YOLO v8:目标检测的最新王者
本文来自公众号“AI大道理”
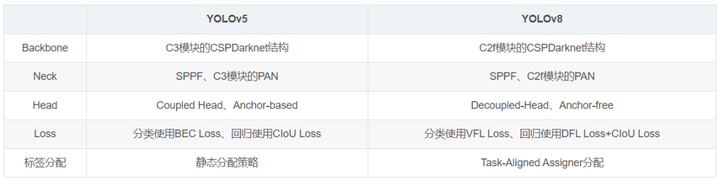
Yolov8是Yolo系列模型的最新王者,各种指标全面超越现有目标检测模型。
Yolov8借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,全面改进了Yolov5模型结构,同时保持了Yolov5工程化简洁易用的优势。
1、YOLOV8的改进
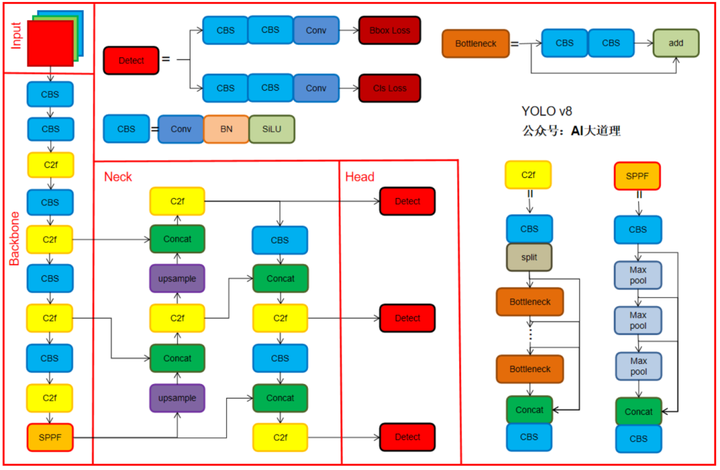
1)Backbone
2)Neck
3)Head
4)Loss计算
5)标签匹配策略
添加图片注释,不超过 140 字(可选)
1、Backbone
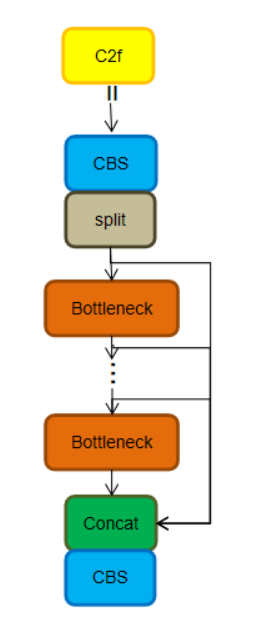
YOLOv8的backbone使用C2f模块代替C3模块。C2f模块借鉴了YOLOv7中的ELAN思想,通过并行更多的梯度流分支,目的是为了在保证轻量化的同时获得更加丰富的梯度流信息,额外还增加了一个Split操作。
结构如下所示,可以发现多了更多的跳层连接和额外的 Split 操作。
C2f中每个BottleNeck的输入Tensor的通道数channel都只是上一级的0.5倍,因此计算量明显降低。从另一方面讲,梯度流的增加,也能够明显提升收敛速度和收敛效果。
yolov8的C2f:
添加图片注释,不超过 140 字(可选)
具体改进如下:
-
第一个卷积层的Kernel size从6×6改为3x3。
-
所有的C3模块改为C2f模块,多了更多的跳层连接和额外Split操作。
-
Block数由C3模块3-6-9-3改为C2f模块的3-6-6-3。
2、Neck
Neck保留了PAN思想,删除了上采样阶段的卷积结构,将 C3 模块换成 C2f。
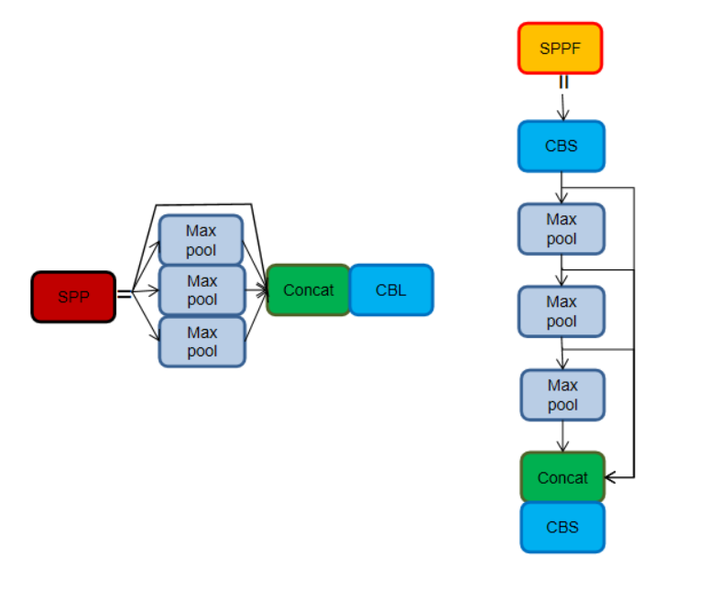
SPPF对比SPP,两者的作用是一样的,但SPPF的速度更高。
添加图片注释,不超过 140 字(可选)
3、Head
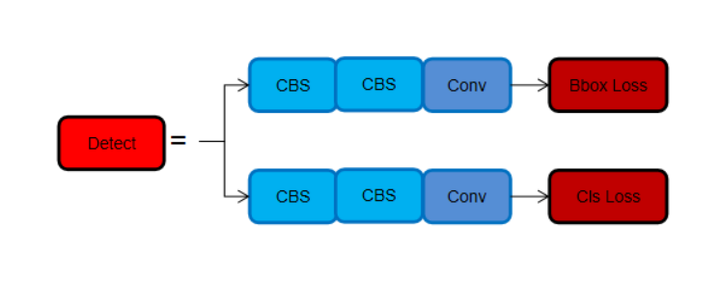
解耦头:Head部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。
添加图片注释,不超过 140 字(可选)
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法。
YOLOX的Head中也使用了解耦头和Anchor-free策略。在目标检测中,分类与回归任务的冲突是一种常见问题,因此,分类与定位头的解耦已被广泛应用到单阶段、两阶段检测中。YOLOX的作者分析发现:检测头耦合会影响模型性能,采用解耦头替换YOLO的检测头可以显著改善模型收敛速度。
Anchor-free:
Anchor-based和Anchor-free的区别就在于训练过程是否设置了先验框,Anchor-based策略非常依赖于好的先验框设计,对于不同的任务以及形变较大(高宽比变化大)的目标,可能都需要人为地根据经验对先验框超参数进行设计和调节。Anchor-free相对于就简单很多,但操作简单的同时可能会带来召回率性能欠佳、对重叠目标的检测效果一般等问题(比如YOLOv1)。
4、Loss 计算
Loss 计算包括 2 个分支:分类和回归分支,没有了之前的 objectness 分支。yolov8采用VFL Loss作为分类损失,同时使用DFL Loss 和CIOU Loss作为回归损失。VFL Loss(Varifocal Loss)的灵感来自Focal Loss。Focal Loss的设计是为了解决密集目标检测器训练中前景类和背景类之间极度不平衡的问题。Focal Loss:
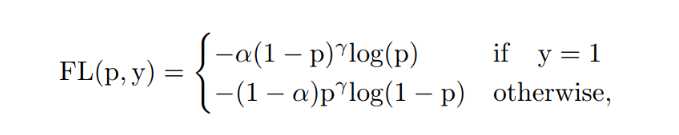
添加图片注释,不超过 140 字(可选)
其中,1为ground-truth类,表示前景类的预测概率。如公式所示,调制因子(γ为前景类和γ为背景类)可以减少简单样例的损失贡献,相对增加误分类样例的重要性。
Focal Loss处理的正负样本是对称的,VFL Loss则是提出了非对称的加权操作。
VFL Loss:
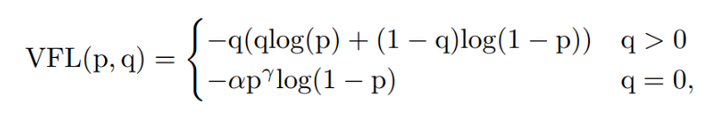
添加图片注释,不超过 140 字(可选)
其中,预测值为目标分数。对于前景点将其ground truth类别分数设定为生成的边界框和它的ground truth(gt_IoU)之间的IoU,否则为0;而对于背景点,所有类的分数为0。
如公式所示,通过利用γ的因子缩放损失,VFL Loss仅减少了负例(q=0)的损失贡献,而不以同样的方式降低正例(q>0)的权重。这是因为正样本相对于负样本是非常罕见的,应该保留它们的学习信息。
DFL Loss:
Distribution Focal Loss损失的提出主要是为了解决bbox的表示不够灵活(inflexible representation)问题。传统目标检测,尤其是复杂场景中,目标物体的真实边界框的定义其实是无法精确给出的(包括标注人的主观倾向,或是遮挡、模糊等造成的边界歧义及不确定性)。比如水中的帆板边界、被遮挡的大象边界,其实都很难去界定一个精确的位置。
传统的回归方法直接使预测值向一个离散的确定值(标签位置y )进行逼近。针对上方所述的场景,回归一个分布范围(下方右图)相比于逼近一个离散值更符合事实。DFL损失就是基于这样的思想,将框的位置建模成一个general distribution,让网络能够快速地聚焦于标签位置y 附近范围的位置分布。
但是如果分布过于随意,网络学习的效率可能不会高,因为一个积分目标可能对应无穷多种分布模式。
考虑到真实的分布通常不会距离标注的位置太远,因此Distribution Focal Loss选择优化标签y附近左右两个位置(yi与yi+1)的概率,使得网络分布聚焦到标签值附近。
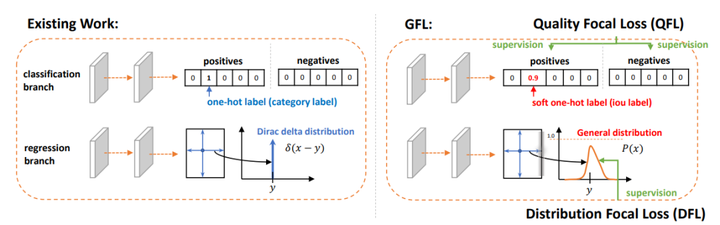
添加图片注释,不超过 140 字(可选)
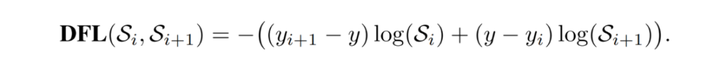
添加图片注释,不超过 140 字(可选)
5、标签匹配策略
YOLOv5采用的依然是静态分配策略,考虑到动态分配策略的优异性。
Yolov8算法中直接引用了TOOD中的Task-Aligned Assigner正负样本分配策略。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
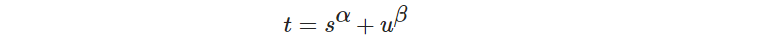
添加图片注释,不超过 140 字(可选)
其中,s是标注类别对应的预测分值,u是预测框和GT Box的IoU,两者相乘即可衡量对齐程度(Task-Alignment)。α和β是权重超参数。
t可以同时控制分类得分和IoU的优化来实现Task-Alignment,从而引导网络动态关注高质量的anchor。当类别分值越高且IoU越高时,t的值就越接近于1。
具体执行步骤如下:
-
基于分类得分和预测框与GT的IoU,加权得到一个关联分类以及回归的对齐分数alignment_metrics。
-
计算anchor的中心点是否在当前GT框内,只有在当前GT内的anchor才能作为正样本。
-
满足2的前提下,基于alignment_metrics选取topK大的作为正样本,其余作为负样本进行训练。
6、总结
添加图片注释,不超过 140 字(可选)
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

添加图片注释,不超过 140 字(可选)
—————————————————————
|
萍水相逢逢萍水,浮萍之水水浮萍!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号