AIBigKaldi(十三)| Kaldi的三音子模型训练(下)(源码解析)
本文来自公众号“AI大道理”。
程序acc-tree-stats累积好了构建决策树所需的统计量,程序cluster-phones和compile-questions自动生成好了构建决策树所需的问题集,也准备好了roots.int文件。
接下来可以开始构建决策树,对三音素GMM的状态进行绑定。
以kaldi的thchs30为例。

![]() 5 三音子模型训练
5 三音子模型训练
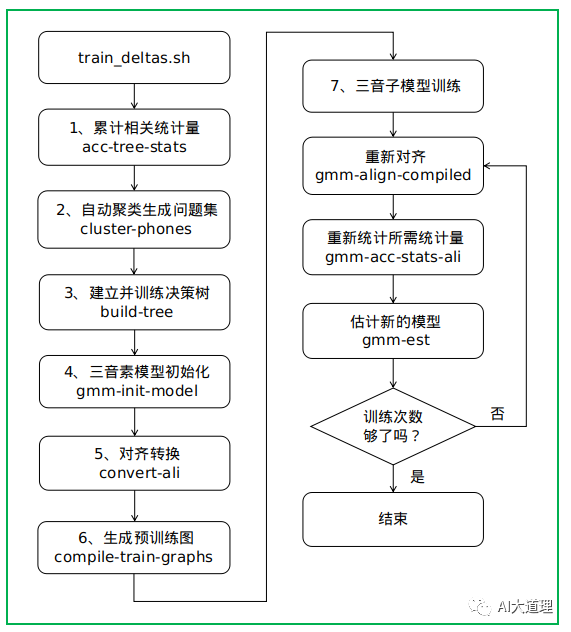
过程之道:
![]()
![]() 5 .3 建立决策树
5 .3 建立决策树
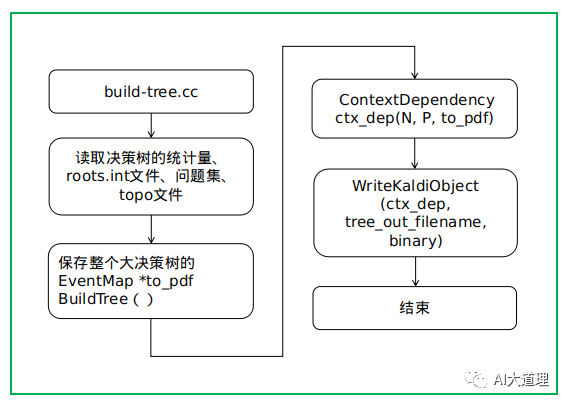
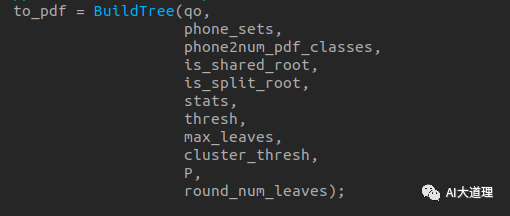
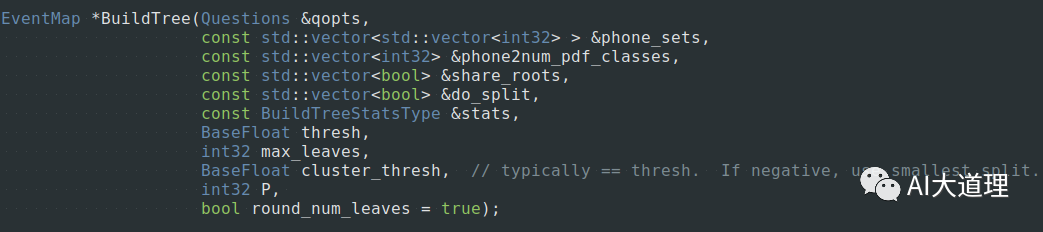
5.3.1 build-tree.cc
给定EventType(三音素+HMM state-id),通过决策树得到这个EventType对应的p.d.f.的pdf-id。
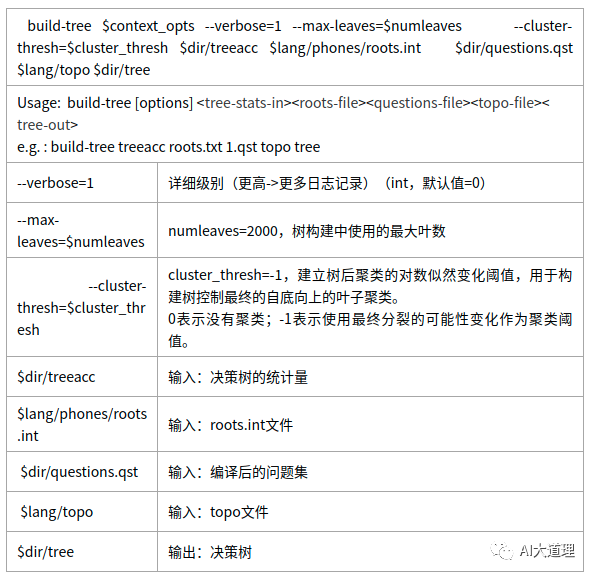
功能:
建立决策树tree。
输入:累积的统计量treeacc、问题集questions.qst、roots.int、topo
输出:决策树tree
源码解析:

![]()
![]()
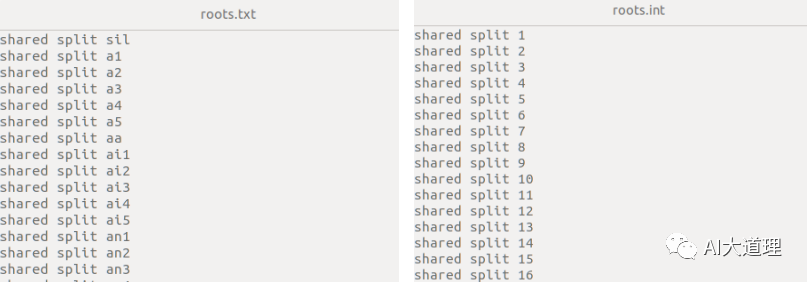
其中roots.int:
roots文件指明在决策树的聚类过程中,哪些音素应该共享树根。
对放在roots文件同一行的音素共享一个树根,并且roots的每一行需指明下述两件事。
1)shared or not-shared
roots文件中有两种“共享”。
一种是roots文件中位于同一行的音素共享同一个决策树。
另一种是在每一行前指定”shared”,对不同HMM状态共享同一个决策树。
对一个音素的每个HMM状态都应该建立一个决策树:若一个音素都包含3个HMM状态,则其需要建立三个决策树。
若指定”shared”,则Kaldi使三个HMM状态上的决策树共享同一个树根。
若指定”not-shared”,则Kaldi为三个HMM状态分别建立决策树树根。
2)split or not-split
“split”或”not-split”说的是,是否应该对当前的决策树树根进行划分。
如果该行指明”split”,则对决策树进行划分;如果该行指明”not-split”,则对该决策树不进行任何划分。
![]()
a1共享一个决策树根,并且该行音素的不同HMM状态也共享(”shared”)一个决策树根。
程序过程:
![]()
函数解析:
![]()
![]()
函数过程:
![]()
函数中的函数:
-
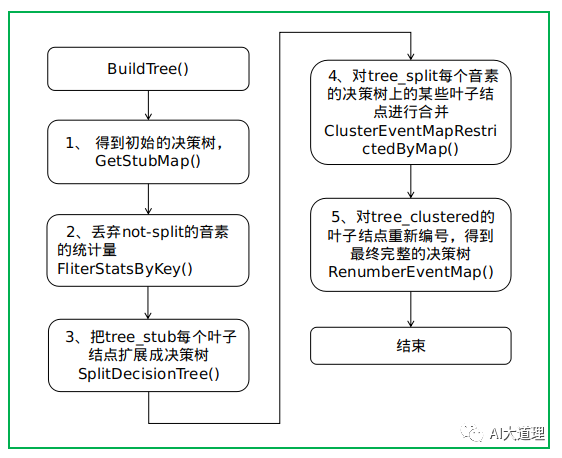
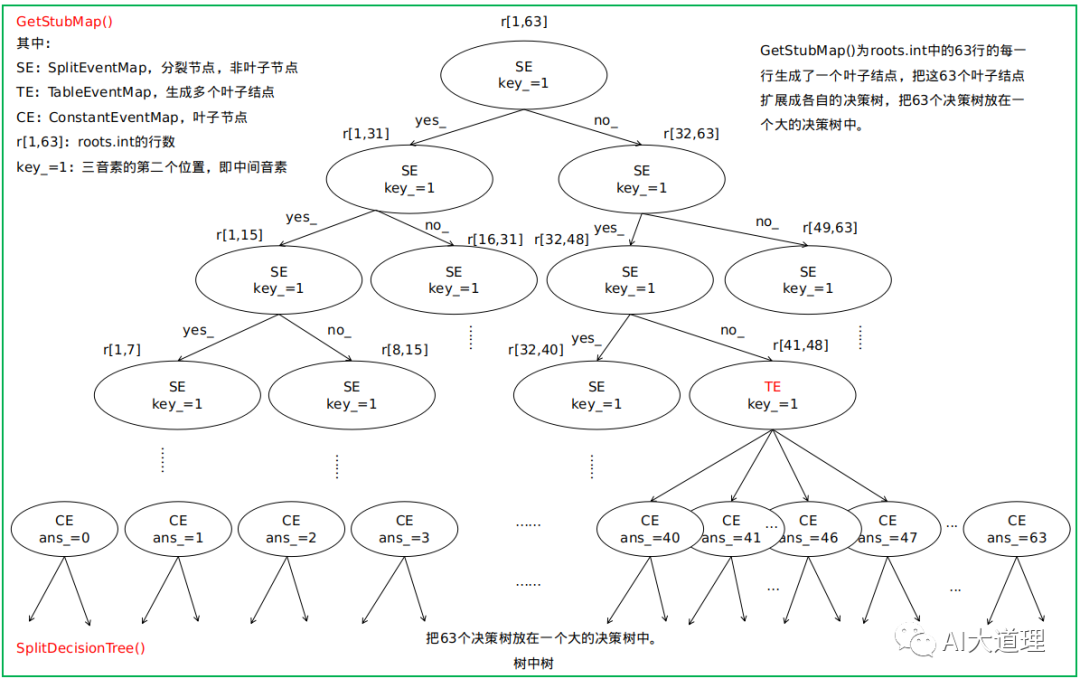
GetStubMap()
得到初始的决策树EventMap *tree_stub,也就是扩展前的决策树。
扩展前的决策树的一个叶子结点对应roots.int中的一行的决策树的树根。
假如有63个音素需要构建63个决策树。(thchs30中为218个)
Kaldi决定这63个决策树也用一棵决策树D表示——D有63个叶子结点,每个叶子结点都作为63个决策树的树根。
灵魂的拷问:这是在做什么呢?
答:其实可以不这么做,单独保存63个决策树也可以,但是这样显然不方便,因此用树的结构把这些树保存在一颗树的叶子节点上。
分裂就是简单的对半分,只是为了让数据一个一个排列保存。
![]()
-
FliterStatsByKey()
只把在roots.int中指定为split的音素的统计量留下,把指定为not-split的音素的统计量丢弃。
因为roots.int里面都是split,所以这一步什么都没做。
-
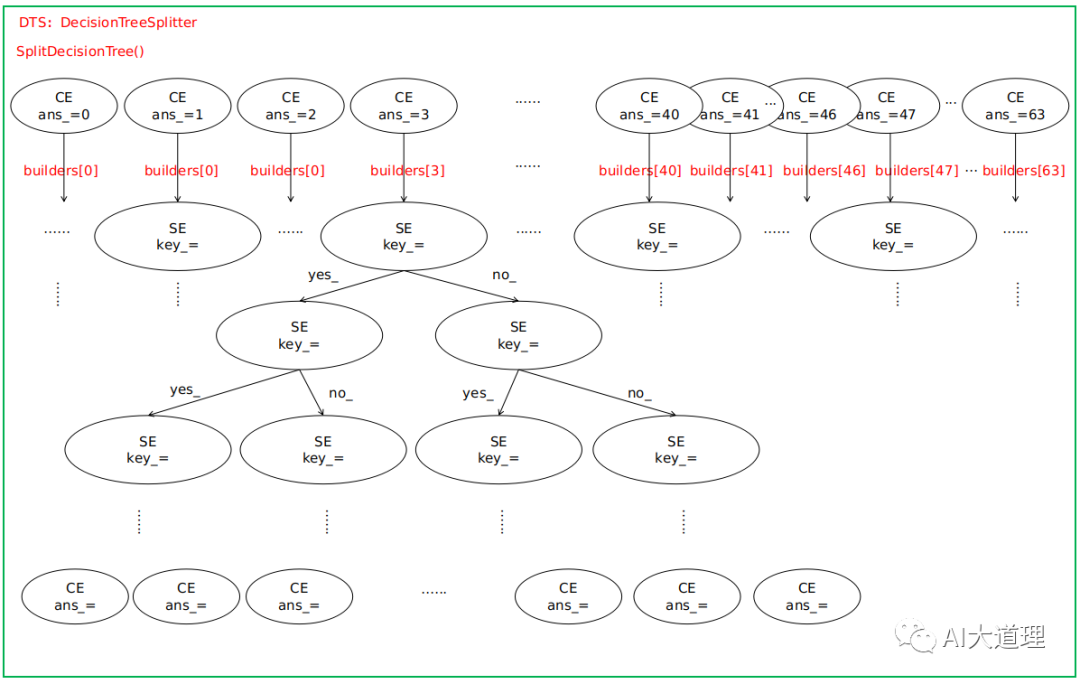
SplitDecisionTree()
对tree_stub进行扩展,生成整个大的决策树EventMap *tree_split:把tree_stub的每个叶子结点扩展成决策树,对每一个音素生成实际的决策树。
参数input_map就是扩展前的决策树tree_stub,其一个叶子结点表示一个音素。(确切来说是roots.int中同一行的音素集合,但因为其共享同一个决策树,暂且称该音素集为一个音素)。
对tree_stub的每个叶子结点、也就是每个音素构建一棵决策树,实现状态绑定,减少GMM参数。
对决策树持续进行划分,直到总的叶子结点数目到达max_leaves,或者所有叶子结点中的最优划分带来的最大似然提升都小于thresh。
![]()
对三音素进行问问题:
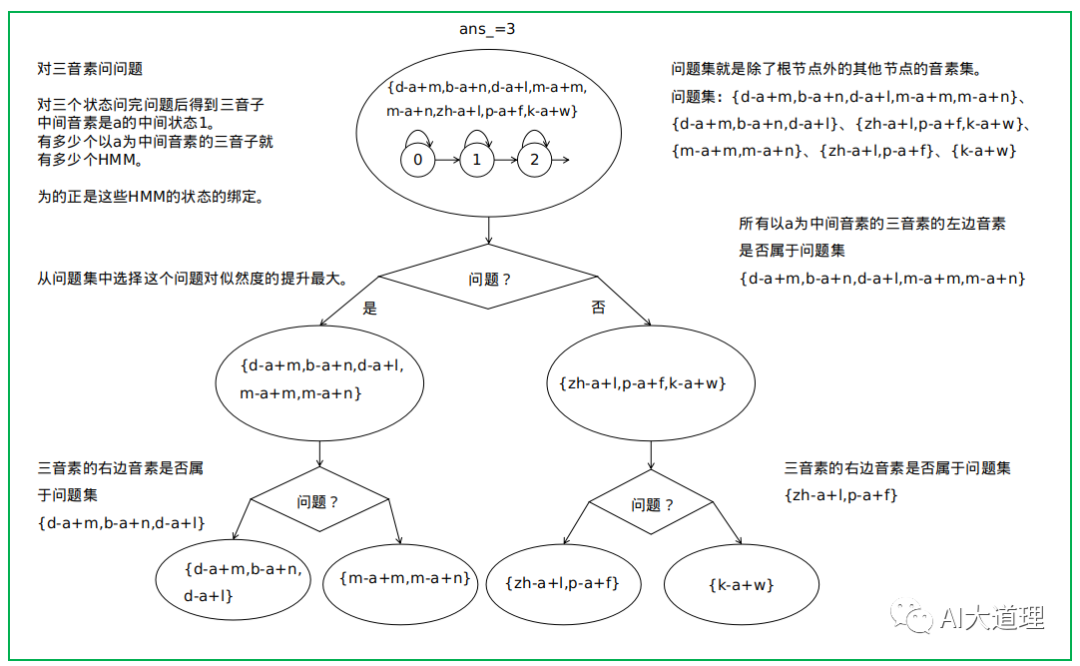
![]()
-
ClusterEventMapRestrictedByMap()
对tree_split每个音素的决策树上的某些叶子结点进行合并,得到EventMap *tree_clustered。
合并前的CE均有不同的answer_,也就是pdf-id不同,合并后某些CE的answer_相同,相同则说明这些叶子结点合并了。
-
RenumberEventMap()
对tree_clustered的叶子结点重新编号(从0开始),得到EventMap *tree_renumbered,这就是我们最终得到的完整的决策树。
把tree_renumbered返回到主程序build-tree。
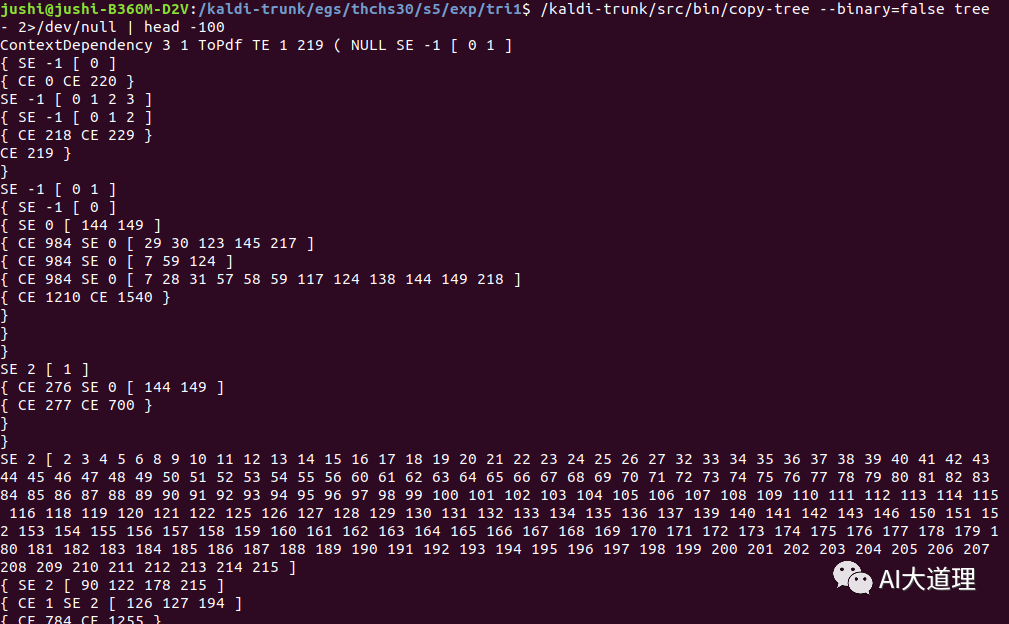
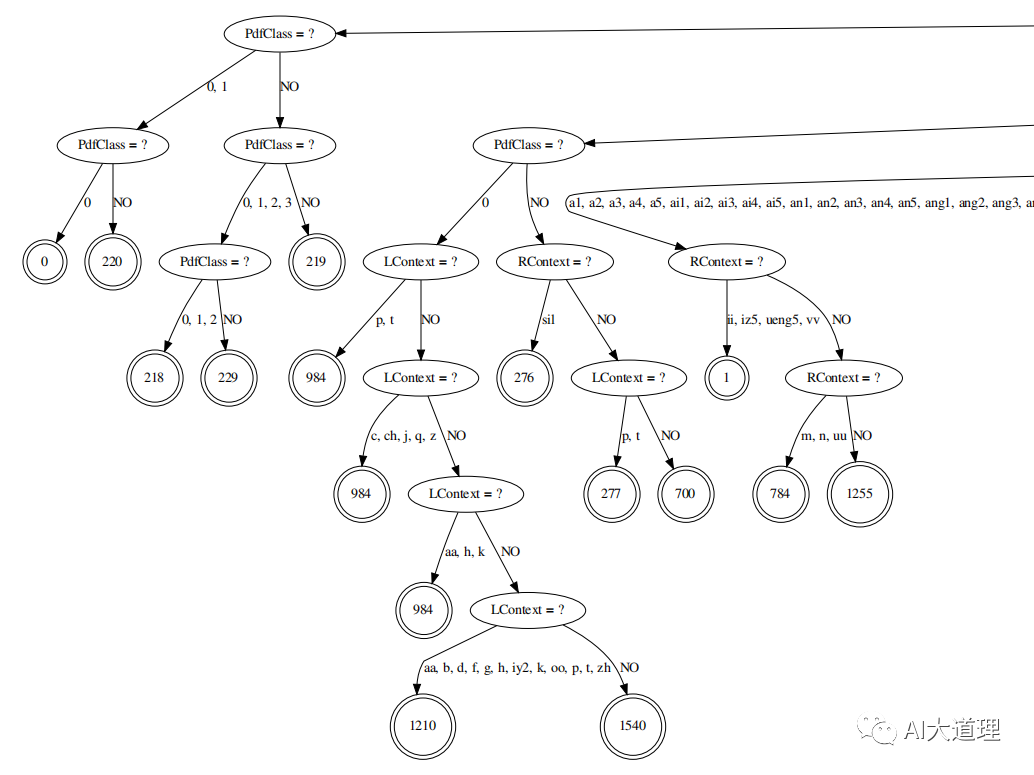
决策树构建结果:
![]()
说明:
ContextDependency 3 1:表示音素宽度N_(=3)、中间音素位置P_(=1)
TE 1 219:TE表示决策树树根。1表示对中间音素进行划分,219表示划分完后总共有219个结点。
实际上我们只有218个音素(1-218),但代码中计算的是0-218,所以总共有219个结点。NULL就是0对应的结点。
SE -1 [0 1]:SE表示决策树的非叶子结点,-1表示该结点是对hmm state进行提问;[0 1]表示提的问题是”该三音素的hmm state是0或1吗“。
CE 0:CE表示决策树的叶子结点 0表示该叶子结点的编号(在kaldi中叫pdf-id)
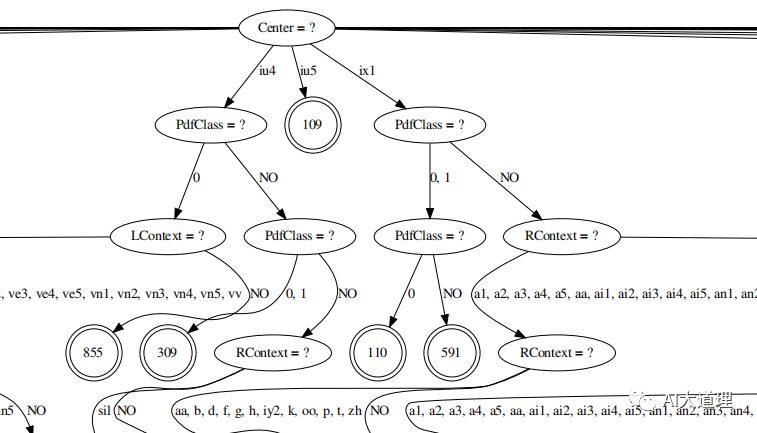
使用命令查看决策树:
/kaldi-trunk/src/bin/draw-tree phones.txt tree|dot -Tpdf >tree.pdf
![]()
![]()
![]() 5 .4 三音子模型初始化
5 .4 三音子模型初始化
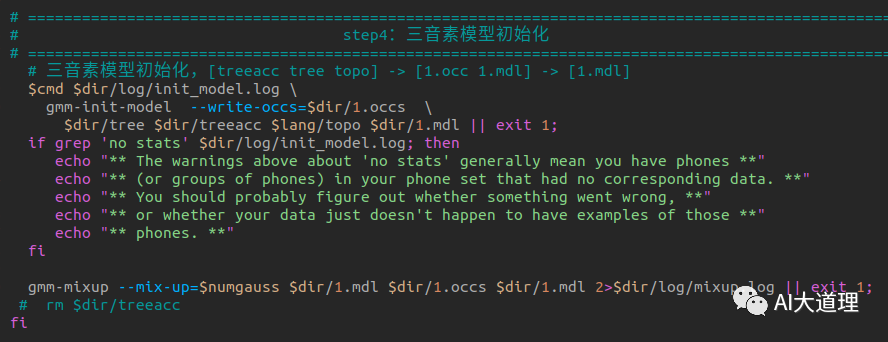
5.4.1 gmm-init-model.cc
功能:
使用决策树tree和决策树统计量treeacc初始化GMM。
源码解析:
![]()

![]()
5.4.2 gmm-mixup.cc
功能:
进行高斯混合、高斯合并。
源码解析:

![]()
![]() 5 .5 对齐转换
5 .5 对齐转换
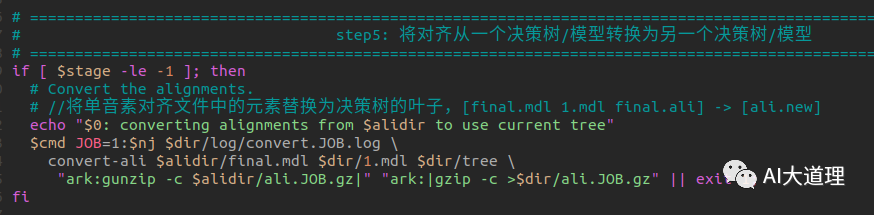
convert-ali.cc
将路线从一个决策树/模型转换为另一个决策树/模型。
灵魂的拷问:为什么需要进行转换?
答:每次进行三音子训练都会重新生成tree文件以达到最合理的聚类绑定效果。
这样逻辑模型到物理模型的映射关系会发生改变,需要将原有对齐中的信息进行转换保证与新tree文件一致。
源码解析:
![]()

![]()
![]() 5 .6 生成预训练图
5 .6 生成预训练图
compile-train-graphs.cc

![]()
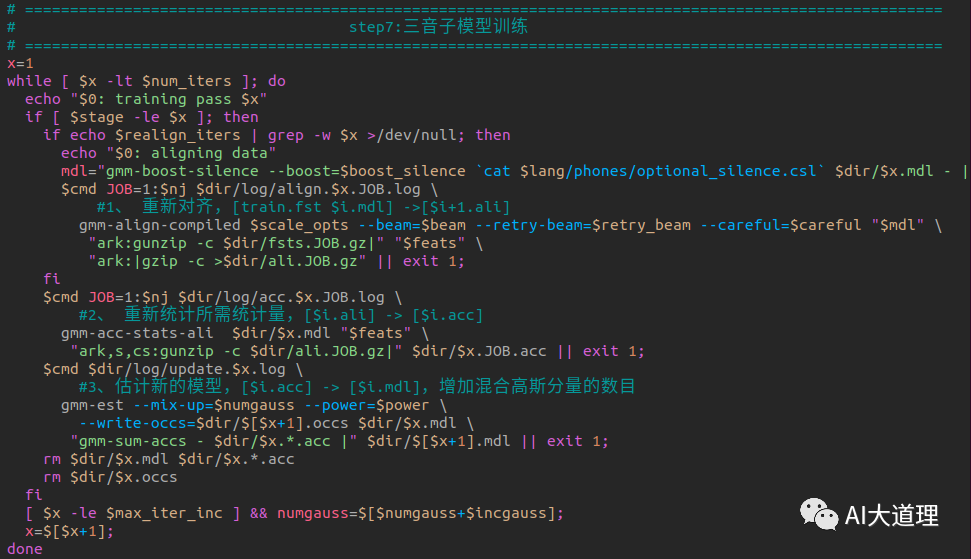
![]() 5 .7 三音子模型训练
5 .7 三音子模型训练
过程之道:
初始化三音素模型->生成训练图HCLG.fst->对标签进行初始化对齐->统计估计模型所需的统计量->估计参数得到新模型->迭代训练->最后的模型final.mdl。
![]()
训练过程:
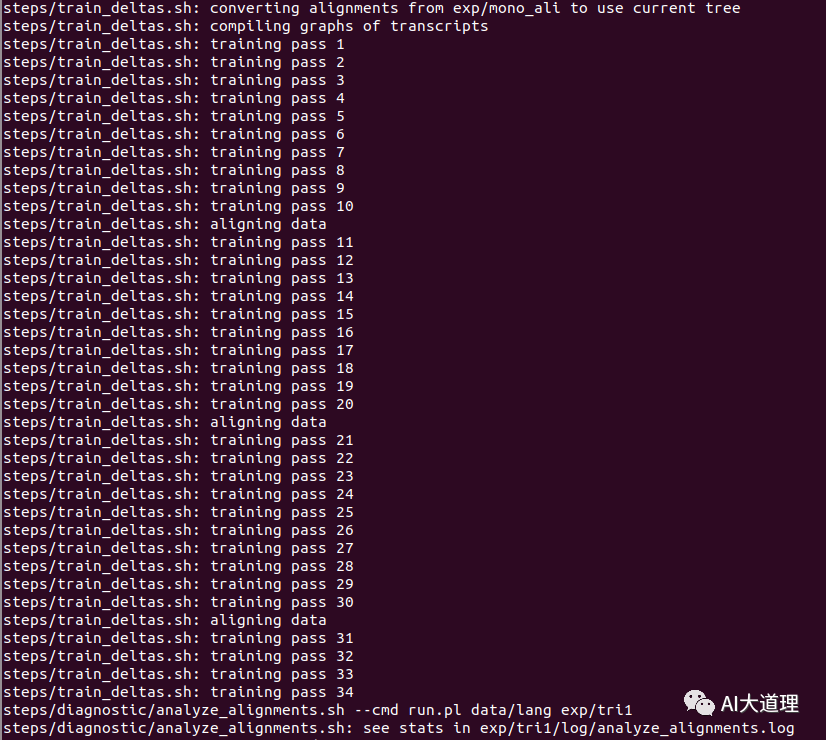
![]()
训练迭代次数num_iters=35。
训练完毕。
训练好的三音子模型:
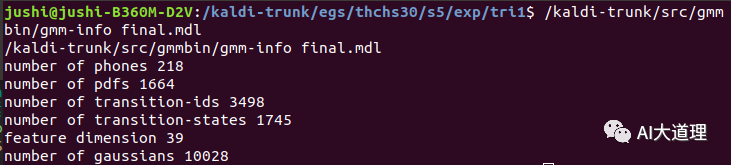
![]()
对比一下单音素模型:
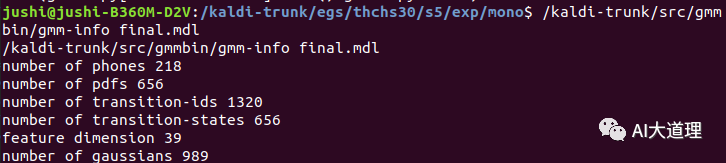
![]()
经过状态绑定后,最终高斯数量为10028个,实际设置的时候给的参数是10000。
![]() 5 .8 三音子模型解码识别
5 .8 三音子模型解码识别
train_deltas.sh
功能:
解码识别。

![]()
三音子模型部分解码识别(词级别):

![]()
单音素模型解码识别(词级别):
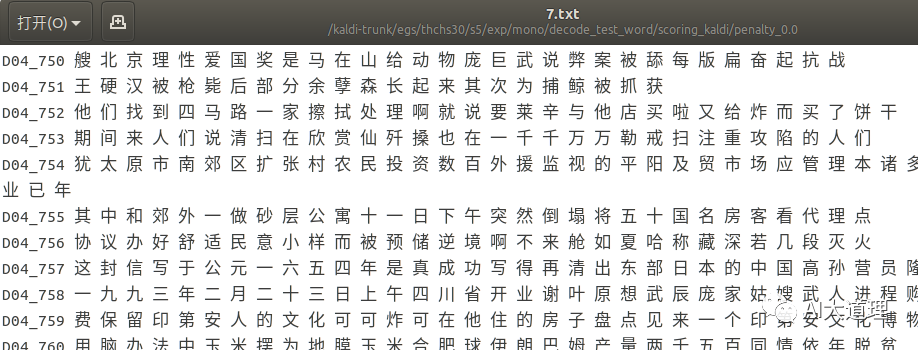
![]()
真正结果(标签词):

![]()
直观上感觉三音素模型识别结果比单音素模型好点。
三音子模型词错误率为:36.03%,对比单音素模型词错误率为50.58%。
可见词错误率下降了不少。

![]()
三音子模型部分解码识别(音素级别):

![]()
真正结果(标签音素):

![]()
三音子模型音素错误率为:20.44%,对比单音素模型音素错误率为32.43%。

![]()
![]() 5 .9 三音子模型对齐
5 .9 三音子模型对齐
align_si.sh
功能:
对齐,为下面模型优化做准备。

![]()
对齐结果:
![]()
![]() 总结
总结
三音子模型词错误率为:36.03%,对比单音素模型词错误率为50.58%。
三音子模型音素错误率为:20.44%,对比单音素模型音素错误率为32.43%。
可见三音素模型识别率已经有了提高。
能否继续优化模型?
特征变换助于模型的改善。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号