AI大视觉(十四) | Yolo v4是如何进行改进的?
本文来自公众号“每日一醒”
YOLO V4就是筛选了一些从YOLO V3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并以YOLO V3为基础进行改进的目标检测模型。
YOLO V4在保证速度的同时,大幅提高模型的检测精度。

![]() YOLOV4的改进
YOLOV4的改进
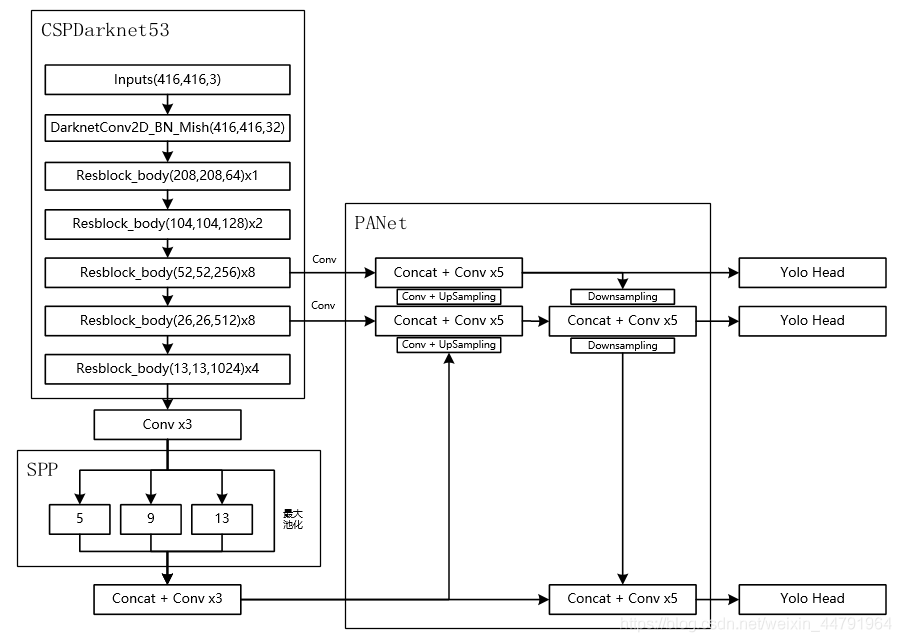
1、backbone:CSPDarkNet53
2、neck:SPP+PAN
3、head:YOLOv3
4、DropBlock正则化
5、数据增强:CutMix、马赛克(Mosaic)、自对抗训练
6、训练用到的小技巧:Label Smoothing平滑、学习率余弦退火衰减
7、激活函数:使用Mish激活函数
8、损失函数:CIOU
![]()
![]() backbone
backbone
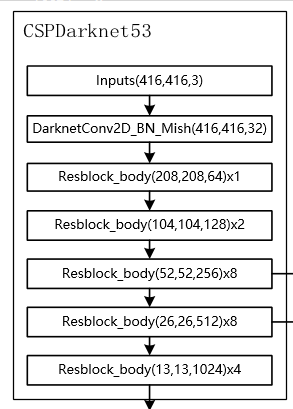
主干特征提取网络Backbone的改进点:
DarkNet53 => CSPDarkNet53
![]()

![]()
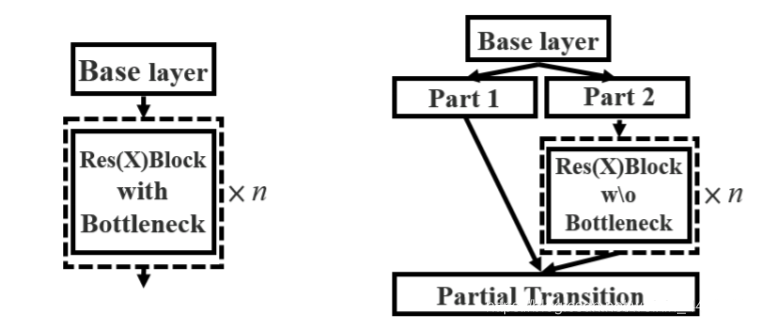
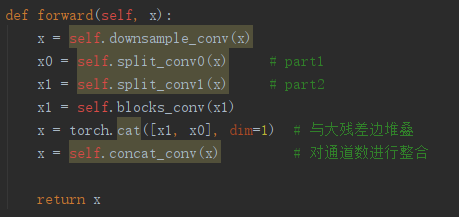
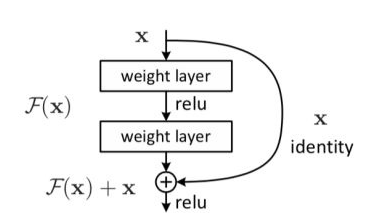
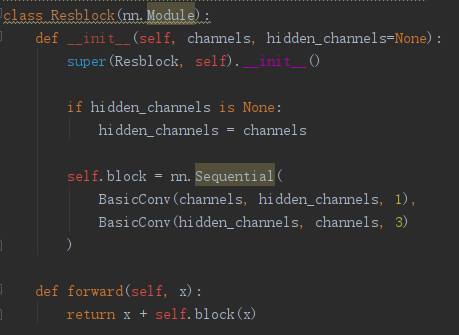
CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分。
主干部分继续进行原来的残差块的堆叠。
另一部分则像一个残差边一样,经过少量处理直接连接到最后。
因此可以认为CSP中存在一个大的残差边。
对于整个CSPdarknet的结构块,就是一个大残差块+内部多个小残差块。
大残差:
![]()
![]()
小残差:
![]()
![]()
![]() spp
spp
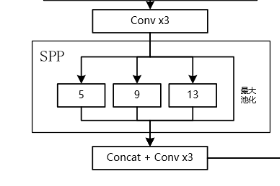
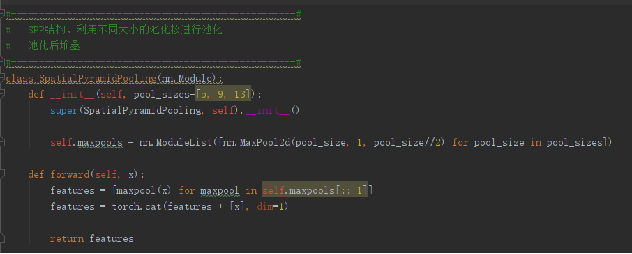
SPP结构是在CSPdarknet53的最后一个特征层的卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)
spp能够极大地增加感受野,分离出最显著的上下文特征。
SPP结构从细密和粗糙级别上分割图像,然后融合局部的特征。
SPP有3个优势:
任任意size和scale输入下,产生固定的输出特征。
使用多级spatial bins(多个尺寸的pooling),多级pooling对于物体形变具有鲁棒性。
SPP的优势,可以让我们:1,生产整个图片的特征,用于测试;2,允许我们在各种size和scale下训练网络,可以增加样本个数,防止过拟合。(类似数据增益)
![]()
![]()
![]() PANet
PANet
PANet的整体结构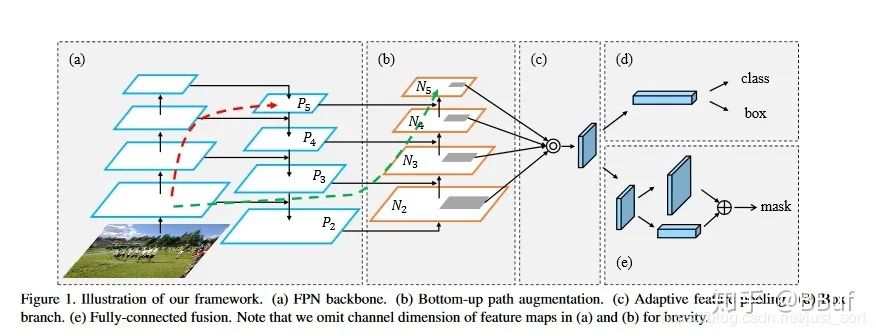
![]()
可以看到PANet的结构的组成部分就是我们讲的FPN,Bottom-Up Path Augmentation,Adaptive Feature Pooling,Fully-Connected Fusion这四个小模块。
Bottom-up Path Augemtation的提出主要是考虑到网络的浅层特征对于实例分割非常重要,浅层特征中包含大量边缘形状等特征,这对实例分割这种像素级别的分类任务是起到至关重要的作用的。
因此,为了保留更多的浅层特征,论文引入了Bottom-up Path Augemtation。
红色的箭头表示在FPN中,因为要走自底向上的过程,浅层的特征传递到顶层需要经过几十个甚至上百个网络层,当然这取决于BackBone网络用的什么,因此经过这么多层传递之后,浅层的特征信息丢失就会比较严重。
绿色的箭头表作者添加了一个Bottom-up Path Augemtation结构,这个结构本身不到10层,这样浅层特征经过原始FPN中的横向连接到P2然后再从P2沿着Bottom-up Path Augemtation传递到顶层,经过的层数不到10层,能较好的保存浅层特征信息。

![]()
![]()
![]() head
head
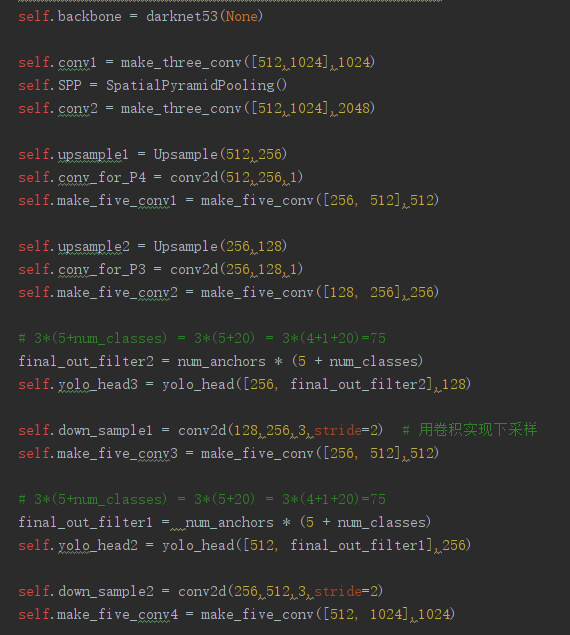
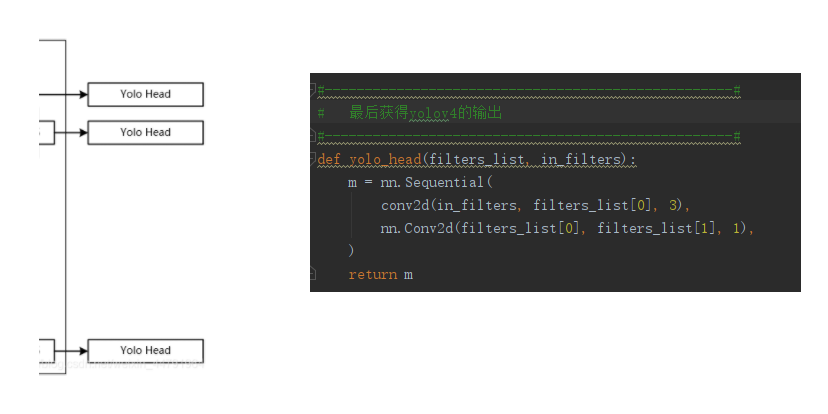
head本质上就是3*3的卷积和1*1的卷积。
其中3*3的卷积是包括标准化和激活函数的,只要进行特征整合。
而1*1的卷积仅仅是卷积,它获取到的特征转化为预测结果。
![]()
![]() 激活函数
激活函数

![]()
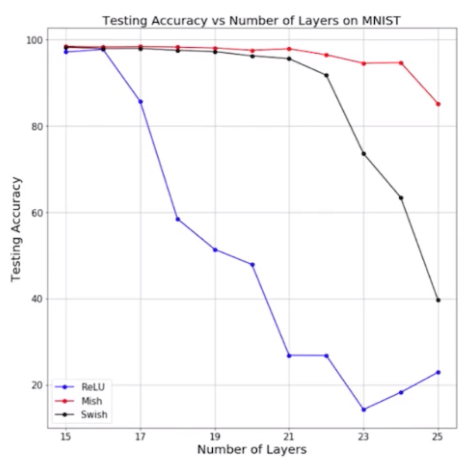
为什么用mish?
随着神经网络层数的增加,mish激活函数表现最好,测试准确率下降最少。
![]()
![]() 数据增强
数据增强
CutMix数据增强和马赛克(Mosaic)数据增强
CutMix:
两个图片,一个图片剪切后放到另外一个图片上。

![]()
Mosaic:
合并4张图片,跨越上下文,相当于小目标的数据增加了。

![]()
![]() 自对抗训练(Self-Adversarial training)
自对抗训练(Self-Adversarial training)
对抗训练:将生成的对抗样本加入到训练集中去,做一个数据增强,让模型在训练的时候就先学习一遍对抗样本。
一张图上,让神经网络反向更新图像,对图像做改变扰动,然后在这个图像上训练。

![]()
![]() 标签平滑
标签平滑
label smoothing就是一种正则化的方法而已,让分类之间的cluster更加紧凑,增加类间距离,减少类内距离,避免over high confidence的adversarial examples。

![]()
![]() DropBlock正则化
DropBlock正则化
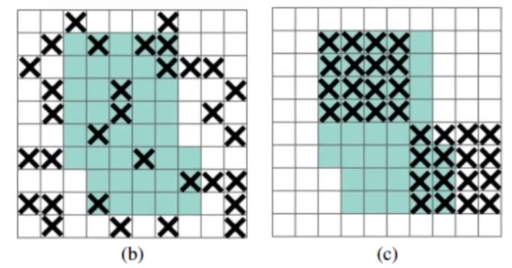
dropout:用于全连接层,以一定概率随机将输出神经元置0,BP阶段不更新对应神经元。
dropblock:(c)作用于每一个block,对(b)来说,drop掉的像素的信息可以通过相邻像素学习得到,而(c)drop掉一块区域,会迫使网络学习其他区域信息,更有利于提取全局特征,效果更好,所以本方法称为dropblock。
可以看到dropblock和random erase等有类似之处,不同在于random erase作用于输入图像,而dropblock作用于网络中间层特征图。
![]()
![]() 学习率余弦退火衰减
学习率余弦退火衰减
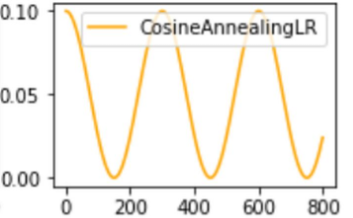
使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一点,而余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。
余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。
这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
有利于跳出局部最优解。
![]()
![]() CIOU
CIOU
DIOU考虑到了两个检测框的中心距离。而CIOU考虑到了三个几何因素,分别为:
(1)重叠面积
(2)中心点距离
(3)宽高比
CIOU的公式定义如下:
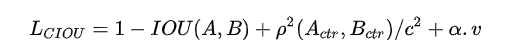
![]()
这个惩罚项作用就是控制预测框的宽高能够尽可能快速地与真实框的宽高接近。
![]() 总结
总结
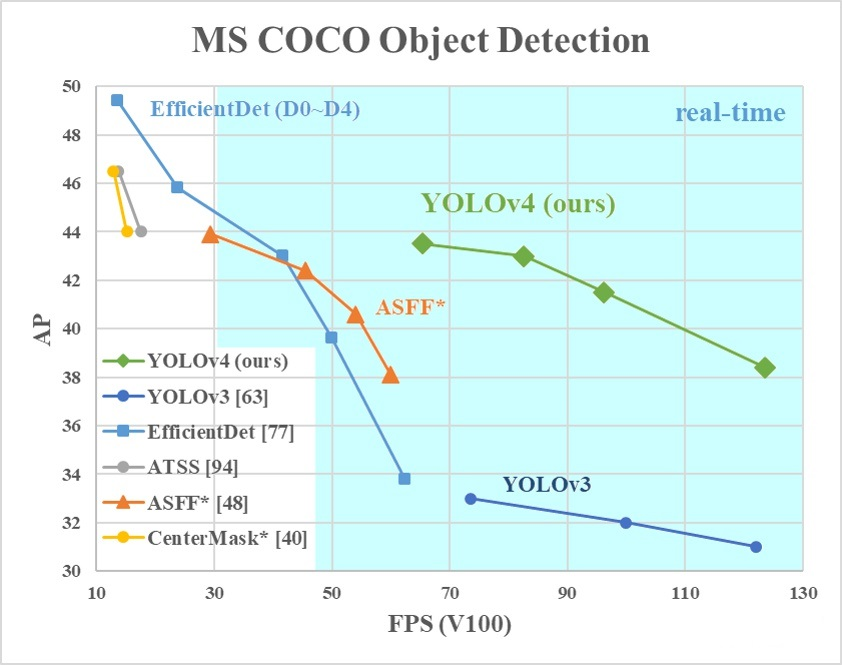
YOLO V4就是筛选了一些从YOLO V3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并以YOLO V3为基础进行改进的目标检测模型。
YOLO V4在保证速度的同时,大幅提高模型的检测精度。
![]()

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“每日一醒”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号