
AI大视觉(十一) | Yolo v3 如何进行训练?
本文来自公众号“AI大道理”
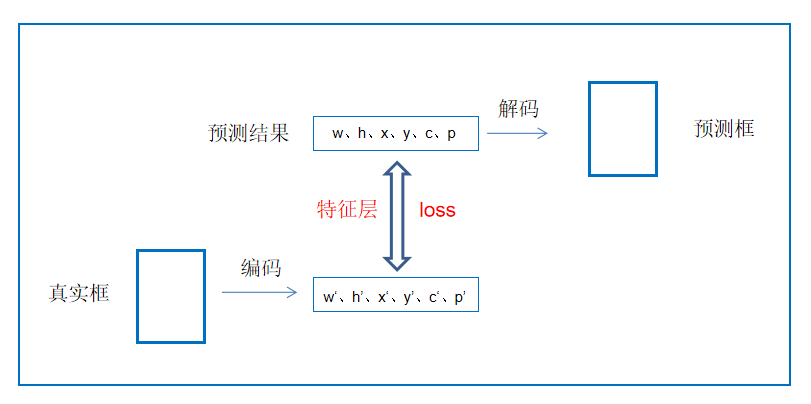
yolov3训练的loss是在特征层上进行求解的。
所以不管是预测值,还是真实值都要映射到特征层上。
这是一个双向奔赴的过程。

![]() loss求解
loss求解
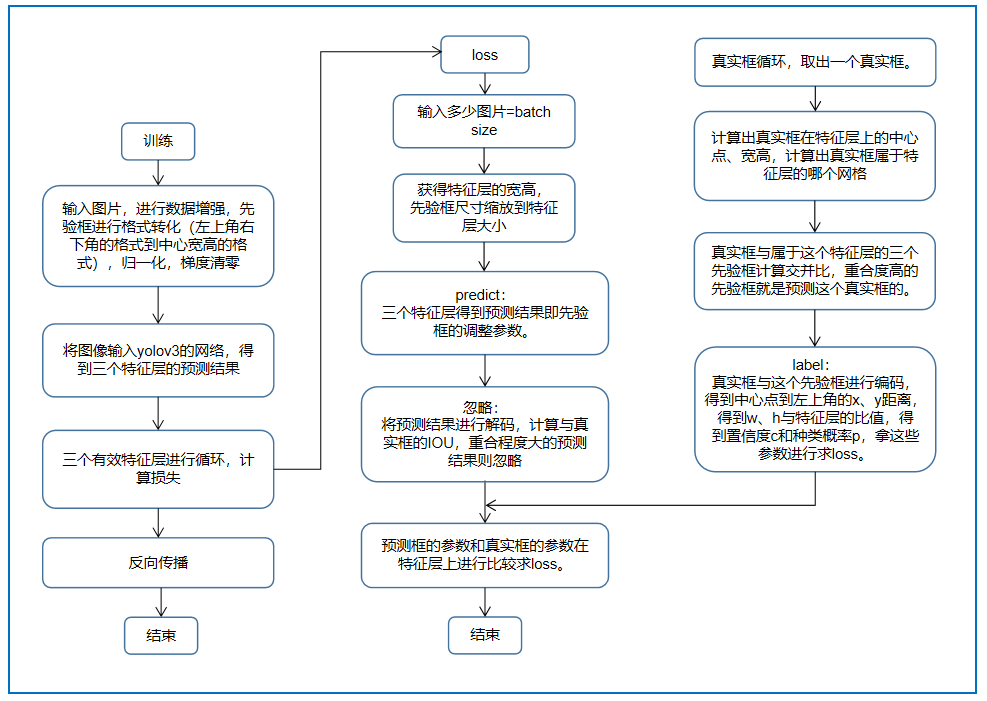
(1)输入图片进行数据增强。
(2)将图片输入yolov3网络获得三个特征层的预测结果。
(3)三个有效特征层循环计算损失。
(4)反向传播进行训练。
![]()
![]()
由于YOLOv3将分类预测改为回归预测,分类损失函数便换成了二值交叉熵损失函数。
Loss 要计算:
-
中心点的 Loss
-
宽高的 Loss
-
置信度的 Loss
-
目标类别的 Loss
-
![]()

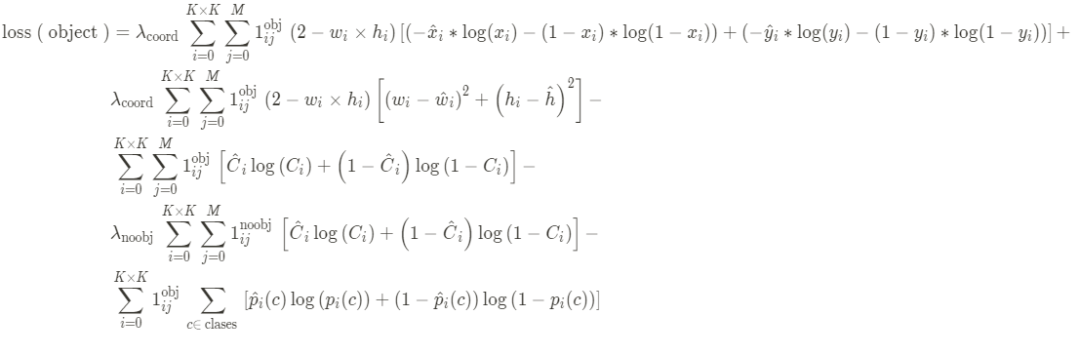
其中:
宽高w、h的loss使用均方差损失函数。
中心点的坐标x、y的loss、置信度c的loss和目标类别p的loss使用交叉熵损失函数。
![]()
解释:
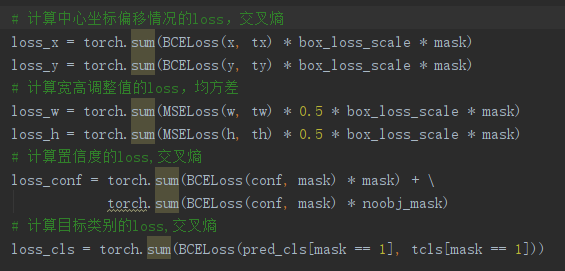
对于目标类别obj 的loss,Logistic回归正好方差损失和交叉熵损失的求导形式是一样的,都是output - label的形式。也就是说,本来这里应该用(二元分类的)交叉损失熵的,不过作者在代码里直接用方差损失代替了。
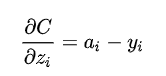
![]()
对于中心点的坐标x、y的 loss,DarkNet官方实现的YOLOV3里面坐标损失用的是BCE Loss,而YOLOV3官方论文里面说的是MSE Loss。
对于宽高w、h的loss是MSE Loss,因为没有经过sigmoid,而x、y是BCE Loss因为经过了sigmoid。
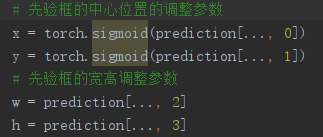
![]()
![]() 预测值
预测值
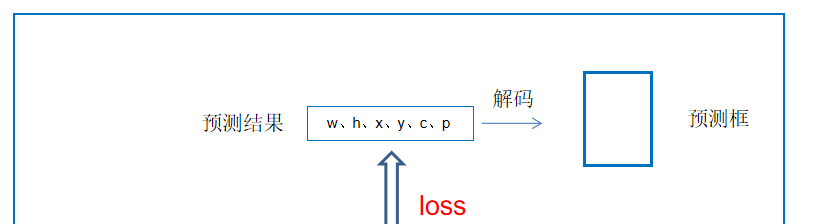
(1)三个有效特征层进行循环计算损失。
(2)获得特征层的宽高,先验框尺寸缩放到特征层大小。
利用原来图片尺寸和特征层的比例进行缩放。
(3)特征层获得预测结果,即先验框的调整参数。
(4)将预测结果解码与真实框计算IOU,重合程度大的预测结果则忽略。
因为这是属于预测比较准确的框,作为负样本不合适。
(5)预测框的参数与真实框的参数在特征层上进行比较求loss。
![]()
![]() 真实值
真实值
(1)真实框循环,取出其中一个真实框。

![]()
.xml:
使用labelImg软件进行标注得到.xml文件,两个目标是使用左上角和右下角的格式的。

![]()
.xml->.txt:

![]()
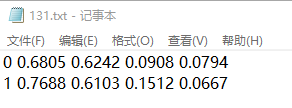
label:
经过转化,中心点以及宽和高的标注信息,并且进行归一化,四个值即是归一化后保留4位有效数字的x,y,w,h。
![]()
(2)原始的真实框数值是0-1之间,需要乘上先验框的宽高,才可以转化成特征层的形式,才可以把它和先验框进行对比(暂时不是与预测框对比)
label*13:
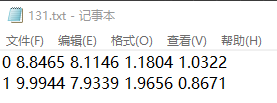
![]()
(3)计算真实框在特征层上的中心点、宽高,计算真实框属于特征层的哪个网格。
13*13个网格中的哪个,就是根据真实框的位置确定这个真实框由哪个网格负责预测。
网格的左上角负责预测,所以只要中心点坐标去掉小数点保留整数的数值就是了。
如上面的两个真实框在13*13的特征层中由(8,8)与(9,7)这两个网格负责预测。
当然,每个网格有三个先验框。
(4)真实框与属于这个特征层的3个先验框计算交并比,与真实框重合度最大的先验框就是这个真实框的来源框。
(5)编码得到真实框的参数。
与解码公式相反。
其中:
中心偏差真实参数=真实框中心-网格左上角
宽高真实参数=log(真实框的宽高/先验框的宽高)
解码公式:
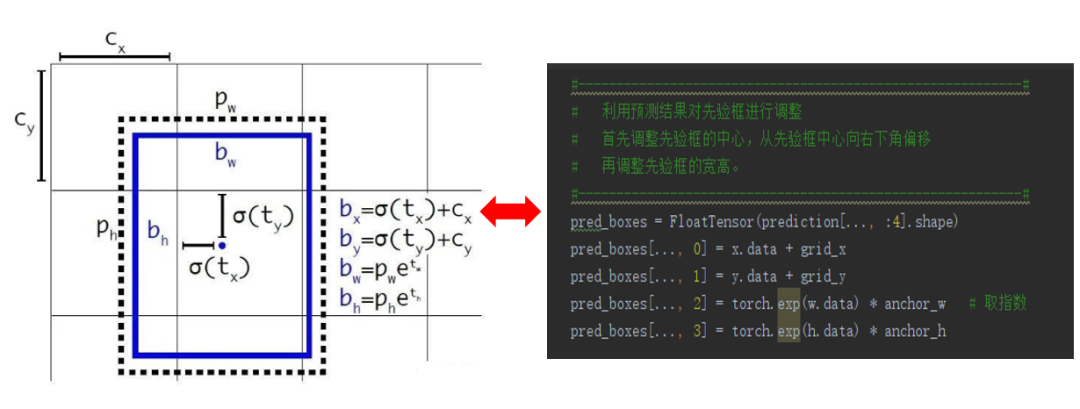
![]()
编码公式:
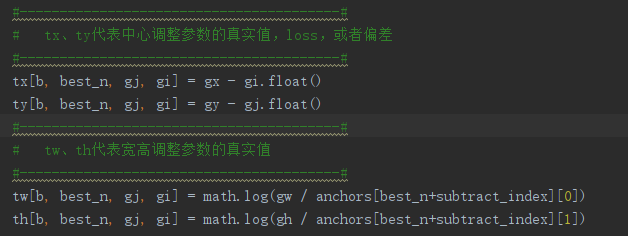
![]()
(6)真实框的参数与预测框的参数在特征层上进行比较求loss。
(7)继续取出真实框,进行相同操作。
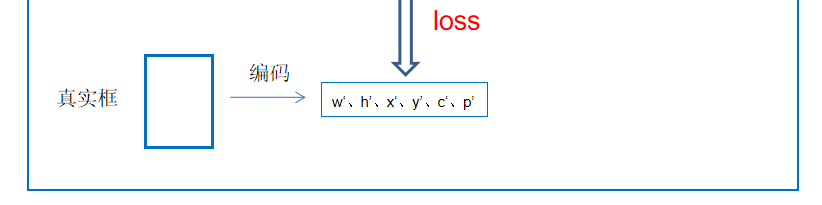
![]()
![]() 总结
总结
yolov3训练的loss是在特征层上进行求解的。
所以不管是预测值,还是真实值都要映射到特征层上。
这是一个双向奔赴的过程。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号