
-
同时可以期待后续文章ing🚀


