CLIP:万物分类(视觉语言大模型)
本文来着公众号“AI大道理”
论文地址:https://arxiv.org/abs/2103.00020
传统的分类模型需要先验的定义固定的类别,然后经过CNN提取特征,经过softmax进行分类。然而这种模式有个致命的缺点,那就是想加入新的一类就得重新定义这个类别的标签,并重新训练模型,这样非常不方便。CLIP打破了这个桎梏。CLIP能做到在一定标签内进行训练,标签外的也能进行分类。
那么CLIP到底是如何认识未知的事物的呢?
1、从人脸识别开始说起
最早的打破固定标签的方法和应用就是人脸识别了。
早期的人脸识别,我们完全可以当做一个分类任务来做。比如一个教室或者一个公司,当做固定的人,我们就做一个N类的分类即可。然而我们知道,公司的人是变动的,新来一个同事由于事先没有训练过,导致分类不出来,所以就得重新训练这个分类模型,把新来的同事的人脸加入数据集中进行重新然后才能再次work。为了解决这个问题,对比学习、相似度训练派上了用场。我们完全可以训练一个人脸相似度的模型,这个模型的数据集是这样的,一对一对同样的人的两张人脸一起训练,提取特征之后计算特征向量之间的余弦相似度,相似度高的认为是同一张人脸,从而达到人脸识别的效果。当然,也可以三张图片一起训练,即两张一样的人脸外加一张其他人脸,使得一样的人脸相似度高,不一样的人脸相似度低。不管如何,这样训练出来的模型可以看做一个相似度模型。那么新来一个员工怎么办呢?很简单,只需要把它的人脸采集一张放入库中就行,而无需重新训练模型。当推理的时候,拍摄一张它的人脸,这个人脸进入相似度模型,和人脸库中的所有人脸进行计算相似度,那么之前放入的那张它的人脸就可以和当前拍摄到的人脸得出相似度最高的分数。这就有效解决了新来人脸要重新训练的问题。这个思想和CLIP是非常相似的,只不过CLIP的库是文字,而人脸识别系统的库是图片。这个库可以训练完成之后随时加入没有见过的。不管是文字,还是图片,本质都是一样的,在特征提取后或者说编码之后都是数字,都是向量。

添加图片注释,不超过 140 字(可选)
2、CLIP简介
CLIP,Contrastive Language–Image Pre-training,是2021年openAI推出的一个基于对比学习的模型,利用文本信息训练一个可以实现zero-shot的视觉模型,迁移能力很强。CLIP也可以称为多模态大模型,零样本学习方法。CLIP最大的贡献在于打破了固定类别标签范式。CLIP模型不一样,CLIP在训练的过程中,是将句子和图片匹配,然后在推理过程中找到与之最接近的模板句子。CLIP模型在训练过程中,用到了4亿组图像文本对,可以说是涵盖了自然界中的大部分场景。
3、网络结构
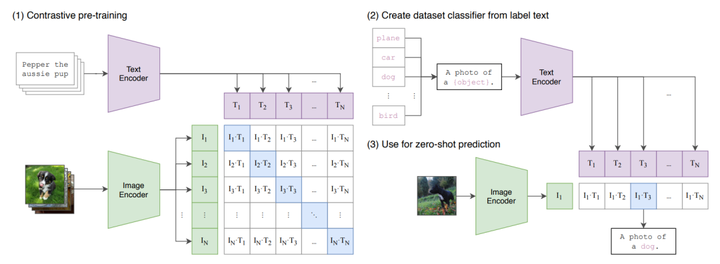
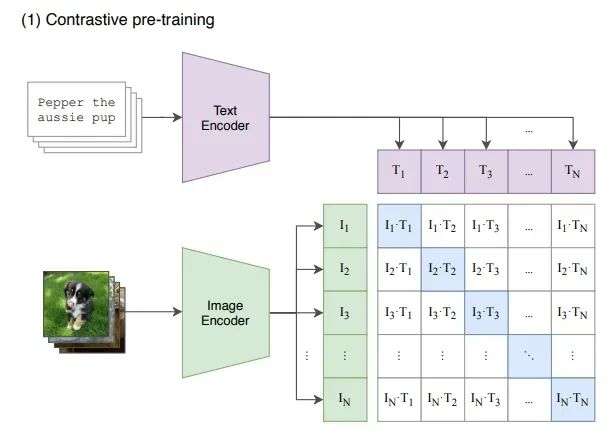
CLIP的网络结构主要包含Text Encoder和Image Encoder两个模块,分别提取文本和图像特征,然后基于比对学习让模型学习到文本-图像的匹配关系。CLIP使用大规模数据(4亿文本-图像对)进行训练,基于海量数据,CLIP模型可以学习到更多通用的视觉语义信息,给下游任务提高帮助。具体步骤如下:1)输入的文本和图像分别经过各自的Encoder处理成特征向量;2)构建关系矩阵。形如图1右边的矩阵,图1右边的矩阵中的每一个元素都是每一个图像特征向量和其他文本特征向量的余弦相似度。该矩阵中主对角线的元素都是匹配的(图像和文本特征完全对应),其他地方的元素并不匹配。3)主对角线的余弦相似度尽可能的最大,其他地方的余弦相似度尽可能的最小。
添加图片注释,不超过 140 字(可选)
4、CLIP的学习方法
CLIP采用对比学习。对比学习是一种学习相似性度量的方法,它的核心思想是通过将同一组数据中的不同样本对进行比较,来学习它们之间的相似度或差异度。在CLIP模型中,对比学习被用来训练模型学习视觉和语言的相互关系。具体来说,CLIP模型将图像和文本映射到同一表示空间,并通过对比不同图像和文本对之间的相似性和差异性进行训练,从而学习到具有良好泛化能力的特征表示。如果是预测一个图像所对应的文本,需要逐字逐句的去预测,非常复杂,效率较低,因为一张图像可能有多种文本描述,如果是使用对比学习的方法,预测一个图像和一个文本是否配对,那任务就简单很多。将预测性目标函数换成对比性目标函数,训练效率提高了四倍。
5、CLIP的训练
CLIP在训练过程中,取一个batch_size的图像文本对,图像经过Image Encode, 文本经过Text Encoder,然后在向量之间计算余弦相似度,结果就如图像所示,对象线上的元素分别是一一对应的。那么文本编码和图像编码之间的相似度的也该是最高的,即在对比学习中,对角线上的元素即为正样本,其余非对角线元素为负样本。因此这个模型经过训练后,能实现的最终理想目标就是一组图像文本对,图像经过Image Encoder编码和文本经过Text Encoder的编码应该是一摸一样的。
添加图片注释,不超过 140 字(可选)
其实,预训练网络的输入是文字与图片的配对,每一张图片都配有一小句解释性的文字。将文字和图片分别通过一个编码器,得到向量表示。这里的文本编码器就是 Transformer;而图片编码器既可以是 Resnet,也可以是 Vision transformer,作者对这两种结构都进行了考察。
添加图片注释,不超过 140 字(可选)
这里细微的区别就是,普通有分类头的监督学习的模型,输入的是已知的图片,不用再输入标签,自行分类,其实标签是已经在了,这是全包围的。CLIP输入的可以是外来没有训练过的图片,输入这个图片对应的文字到文字库里面,然后也可以正确分类。
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WebImageText,如果按照文本的单词量,它和训练GPT-2的WebText规模类似,如果从数量上对比的话,它还比谷歌的JFT-300M数据集多一个亿,所以说这是一个很大规模的数据集。CLIP虽然是多模态模型,但它主要是用来训练可迁移的视觉模型。所有的模型都训练32个epochs,采用AdamW优化器,而且训练过程采用了一个较大的batch size:32768。由于数据量较大,最大的ResNet模型RN50x64需要在592个V100卡上训练18天,而最大ViT模型ViT-L/14需要在256张V100卡上训练12天,可见要训练CLIP需要耗费多大的资源。
6、CLIP的推理
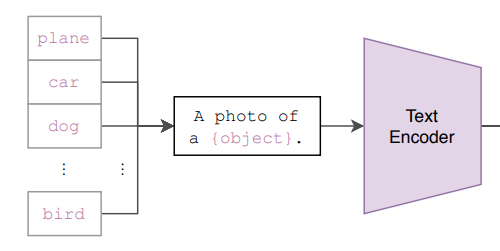
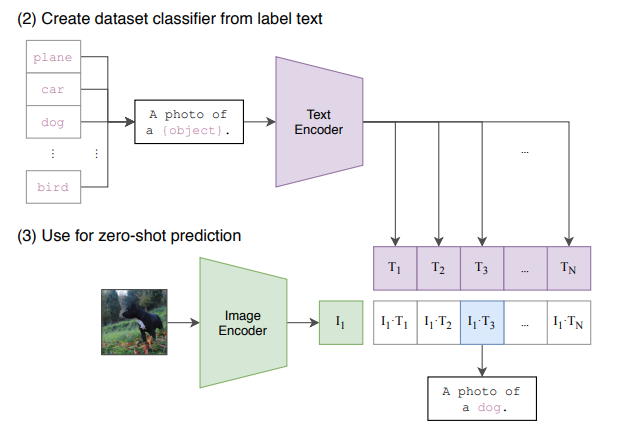
接下来是 zero-shot 的推理过程。给定一张图片,如何利用预训练好的网络去做分类呢?这里作者很巧妙地设置了一道“多项选择”。具体来说,我给网络一堆分类标签,比如cat, dog, bird,利用文本编码器得到向量表示。然后分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果。作者提到,相比于单纯地给定分类标签,给定一个句子的分类效果更好。比如一种句子模板 A photo of a ...,后面填入分类标签。这种句子模板叫做 prompt(提示)。这也很好理解:预训练时模型看到的大多是句子,如果在推理时突然变成单词,效果肯定会下降。作者还说,句子模板的选择很有讲究,还专门讨论了prompt engineering,测试了好多种类的句子模板。提示信息有多种,从图2中可以看到它用不同的类别替换一句话中不同的词,形成不同的标签。
添加图片注释,不超过 140 字(可选)
推理过程中最关键的一点,在于我们有很高的自由度去设置“多项选择题”。从前的分类网络的类别数量是固定的,一般最后一层是跟着 softmax 的全连接层;如果要更改类别数量,就要更换最后一层;并且预测的内容是固定的,不能超过训练集的类别范围。但对于 CLIP 来说,提供给网络的分类标签不仅数量不固定,内容也是自由的。如果提供两个标签,那就是一个二分类问题;如果提供1000个标签,那就是1000分类问题。标签内容可以是常规的分类标签,也可以是一些冷门的分类标签。我认为这是 CLIP 的一大主要贡献——摆脱了事先定好的分类标签。
7、CLIP的损失函数
首先是图像文本编码器,编码结果维度并不一致,无法计算相似度,因此一个learn prob将维度统一。对编码结果进行归一化,对编码计算相似度矩阵,然后计算对比损失。损失函数:

添加图片注释,不超过 140 字(可选)
其中, 温度系数τ是设定的超参数,q和k可以表示相似度度量,分子部分表示正例之间的相似度,分母表示正例与负例之间的相似度。因此看出,相同类别相似度越大,不同类别相似度越小,损失就会越小。这一步得到的Encoder和Decoder用于下面的步骤。

添加图片注释,不超过 140 字(可选)
8、CLIP的应用
StyleCLIP:变脸

添加图片注释,不超过 140 字(可选)
CLIPDraw:画画

添加图片注释,不超过 140 字(可选)
CLIP + NeRF:

添加图片注释,不超过 140 字(可选)
CLIPasso:提炼语义概念,生成图片目标的高度抽象线条画

添加图片注释,不超过 140 字(可选)
9、总结
CLIP在图像文本匹配或者图像文本检索任务上,速度很快。因为这两个任务通常有一个很大的已有的数据库,CLIP可以提前把数据库里所有的图像文本的特征提前抽取好,当给定新的一张图片或者一个文本,将其与已有的数据库做匹配,直接计算一个点乘,矩阵乘法是比较快的。
局限性:
-
CLIP的zero-shot性能虽然和有监督的ResNet50相当,但是还不是SOTA,作者估计要达到SOTA的效果,CLIP还需要增加1000x的计算量,这是难以想象的;
-
CLIP的zero-shot在某些数据集上表现较差,如细粒度分类,抽象任务等;
-
CLIP在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题,即如果测试数据集的分布和训练集相差较大,CLIP会表现较差;
-
CLIP并没有解决深度学习的数据效率低下难题,训练CLIP需要大量的数据;
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

添加图片注释,不超过 140 字(可选)
—————————————————————
公众号《AI大道理》征稿函mp.weixin.qq.com/s?__biz=MzU5NTg2MzIxMw==&mid=2247489802&idx=1&sn=228c18ad3a11e731e8f325821c184a82&chksm=fe6a2ac8c91da3dec311bcde280ad7ee760c0c3e08795604e0f221ff23c89c43a86c6355390f&scene=21#wechat_redirect
|
留言吧mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=77&appmsgid=100018830&isMul=1&replaceScene=0&isSend=0&isFreePublish=0&token=2064732160&lang=zh_CN
萍水相逢逢萍水,浮萍之水水浮萍!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号