Yolov3-v5正负样本匹配机制
本文来自公众号“AI大道理”。
什么是正负样本?
正负样本是在训练过程中计算损失用的,而在预测过程和验证过程是没有这个概念的。
正样本并不是手动标注的GT。
正负样本都是针对于算法经过处理生成的框而言,而非原始的GT数据。
正例是用来使预测结果更靠近真实值的,负例是用来使预测结果更远离除了真实值之外的值的。
训练的时候为什么需要进行正负样本筛选?
在目标检测中不能将所有的预测框都进入损失函数进行计算,主要原因是框太多,参数量太大,因此需要先将正负样本选择出来,再进行损失函数的计算。
对于正样本,是回归与分类都进行,而负样本由于没有回归的对象,不进行回归,只进行分类(分类为背景)。
为什么要训练负样本?
训练负样本的目的是为了降低误检测率、误识别率,提高网络模型的泛化能力。通俗地讲就是告诉检测器,这些“不是你要检测的目标”。
正负样本的比例最好为1:1到1:2左右,数量差距不能太悬殊,特别是正样本数量本来就不太多的情况下。
如果负样本远多于正样本,则负样本会淹没正样本的损失,从而降低网络收敛的效率与检测精度。这就是目标检测中常见的正负样本不均衡问题,解决方案之一是增加正样本数。

1、YOLOv3正负样本定义
yolov3是基于anchor和GT的IOU进行分配正负样本的。
步骤如下:
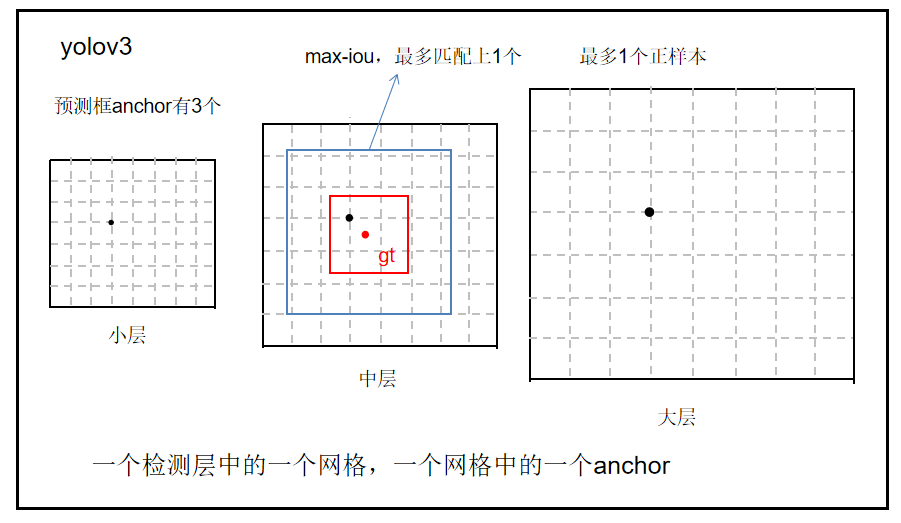
步骤1:每一个目标都只有一个正样本,max-iou matching策略,匹配规则为IOU最大(没有阈值),选取出来的即为正样本;
(每个目标只有一个正样本,就是这个目标先选择大中小三层中的一层,再在这层中选择一个网格,在网格上选择三个anchor中的一个)
步骤2:IOU<0.2(人为设定阈值)的作为负样本;
步骤3:除了正负样本,其余的全部为忽略样本
比如drbox(drbox就是anchor调整后的预测框)与gtbox的IOU最大为0.9,设置IOU小于0.2的为负样本。
那么有一个IOU为0.8的box,那么这个box就是忽略样本,有一个box的IOU为0.1,那么就是负样本。
步骤4:正anchor用于分类和回归的学习,正负anchor用于置信度confidence的学习,忽略样本不考虑。

2、YOLOv4正负样本定义
然而,在训练中,若只取一个IOU最大为正样本,则可能导致正样本太少,而负样本太多的正负样本不均衡问题,这样会大大降低模型的精确度。
因此,yolov4为了增加正样本,采用了multi anchor策略,即只要大于IoU阈值的anchor box,都统统视作正样本。
那些原本在YOLOv3中会被忽略掉的样本,在YOLOv4中则统统成为了正样本,这样YOLOv4的正样本会多于YOLOv3,对性能的提升也有一些帮助。
yolov4的GT需要利用max iou原则分配到不同的预测层yolo-head上去,然后在每个层上单独计算正负样本和忽略样本。不存在某个GT会分配到多个层进行预测的可能性,而是一定是某一层负责的。


3、YOLOv5正负样本定义
yolov3的做法是一个gt标签框只能匹配到大中小三层中的某一层(a),某一层中某一个网格(b),某个网格中三个anchor中的某一个(c)。这个anchor就是训练输出的,是先验框经过调整参数的anchor,这个框与标签gt匹配上为正样本,匹配不上为负样本。
yolov4仅仅是这个框与标签gt匹配上的量变多了,从1个变成多个。
yolov5觉得yolov4的做法正样本还是太少了,于是继续增加正样本的数量。
如何增加?有三大方法,这三种方法分别对应yolov3的abc三个地方。
(1) 跨分支预测(a)
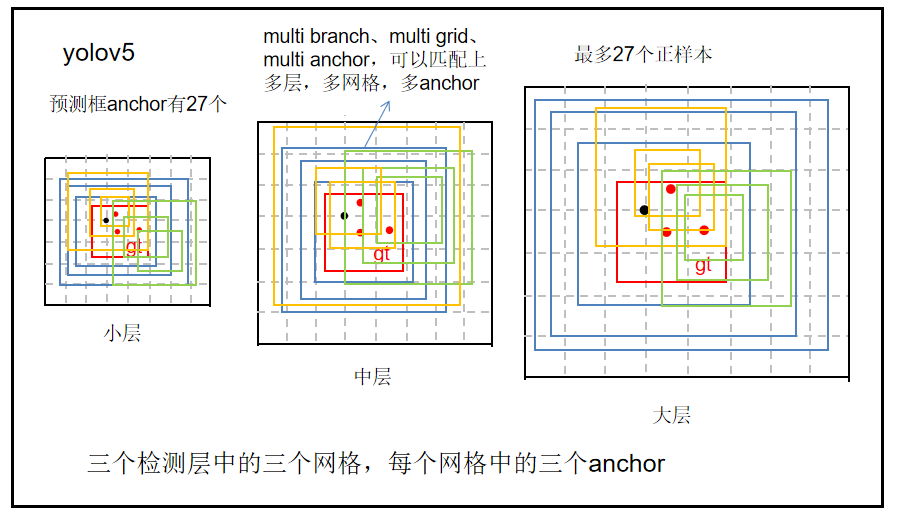
跨分支预测就是一个GT框可以由多个预测分支来预测,重复anchor匹配和grid匹配的步骤,可以得到某个GT 匹配到的所有正样本。

即这个gt可以由大中小中的几个分支负责与训练输出进行匹配。最多三个。
(2) 跨grid预测(b)
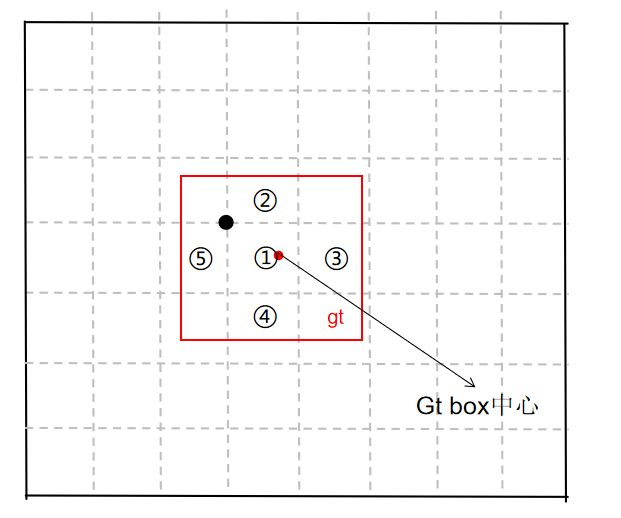
假设一个GT框落在了某个预测分支的某个网格内,则该网格有左、上、右、下4个邻域网格,根据GT框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个GT框可以由3个网格来预测。
例子:
GT box中心点处于grid1中,grid1被选中,为了增加增样本,grid1的上下左右grid为候选网格,因为GT中心点更靠近grid2和grid3,grid2和grid3也作为匹配到的网格。
GT再与grid2和grid3上的三个anchor进行匹配。
即这个gt可以由大中小中的几个分支负责,各个分支可以由多个网格负责,这些网格上的anchor通过训练即可调整参数,形成输出的anchor,这个anchor再与gt进行匹配。最多三个网格。加上3分支,总共9个。
(3) 跨anchor预测(c)
每个层级每个格子有三个anchor,yolov3、yolov4只能匹配上三个中的一个,而yolov5可以多个匹配上。
具体方法:
不同于IOU匹配,yolov5采用基于宽高比例的匹配策略,GT的宽高与anchors的宽高对应相除得到ratio1,anchors的宽高与GT的宽高对应相除得到ratio2,取ratio1和ratio2的最大值作为最后的宽高比,该宽高比和设定阈值(默认为4)比较,小于设定阈值的anchor则为匹配到的anchor。

即一个gt可以由多个分支中的多个网格中的多个anchor同时负责。
总共有3*3*3=27个anchor负责一个gt,这样正样本的数量将大大提升。
yolov3是一个目标最多1个正样本,yolov4是一个目标最多3个正样本,yolov5一个目标最多可以有27个正样本。
yolov5正负样本分配步骤:
步骤1:对每一个GT框,分别计算它与9种anchor的宽与宽的比值、高与高的比值;
步骤2:在宽比值、高比值这2个比值中,取最极端的一个比值,作为GT框和anchor的比值;
步骤3:得到GT框和anchor的比值后,若这个比值小于设定的比值阈值,那么这个anchor就负责预测GT框,这个anchor的预测框就被称为正样本,所有其它的预测框都是负样本。

4、总结
问题1:为什么是基于anchor和gt真实标签呢?不是应该是网络输出框和gt的匹配程度吗?
答:训练输出什么呢?训练输出和预测输出是类似的。
预测输出很多检测框,这些检测框经过了nms,所以只剩下一些。
而训练的时候没有经过nms,所以训练的输出框有很多。
这些框到底是什么呢?这些框其实就是anchor。
就是设置的9个先验框anchor通过调节参数得到的预测框。
所以说,anchor和gt的真实标签匹配不是先验框和真实标签的匹配,而是经过参数调节后的预测框和真实标签的匹配。
(确定gt属于哪个anchor负责预测的时候用的是先验框,确定正负样本的时候用的是先验框经过调整后的预测框)

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号