孪生网络:图片相似度对比神器
本文来自公众号"AI大道理" ——————
Siamese Network(孪生网络)很早就被发明了,它的作者是著名的卷积神经网络LeNet-5的作者LeCun。最早用来从相似图片数据集上学习图片表示的网络结构就是siamese网络。两幅图通过两个共享权重的CNN得到各自的表示,而各自表示的距离决定了他们是相似还是不相似。

添加图片注释,不超过 140 字(可选)
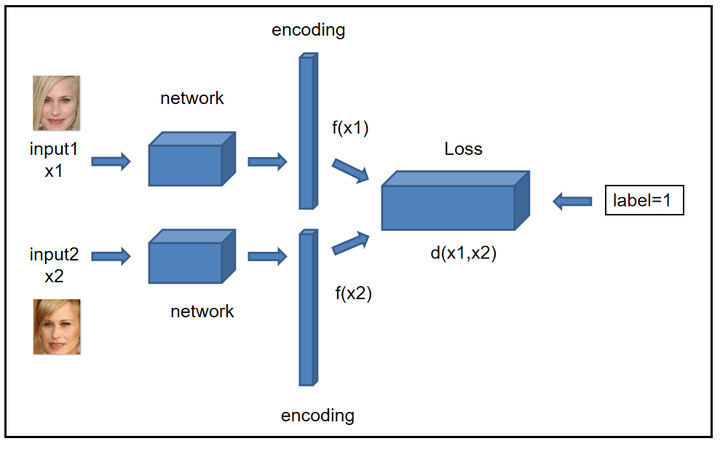
1、真假孪生网络
Siamese网络有两个输入,两个网络,根据这两个网络是否共享权重,可以分为真孪生网络siamese network和伪孪生网络pseudo-siamese network。真孪生网络:
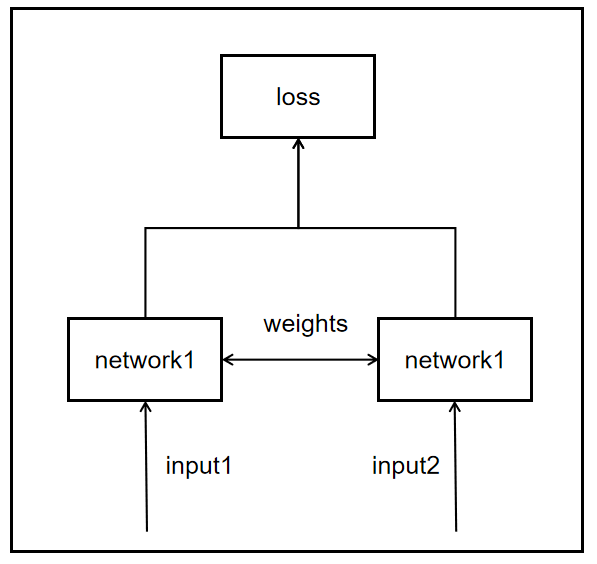
添加图片注释,不超过 140 字(可选)
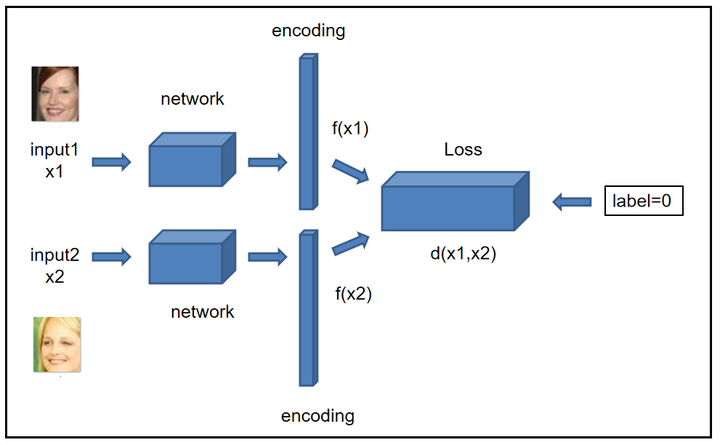
伪孪生网络:对于pseudo-siamese network,两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
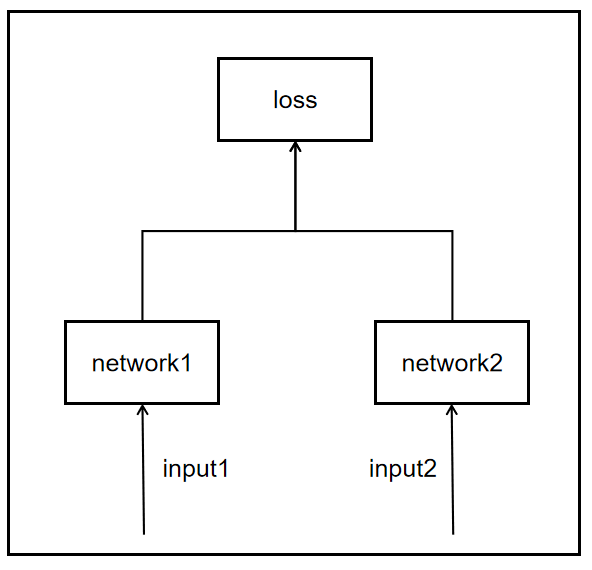
添加图片注释,不超过 140 字(可选)
可以看出差别就在于是否共享权重。不同应用:孪生神经网络用于处理两个输入"比较类似"的情况。伪孪生神经网络适用于处理两个输入"有一定差别"的情况。我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合;如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用pseudo-siamese network。
添加图片注释,不超过 140 字(可选)
2、Siamese Network的主要特点
(1)Siamese 网络采用两个不同的输入,通过两个具有相同架构、参数和权重的相似子网络。
(2)这两个子网络互为镜像,就像连体双胞胎一样。因此,对任何子网架构、参数或权重的任何更改也适用于其他子网。(3)两个子网络输出一个编码来计算两个输入之间的差异。(4)Siamese 网络的目标是使用相似度分数对两个输入是相同还是不同进行分类。可以使用二元交叉熵、对比函数或三元组损失来计算相似度分数,这些都是用于一般距离度量学习方法的技术。(5)Siamese 网络是一种one-shot分类器,它使用判别特征从未知分布中概括不熟悉的类别。
添加图片注释,不超过 140 字(可选)
孪生网络结构模型主要两个部分组成,第一部分是提取特征的全联接层和一个全联接层,第二个全联接网络用于对比卷积神经网络提取向量之间的距离。
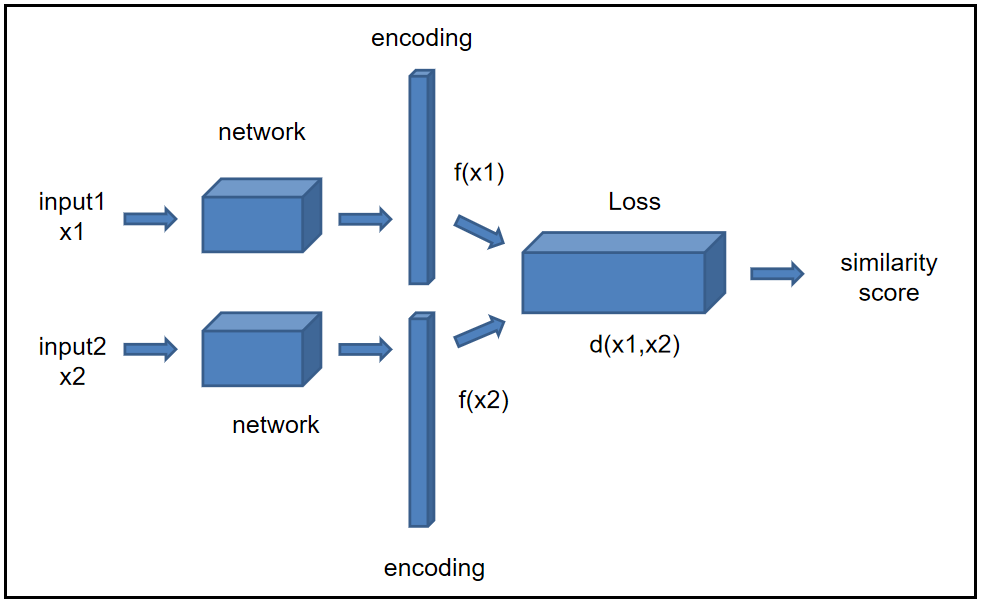
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
-
设计一个卷积神经网络用于提取图像特征。
-
每次将两张图片输入到同一个神经网络,得到一个特征向量。
-
将这两个特征向量相减得到一个新的向量。
-
将相减得到的新的向量输入到一个全联接层得到一个标量。
-
用 sigmoid 函数将结果映射到0或1。如果两张图片是同一个类别输出应该接近 1,不同类输出接近 0。

添加图片注释,不超过 140 字(可选)
3、训练孪生网络
对于sigmoid 输出的预测值和真实值计算距离也就是损失函数,损失函数可以是输出和真实值的交叉熵来反应预测和真实值之间差别。这样就可以通过梯度下降在反向传播来更新参数。模型主要有两个部分分别是卷积神经网络和全连接神经网络,训练过程就是更新这两部分网络的参数。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
训练 Siamese 神经网络:
(1)加载包含不同类的数据集(2)创建正负数据对。当两个输入相同时为正数据对,当两个输入不同时为负数据对。(3)构建卷积神经网络,它使用全连接层输出特征编码。我们将通过姊妹 CNN传递两个输入。姐妹 CNN 应该具有相同的架构、超参数和权重。(4)构建差分层以计算两个姐妹 CNN 网络编码输出之间的距离。(5)最后一层是具有单个节点的全连接层,使用 sigmoid 激活函数输出相似度分数。(6)使用二元交叉熵作为损失函数。
添加图片注释,不超过 140 字(可选)
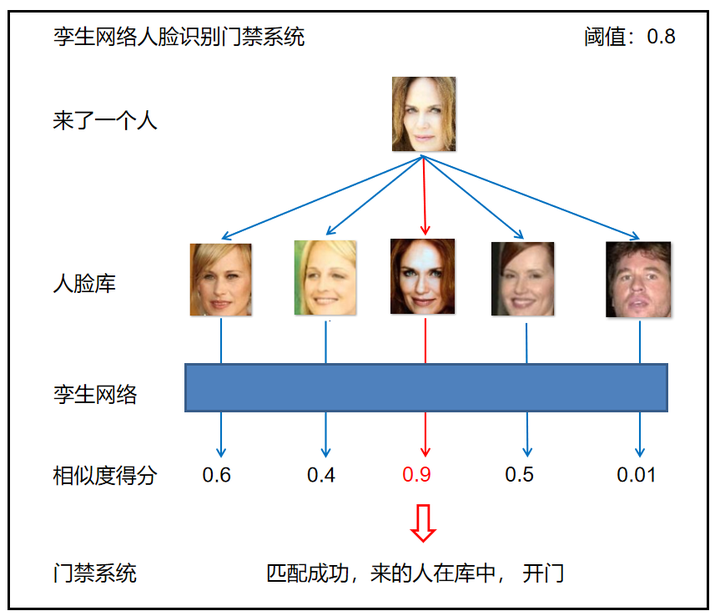
4、测试孪生网络
向训练模型发送两个输入以输出相似度分数。由于最后一层使用 sigmoid 激活函数,它输出一个范围在 0 到 1 之间的值。接近 1 的相似度得分意味着两个输入是相似的,接近 0 的相似度得分意味着两个输入不相似。选择一个相似性截止阈值。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
5、为什么姐妹网络要一样?
两个姐妹卷积网络的模型架构、超参数和权重必须相同。它确保它们各自的网络不会将两个极其相似的图像映射到非常不同的特征空间。也就是说加入输入的是不同的网络,即使输入的是一类两张图片,提取出来的特征也会天差地别,使得相似度不高。
添加图片注释,不超过 140 字(可选)
6、为什么要两个分支,一个基础网络不能搞定吗?
一个网路实现方法:Siamese net 其实名字很具有欺骗性,连论文都有欺骗性,很多人一听名字都以为有两个网络,至少看图就是这么想的。在代码实现的时候,甚至可以是同一个网络,不用实现另外一个,因为权值都一样。input1 和 input2 其实是前后分别输入得到两个向量后做计算,尽可能大或者小,然后loss直接更新网络。这样就没有“两个网络”,各种操作其实都在同一个网络下进行。同时在推理的时候也不需要两个网络同时进行,人脸库中的特征可以提前提取好等待匹配,需要进行推理的图片也只需要一个网络进行提取然后和库中的人脸特征进行匹配就行。
因此,两个网络只是思想,实现起来一个网络就够了。
两个网络实现方法:当然也是可以用两个一模一样的网络的,这样训练的时候会快些。上述训练前后两个图片是一对的,需要一前一后输入一个网络才能训练,两个网络就是同时输入网络进行训练,但是这样注意要共享权重,而一个网络则不用管这点。
一个网络是串行训练,两个网络是并行训练。但是推理的时候两个网络就浪费了一个网络,只需要一个网络。
添加图片注释,不超过 140 字(可选)
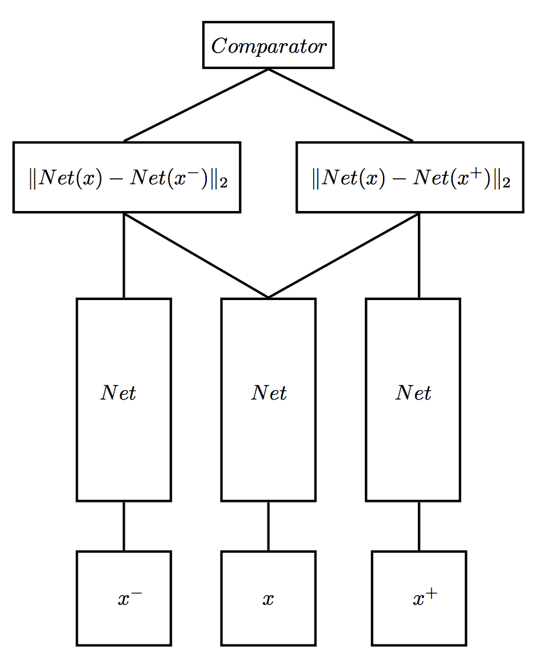
7、triplet network
在siamese网络之后,又提出了用triplet loss来学习图片的表示,大概思路如下:
-
拿到3张图片A, B, C。其中A,B相似,A,C不相似。
-
学到A, B, C 的表示,使得A,B之间的距离尽量小,而A,C之间的距离尽量大。
在 Triplet loss 中,我们使用数据的三元组而不是二元对。三元组由anchor、正样本和负样本组成。
在 Triplet loss 中,anchor和正样本编码之间的距离被最小化,而anchor和负样本编码之间的距离被最大化。
添加图片注释,不超过 140 字(可选)
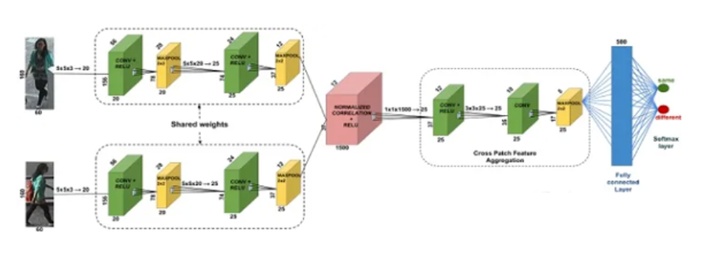
训练人脸识别网络的时候需要输入图像对来判断是不是同一个人,loss是两个样本之间的相似度。不过,光是相似度是不够的。不仅要将正负样本区分开,还要让类内更加紧凑(方差小),类间更加疏远(方差大)。triplet network将输入改成三个,训练的时候使用一个正例+两个负例,或者一个负例+两个正例。训练的目标就是同类别间的距离尽可能的小,不同类别间的距离尽可能的大。
添加图片注释,不超过 140 字(可选)
8、Siamese 神经网络的应用
(1)签名验证
(2)人脸识别
(3)指纹对比
(4)文本匹配
(5)目标跟踪
添加图片注释,不超过 140 字(可选)
9、总结
孪生网络可以看做分类模型,输出是0和1的分类。
只不过这种分类的对象是两张图片,而传统分类则是一张图片。
传统分类若想增加一类则需要大量这类图片数据集并重新训练,而孪生网络在训练结束后只需要一张对比图片放入比对库中即可,无需重复训练模型。
孪生网络用于特征提取的网络可以多种多样,比如VGG、Resnet等都可以作为特征提取网络。
基于特征比对的思想,人脸识别等应用也不一定要用孪生网络,传统的图像算法只要能获取人脸特征,并用一维向量表示这些特征,也是可以用的。
在目标跟踪领域需要进行下一帧的检测框目标与当前检测框目标的匹配,孪生网络可以计算这两帧目标的相似度,从而进行匹配。

添加图片注释,不超过 140 字(可选)
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————
|
萍水相逢逢萍水,浮萍之水水浮萍!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号