
SPP-net
SPP-net原理解读
转载自:目标检测:SPP-net 地址https://blog.csdn.net/tinyzhao/article/details/53717136
上文说到R-CNN的最大瓶颈是2k个候选区域都要经过一次CNN,速度非常慢。Kaiming He大神最先对此作出改进,提出了SPP-net,最大的改进是只需要将原图输入一次,就可以得到每个候选区域的特征。
概述
在R-CNN中,候选区域需要进过变形缩放,以此适应CNN输入,那么能不能修改网络结构,使得任意大小的图片都能输入到CNN中呢?作者提出了spatial pyramid pooling结构来适应任何大小的图片输入。
网络结构
为什么CNN需要固定输入大小?卷积层和池化层的输出尺寸都是和输入尺寸相关的,它们的输入是不需要固定图片尺寸的,真正需要固定尺寸的是最后的全连接层。

由于FC层的存在,普通的CNN通过固定输入图片的大小来使得全连接层输入固定。作者不这样思考,既然卷积层可以适应任何尺寸,那么只需要在卷积层的最后加入某种结构,使得后面全连接层得到的输入为固定长度就可以了。这个结构就是spatial pyramid pooling layer:
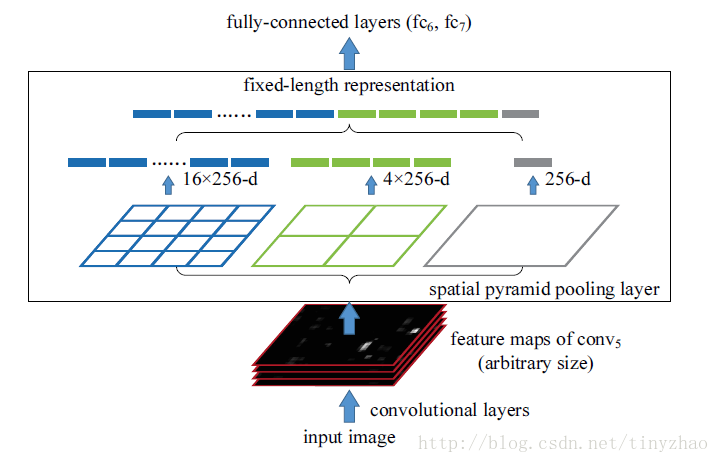
在最后的卷积层和全连接层之间加入SPP层。具体做法是,在conv5层得到的特征图是256层,每层都做一次spatial pyramid pooling。先把每个特征图分割成多个不同尺寸的网格,比如网格分别为4*4、2*2、1*1,然后每个网格做max pooling,这样256层特征图就形成了16*256,4*256,1*256维特征,他们连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。
训练
这样的网络怎么训练呢?对于图片分类任务而言,如果图片大小固定,那么SPP层每个金字塔的大小是可以提前计算的,根据conv5的尺寸计算出每次池化的步长和窗口大小。如果图片大小不固定呢,将图片变为不同的尺寸224*224和180*180,因为池化层是没有参数的,步长和窗口大小是提前计算得到的,两种尺寸的网络是共享了所有的参数。使用两种尺寸图片轮流训练网络,更新参数。作者发现多尺寸和单尺寸收敛速度是差不多的。两种尺寸是训练时候的策略,在测试的时候,不管什么尺寸的输入,直接使用训练好的参数计算。
检测
上面说的都是分类问题,下面说SPP在检测问题中的应用。

对卷积层可视化发现:输入图片的某个位置的特征反应在特征图上也是在相同位置。基于这一事实,对某个ROI区域的特征提取只需要在特征图上的相应位置提取就可以了。

一张任意尺寸的图片,在最后的卷积层conv5可以得到特征图。根据Region proposal步骤可以得到很多候选区域,这个候选区域可以在特征图上找到相同位置对应的窗口,然后使用SPP,每个窗口都可以得到一个固定长度的输出。将这个输出输入到全连接层里面。这样,图片只需要经过一次CNN,候选区域特征直接从整张图片特征图上提取。在训练这个特征提取网络的时候,使用分类任务得到的网络,固定前面的卷积层,只微调后面的全连接层。
在检测的后面模块,仍然和R-CNN一样,使用SVM和边框回归。SVM的特征输入是FC层,边框回归特征使用SPP层。
总结
SPP-net对R-CNN最大的改进就是特征提取步骤做了修改,其他模块仍然和R-CNN一样。特征提取不再需要每个候选区域都经过CNN,只需要将整张图片输入到CNN就可以了,ROI特征直接从特征图获取。和R-CNN相比,速度提高了百倍。
SPP-net缺点也很明显,CNN中的conv层在微调时是不能继续训练的。它仍然是R-CNN的框架,离我们需要的端到端的检测还差很多。既然端到端如此困难,那就先统一后面的几个模块吧,把SVM和边框回归去掉,由CNN直接得到类别和边框可不可以?于是就有了Fast R-CNN。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号