AI大语音(十二)——WFST解码器(下)(深度解析)
本文来自公众号“AI大道理”。
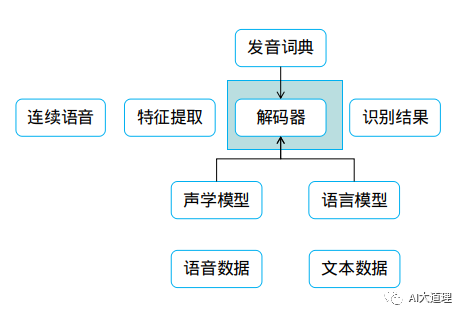
把HMM、语言模型N-gram、发音词典、上下文相关转化成WFST,再进行合成得到一个巨大的WFST。
对这个巨大的WFST进行确定化、权重移动、最小化等优化,得到一个浓缩的包含各种约束的网络。
语音识别就变成在一个WFST的搜索问题了,使用Viterbi的集束搜索得到最优路径,即识别结果。
![]()
1 WFST的源头
源头:
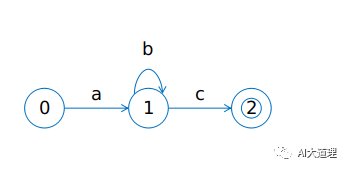
1)有限状态接收器FSA(Finite State Acceptor)
FSA弧上有“输入”信息,随着状态的不断转移,可以判断能否接收特定的符号串。
![]()
这个FSA可以接收ab*c,如abc,abbc等等,不能接收acb、abcd等字符串。
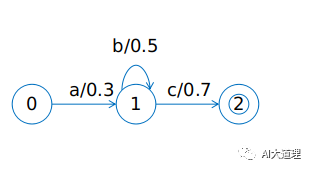
2)带权重的有限状态接收器WFSA(Weighted Finite State Acceptor)
WFST弧上有 “输入符号/权重” ,可以接收特定的字符串,同时还能输出权重信息。
![]()
如果输入了abbc,则对应的权重值为0.3*0.5*0.5*0.7=0.0525
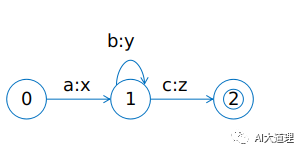
3)有限状态转换器FST(Finite State Transducer)
FST弧上有 “输入:输出” 信息,当接收了特定字符串后,输出另外一个特定字符串。
![]()
如果输入了abbc,则输出xyyz。
4)权有限状态转换器WFST(Weighted Finite State Transducer)
WFST弧上有“输入:输出/权重”。
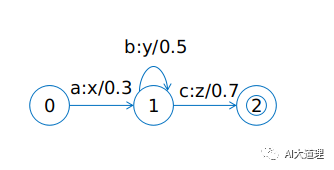
![]()
当输入abbc时,输出xyyz,同时输出权重值0.3*0.5*0.5*0.7=0.0525。
2 WFST的表示
定义一个WFST。
T=(A,B,Q,I,F,E,λ,ρ)
T:表示一个在数集K上的WFST,
A:表示一个有限的输入集,
B:表示一个有限的输出集,
Q:表示一个有限的状态集,
I:表示一个有限的初始状态集I⊆Q,
F:表示一个有限的结束状态集F⊆Q,
E:表示一个有限的状态转移集E⊆Q×(A⋃{ϵ})×(B⋃{ϵ})×K×Q,(输入输出可为空ϵ)
λ:表示初始状态的权重。
ρ:表示结束状态的权重,
E[q]:表示离开状态q的所有状态转移的集合。
p[e]:表示这个转移的出发状态,n[e]:表示这个转移的到达状态,
i[e]:表示这个转移上的输入label,o[e]:表示这个转移上的输出label,w[e]:表示这个转移上的权重值。
那么,一条路径(path)就是一连串的转移,π=e1⋯ek
并且满足n[ei−1]=p[ei],i=2,⋯,k,p[π]=n[e1],n[π]=n[ek]。
一整条路径的权重w[π]等于各个状态转移上的权重相⨂:w[π]=w[e1]⨂⋯⨂w[ek];
那么多个有限路径集合的权重w[R]就等于每条路径的权重相⨁:w[R]=⨁π∈Rw[π]。
一个规范的(regulated)WFST可以表示为:
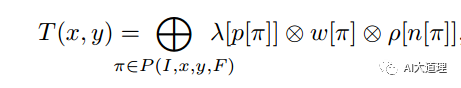
![]()
其中,P(p,x,y,q)表示从状态p到q,输入为x输出为y。
3 合成算法(Composition)
Composition将两个不同级的WFST进行组合。
语音识别中发音词典的WFST是音素对词的映射,而语言模型的WFST是词对受语法约束的词的映射,那么两个WFST进行Composition后就变成了音素对受语法约束的词的映射。
效果:
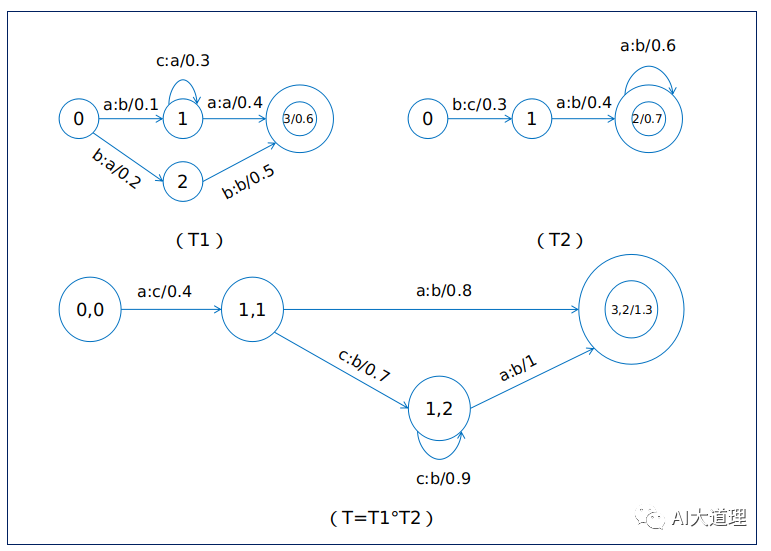
![]()
算法:
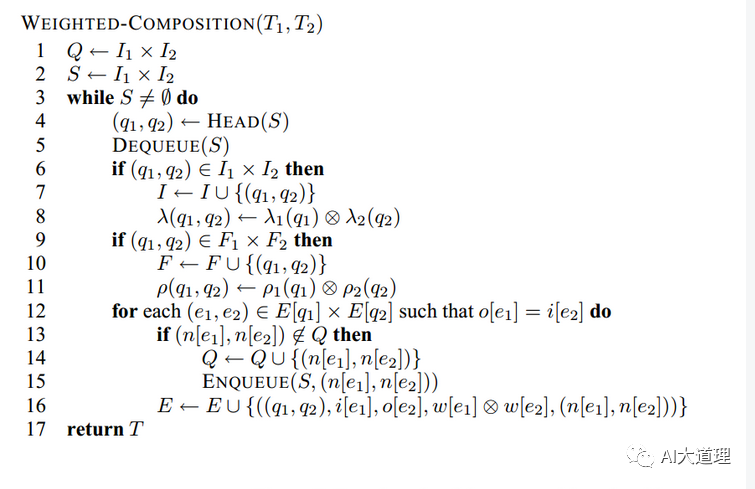
![]()
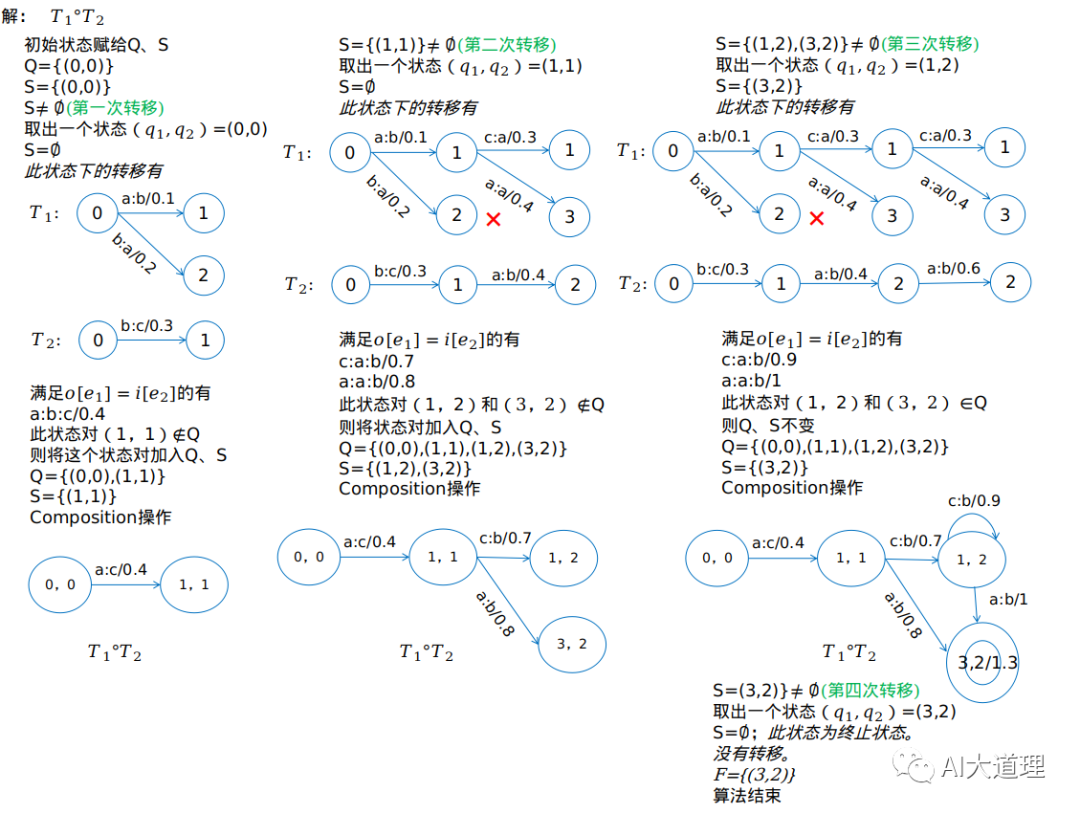
首先把两个WFST的初始状态赋给状态集Q、队列S。
Q用来统计出现过的所有状态对的集合。
S用来记录此时的状态对能达到的所有状态对的集合。
把队列S的头元素赋给状态对(q1,q2),用Dequeue(S)取出状态。
判断是否为结束状态,如果是就把该状态加入到最终状态集合F中去。
找出所有离开T1中:状态q1的所有转移和离开T2中的状态q2的所有转移,并且对比T1的这些转移的输出label是否等于T2的这些转移的输入label(o[e1]=i[e2]),
如果等于的话则则判断他们的目的状态是否在Q中(之前说了Q是统计所有出现过的状态,那么此时的含义就是判断是否出现了新状态)。
如果是新状态的话则将它加入到Q和S的集合中,
compostion的操作,状态对(q1,q2)到状态对(n[e1],n[e2])的转移,转移上的输入标签是i[e1],输出标签是o[e2],权重是w[e1]⨂w[e2]
把这个转移加入到转移集合E中。
继续取出状态,直到队列S为空。
流程:

![]()
图解:
![]()
4 确定化算法(Determinization)
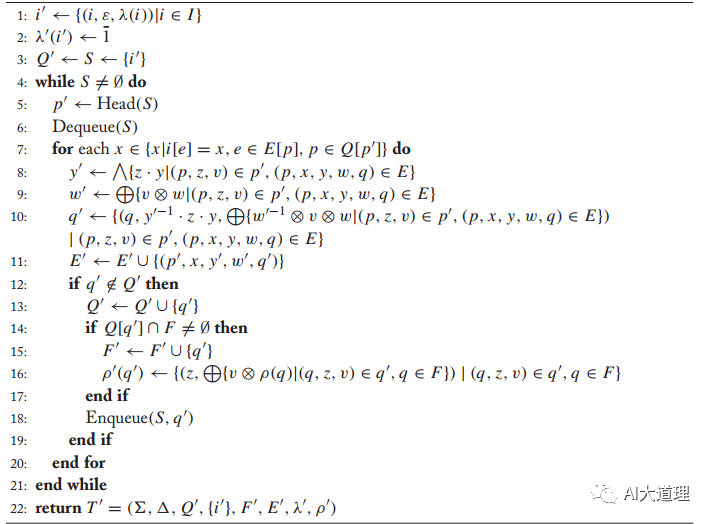
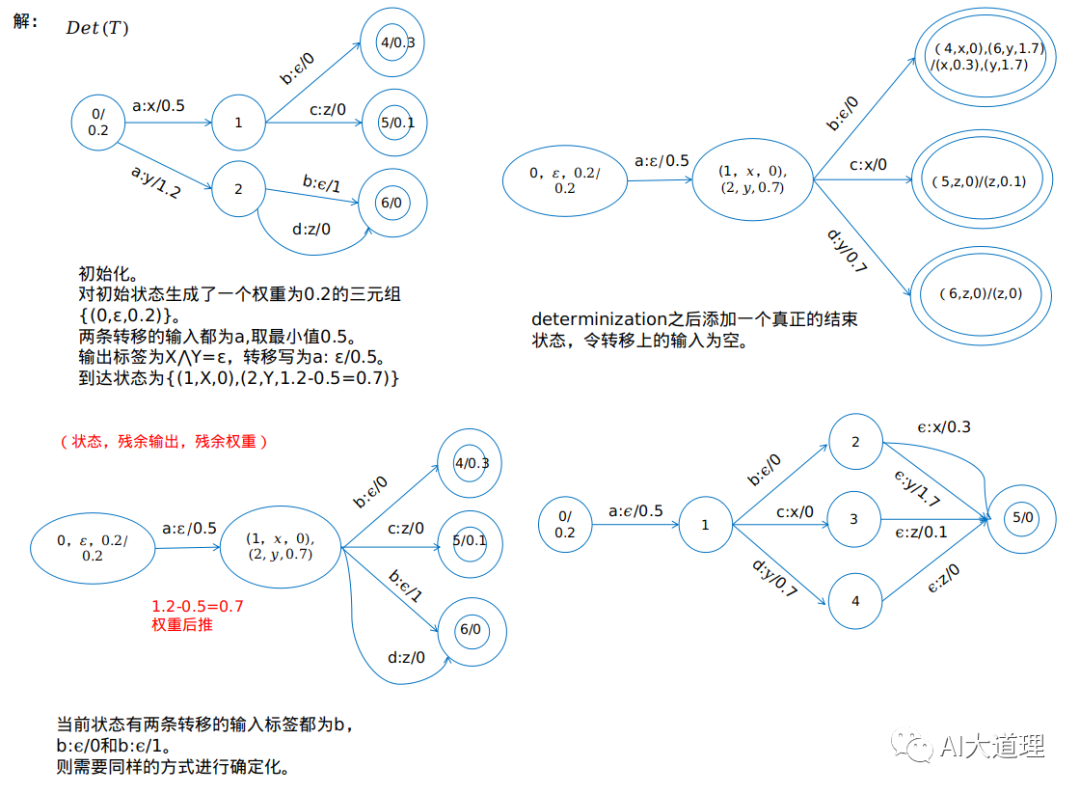
determinization的功能是当离开某个状态的转移上的输入标签相同时,采取某种机制只保留其中的一条而不影响整个系统的结果,这样离开某个状态的转移就是确定的了,因为每输入一个标签,它都会到达唯一一个确定的状态。
determinization可以大大地加快运行的时间。
有残余权重来记录权重信息,还要有”残余“输出来记录输出信息。算法中每个状态我们用三元组集合来表征:{(p,z,v)|p∈Q,z∈B,v∈K},其中p代表该状态,z代表”残余“输出(leftover output label),v代表残余权重(residual weight)。
效果:

![]()
算法:
![]()
这里和composition类似,也用了Q来统计出现过的所有三元组,用队列S来记录新的三元组并作循环条件。
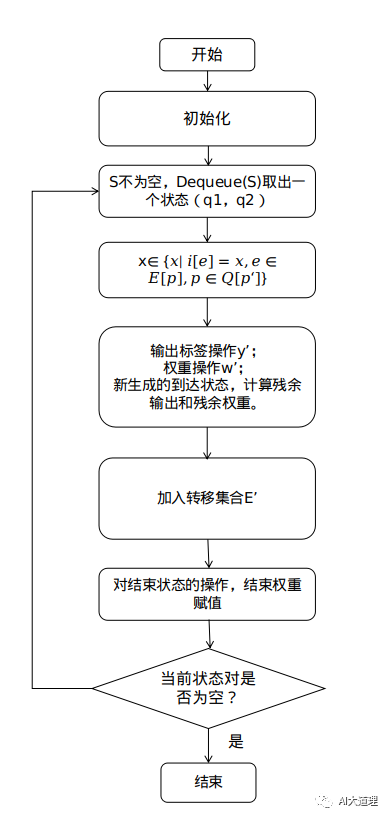
流程:
![]()
图解:
![]()
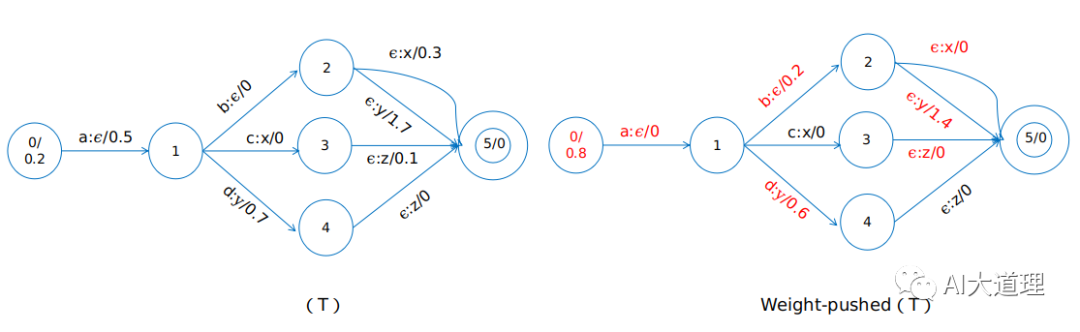
5 权重推移(Weight pushing)
权重推移将WFST中的权重尽可能往靠近初始状态的方向移动。权重推移后相同输入/输出的权重不变。
权重推移增加了搜索的效率。
(灵魂的拷问:为什么可以提高搜索的效率?
AI大语音:在搜索过程中会把不需要的路径排除掉。权重推移后一开始就可以排除掉很多种可能路径,从而提高搜索效率。)
效果:
![]()
一般的权重推移算法包括两个步骤:
1) 给每个状态计算一个potential,计算方式如下: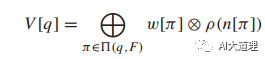
![]()
2) 根据上面计算的potential和实际权重差值来修改转移路径上的权重值。
算法:
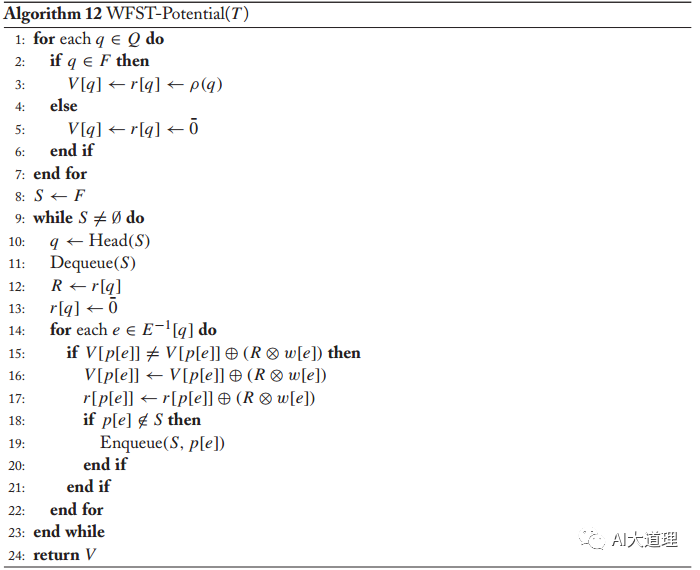
![]()

![]()
图解:
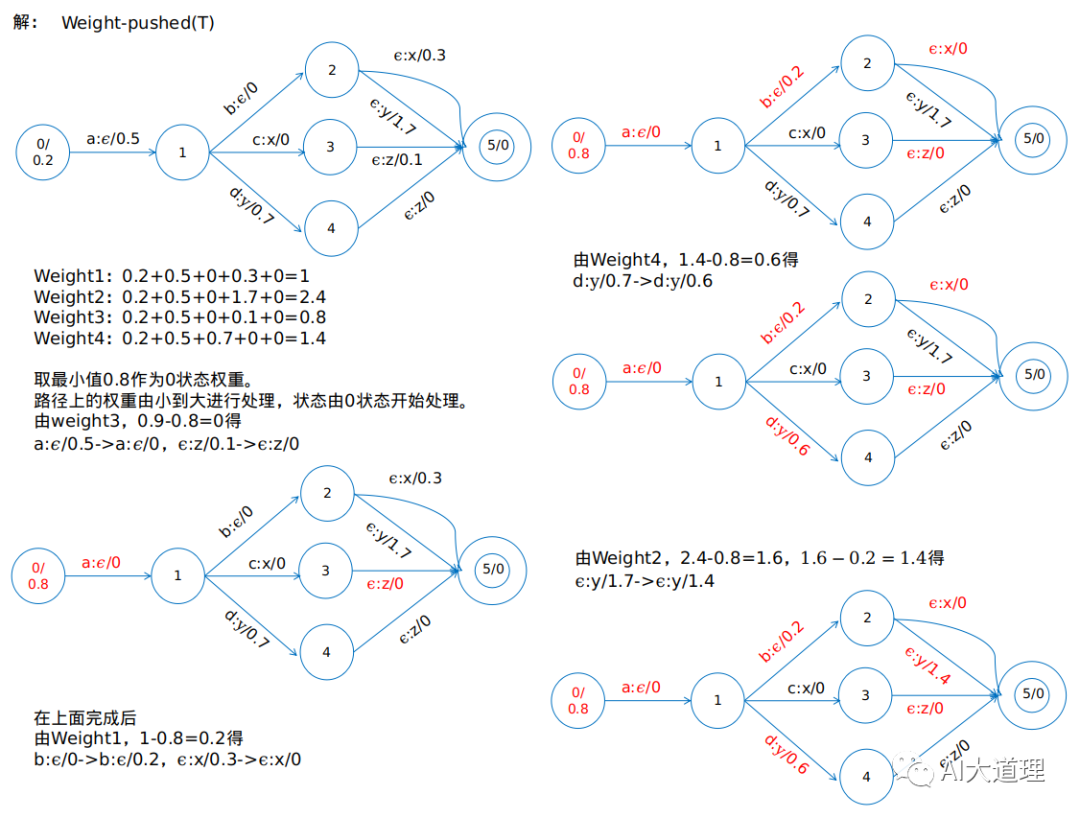
![]()
6 最小化算法(Minimization)
minimization可以让WFST中的状态数最少。
效果:
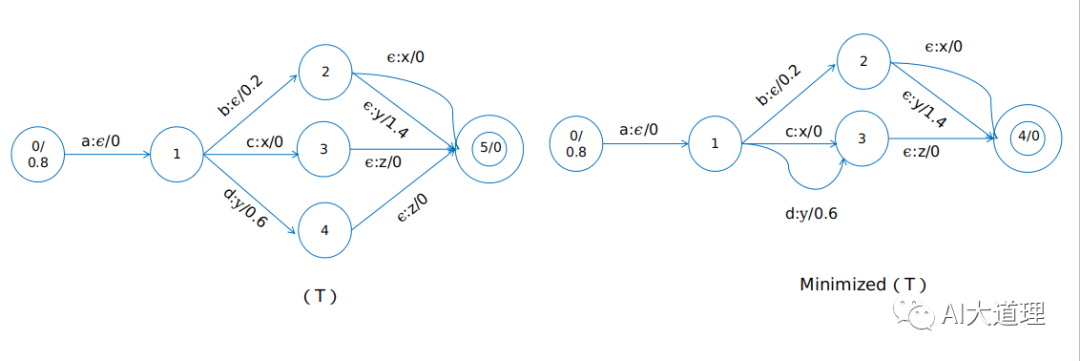
![]()
算法:

![]()
7 HCLG
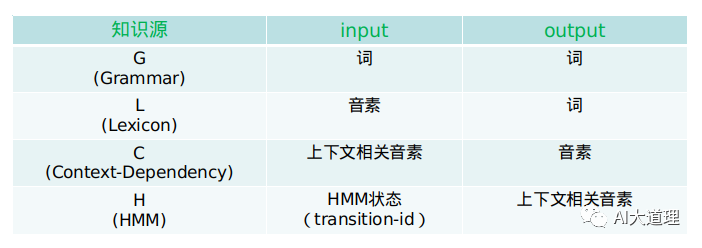
![]()
1) G.fst
G.fst对应语言模型,用来描述词与词之间组合的可能性。
每个节点代表一个词,节点之间的转移弧权重代表前一个词与后一个词的条件概率P(w2|w1)。
如果w1和w2两个词的组合不存在,则条件概率由w1回退概率和w2的概率相乘得到。
3-gram语言模型如下
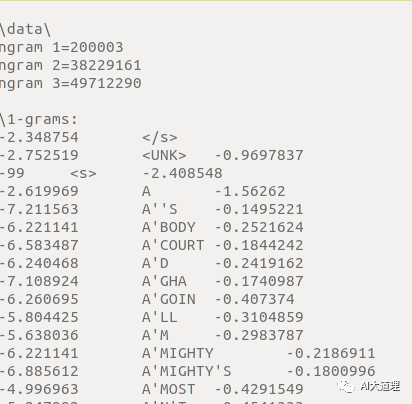
![]()
由3-gram语言模型生成的G.fst(小部分)

![]()
2) L.fst
L.fst对应发音词典,实现单音子到词的转换。
字典:
Cay k ey
ache ey k
K. K ey
由字典生成的L.fst
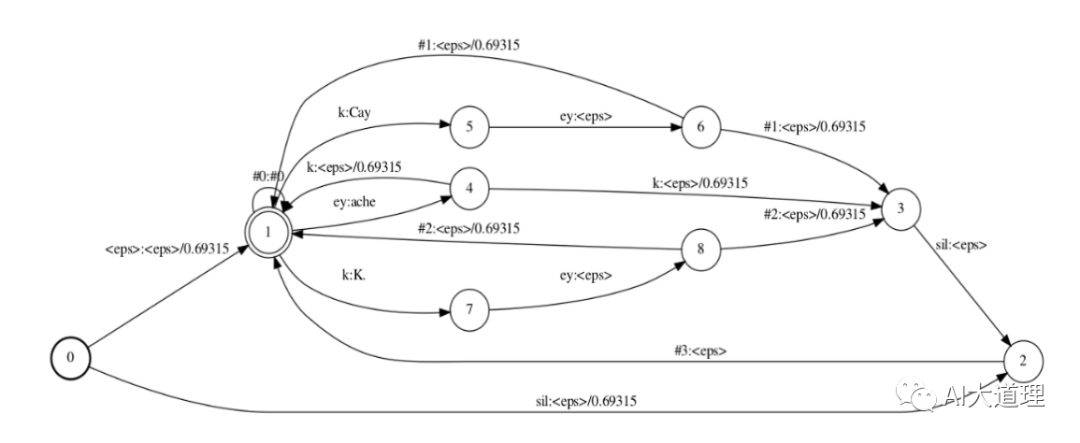
![]()
3)C.fst
C.fst描述音素上下文关系的转换,一般是三音子到单音子的转换。
<eps>/j/j j
<eps>/j/in1 j
j/in1/in1 in1
........
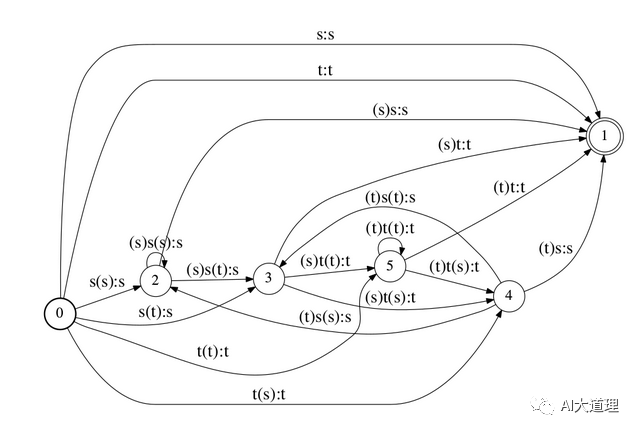
![]()
通常Kaldi里不单独生成C,而是直接与LG进行compose,生成CLG。
4)H.fst
H.fst表示HMM的转换关系。
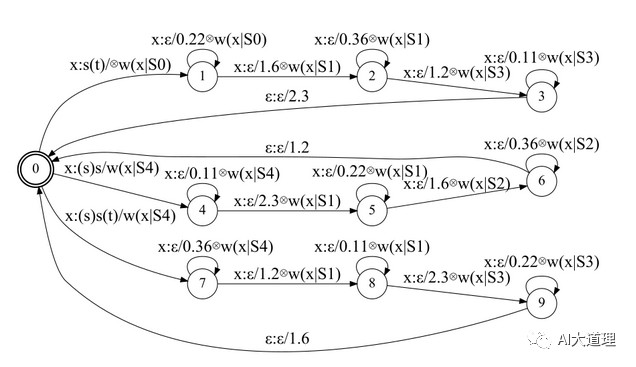
![]()
5)HCLG
H、C、L、G组成WFST

![]()

![]()
7 总结
随着深度学习的崛起,研究人员将其逐步应用于语音识别中。
最开始便是DNN代替了 GMM 实现了观察状态概率输出,实现DNN-HMM声学模型框架。

![]()
下期预告
AI大语音(十三)——DNN-GMM(深度解析)
往期精选
AI大语音(十一)——WFST解码器(上)(深度解析)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号