

Gmapping
https://zhuanlan.zhihu.com/p/57566566
https://blog.csdn.net/weixin_42143481/article/details/105230356
https://blog.csdn.net/qq_25241325/article/details/81031716
https://blog.csdn.net/liuyanpeng12333/article/details/81946841
https://blog.csdn.net/Mason_Mao/article/details/80994874
https://zhuanlan.zhihu.com/p/85946393
https://blog.csdn.net/lqygame/article/details/71158422
1 地图构建中的Rao-Blackwellized粒子滤波算法
SLAM的核心思想是根据其观测值和其里程计测量信息去估计联合后验概率密度函数(代表地图中的点、代表机器人的轨迹)。可以看出,轨迹和地图需要同时计算出来,这样的计算很复杂而且计算的结果可能不收敛。而RBPF(Rao-Blackwellized Particle Filter)算法利用公式(1)对联合概率密度函数进行因式分解。
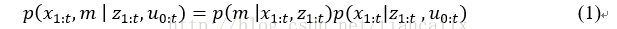
因此RBPF可以先估计机器人的轨迹而后再去根据已知的轨迹计算地图。由地图的概率密度函数可以看出,地图强烈依赖于机器人的位姿,所以这个方法是可行的。
地图的概率密度函数可以通过已知位姿的建图方法“mapping with known poses”来计算。后验概率密度函数应用粒子滤波来估计?。
粒子滤波算法的核心思想是利用一系列随机样本的加权和近似后验概率密度函数,通过求和来近似积分操作。该算法源于Monte Carlo思想,即以某事件出现的频率来指代该事件的概率。因此在滤波过程中,需要用到概率的地方,一概对变量采样,以大量采样及其相应的权值来近似表示概率密度函数。
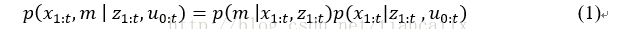
其中最普遍的粒子滤波算法为SIR(Samping Importance Resampling)滤波器。该算法通过以下四步完成:
1)预测阶段:粒子滤波首先根据状态转移函数预测生成大量的采样,这些采样就称之为粒子,利用这些粒子的加权和来逼近后验概率密度。
2)校正阶段:随着观测值的依次到达,为每个粒子计算相应的重要性权值。这个权值代表了预测的位姿取第个粒子时获得观测的概率。如此这般下来,对所有粒子都进行这样一个评价,越有可能获得观测的粒子,获得的权重越高。
3)重采样阶段:根据权值的比例重新分布采样粒子。由于近似逼近连续分布的粒子数量有限,因此这个步骤非常重要。下一轮滤波中,再将重采样过后的粒子集输入到状态转移方程中,就能够获得新的预测粒子了。
4)地图估计:对于每个采样的粒子,通过其采样的轨迹与观测计算出相应的地图估计。
重要性权值的计算
SIR算法需要在新的观测值到达时从头评估粒子的权重。当轨迹的长度随着时间的推移而增加时,这个过程的计算复杂度将越来越高。因此Doucet等学者通过式(2)限制重要性概率密度函数来获得递归公式去计算重要性权值。
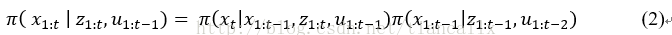

pi和p有什么区别?p和pi分别如何计算
2 GMapping中的优化算法
GMapping为2007年在ROS中开源的SLAM软件包,是目前使用最广泛的软件包。它可用于室内和室外,应用改进的自适应RBPF算法来进行定位与建图。
Doucet等学者基于RBPF算法提出了改进的重要性概率密度函数并且增加了自适应重采样技术。如上一节所述,为了获得下一迭代步骤的粒子采样我们需要从重要性概率密度函数中抽取样本。显然,重要性概率密度函数越接近目标分布,滤波器的效果越好。
2.1 最优重要性概率密度函数
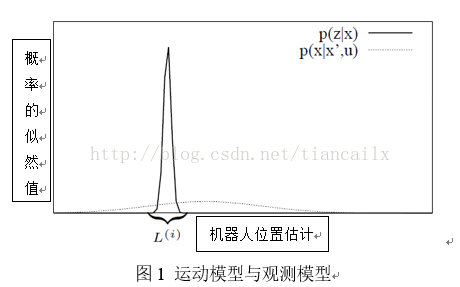
典型的粒子滤波器应用里程计运动模型作为重要性概率密度函数。这种运动模型的计算非常简单,并且权值只根据运动模型即可算出。然而,这种模型并不是最理想的。当机器人装备激光雷达(如SICK,Hokuyo等)时,激光测得的数据比里程计精确的多,因此使用观测模型作为重要性概率密度函数将要准确的多。图1展示了观测模型的分布明显小于运动模型的分布。由于观测模型的分布区域很小,样本处在观测的分布(图中的区域)的几率很小,在保证充分覆盖观测的分布情况下所需要的粒子数就会变得很多,这将会导致使用运动模型作为重要性概率密度函数类似的问题:需要大量的样本来充分覆盖分布的区域。
为了克服这个问题,可以在生成下一次采样时将最近的观测考虑进去。通过将整合到概率分布中,可以将抽样集中在观测似然的有意义的区域。为此Doucet等提出了最优重要性概率密度函数,式4为粒子权重方差的最优分布。
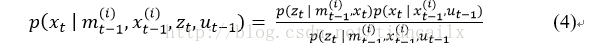
所以式(4)在机器人装备激光测距仪的时候非常适用。
现在的RBPF算法过程是这样的,首先根据运动模型对机器人下一时刻位姿进行预测,得到预测的状态值并且对其进行采样。第二步是通过最优概率密度函数(4)对各个粒子进行权值的计算。之后进行重采样,根据粒子的权重重新分布粒子,为下次预测提供输入。最后,根据粒子的轨迹计算地图的后验概率密度函数。

图2中展示了在不同场景下的粒子分布情况。(a)为在开放的走廊中,粒子沿着走廊分布。(b)为在死胡同中,粒子分布的不确定性很小,分布的很集中。(c)为根据里程计运动模型预测生成的粒子分布,分布的很分散。
因此,该算法将最近的里程计信息与观测信息同时并入重要性概率密度函数中,使用匹配扫描过程来确定观察似然函数的分布区域,这样就把采样的重点集中在可能性更高的区域。当由于观察不佳或者当前扫描与先前计算的地图重叠区域太小而失败时,将会用图2中(c)所示的里程计运动模型作为重要性概率密度函数。
限制重采样次数
为了避免粒子耗散,作者提出限制重采样次数的策略。我们可以想象,当机器人持续探索未知区域,且尚未发生回环的时候,由于方案一中提议分布的改善,粒子的多样性和准确性都维持在一个较高的水平。虽然累计误差始终在叠加,但在局部区域,可以认为粒子保持了较高的精度。此时,如果频繁执行重采样,粒子的多样性将会消失,历史久远的位姿将变得越来越单一。
何时执行重采样,是一个值得思考的问题。应当明确,重采样的目的是抛弃那些明显远离真实值的粒子,增强那些离真实值近的粒子。如果所有粒子都在真实值附近,且分布均匀,那么我们就没有理由执行重采样。在回环发生之前,即使有些粒子已经远离了真实值,但现有的观测不足以区分开正确的粒子和错误的粒子,因此这时候的重采样是没有意义的。只有在回环发生之后,新的观测彻底拉开正确粒子和错误粒子的权重差距,此时的重采样才能起到应有的效果。
那么,如何才能知道回环是否发生呢。显然,GMapping中没有回环检测的算法,但机智的作者给出了更巧妙的实现方式。直接通过下式评估所有粒子权重的分散程度。
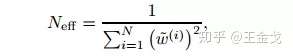
Neff越大,粒子权重差距越小。想象极端情况,当所有粒子权重都一样的时候(比如重采样之后),这些粒子恰好可以表示真实分布(类似于按照某个分布随机采样的结果)。当Neff降低到某个阈值以下,说明粒子的分布与真实分布差距很大,在粒子层面表现为某些粒子离真实值很近,而很多粒子离真实值较远。这正是回环发生时经常出现的情况,重采样就应该在此时进行。
