NLP知识总结和论文整理
词向量
参考论文: Efficient Estimation of Word Representations in Vector Space
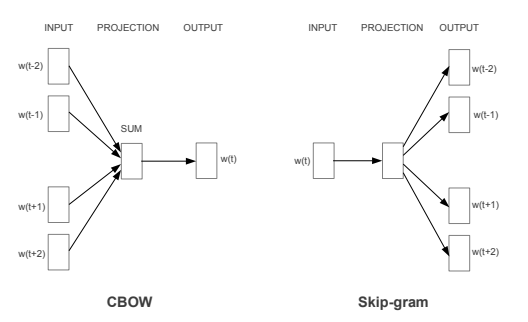
CBOW (Continuous Bag-of-Word): 挑一个要预测的词,来学习这个词前后文中词语和预测词的关系。
Skip-Gram: 使用文中的某个词,然后预测这个词周边的词。相比 CBOW 最大的不同,就是剔除掉了中间的那个 SUM 求和的过程,将词向量求和的这个过程不太符合直观的逻辑,而Skip-Gram没有这个过程。
句向量
Seq2Seq Learning 参考论文: Sequence to Sequence Learning with Neural Networks
将一个 sequence 转换成另一个 sequence。也就是用Encoder压缩并提炼第一个sequence的信息,然后用Decoder将这个信息转换成另一种语言或其他的表达形式。
In practice: Google's NMT System. 参考论文: Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
CNN for NLP 参考论文:Convolutional Neural Networks for Sentence Classification
注意力
CNN Attention Neural Image Caption Generation 参考论文: Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Seq2Seq Attention Mechanism 参考论文:Effective Approaches to Attention-based Neural Machine Translation
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Transformer 参考论文:Attention Is All You Need
Layer Normalization 参考论文:Layer Normalization
Other Normalization 参考论文:PowerNorm: Rethinking Batch Normalization in Transformers
RNN 与 attention 参考论文: Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
预训练模型
ELMo 参考论文:Deep contextualized word representations
找出词语放在句子中的意思。ELMo还是想用一个向量来表达词语,不过这个词语的向量会包含上下文的信息。
ELMo的训练:前向LSTM预测后文的信息,后向LSTM预测前文的信息。训练一个顺序阅读者+一个逆序阅读者,在下游任务的时候, 分别让顺序阅读者和逆序阅读者,提供他们从不同角度看到的信息。
GPT 参考论文:Improving Language Understanding by Generative Pre-Training
Language Models are Unsupervised Multitask Learners
Language Models are Few-Shot Learners
用非监督的人类语言数据,训练一个预训练模型,然后拿着这个模型进行finetune, 基本上就可以让你在其他任务上也表现出色。
BERT 参考论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 和 GPT 还有 ELMo 是一个性质的东西。 它存在的意义是要变成一种预训练模型,提供 NLP 中对句子的理解。ELMo 用了双向 LSTM 作为句子信息的提取器,同时还能表达词语在句子中的不同含义;GPT 呢, 它是一种单向的语言模型,同样也可以用 attention 的方式提取到更加丰富的语言意思信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号