AIBigKaldi(十一)| Kaldi的三音子模型训练(上)(源码解析)
本文来自公众号“AI大道理”。
单音子模型的假设是一个音素的实际发音与其左右的音素无关。
这个假设与实际并不符合。
由于单音子模型过于简单,识别结果不能达到最好,因此需要继续优化升级。
就此引入多音子的模型。
最为熟悉的就是三音子模型,即上下文相关的声学模型。
(本篇主要解析kaldi源码实现,详细算法原理请阅读:
以kaldi的thchs30为例。

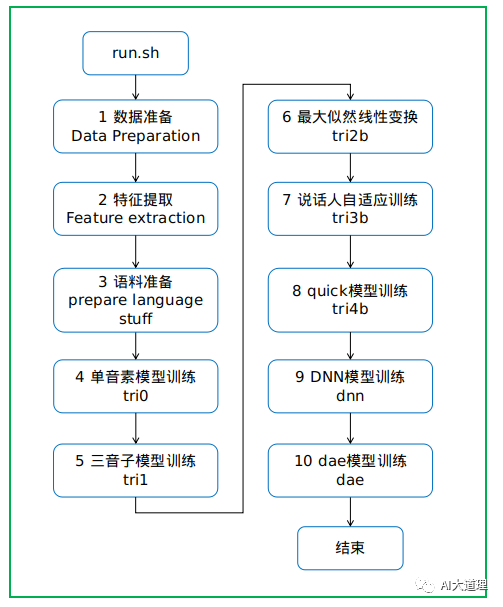
![]() 0 总过程
0 总过程
![]() 5 三音子模型训练
5 三音子模型训练
通过单音素模型得到单音素各个状态所有对应的特征集合。
然后做上下文的扩展得到三音素的各个状态所有对应的特征集合。
我们可以把训练数据上所有的单音素的数据对齐转为三音素的对齐。
灵魂的拷问:为什么要做状态绑定?
答:假如有218音素,若使用三音子模型则有218的3次方个三音子。
如果不进行聚类,需要建立218*218*218*3个混合gmm模型(假设每个triphone有3个状态)。
一方面计算量巨大,另一方面会引起数据稀疏。
所以会根据数据特征对三音子的状态进行绑定。
train_deltas.sh
源码解析:

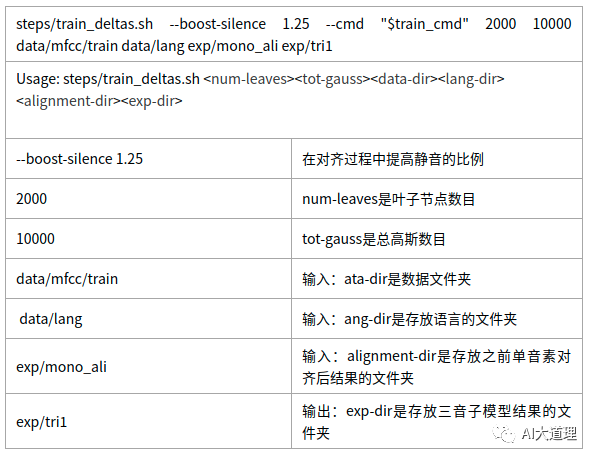
需要的文件:
$alidir/final.mdl $alidir/ali.1.gz $data/feats.scp $lang/phones.txt
过程之道:
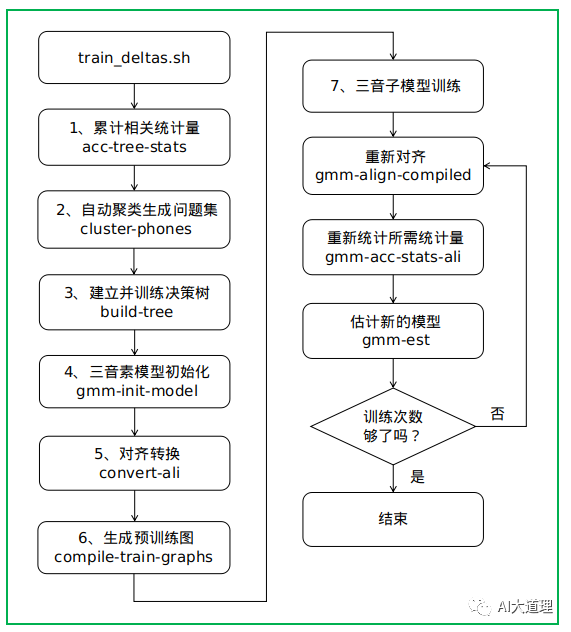
![]() 5.1 累计相关统计量
5.1 累计相关统计量
统计量:phone的特征均值、方差、phone所出现的语音帧数量。
灵魂的拷问:为什么需要累计相关统计量?
答:为自动产生问题集做准备,问题集又是为了构建决策树做准备。
自动产生问题集时决策树分裂是依据似然增益最大原则来进行的。
分裂前和分裂后的似然变化(增益)为D=L(Sl)+L(Sr)-L(S),似然增益越大,说明分裂后的两部分数据之间的差距越大,则越应该使用两个单独的GMM分别建模。
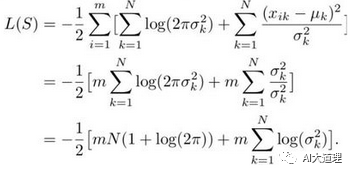
状态集S的似然L(S),根据L(S)的计算公式,需要知道状态集S产生的所有观测的协方差,对角协方差的对角线上是特征向量集每一维的方差。
想知道每一维的方差就需要知道特征向量集的和以及特征向量集的平方和(D(X)=E(X^2)-(EX)^2)。
计算L(S)除了要知道协方差,还需要知道状态集S产生的特征向量的个数,也就是状态集S出现的次数。
![]() 5.1.1 acc-tree-stats.cc
5.1.1 acc-tree-stats.cc
功能:
为决策树的构建累积相关的统计量。
输入:声学模型、特征、对齐
输出:统计量。
源码解析:
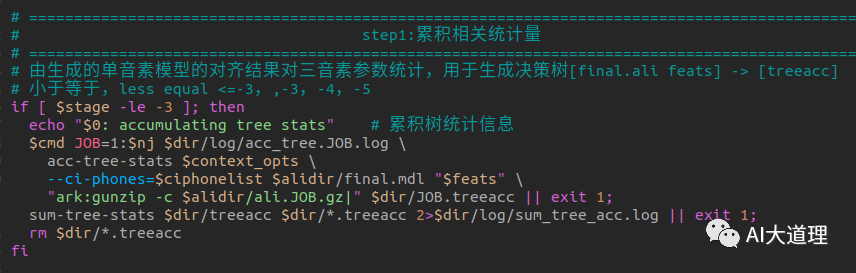

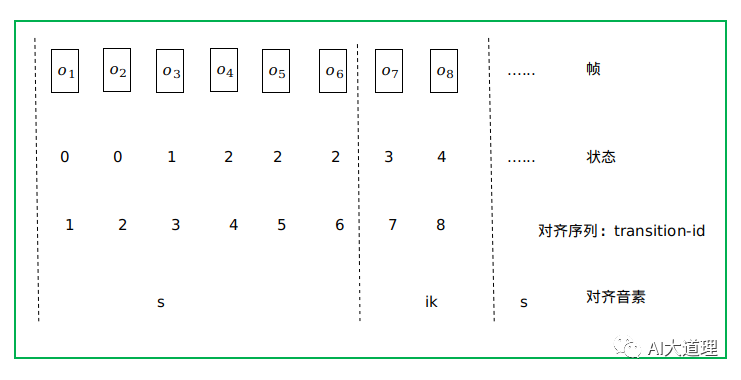
其中,在得到统计量之前,我们需要对每个句子进行维特比强制对齐。

有了强制对齐结果,就可以得到每一帧是属于哪个EventType。
对齐训练里面保存的数字是transition-id,根据transition-id可以得到三音素及其对应的状态。
根据EventType的所有帧对应的特征得到这个EventType的统计量(出现次数count_,特征向量的均值和均值的平方)。
统计量的结果保存在treeacc文件中:

其中:
EV 4 -1 0 0 0 1 29 2 134:就是一个EventType,4表示后面有4对pair。
-1 0 0 0 1 29 2 134:表示该三音素是0/29/134的第1个hmm状态。
GCL 1:表示该EventType出现的次数(对应count_变量)。
0.01:表示方差如果有小于0.01,则等于0.01。
第一行 表示特征向量的均值。
第二行 表示特征向量的均值的平方。
过程之道:
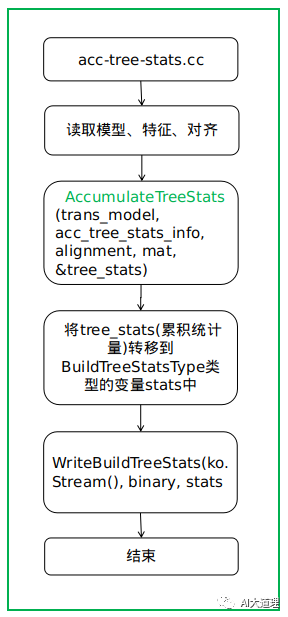
源码解析:
1)数据结构
std::map<EventType, GaussClusterable*> tree_stats

-
EventType:
在kaldi中用EventType描述三音素及HMM的状态。
假设三音素是a-b+c,编号为2,3,4。
EventType e = { (-1, 1), (0, 2), (1, 3), (2,4) }
表示三音素的三对数和表示HMM状态的一对数放在一起,这四对数就可以描述三音素及HMM状态。
在kaldi中用EventType表示这一数据结构:
typedef std::vector<std::pair<EventKeyType,EventValueType> > EventType;
所以,一个EventType就是一个带着三音素信息的状态state。
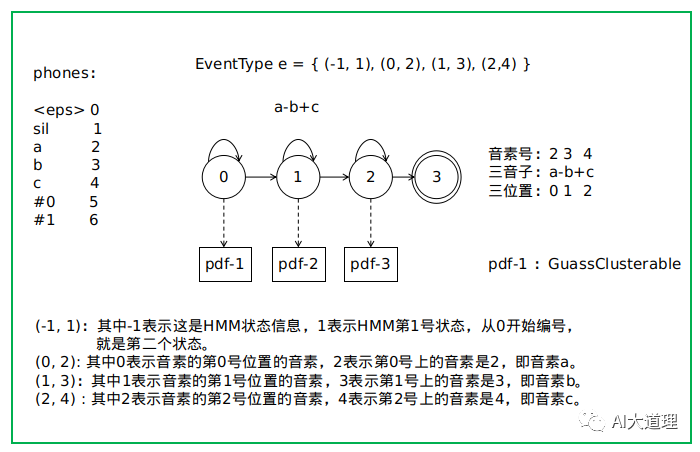
那么如何确定以b为中间音素的三音子的第二个状态下面挂着的pdf-id呢?pdf-2怎么得到?

EventMap是保存决策树的一种方法,它是一个多态纯虚类,不能够被实例化。
-
GuassClusterable
GuassClusterable继承自Clusteralbe,Clusteralbe对象的主要作用是把统计量累加在一起,和计算目标函数。
alignment之后,从左到右扫描对齐数据能从中得到三音素及HMM状态和其对应的特征向量,也就是得到一个EventType和其对应的特征向量。
在扫描过所有训练数据后,出现的每个EventType会对应多个特征向量。
2)主要函数
对所有的特征数据、对齐数据执行这个函数后,我们从训练数据中得到了所有的EventType和该Event Type对应的统计量。
这些统计量可以被用于自动产生问题集、构建决策树。
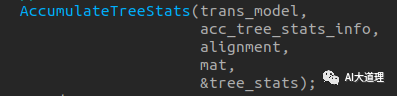
函数声明

函数过程:
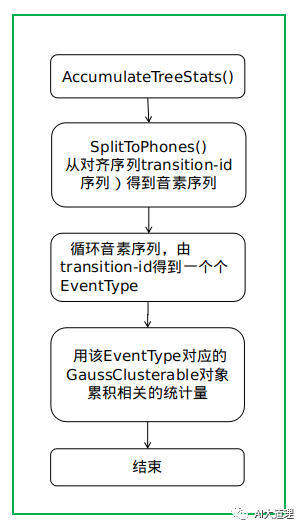
SplitToPhones()
3)BuildTreeStatsType
构建决策树所用到的统计量可以表示成:
typedef std::vector<std::pair<EventType, Clusterable*> >
BuildTreeStatsType;
![]() 5.1.2 sum-tree-stats.cc
5.1.2 sum-tree-stats.cc
功能:
语音上下文树构建的总和统计。
![]() 总结
总结
为了弥补单因素模型的不足,需要上下文相关的三音子模型。
为了构建三音子模型,需要进行状态绑定。
为了进行状态绑定 ,需要构建决策树。
为了构建决策树,需要准备问题集。
为了自动生成问题集,需要累计相关统计量。
为了累计相关统计量,需要对齐序列、单音素模型、每句话的特征。
至此累计好了相关统计量,接下来就可以自动生成问题集了。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————


![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号