AI大语音(十一)——WFST解码器(上)(深度解析)
点击上方“AI大道理”,选择“置顶”公众号
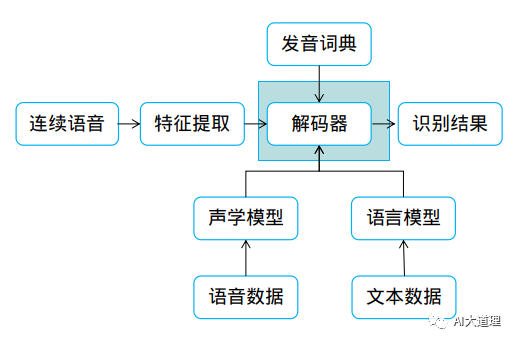
为了让识别出来的语音符合常规语言表达,引入了语言模型作为约束。
为了加速解码识别效率又引入了WFST解码机制。
解码本质:解码就是在网络中寻找最优路径。
![]()
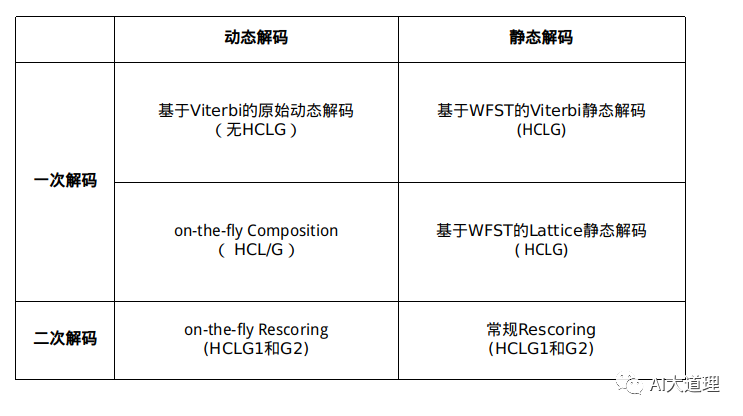
解码方式多种多样,各有优缺点。
![]()
(注:on-the-fly Rescoring 归为动态解码有待商榷)
1 基于Viterbi的原始动态解码
无HCLG、一次解码
基于Viterbi的动态解码是最基础的解码。
线性词典:动态解码网络仅仅把词典编译为状态网络,构成搜索空间。编译的一般流程为:首先把词典中的所有单词并联构成并联网络;然后把单词替换为音素串;接着把每个音素根据上下文拆分为状态序列;最后把状态网络的首尾根据音素上下文一致的原则进行连接,构成回环。
编译出来的网络一般称为线性词典(Linear Lexicon)。
每个单词的状态序列保持严格独立,不同单词的状态之间没有节点共享,因此内存占用比较大,解码过程中的重复计算比较多。
![]()
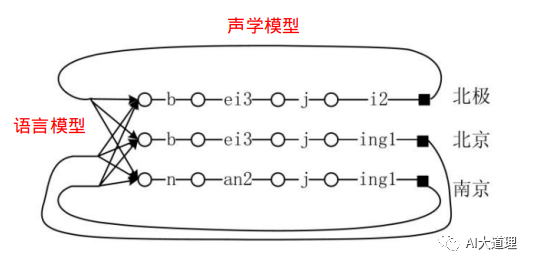
将上图状态拉成直线,做为Y轴,X轴为时间T。

![]()
随着时间的推移,帧的移动,逐渐对齐到词的最后一个音素的最后一个状态,比如第7帧对齐到“北京”、“北极”、“南京”等词典中每个词的HMM的最后状态,对比累计概率,挑选出“北京”。继续进行下去,结合语言模型,加入语言模型概率,得到最优路径“北京是首都”,即解码结束。
可见,从状态序列到词序列的整个转化过程十分复杂,且词汇量很大的话,计算量很大,解码效率不高。
树型词典:一般把单词首尾发音相同的部分进行合并,称为树型词典(Tree Lexicon)。由于大量相同状态的节点被合并在一起,因此可以显著降低搜索空间的规模,减少解码过程的运算量。

![]()
(该方法基本不用)
2 基于WFST的Viterbi静态解码
HCLG、一次解码
为了加快解码速度,可以把动态知识源提取编译好,形成静态网络,在解码时直接调用。
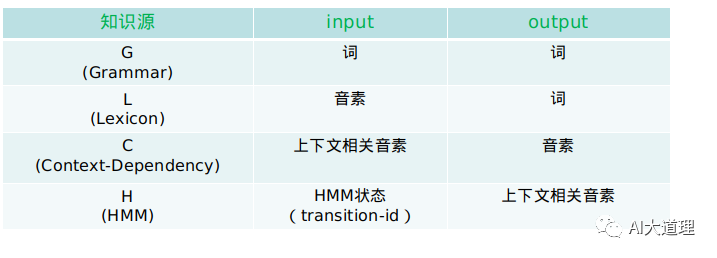
从输入HMM状态序列,直接得到词序列及其相关得分。
用H、C、L、G分别表示上述HMM模型、三音子模型、字典和语言模型的WFST形式。
![]()
一般网络构建的流程为:

![]()
或者
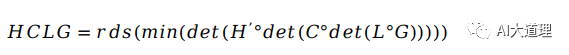
![]()
声学得分依然还要根据输入特征单独计算,其他知识源词典、语言模型、上下文依赖不需要再考虑,已经融入整个静态网络中,通过网络的转移弧输入、输出、权重来整体代替。
由于静态网络已经把搜索空间全部展开,它只需要根据节点间的转移权重计算声学概率和累计概率即可,因此解码速度非常快。
基于WFST的Viterbi静态解码过程:
解码过程使用了令牌传播机制Token passing,其实就是viterbi解码的通用版本。
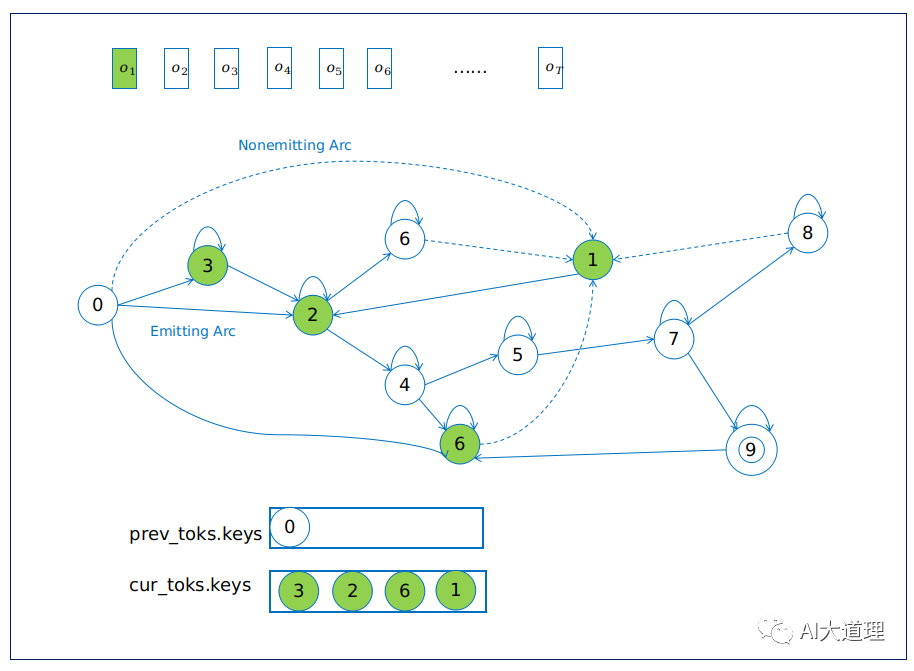
![]()
1)解码第一帧时,从状态节点0出发,首先进行ProcessEmitting处理的发射状态转移弧,节点0转移到节点3、2、6。接着ProcessNonemitting沿着虚线非发射转移弧将6传播到同一时刻下的状态节点1。
2)解码第二帧时首先切换Token列表,把cur_toks列表转变到pre_toks列表后,将cur_toks置空。然后再进行ProcessEmitting、ProcessNonemitting。
3)随着时间的推移,帧的进行,到达最后一帧,选择最低累计代价的Token,然后以次Token回溯最优路径。
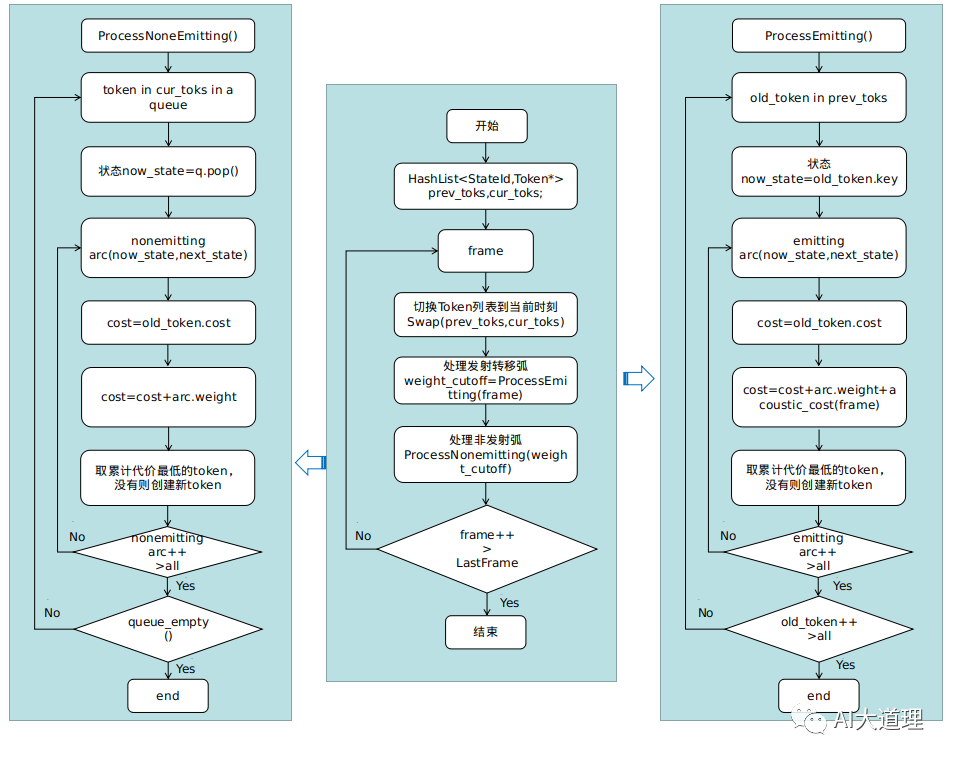
![]()
其中:
Emitting Arc 表示发射转移弧,类似HMM的发射状态,观察值产生声学得分
aoustic_cost;
Nonemitting Arc表示非发射转移弧,类似HMM的非发射状态,不产生观察值,没有声学得分;
每条转移弧对应的权重为图代价graph_cost(语言模型得分、转移概率、发音词典)。

![]()
Swap(prev_toks,cur_toks) :

![]()
直到最后一帧,选择最低累计代价的Token,根据该Token回溯最优路径。
3 基于WFST的Lattice静态解码
HCLG、一次解码
Viterbi解码识别只保留一条最优路径,若要保存多种候选识别结果,就需要Lattice。
(灵魂的拷问:为什么要保存多种候选结果呢?viterbi识别出一条最优路径不够吗?
AI大语音:不能保证viterbi给的最优路径就是真正的对的路径,错误的路径一样可能成为viterbi算法跑出来的最优路径)
Lattice解码需要保存多条搜索路径,Token间需要有链表信息。
前向链接ForwardList与转移弧不同,用来链接前后两帧之间的发射转移弧之间的Token,或同一时刻非发射转移弧之间的Token。
令牌列表TokenList每帧一个,可以和帧索引建立关联。

![]()

![]()
基于WFST的Lattice静态解码过程:
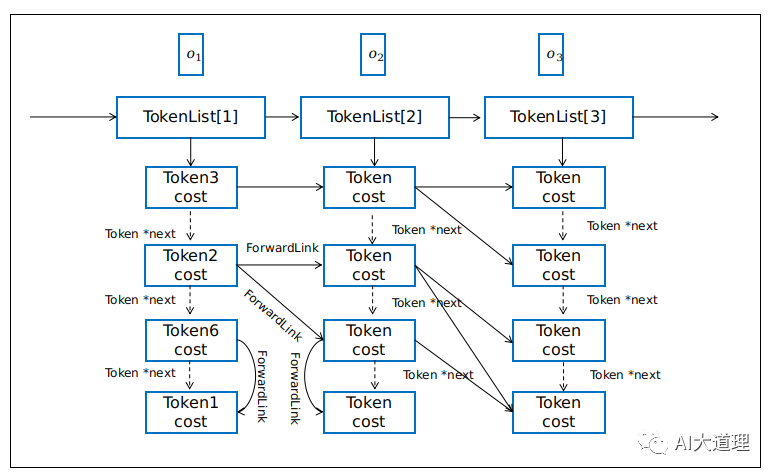
![]()
问题与解决:
在HCLG中,G的大小对最终的HCLG的大小起主要作用。
静态图HCLG问题:
1)静态图HCLG自身占用空间大,难以使用大的语言模型,其在解码运行过程中占用内存也大,难以在移动端直接使用HCLG。
2) 静态图HCLG构建过程速度慢,消耗内存高。
为了解决该问题,有两种方法:
1)on-the-fly Composition;
2)Rescoring(常规Rescoring、on-the-fly Rescoring)。
4 on-the-fly Composition
HCL/G、一次解码、动态解码
on-the-fly Composition动态解码思路是把HCLG分开成HCL和G,称之为HCL/G。构图时分别构建HCL和G,分别构建的HCL和G。因为不是完全展开的图,这两个图的大小远比其展开的静态图HCLG小,这样就节省了空间。
另一方面无需再进行HCL和G的Compose这一过程,而这一步恰恰是静态图HCLG构建过程中最为耗时的一步,所以又节省了构图时间。
在解码时,分别加载HCL和G,然后根据解码动态的对HCL和G进行按需动态Compose,而无需完全Compose展开。
动态图有什么问题呢?
动态图HCL/G要在解码时动态的做Compose,也就加大了解码时的计算量,所以解码速度会相对降低。
5 Rescoring
HCLG1和G2、二次解码
Rescoring,其思路是在构建时使用小的LM1构建G1,使用G1构建静态图HCLG1,然后使用小的LM1和大的LM2构建G2(G2中LM的weight为LM2的weight减去LM1的weight)。解码时根据HCLG1和G2的使用方式,又可以做进一步细分:
1)常规Rescoring:利用HCLG1先全部解码,生成lattice或者nbest,然后在G2上做lattice和nbest的Rescoring。
2)on-the-fly Rescoring:使用HCLG1做解码,在解码过程中,每当解码出word时,立即再加上G2中的LM weight,所以称之为on-the-fly Rescoring。Kaldi中的BigLM Decoder即为on-the-fly Rescoring。
6 总结
基于Voiterbi的原始动态解码词典一旦很大,计算量就会很大,解码速度很慢。
为了加速解码速度,一方面可以进行剪枝处理,在解码中选出最优路径,超过剪枝阈值的路径则直接删除,不再后续运算。
另一方面可以把知识源预先编译成一个静态网络,在解码中直接使用。其中一般基于WFST的Viterbi静态解码得到的一条最优路径可能并不是实际上真正的最优路径,为了得到更多的候选结果使用基于WFST的Lattice静态解码。
静态解码HCLG占用空间大,难以使用大的语言模型,HCLG在构建过程中速度慢,消耗内存高。
为了解决静态一次解码的问题,可以进行on-the-fly composition动态解码和rescoring解码。

![]()

![]()
下期预告
AI大语音(十二)——WFST解码器(下)(深度解析)
往期精选
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号