
目标跟踪基础:两张图片相似度算法
本文来自公众号“AI大道理”
——————
目标跟踪就是在时序帧中搜索目标的过程,本质上就是检索。
不管是传统的目标跟踪中的生成模型和判别模型,还是用深度学习来做目标跟踪,本质上都是来求取目标区域与搜索区域的相似度,这就是典型的多输入。
目标跟踪为什么需要相似度?
在跟踪中,下一帧的目标要和上一帧的目标做一个匹配,才能确定是同一个目标。那么同样是行人,如何确定检测框是同一个目标呢?
可以对检测框的目标与上一针所有检测框目标进行相似度匹配。
当然其他的根据检测框的位置,中心点的距离等等都存在不稳定性。
图像的相似度度量存在的困难主要在:
-
相似度的比较依赖图像结构。L2距离等度量逐像素的比较相似度,忽视了图像的结构信息,因此不适合比较图像的相似度。
-
上下文相关。比如红色的圆和红色的正方形更像还是和蓝色的圆更像?
-
相似度有可能不满足距离的定义。

添加图片注释,不超过 140 字(可选)
一、相似度算法
1、传统算法
-
余弦相似度
-
哈希算法
-
直方图
-
互信息
-
均方误差(MSE)算法
-
SSIM结构相似性
-
特征匹配
2、深度学习算法
-
孪生网络
-
SimGNN
-
Graph kernel

添加图片注释,不超过 140 字(可选)
二、传统相似度算法

添加图片注释,不超过 140 字(可选)
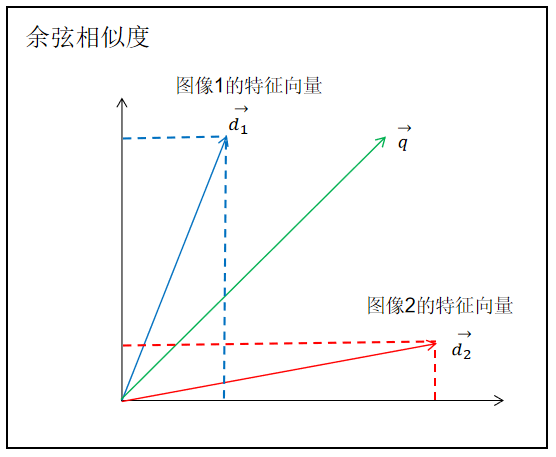
2.1 余弦相似度
余弦相似度是一种常用的衡量向量之间相似度的方法,它可以用于计算两个向量之间的夹角的余弦值。
在图像相似度计算中,可以将图像转换为特征向量,然后使用余弦相似度来比较这些特征向量的相似程度。
余弦相似度的计算公式如下:

添加图片注释,不超过 140 字(可选)
其中,A和B分别表示两个向量,·表示向量的点积,||A||和||B||表示向量的范数(即向量的长度)。
余弦相似度的取值范围在 -1 到 1 之间,值越接近 1 表示两个向量越相似,越接近 -1 表示两个向量越不相似,接近 0 表示两个向量之间没有明显的相似性或差异。
在图像相似度计算中,可以将图像转换为特征向量(如使用卷积神经网络提取的特征向量),然后计算这些特征向量之间的余弦相似度来衡量图像的相似性。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
2.2 哈希算法
在图片相似度算法中,哈希算法也被广泛应用。
图像哈希算法通过将图像转换为固定长度的哈希值,从而实现图像的相似度比较和检索。
以下是两种常见的图像哈希算法:
-
平均哈希(Average Hash):平均哈希算法将图像缩小为一个固定的大小(如8x8像素),然后将图像转换为灰度图像,并计算图像的平均灰度值。接下来,将每个像素的灰度值与平均灰度值进行比较,将比平均灰度值大的像素标记为1,比平均灰度值小的像素标记为0。最终,将这些二进制结果组合成一个固定长度的哈希值,用于表示图像。通过比较两个图像的哈希值的汉明距离(Hamming Distance),可以评估图像的相似度,距离越小表示图像越相似。
-
感知哈希(Perceptual Hash):感知哈希算法借助离散余弦变换(Discrete Cosine Transform,DCT)来提取图像的频率特征。它首先将图像转换为灰度图像,并调整图像的大小为固定的尺寸(如32x32像素)。然后,对调整后的图像应用DCT,并保留低频分量。接下来,根据DCT系数的相对大小,将图像转换为一个二进制哈希值。通过计算两个图像哈希值的汉明距离,可以衡量图像的相似度。
这些哈希算法主要适用于简单的图像相似度比较和快速图像检索任务。
它们具有计算效率高、哈希值固定长度、对图像变换具有一定鲁棒性等优点。
然而,由于哈希算法的特性,它们对于图像的细微变化或者复杂场景下的相似度比较可能存在一定的局限性。
添加图片注释,不超过 140 字(可选)
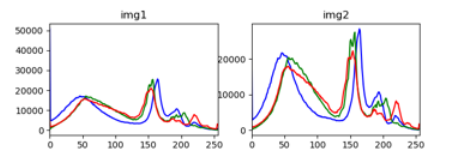
2.3 直方图
直方图是一种常用的图片相似度算法,它可以用来衡量两张图片在颜色分布上的相似度。
直方图算法通过统计图像中不同颜色的像素数量,并以直方图的形式呈现,进而进行图像相似度的比较。
直方图算法计算图片相似度的步骤:
-
图像预处理:将图像转换为灰度图像或彩色图像,并根据需要进行尺寸调整。
-
计算直方图:对于灰度图像,直方图表示不同灰度级别的像素数量。对于彩色图像,可以分别计算各个通道(如红、绿、蓝)的直方图。直方图可以使用固定的桶(bin)或者动态的自适应桶来表示。
-
直方图比较:对于两张图片的直方图,可以使用不同的距离或相似度度量方法来进行比较。常见的度量方法包括欧氏距离、曼哈顿距离、巴氏距离等。
-
相似度评估:根据直方图比较的结果,计算出两张图片之间的相似度得分。得分越高表示两张图片越相似。
直方图算法的优点是简单易懂,计算速度快,并且对于图片的旋转、缩放等变换具有一定的鲁棒性。
然而,直方图算法也有一些局限性,例如它只考虑了颜色分布而忽略了纹理和结构等因素。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
2.4 互信息
互信息是一种用于衡量两个随机变量之间相互依赖关系的指标,可以用于计算图片的相似度。
互信息衡量的是两个变量之间的信息共享程度,通过计算它们的联合概率分布和各自概率分布的乘积来评估它们的相关性。
通过计算两个图片的互信息来表征他们之间的相似度,如果两张图片尺寸相同,还是能在一定程度上表征两张图片的相似性的。
但是,大部分情况下图片的尺寸不相同,如果把两张图片尺寸调成相同的话,又会让原来很多的信息丢失,所以很难把握。
两个离散随机变量 X 和 Y 的互信息可以定义为:
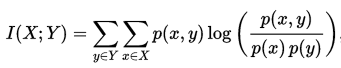
添加图片注释,不超过 140 字(可选)
其中 p(x,y) 是 X 和 Y 的联合概率分布函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率分布函数。
在连续随机变量的情形下,求和被替换成了二重定积分:
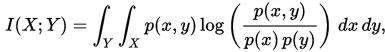
添加图片注释,不超过 140 字(可选)
其中 p(x,y) 当前是 X 和 Y 的联合概率密度函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率密度函数。
互信息的取值范围通常是非负的,值越大表示两个变量之间的相关性越高,也可以理解为两张图片的相似度越高。
互信息算法可能对图像的纹理、结构等细节不敏感,因此在某些情况下可能无法准确地反映图像的相似度。
添加图片注释,不超过 140 字(可选)
2.5 均方误差(MSE)算法
均方误差(Mean Squared Error,MSE)是一种常用的图片相似度算法,用于衡量两张图片之间的差异程度。
该算法通过计算两张图片对应像素之间的差值的平方,并求取平均值来得到相似度评分。
MSE的值越小表示两张图片越相似,值为0表示完全相同。
MSE算法只考虑像素级别的差异,可能无法准确地捕捉图像的纹理、结构等细节。
MSE的计算公式:
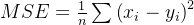
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
2.6 SSIM结构相似性
结构相似性指数是一种用于衡量两张图片之间结构相似性的指标。
与均方误差(MSE)相比,SSIM更能捕捉图像的结构信息和感知差异。
SSIM的计算方法考虑了亮度、对比度和结构三个方面的差异。
SSIM公式:
SSIM取值范围[0, 1],值越大,表示图像失真越小。
公式:
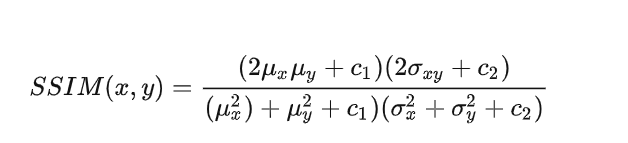
添加图片注释,不超过 140 字(可选)
uX、uY分别表示图像X和Y的均值,σX、σY分别表示图像X和Y的标准差,σXσX、σYσY分别表示图像X和Y的方差。σXY代表图像X和Y协方差。C1,C2和C3为常数,是为了避免分母为0而维持稳定。通常取C1=(K1L)^2, C2=(K2L)^2, C3=C2/2, 一般地K1=0.01, K2=0.03, L=255( 是像素值的动态范围,一般都取为255)
对于比较不同字体的字形相似度,可以考虑使用SSIM算法。因为SSIM算法更注重图像的结构相似性,它更好地检测出字形上的细微差异。
SSIM取值范围[0, 1],值越大,表示图像失真越小。
添加图片注释,不超过 140 字(可选)
2.7 特征匹配
特征匹配是一种常用的图片相似度算法,它基于图像中的特征点来计算相似度。
特征匹配算法步骤:
-
提取特征点:使用特征提取算法(如SIFT、SURF、ORB等)从两张图片中提取特征点。这些特征点可以是图像中具有鲁棒性和独特性的局部区域。
-
描述特征点:对于每个特征点,使用特征描述算法(如SIFT、SURF、ORB等)计算其特征描述子。描述子是对特征点周围区域的图像信息进行编码,用于表示该特征点的特征信息。
-
特征匹配:将第一张图片中的特征点与第二张图片中的特征点进行匹配。匹配算法通常基于描述子之间的相似度度量(如欧氏距离、汉明距离等),找到两张图片中相似的特征点对。
-
计算相似度:根据匹配到的特征点对,可以计算相似度指标(如匹配点对的数量、相似度得分等)来衡量两张图片之间的相似度。更多时候,还会使用一些筛选机制,例如RANSAC算法进行外点去除,以提高匹配的准确性。
特征匹配算法对图片中的局部特征进行有效的匹配和比较,相对于像素级的方法能更好地处理图像中的变换、缩放、旋转等变换操作。
特征匹配算法的性能受到图像质量、变换、遮挡、光照等因素的影响。
添加图片注释,不超过 140 字(可选)
三、深度学习算法
添加图片注释,不超过 140 字(可选)
3.1 Siamese
Siamese网络是一种神经网络结构,主要用于处理相似度比较或度量学习任务。
它的设计灵感来源于孪生兄弟(Siamese Twins),因为网络的结构呈现出两个相同的分支,共享参数并共同学习。
Siamese网络的主要特点是通过共享权重的方式处理输入的两个样本,然后将它们的表示进行比较或度量,输出它们的相似度分数。
这使得Siamese网络在处理两张图片的相似度非常有效。
Siamese网络的训练过程通常涉及两个主要步骤:
-
正样本和负样本对生成:从训练数据集中生成正样本对和负样本对。正样本对包含相同类别的样本,负样本对包含不同类别的样本。
-
训练网络:使用正样本对和负样本对作为输入,通过最小化损失函数(如对比损失函数、三元组损失函数等)来训练Siamese网络。损失函数的目标是使正样本对的相似度得分高于负样本对的相似度得分。
在推理阶段,Siamese网络可以通过将两个输入样本分别通过共享的分支来计算它们的表示,然后使用相似度度量方法(如欧氏距离、余弦相似度等)来计算它们的相似度得分。
Siamese网络的优点在于能够学习样本之间的相似性,并且对于训练数据中不平衡的类别分布也相对较为鲁棒。
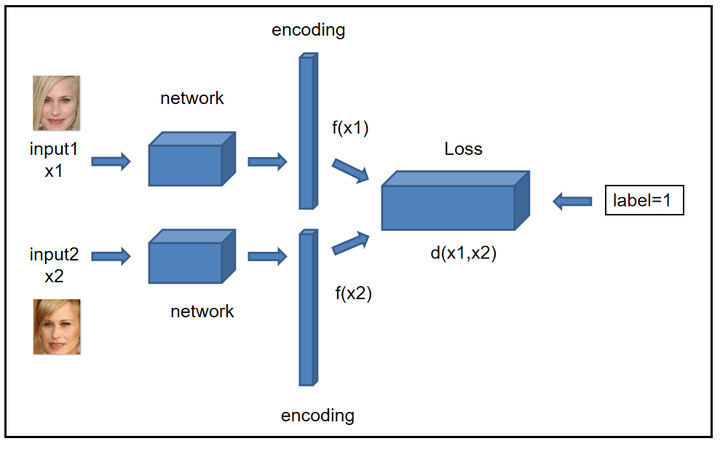
添加图片注释,不超过 140 字(可选)
Siamese网络由于最后一层使用 sigmoid 激活函数,它输出一个范围在 0 到 1 之间的值。接近 1 的相似度得分意味着两个输入是相似的,接近 0 的相似度得分意味着两个输入不相似。
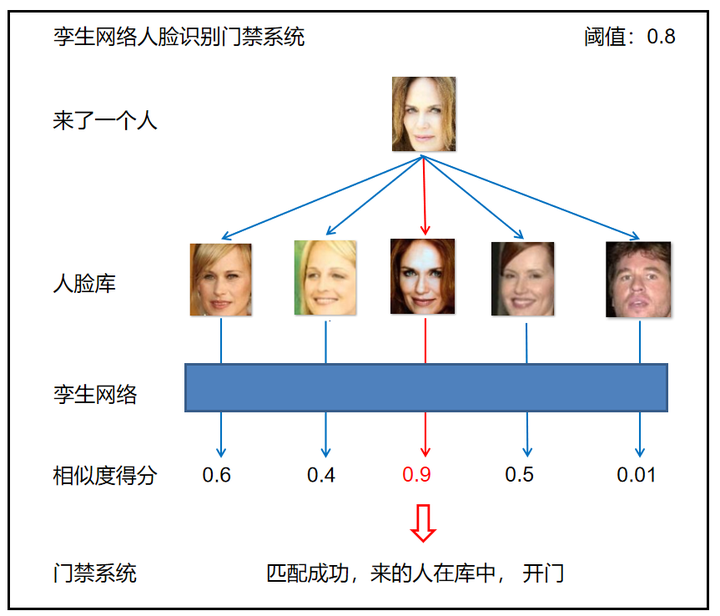
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
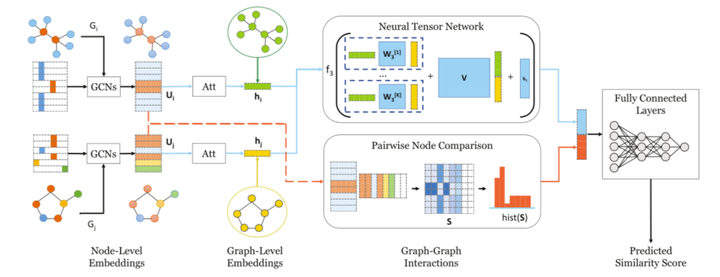
3.2 SimGNN
SimGNN是基于图神经网络(Graph Neural Network,GNN)的一种模型,用于处理图数据的相似度计算任务。
SimGNN是一种基于端到端神经网络的方法,它试图学习一个函数来将一对图映射到一个相似度分数。
SimGNN的全称是"Similarity Graph Neural Network",它旨在学习图数据中节点之间的相似度。
相似度图可以被用来解决各种任务,例如推荐系统中的物品相似度计算、文本匹配中的句子相似度计算等。
SimGNN的核心思想是通过图神经网络的方式对图数据进行表示学习,然后通过学到的表示来计算节点之间的相似度。
SimGNN步骤:
-
图数据表示:将图数据表示为节点特征矩阵和邻接矩阵的组合形式。节点特征矩阵用于表示每个节点的特征向量,邻接矩阵表示图中节点之间的连接关系。
-
图神经网络模型:使用图神经网络模型(如Graph Convolutional Network,Graph Attention Network等)对图数据进行表示学习。这些模型通过迭代地聚合节点周围的信息来更新节点的表示。
-
相似度计算:基于学到的节点表示,通过定义相似度度量方法(如余弦相似度、点积相似度等)来计算节点之间的相似度。
SimGNN的优点在于能够利用图数据中的结构信息和节点特征,进行有效的相似度计算。
SimGNN在推荐系统、文本匹配、社交网络分析等领域具有广泛的应用。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
3.3 Graph kernel
Graph kernels(图核)是一类用于计算图数据相似度的方法。
在机器学习和图分析领域,图数据常用于表示复杂的关系和结构,如社交网络、化学分子和推荐系统等。
图核方法旨在衡量不同图之间的相似性或距离。
图核方法基于图的结构和属性信息,通过将图数据映射到一个高维的向量空间中进行计算。这样可以使用向量空间中的传统机器学习算法来进行图的比较和分类。
常见的图核方法包括以下几种:
-
子图同构核(Graph Isomorphism Kernel):该方法比较两个图中的所有子图,通过计算子图之间的同构关系来衡量图的相似度。
-
核向量机(Kernelized Support Vector Machines):该方法通过使用核函数将图数据映射到一个高维空间,并在该空间中使用支持向量机(SVM)来进行分类或回归任务。
-
图编辑距离核(Graph Edit Distance Kernel):该方法基于图编辑距离,衡量两个图之间的编辑操作(如添加节点、删除节点、修改边等)的相似度。
-
直接计算核(Direct Computation Kernels):该方法直接计算两个图之间的相似度或距离,而不依赖于图的映射或编辑操作。常见的直接计算核包括图谱核(Graphlet Kernel)、子图核(Subgraph Kernel)等。
添加图片注释,不超过 140 字(可选)
四、总结
在目标跟踪中,相似度计算是用来度量当前帧中的目标与跟踪器所预测的目标之间的相似程度。
基于相似度的计算结果,可以用于确定当前帧中最可能的目标位置或更新跟踪器的状态。
常用的相似度计算方法在目标跟踪中的应用:
-
基于外观的相似度计算:
-
均方差(Mean Squared Error,MSE):计算目标区域与跟踪器所预测的目标区域之间的像素值差异。
-
结构相似性指数(Structural SIMilarity,SSIM):综合考虑目标区域的亮度、对比度和结构相似性。
-
基于直方图的相似度:通过计算目标区域的颜色直方图或梯度直方图之间的差异来度量相似度。
-
2基于运动的相似度计算:
-
光流相似度:通过计算目标区域内像素的运动向量与跟踪器预测的运动向量之间的差异来度量相似度。
-
运动模型相似度:通过比较目标区域的运动模型(如线性模型或卡尔曼滤波器预测模型)与跟踪器预测的运动模型之间的差异来度量相似度。
-
3基于深度学习的相似度计算:
-
使用卷积神经网络(Convolutional Neural Networks,CNN):将目标区域和跟踪器预测的目标区域输入到预训练的CNN中,通过计算它们的特征向量之间的距离或相似度来度量相似度。
-
使用Siamese网络:利用孪生网络结构,将目标区域和跟踪器预测的目标区域分别输入到共享的网络分支中,通过比较它们的表示向量之间的距离或相似度来度量相似度。
这些相似度计算方法的选择取决于目标跟踪任务的特点、可用数据和计算要求。
通常,通过实验和评估来选择最适合特定任务的相似度计算方法。

添加图片注释,不超过 140 字(可选)
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号—————————————————————

添加图片注释,不超过 140 字(可选)
—————————————————————
|
萍水相逢逢萍水,浮萍之水水浮萍!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号