
ConcurrentHashMap 核心原理,彻底给整明白了
ConcurrentHashMap,它在技术面试中出现的频率相当之高,所以我们必须对它深入理解和掌握。
谈到 ConcurrentHashMap,就一定会想到 HashMap。HashMap 在我们的代码中使用频率更高,不需要考虑线程安全的地方,我们一般都会使用 HashMap。HashMap 的实现非常经典,如果你读过 HashMap 的源代码,那么对 ConcurrentHashMap 源代码的理解会相对轻松,因为两者采用的数据结构是类似的
这篇文章主要讲解ConcurrentHashMap的核心原理,并注释详细源码,文章篇幅较长,可收藏再看
基本结构
ConcurrentHashMap 是一个存储 key/value 对的容器,并且是线程安全的。我们先看 ConcurrentHashMap 的存储结构,如下图:
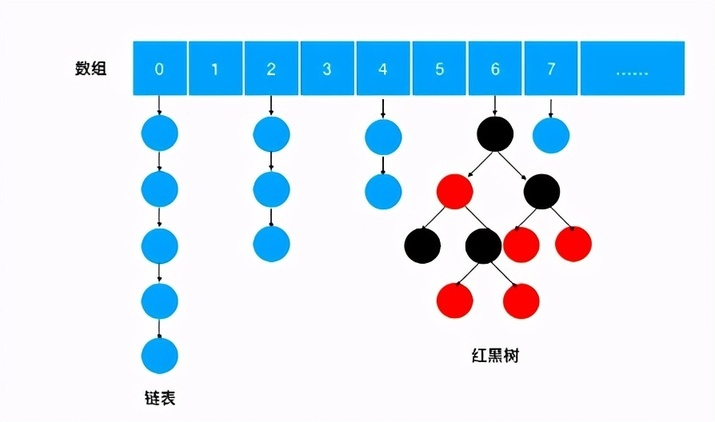
虽然 ConcurrentHashMap 的底层数据结构,和方法的实现细节和 HashMap 大体一致,但两者在类结构上却没有任何关联,我们看下 ConcurrentHashMap 的类图:
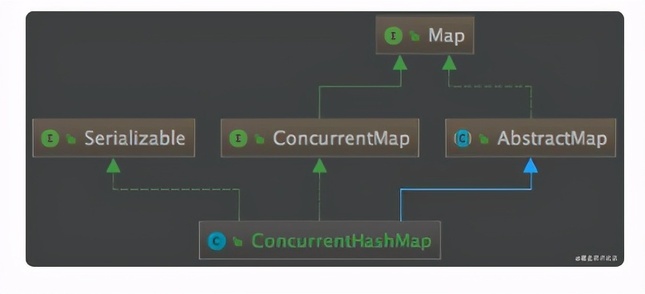
看 ConcurrentHashMap 源码,我们会发现很多方法和代码和 HashMap 很相似,有的同学可能会问,为什么不继承 HashMap 呢?
继承的确是个好办法,但ConcurrentHashMap 都是在方法中间进行一些加锁操作,也就是说加锁把方法切割了,继承就很难解决这个问题。
ConcurrentHashMap和HashMap两者的相同之处:
数组、链表结构几乎相同,所以底层对数据结构的操作思路是相同的(只是思路相同,底层实现不同);
都实现了 Map 接口,继承了 AbstractMap 抽象类,所以大多数的方法也都是相同的,HashMap 有的方法,ConcurrentHashMap 几乎都有,所以当我们需要从 HashMap 切换到 ConcurrentHashMap 时,无需关心两者之间的兼容问题。
不同之处:
红黑树结构略有不同,HashMap 的红黑树中的节点叫做 TreeNode,TreeNode 不仅仅有属性,还维护着红黑树的结构,比如说查找,新增等等;ConcurrentHashMap 中红黑树被拆分成两块,TreeNode 仅仅维护的属性和查找功能,新增了 TreeBin,来维护红黑树结构,并负责根节点的加锁和解锁;
新增 ForwardingNode (转移)节点,扩容的时候会使用到,通过使用该节点,来保证扩容时的线程安全。
这些概念名词文章后面都会依次介绍
基本构成
重要属性
我们来看看 ConcurrentHashMap 的几个重要属性
重要组成元素
Node
“
链表中的元素为Node对象。他是链表上的一个节点,内部存储了key、value值,以及他的下一个节点的引用。这样一系列的Node就串成一串,组成一个链表。
”
ForwardingNode
“
当进行扩容时,要把链表迁移到新的哈希表,在做这个操作时,会在把数组中的头节点替换为ForwardingNode对象。ForwardingNode中不保存key和value,只保存了扩容后哈希表(nextTable)的引用。此时查找相应node时,需要去nextTable中查找。
”
TreeBin
“
当链表转为红黑树后,数组中保存的引用为 TreeBin,TreeBin 内部不保存 key/value,他保存了 TreeNode的list以及红黑树 root。
”
TreeNode
“
红黑树的节点。
”
下面依次讲解各个核心方法,有详细注释
Put方法
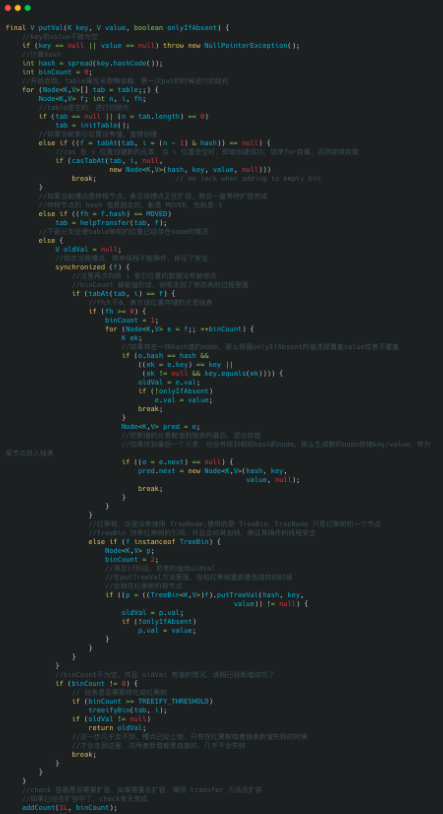
ConcurrentHashMap 在 put 方法上的整体思路和 HashMap 相同,但在线程安全方面写了很多保障的代码,我们先来看下大体思路:
1.如果数组为空,初始化,初始化完成之后,走 2;
2.计算当前槽点有没有值,没有值的话,cas 创建,失败继续自旋(for 死循环),直到成功,槽点有值的话,走 3;
3.如果槽点是转移节点(正在扩容),就会一直自旋等待扩容完成之后再新增,不是转移节点走 4;
4.槽点有值的,先锁定当前槽点,保证其余线程不能操作,如果是链表,新增值到链表的尾部,如果是红黑树,使用红黑树新增的方法新增;
5.新增完成之后 check 需不需要扩容,需要的话去扩容。
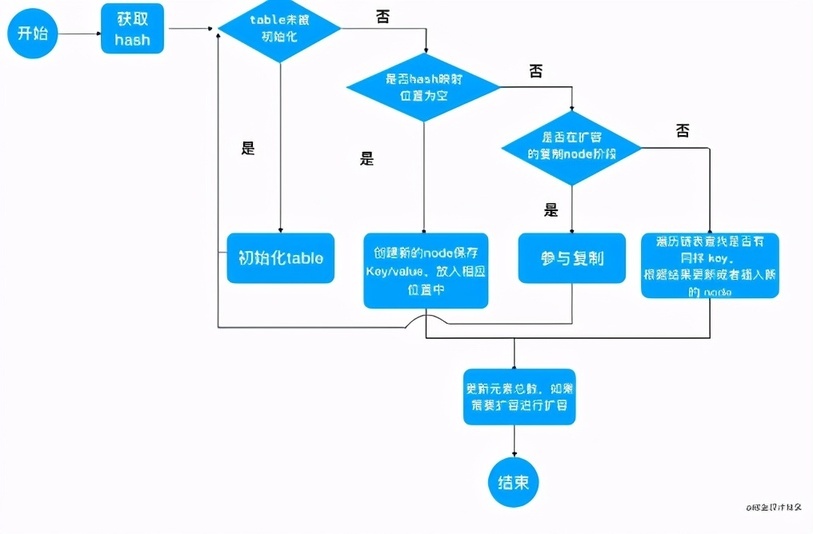
ConcurrentHashMap在put过程中,采用了哪些手段来保证线程安全呢?
数组初始化时的线程安全
数组初始化时,首先通过自旋来保证一定可以初始化成功,然后通过 CAS 设置 SIZECTL 变量的值,来保证同一时刻只能有一个线程对数组进行初始化,CAS 成功之后,还会再次判断当前数组是否已经初始化完成,如果已经初始化完成,就不会再次初始化,通过自旋 + CAS + 双重 check 等手段保证了数组初始化时的线程安全
那么接下来我们就来看看 initTable 方法。
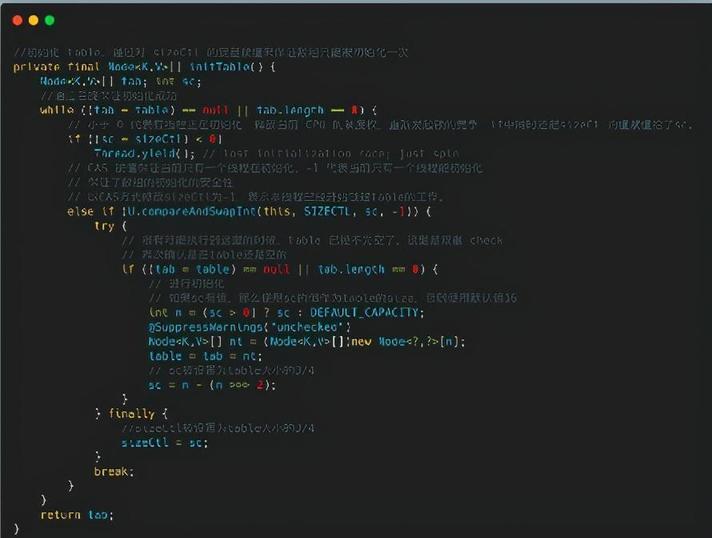
注意里面有个关键的值 sizeCtl,这个值有多个含义。
1、-1 代表有线程正在创建 table;
2、-N 代表有 N-1 个线程正在复制 table;
3、在 table 被初始化前,代表根据构造函数传入的值计算出的应被初始化的大小;
4、在 table 被初始化后,则被设置为 table 大小 的 75%,代表 table 的容量(数组容量)。
新增槽点值时的线程安全
此时为了保证线程安全,做了四处优化:
1.通过自旋死循环保证一定可以新增成功。
在新增之前,通过 for (Node<K,V>[] tab = table;;)这样的死循环来保证新增一定可以成功,一旦新增成功,就可以退出当前死循环,新增失败的话,会重复新增的步骤,直到新增成功为止。
2.当前槽点为空时,通过 CAS 新增。
Java 这里的写法非常严谨,没有在判断槽点为空的情况下直接赋值,因为在判断槽点为空和赋值的瞬间,很有可能槽点已经被其他线程复制了,所以我们采用 CAS 算法,能够保证槽点为空的情况下赋值成功,如果恰好槽点已经被其他线程赋值,当前 CAS 操作失败,会再次执行 for 自旋,再走槽点有值的 put 流程,这里就是自选 + CAS 的结合。
3.当前槽点有值,锁住当前槽点。
put 时,如果当前槽点有值,就是 key 的 hash 冲突的情况,此时槽点上可能是链表或红黑树,我们通过锁住槽点,来保证同一时刻只会有一个线程能对槽点进行修改
4.红黑树旋转时,锁住红黑树的根节点,保证同一时刻,当前红黑树只能被一个线程旋转
Hash算法
spread方法源码分析
哈希算法的逻辑,决定 ConcurrentHashMap 保存和读取速度。
传入的参数h为 key 对象的 hashCode,spreed 方法对 hashCode 进行了加工。重新计算出 hash。
hash 值是用来映射该 key 值在哈希表中的位置。取出哈希表中该 hash 值对应位置的代码如下。
我们先看这一行代码的逻辑,第一个参数为哈希表,第二个参数是哈希表中的数组下标。通过 (n - 1) & hash 计算下标。n 为数组长度,我们以默认大小 16 为例,那么 n-1 = 15,我们可以假设 hash 值为 100
15的二进制高位都为0,低位都是1。那么经过&计算后,hash值100的高位全部被清零,低位则保持不变,并且一定是小于(n-1)的。也就是说经过如此计算,通过hash值得到的数组下标绝对不会越界。
这里提出几个问题:
1、数组大小可以为 17,或者 18 吗?
2、如果为了保证不越界为什么不直接用 % 计算取余数?
3、为什么不直接用 key 的 hashCode,而是使用经 spreed 方法加工后的 hash 值?
数组大小必须为 2 的 n 次方
第一个问题的答案是数组大小必须为 2 的 n 次方,也就是 16、32、64….不能为其他值。因为如果不是 2 的 n 次方,那么经过计算的数组下标会增大碰撞的几率
如果hash值的二进制是 10000(十进制16)、10010(十进制18)、10001(十进制17),和10100做&计算后,都是10000,也就是都被映射到数组16这个下标上。这三个值会以链表的形式存储在数组16下标的位置。这显然不是我们想要的结果。
但如果数组长度n为2的n次方,2进制的数值为10,100,1000,10000……n-1后对应二进制为1,11,111,1111……这样和hash值低位&后,会保留原来hash值的低位数值,那么只要hash值的低位不一样,就不会发生碰撞。
同时(n - 1) & hash等价于 hash%n。那么为什么不直接用hash%n呢?
这是因为按位的操作效率会更高。
为什么不直接用 key 的 hashCode?
其实说到底还是为了减少碰撞的概率。我们先看看 spreed 方法中的代码做了什么事情:
这个意思是把 h 的二进制数值向右移动 16 位。我们知道整形为 32 位,那么右移 16 位后,就是把高 16 位移到了低 16 位。而高 16 位清0了。
^为异或操作,二进制按位比较,如果相同则为 0,不同则为 1。这行代码的意思就是把高低16位做异或。如果两个hashCode值的低16位相同,但是高位不同,经过如此计算,低16位会变得不一样了。
为什么要把地位变得不一样呢?
这是由于哈希表数组长度n会是偏小的数值,那么进行(n - 1) & hash运算时,一直使用的是hash较低位的值。那么即使hash值不同,但如果低位相当,也会发生碰撞。而进行h ^ (h >>> 16)加工后的hash值,让hashCode高位的值也参与了哈希运算,因此减少了碰撞的概率。
为何高位移到低位和原来低位做异或操作后,还需要和HASH_BITS这个常量做 & 计算呢?HASH_BITS 这个常量的值为 0x7fffffff,转化为二进制为 0111 1111 1111 1111 1111 1111 1111 1111。这个操作后会把最高位转为 0,其实就是消除了符号位,得到的都是正数。这是因为负的 hashCode 在ConcurrentHashMap 中有特殊的含义,因此我们需要得到一个正的 hashCode。
扩容源码分析
我们大致了解了ConcurrentHashMap 的存储结构,那么我们思考一个问题,当数组中保存的链表越来越多,那么再存储进来的元素大概率会插入到现有的链表中,而不是使用数组中剩下的空位。这样会造成数组中保存的链表越来越长,由此导致哈希表查找速度下降,从 O(1) 慢慢趋近于链表的时间复杂度 O(n/2),这显然违背了哈希表的初衷。
所以ConcurrentHashMap 会做一个操作,称为扩容。也就是把数组长度变大,增加更多的空位出来,最终目的就是预防链表过长,这样查找的时间复杂度才会趋向于 O(1)。
扩容的操作并不会在数组没有空位时才进行,因为在空位快满时,新保存元素更大的概率会命中已经使用的位置,那么可能最后几个桶位很难被使用,而链表却越来越长了。
另外 ConcurrentHashMap 还会有链表转红黑树的操作,以提高查找的速度,红黑树时间复杂度为 O(logn),而链表是 O(n/2),因此只在 O(logn)<O(n/2) 时才会进行转换,也就是以 8 作为分界点。
接下来我们分析 treeifyBin 方法代码,这个代码中会选择是把此时保存数据所在的链表转为红黑树,还是对整个哈希表扩容
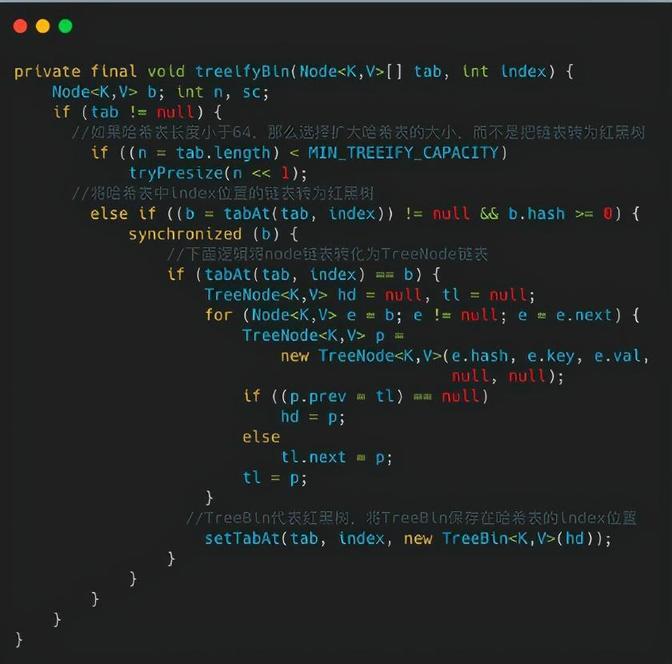
我们再重点看一下 tryPresize,此方法中实现了对数组的扩容,传入的参数 size 是原来哈希表大小的一倍。我们假定原来哈希表大小为 16,那么传入的 size 值为 32

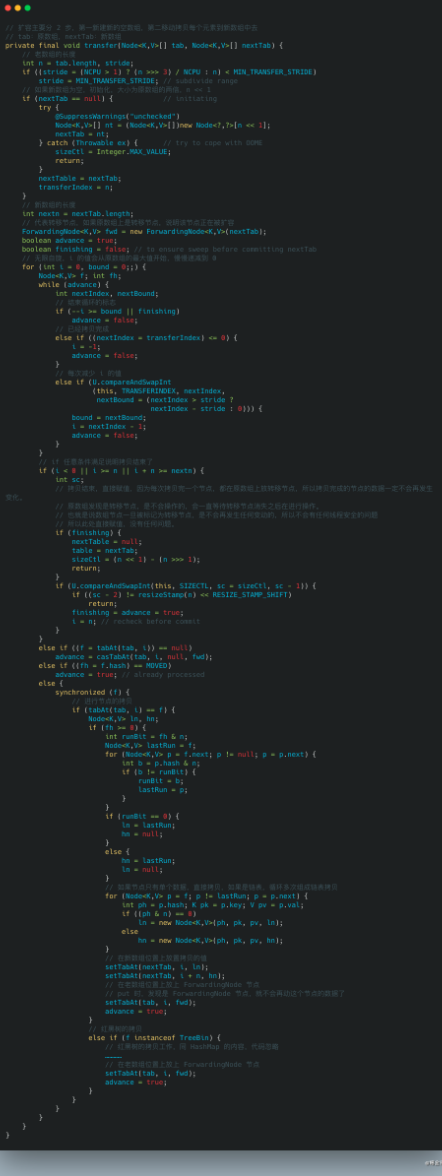
ConcurrentHashMap 的扩容时机和 HashMap 相同,都是在 put 方法的最后一步检查是否需要扩容,如果需要则进行扩容,但两者扩容的过程完全不同,ConcurrentHashMap 扩容的方法叫做 transfer,从 put 方法的 addCount 方法进去,就能找到 transfer 方法,transfer 方法的主要思路是:
1.首先需要把老数组的值全部拷贝到扩容之后的新数组上,先从数组的队尾开始拷贝;
2.拷贝数组的槽点时,先把原数组槽点锁住,保证原数组槽点不能操作,成功拷贝到新数组时,把原数组槽点赋值为转移节点;
3.这时如果有新数据正好需要 put 到此槽点时,发现槽点为转移节点,就会一直等待,所以在扩容完成之前,该槽点对应的数据是不会发生变化的;
4.从数组的尾部拷贝到头部,每拷贝成功一次,就把原数组中的节点设置成转移节点;
5.直到所有数组数据都拷贝到新数组时,直接把新数组整个赋值给数组容器,拷贝完成。
扩容方法主要是通过在原数组上设置转移节点,put 时碰到转移节点时会等待扩容成功之后才能 put 的策略,来保证了整个扩容过程中肯定是线程安全的,因为数组的槽点一旦被设置成转移节点,在没有扩容完成之前,是无法进行操作的
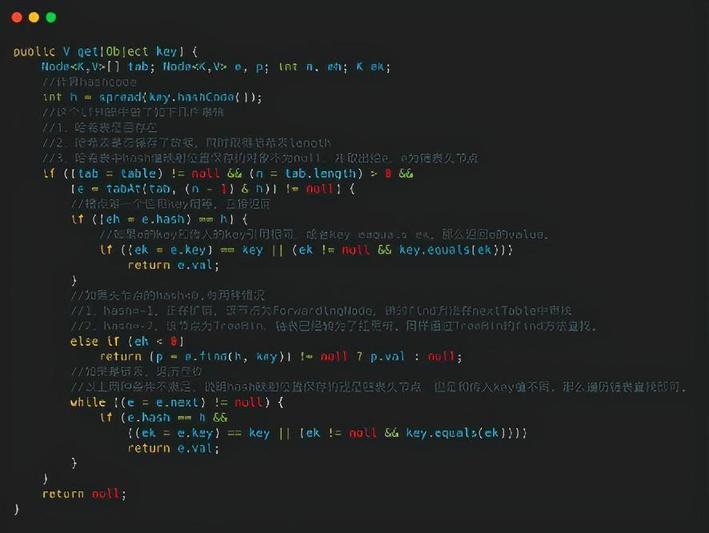
Get方法
ConcurrentHashMap 读的话,就比较简单,先获取数组的下标,然后通过判断数组下标的 key 是否和我们的 key 相等,相等的话直接返回,如果下标的槽点是链表或红黑树的话,分别调用相应的查找数据的方法,整体思路和 HashMap 很像
构造函数源码
这是一个有参数的构造方法。如果你对未来存储的数据量有预估,我们可以指定哈希表的大小,避免频繁的扩容操作。tableSizeFor 这个方法确保了哈希表的大小永远都是 2 的 n 次方。
注意这里传入的参数不是 initialCapacity,而是 initialCapacity 的 1.5 倍 + 1。这样做是为了保证在默认 75% 的负载因子下,能够足够容纳 initialCapacity 数量的元素。
ConcurrentHashMap (int initialCapacity) 构造函数总结下:
1、构造函数中并不会初始化哈希表;
2、构造函数中仅设置哈希表大小的变量 sizeCtl;
3、initialCapacity 并不是哈希表大小;
4、哈希表大小为 initialCapacity*1.5+1 后,向上取最小的 2 的 n 次方。如果超过最大容量一半,那么就是最大容量。
tableSizeFor 是如何实现向上取得最接近入参 2 的 n 次方的。下面我们来看 tableSizeFor 源代码:
依旧是二进制按位操作,这样一顿操作后,得到的数值就是大于 c 的最小 2 的 n 次。我们推演下过程,假设 c 是 9:
到这里可以看出规律来了。如果 c 足够大,使得 n 很大,那么运算到 n |= n >>> 16 时,n 的 32 位都为 1。
总结一下这一段逻辑,其实就是把 n 有数值的 bit 位全部置为 1。这样就得到了一个肯定大于等于 n 的值。我们再看最后一行代码,最终返回的是 n+1,那么一个所有位都是 1 的二进制数字,+1 后得到的就是一个 2 的 n 次方数值。
看完三件事❤️
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
-
点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
-
关注公众号 『 java烂猪皮 』,不定期分享原创知识。
-
同时可以期待后续文章ing🚀


