AIBigKaldi(十二)| Kaldi的三音子模型训练(中)(源码解析)
本文来自公众号“AI大道理”。
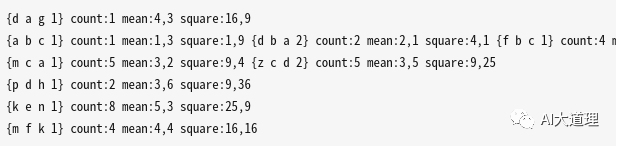
上文已经累计了相关统计量phone的特征均值、方差、phone所出现的语音帧数量。
接下来利用统计量自动生成问题集。
问题集的生成是为了构造决策树对三音子模型进行状态绑定。
以kaldi的thchs30为例。

![]() 5 三音子模型训练
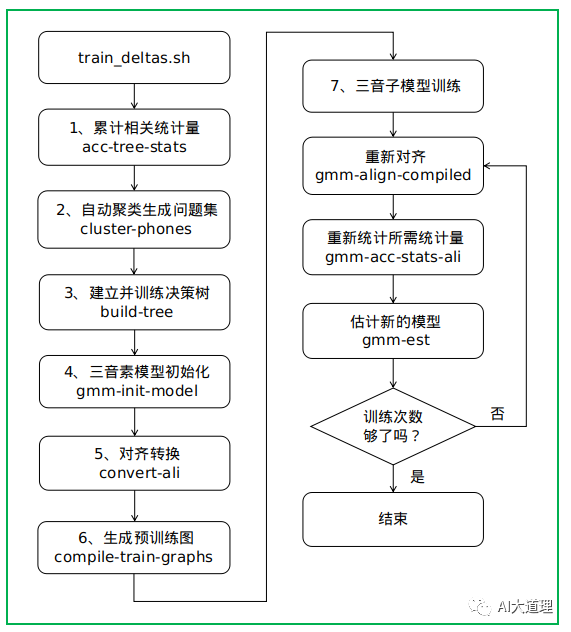
5 三音子模型训练
过程之道:
![]()
![]() 5.2 自动生成问题集
5.2 自动生成问题集
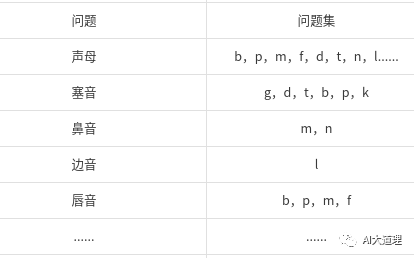
语言学家设置的问题以及根据这些问题得到问题集。
![]()
Kaldi决策树中使用的问题集并不是手工设计的,而是通过之前得到的统计量自动生成的。
灵魂的拷问:Kaldi是如何自动生成问题集的?
答:决策树的创建过程是将所有音素沿着tree的根节点,根据问题集决定该因素最终被分配到tree的哪个叶子节点上。
分裂该节点,其实就是如何从问题集中选择问题,能够使相近的三音素分类到相同的节点上。
问题集中的每个问题都可以将该节点分成两部分,哪种分法(哪个问题)最好,当然是似然增益最大的分法最好。
灵魂的拷问:问题集究竟是什么?
答:每个问题集都是一些音素的集合。
问题集不是问题的集合,而是已经聚类了的一堆堆音素的集合,这些集合反推出问题。
灵魂的拷问:语言学家的问题集可以问待分类的音素“是元音吗?”,kaldi自动生成的问题集如何对待分类的音素进行灵魂的拷问?从而指导它走向正确的归宿呢?
答:很简单!音素属于问题集1吗?属于问题集2吗?
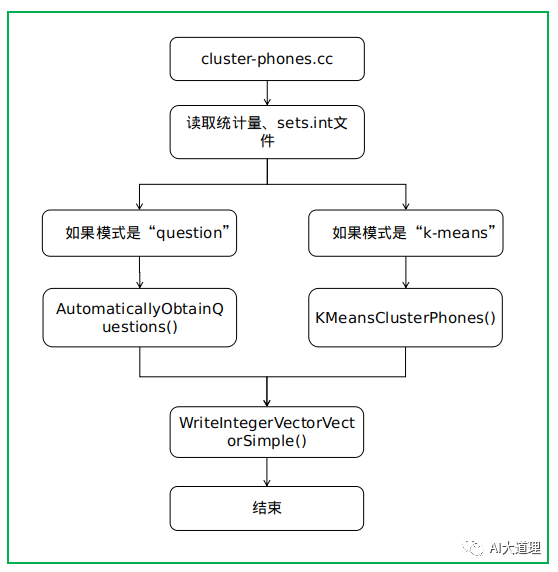
![]() 5.2.1 cluster-phones.cc
5.2.1 cluster-phones.cc
功能:
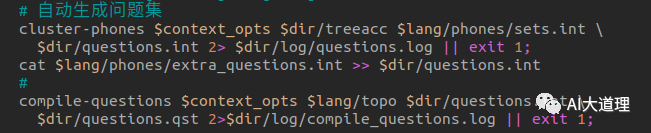
自动生成问题集。
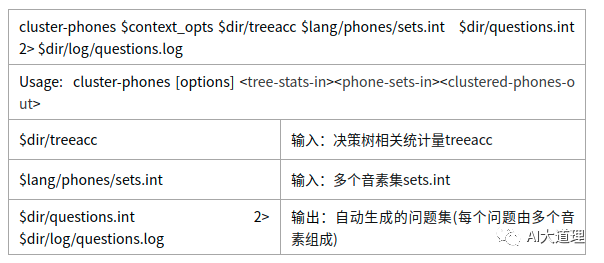
它的作用是对多个音素或多个音素集进行聚类。
源码解析:
![]()
![]()
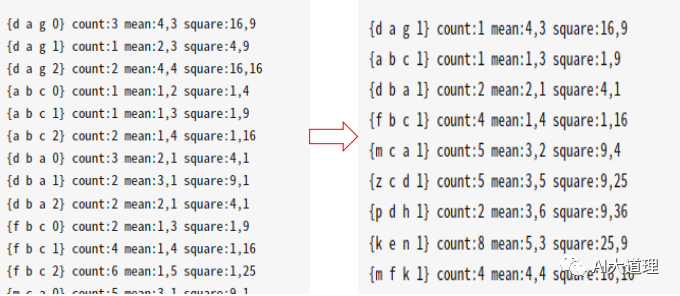
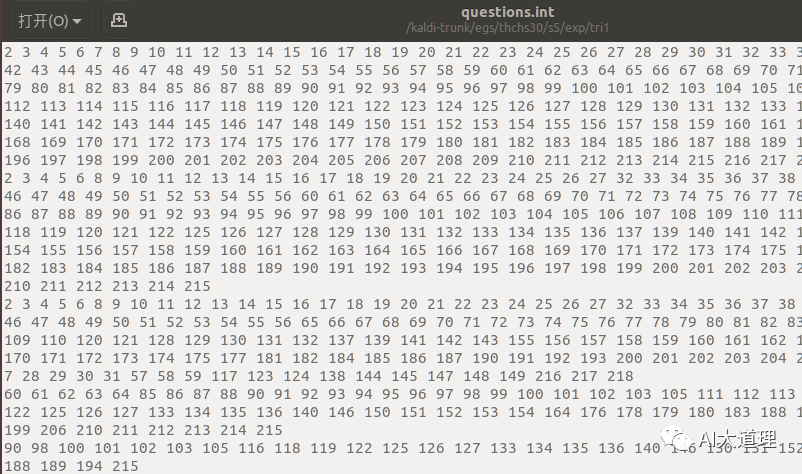
其中sets.int如下,根据sets.int指定的集合,累加同一个集合中音素的统计量。

![]()
1-218个音素的编号。
过程之道:
![]()
函数解析:
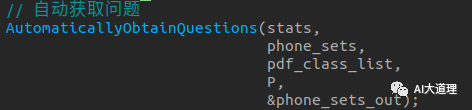
![]()

![]()
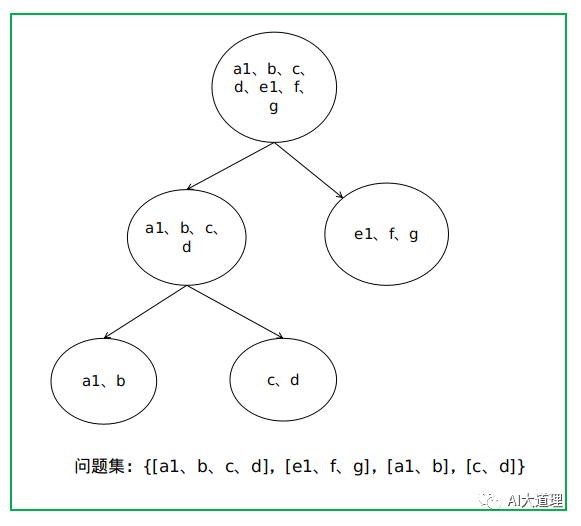
AutomaticallyObtainQuestions()把音素聚类成一棵树,并且对树中的每一个结点,把从该结点可以到达的所有叶子结点合在一起构成一个问题。
对于构建好的树,从每个结点都可以访问到一个(该结点就是叶子结点)或多个叶子结点,把这些叶子结点中的点合在一起,也就是把多个音素集合合在一起,形成一个更大的音素的集合,这个更大的音素集合就构成了一个问题。
函数过程:
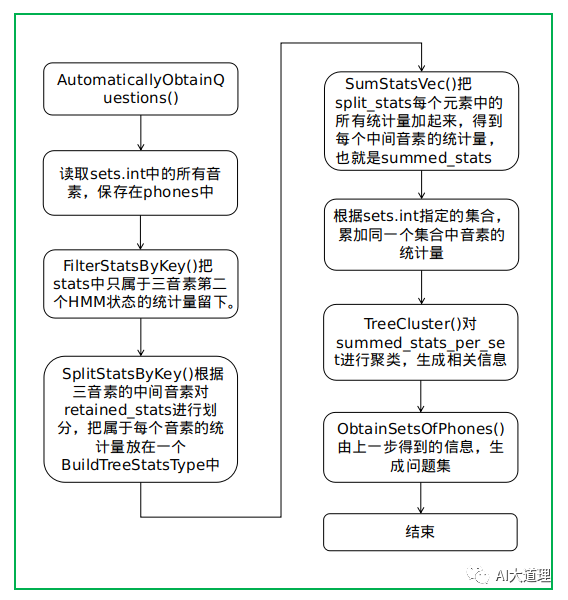
![]()
函数中的函数:
-
FilterStatsByKey()
把stats中只属于三音素第二个HMM状态的统计量留下。
(218*218*218个三音素,每个三音素三个状态,对每个状态单独建立决策树)
通过累积统计量部分我们知道,三音素的三个HMM状态可能都会有对应的统计量,但是这里只把与第二个HMM状态相关的统计量留下进行聚类,其他的都暂时扔掉不用。
![]()
-
SplitStatsByKey()
根据三音素的中间音素对retained_stats进行划分,把属于每个音素的统计量放在一个BuildTreeStatsType中。由参数P指定根据三音素的第几个音素进行划分,因为此处P是1,所以是三音素的中间音素。
![]()
-
SumStatsVec()
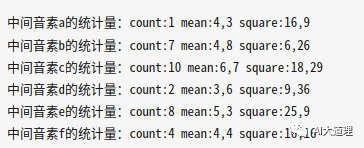
把split_stats每个元素中的所有统计量加起来,得到每个中间音素的统计量,也就是summed_stats,其维数为音素个数。
最终的summed_stats,每个元素保存着某音素作为三音素中间音素、其HMM状态为第二个状态对应的所有统计量的累积。
![]()
-
TreeCluster()
对summed_stats_per_set进行聚类,生成相关信息,完成了对点的划分,构建树。
每当创建新结点的时候(一般为叶子结点),应该总是调用FindBestSplit(Node* node)函数,找到对参数node的最优划分,即采取该划分时,获得的似然提升最大。
实际调用ClusterKMeans()找到对node的最优划分。
并把最优划分时获得的似然提升记录在该node的leaf.best_split中。
若该best_split超过cfg_指定的似然阈值thresh,则把对(best_split, node)放进优先队列queue_中。
该函数调用ClusterKMeans()找到对属于该node的点的最优的划分和对应的似然提升。
![]()
-
ObtainSetsOfPhones()
生成问题集。
计算传递给TreeClusterer的每个点分别属于哪个叶子结点。
在对树完成划分后,每个叶子结点都包含几个点,把这些点属于的叶子结点编号写到assignments_out中。
一行就对应一个问题,也是一系列phone组成的集合。
![]()
-
ClusterKMeans()
把当前节点中的所有点分成两类。
总是调用FindBestSplit(Node* node)函数,找到对参数node的最优划分,即采取该划分时,获得的似然提升最大。
实际调用ClusterKMeans()找到对node的最优划分。
k = cfg_branch_factor。
KMeans聚类过程:
1)随机选取k个质心(k值取决于你想聚成几类)
2)计算样本到质心的距离,距离质心距离近的归为一类,分为k类
3)求出分类后的每类的新质心
4)再次计算计算样本到新质心的距离,距离质心距离近的归为一类
5)判断新旧聚类是否相同,如果相同就代表已经聚类成功,如果没有就循环
2-4步骤直到相同。
![]() 5.2.2 compile-questions.cc
5.2.2 compile-questions.cc
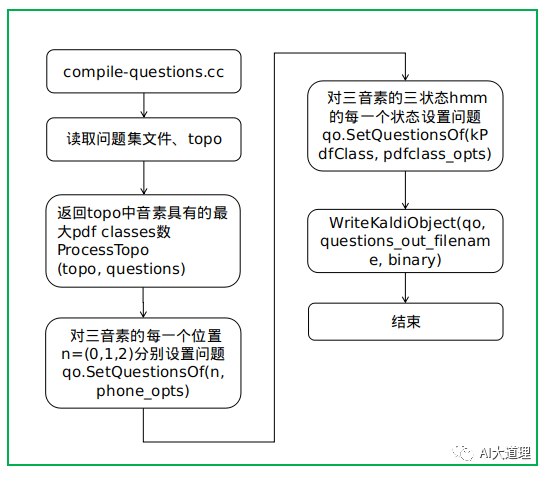
生成问题集只是保存到一个txt文件,这个程序让问题集和topo里面的音素挂钩,或者理解为在三音素上挂上问题集,在三音素的三状态上挂上问题集。
即对三音素的每一个位置分别设置问题,对三音素对应的三状态hmm的每一个状态设置问题。
功能:
编译question。
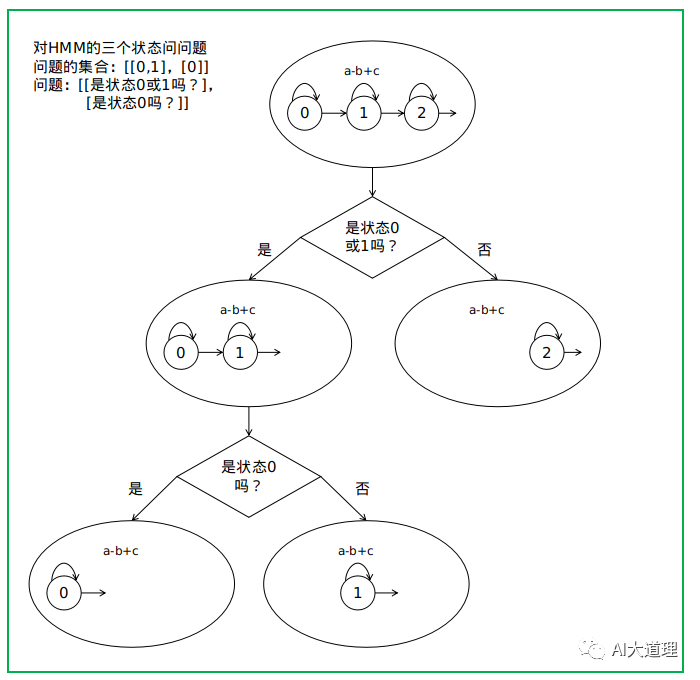
当key=0,1,2时,问题是对三音素中的每个音素分别问问题。
当key=-1时问题是基于HMM的某个状态的,这和HMM的状态数目有关,通常为三个,得到的问题的集合为[[0],[0,1]],如果为5个,则为[[0],[0,1],[0,1,2],,[0,1,2,3]]。
灵魂的拷问:为什么对于HMM的状态的问题的集合是这样的?
答:三状态的HMM编号为012,那么可以问是0吗?不是0就是1或者2。也可以问是0或者1吗?都不是就是2。如果问是0或1或2吗?不就是白问吗!同理五状态的HMM编号为01234,只要不问[0,1,2,3,4]这样的问题就是有价值的问题。
![]()
源码解析:

![]()
过程之道:
![]()
结果之道:

![]()
![]() 总结
总结
三音子模型训练整个过程做了两次的决策树建立。
第一次是为了得到问题集。
通过将所有音素作为决策树根节点,然后计算对音素集进行划分带来的似然度提升,不断对结点进行分裂,进而得到一系列问题集。
第二次是为了进行状态绑定。
对所有中间音素以及hmm state相同的EventType,我们从第一步得到的问题集中选出对似然度提升最大的问题,对建立一颗决策树。
然后比较所有叶子结点,把两两空间距离较近(如欧式距离)的叶子结点绑定在一起,有共同的pdf-id(混合高斯函数)。
至此自动生成了问题集,接下来可以进行构建决策树对三音子进行状态绑定了。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号