AI大语音(十四)——区分性训练 (深度解析)
本文来自公众号“AI大道理”
声学模型的训练一般是基于极大似然准则(ML),然而ML只考虑正确路径的优化训练,没有考虑降低其他路径的分数,因此识别效果不佳。
区分性训练目标是提高正确路径得分的同时降低其他路径的得分,加大这些路径间的差异,因此识别效果更好。
1 互信息
区分性训练的其中一个常用准则叫MMI准则,即最大化互信息准则。
那么什么是互信息呢?
我们先来看看互信息的根源。
源头:
信息量:一个事件发生的概率越大,则它所携带的信息量就越小,而当p(x)=1时,熵将等于0,也就是说该事件的发生包含的信息量小。
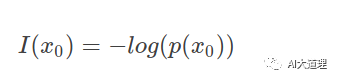
![]()
熵(entropy):又称自信息,所有可能取值的信息量的期望。描述一个随机变量的不确定性的数量,熵越大,不确定性越大,正确估计其值的可能性越小。越不确定的随机变量越需要大的信息量以确定其值。
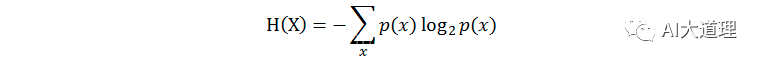
![]()
其中,p(x)表示x的分布概率。
相对熵(relativeentropy):又称KL距离,Kullback-Leibler divergence,
是对同一个随机变量X的两个单独的概率分布的度量。当p=q的时候,相对熵为0,当p和q差距变大时,交叉熵也变大。
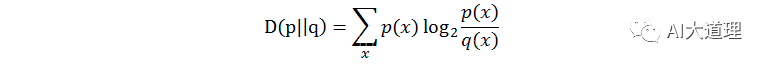
![]()
其中,p(x)和q(x)代表x的两种概率分布。
交叉熵(crossentropy):衡量估计模型和真实概率分布之间的差异。
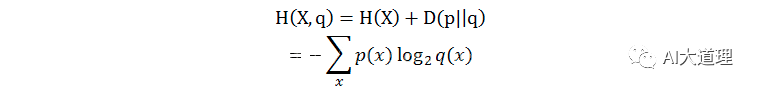
![]()
互信息(mutual information):衡量随机变量相互依赖的程度。
假设存在一个随机变量 X ,和另外一个随机变量 Y ,那么它们的互信息是:
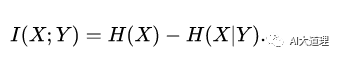
![]()
H(X) 是 X 的信息熵, H(Y|X) 是已知 X 情况下,Y带来的信息熵(条件熵)
使用的最大化互信息条件,就是最大化两个随机事件的相关性。
在数据集里,就是最大化两个数据集合所拟合出的概率分布的相关性。
理想情况下,当互信息最大,可以认为从数据集中拟合出来的随机变量的概率分布与真实分布相同。
2 最大似然估计(MLE)
声学模型的训练一般是基于极大似然准则(ML)。
最大似然估计,即假设一种分布,用现在已知的数据去估计这种分布的参数。
利用估计的分布算出一个交叉熵,然后让交叉熵尽可能小达到估计真实的分布。
最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
ML估计:求使得出现该组样本的概率最大的θ值。

![]()
在语音识别中使用对数似然函数:
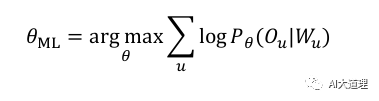
![]()
帧级别 Cross-Entroy 的损失函数如下,目标是最小化该函数:
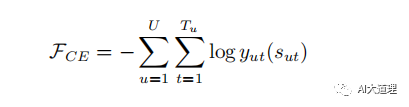
![]()
其中,NN 使用 softmax 作为输出:

![]()
对 softmax 前的 activation 求导,利用该值可以继续反向传播计算任意 NN 的参数的梯度:
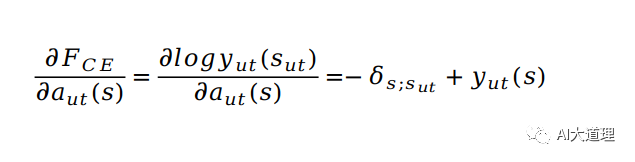
![]()
优点:
1)MLE训练方法简单,一个较高精度的语音识别声学模型能迅速地训练得到。
2)MLE采用的EM等算法使得其不需要精细的参考文本音段时间标注,并在每一步迭代中确保对目标函数的优化。
3) MLE估计对训练资源的消耗较小。
问题:
1)要求所学习模拟的分布是已知的,模型假设必须是正确的。就是说建模时指定的概率密度函数要能够代表实际语音的“真实”分布。
2)训练时数据应趋向于无穷多,可以经由无穷多的数据估计出模型的“真实”参数。
3)解码时需要的语言模型要事先已知,且参数要完全“真实”。
这三点实际上是不可能达到的。
(灵魂的拷问:为什么是不可能达到的?)
问题分析:
语音参数的“真实”分布是不可测的,更谈不上通常意义上的指数族函数(GMM)来充分模拟。
训练数据无穷多本就是天方夜谭。
解码中语言模型存在的问题与声学模型几乎完全一样,也达不到“真实”参数的要求。
结论:
在现实条件下通过MLE训练得到最优分类器是不可能的。
3 区分性训练(DT)
MLE之考虑正确路径的优化训练,没有考虑降低其他路径得分,识别效果不是很理想。
为了在现实条件下能得到较优的分类器,区分性训练被提出。
区分性训练的目标就是提高正确路径得分的同时降低其他路径得分,从而加大打分差异,就显得“区分开了”。
MLE训练更重视调整模型参数以反映训练数据的概率分布,而区分性训练则更重视调整模型之间的分类面,以更好的根据设定的准则对训练数据进行分类。
DT:求使得出现该组样本的概率最大的θ值。
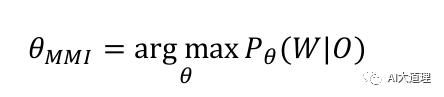
![]()
在语音识别中使用对数似然函数:
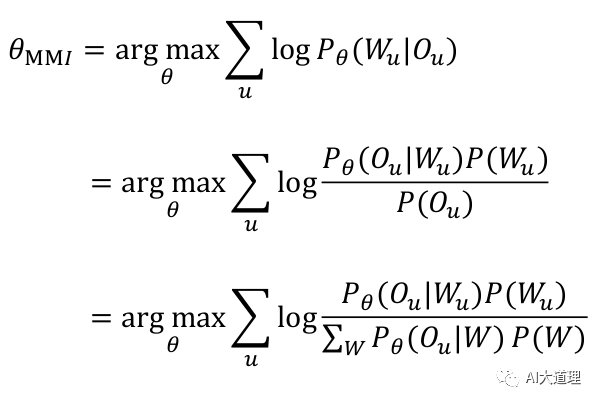
![]()
MMI是区分性训练的一种准则,即Maximum Mutual Information,互信息。
MMI的目标函数:
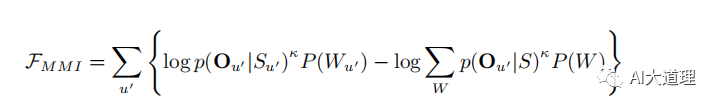
![]()
对 softmax 前的 activation 求导,利用该值可以继续反向传播计算任意 NN 的参数的梯度:
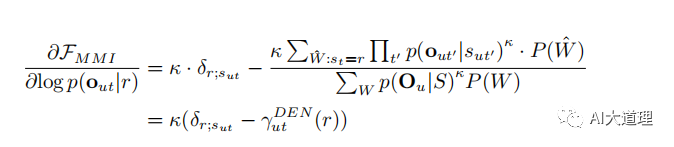
![]()
其中,
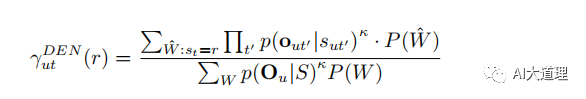
![]()
![]() 表示音频数据 Ou 在 t 时刻处在 r 状态的后验概率。该值可以在完整的解码图中用前向后项算法求的。
表示音频数据 Ou 在 t 时刻处在 r 状态的后验概率。该值可以在完整的解码图中用前向后项算法求的。
有一个问题:
Ou是所有所有可能的词序列对应的状态序列,穷举出来计算量将十分巨大。
(灵魂的拷问:怎么办?)
有三条路可以走。
第一条路(N-best):用N-best代替所有路径,简单粗暴,很少有人这样走。
第二条路(lattice):为每个训练句子都生成一个次图lattice,来近似MMI分母部分,即Lattice-based MMI。
第三条路(n-gram):用统计n-gram表示分母的所有可能路径。
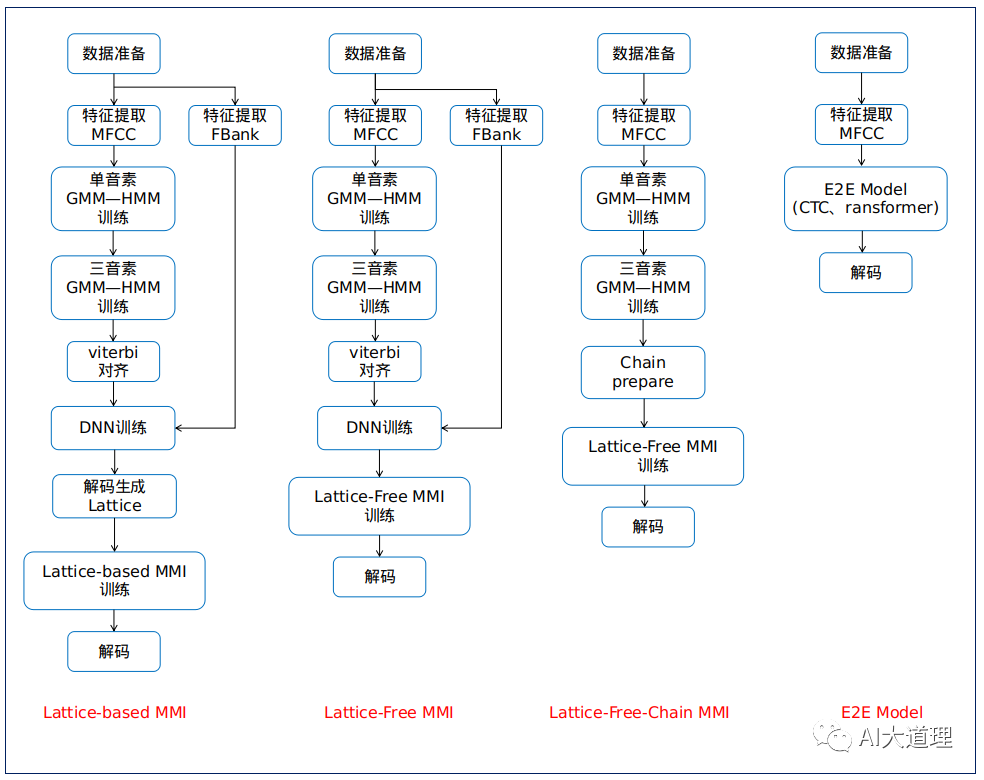
4 Lattice-based MMI
为每个训练句子都生成一个次图lattice,来近似MMI分母部分。
由于Lattice生成过程中结果一系列剪枝等处理,使得包含的路径有限,从而降低计算量。
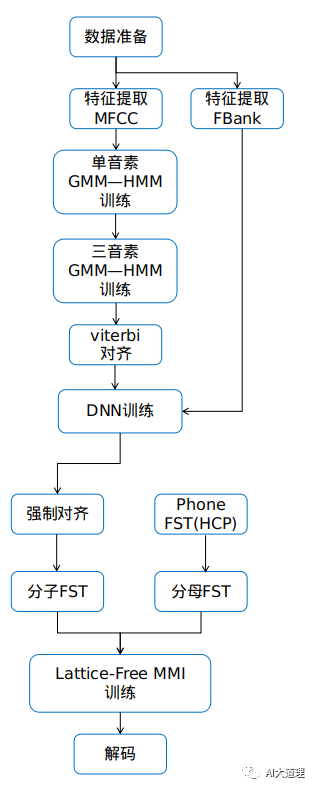
基于DNN-HMM的Lattice-based MMI训练流程:

![]()
1)提取训练好DNN-HMM
2)在DNN-HMM上做状态级别的对齐,得到正确标注对应的Lattice,对应MMI分子部分。
3)基于WFST的HCLG对每条训练句子进行解码识别,得到Lattice,包含各个有限的路径,对应MMI分母部分。
4)进行Lattice-based MMI训练
偷懒是进步和突破的源动力。
有人说生成Lattice太麻烦了,我不想要,于是真就丢掉Lattice这个步骤。
有舍有得,舍掉Lattice又需要什么呢?
5 Lattice-free MMI
可以用n-gram来表示分母W的所有可能。
特点:
由训练数据训练Phone/State的n-gram, and no back-off。
WFST Compose成State level的FST。
FST + AM score + 前向后向算法计算![]() 。
。
Lattice-free MMI 采用音素语言模型代替词语言模型,这样不需要词典了,又丢掉了个麻烦。
因此构造的HCLG实际上只有HCP。
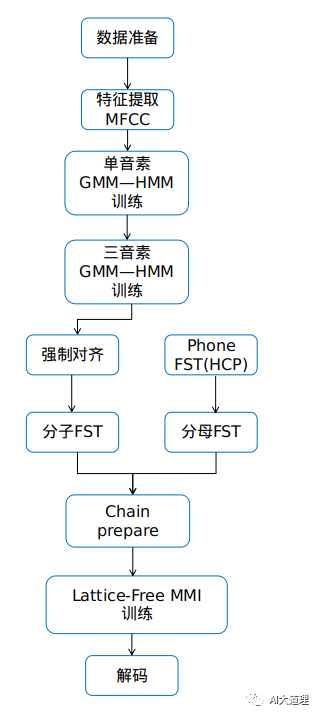
基于DNN-HMM的Lattice-free MMI训练流程:
![]()
1) MMI分母部分的FST前向后向计算直接用音素级别的FST图,并在每次训练后更新状态序列和统计量。
2)基于DNN-HMM得到句子的Lattice(FST形式)进行中MMI分子部分的前向后向计算。
3) 进行Lattice-Free MMI训练。
不知道是不是同一个人,它还想继续偷懒(优化)。
他不旦嫌Lattice麻烦,甚至对DNN训练也觉得是个累赘。
能不能再简单一点呢?
6 chain-model
Chain 模型再次减少了整个语音识别的流程。
Chain prepare包含以下一些准备。
• LF-MMI Topology,phone从原来的3状态降成1状态。(没有理由)
• Reduce frame rate(10ms to 30ms),采用拼帧降采样(每三帧取一帧)的方式,也就是说帧移变成了30ms,而不是10ms。
• bi-phone Tree,决策树的重新生成。
• Numerator FST,强制对齐得到分子FST。
• Denominator n-gram, FST,HCP图得到分母FST。
• Fixed chunk,整个音频分成块,加速训练和解码速度。
• CE Regularization,使用CE作为第二个Task进行Multi-Task Learning。
基于chain model的Lattice-free MMI训练流程:
![]()
chain model的优点:
1、解码速度更快。因为chain model采用拼帧降采样(每三帧取一帧)的方式,也就是说帧移变成了30ms,而不是10ms,所以帧率是传统神经网络声学模型的三分之一;
2、训练速度更快。不需要预先训练DNN模型,同时省去了分母lattice的生成。
7 总结
(得寸进尺的拷问:语音识别流程还能更简单吗?)
能,大道至简。
那就是端到端语音识别。
之前走的路跋山涉水、弯弯绕绕,端到端则是两点一线的直达。
然而欲速则不达,端到端自然也是问题多多。
有得必有失。
得:
不再依赖HMM中的各种条件独立性假设,模型变得简洁,不再需要各个模块。
失:
训练非常依赖大语料、由于没有了独立的语言模型模块,因此实际应用中缺少一定的通用性(本可以外接一个专门领域的语言模型)等问题。
![]()

![]()
下期预告
AI大语音(十五)——端到端语音识别
往期精选
AI大语音(十三)——DNN-HMM(深度解析)
AI大语音(十二)——WFST解码器(下)(深度解析)
AI大语音(十一)——WFST解码器(上)(深度解析)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号