
AI大语音(十三)——DNN-HMM (深度解析)
本文来自公众号“AI大道理”
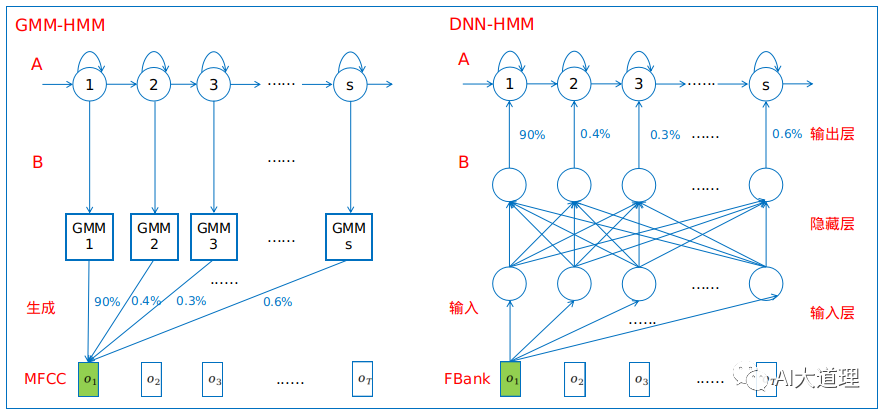
GMM-HMM建模能力有限,无法准确的表征语音内部复杂的结构,所以识别率低。
随着深度学习的崛起,研究人员将其逐步应用于语音识别中。
最开始便是DNN代替了GMM来进行观察状态概率的输出,实现DNN-HMM声学模型框架,大大提高了识别率。
1 GMM-HMM与DNN-HMM对比
DNN-HMM用DNN替换了GMM来对输入语音信号的观察概率进行建模。
GMM对HMM中的后验概率的估计需要数据发布假设,同一帧元素之间需要相互独立,因此GMM-HMM使用的特征是MFCC,这个特征已经做了去相关性处理。
DNN-HMM不需要对声学特征所服从的分布进行假设,使用的特征是FBank,这个特征保持着相关性。
DNN的输入可以采用连续的拼接帧,因而可以更好地利用上下文的信息。
GMM是生成模型,采用无监督学习,DNN是判别模型,采用有监督学习。
DNN输出向量的维度对应HMM中状态的个数,通常每一维输出对应一个绑定的triphone状态。
![]()
(DNN输入可采用连续的拼接帧)

![]()
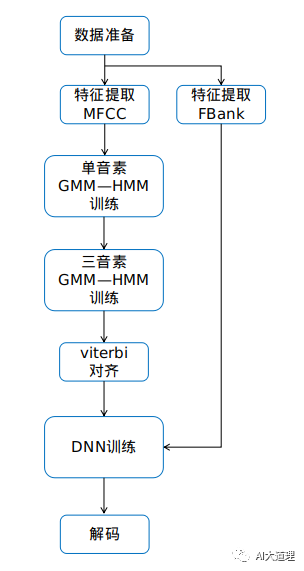
2 DNN-HMM训练步骤
训练DNN-HMM之前,需要先得到每一帧语音在DNN上的目标输出值(标签)。
标签可以通过GMM-HMM在训练语料上进行Viterbi强制对齐得到。利用标签和输入特征训练DNN模型,用DNN模型替换GMM进行观察概率的计算,保留转移概率和初始概率等其他部分。
![]()
(灵魂的拷问:一开始用MFCC特征进行训练、对齐,后来用FBank特征进行训练DNN,MFCC和Fbank特征维度明显不一样,这样对齐的标签和训练的标签一致吗?不会有问题吗?
AI大语音:一帧的数据o1对齐到状态1,都是帧对应到状态,不管什么特征都代表这一帧的数据。)
步骤一:基于GMM-HMM使用viterbi对齐得到标签
训练好GMM-HMM后使用Viterbi进行解码,获得最优路径的同时也自然得到了对齐,即哪一帧属于哪个状态。这样就把一段语音(宏观)和状态(微观)一一对应了。

![]()
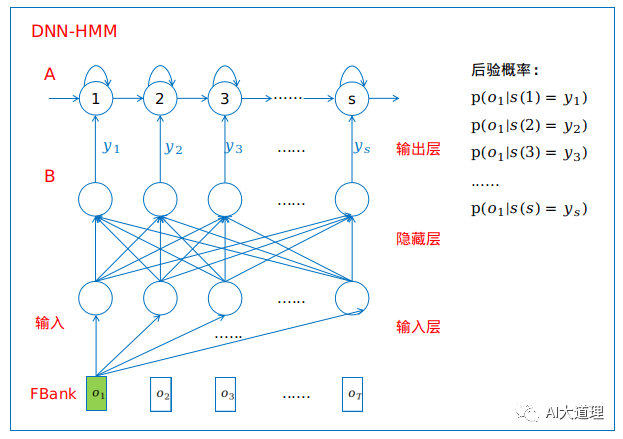
步骤二:构建DNN-HMM
所有音素的HMM只用一个DNN,DNN的输出节点数必须要和HMM的发射状态数一样。多少状态就是多少分类任务。
![]()
(DNN表征的其实是p(s|0),这里p(o|s)用y表示)
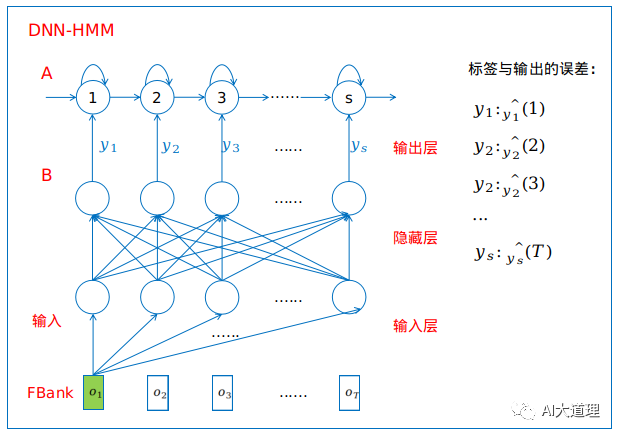
步骤三:训练DNN-HMM

![]()
![]()
当o1输入后,结果softmax把它分类到某一个状态中,就产生一个输出,与标签对比得到误差,进行反向传播训练权重参数W、b。
3 总结
DNN-HMM显著的提高了识别率,那么还能继续优化吗?还能怎么优化呢?
区分性训练为此而生。

![]()
读者讨论
您对DNN-HMM有什么独到见解或疑惑吗?
欢迎在文末“留言吧”讨论。
下期预告
AI大语音(十四)——区分性训练
往期精选
AI大语音(十二)——WFST解码器(下)(深度解析)
AI大语音(十一)——WFST解码器(上)(深度解析)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号